
수업 정리
강의 목록
[DL Basic] Generative Models 1
- Learning a Generative Model
- Generation(sampling) : If we sample should look like a dog
- Density estimation(anomaly detection) : should be high if looks lik a dog, and low otherwise. also known as, explicit models.
- Unsupervised representation learning(feature learning) : We should be able to learn what these image have in common, e.g., ears, tail, etc
>> then, how can we represent ?- Basic Discrete Distributions
- Bernoulli distribution : (biased) coin flip
- Specify Then
- Write :
- Categorical distribution : (biased) m-sided dice
- Specify such that
- Write :
- Structure Through Independence
- What if are independent, then
- How many possible states?
- How many parameters to specify
- entries can be described by just numbers! But this assumption is too strong to model useful distributions.
- Conditional Independence
- Three important rules
- Chain rule :
- Bayes' rule :
- Conditional independence : If then
- If using the chain rule, How many parameters?
- : 1 params
- : 2 params (one per and one per
- : 4 params
- Hence,
- Now, suppose (Markov assumption), then
- How many parameters?
- Hence, by leveraging the Markov assumption, we get exponential reduction on the number of parameters.
- Auto-regressive models leverage this conditional independency.
- Auto-regressive model
- Suppose we have binary pixels
- Our goal is to learn over
- How can we parametrize ?
- Let's use the chain rule to factor the joint distribution
- This is called an autoregressive model
- Note that we need an order of all random variables.
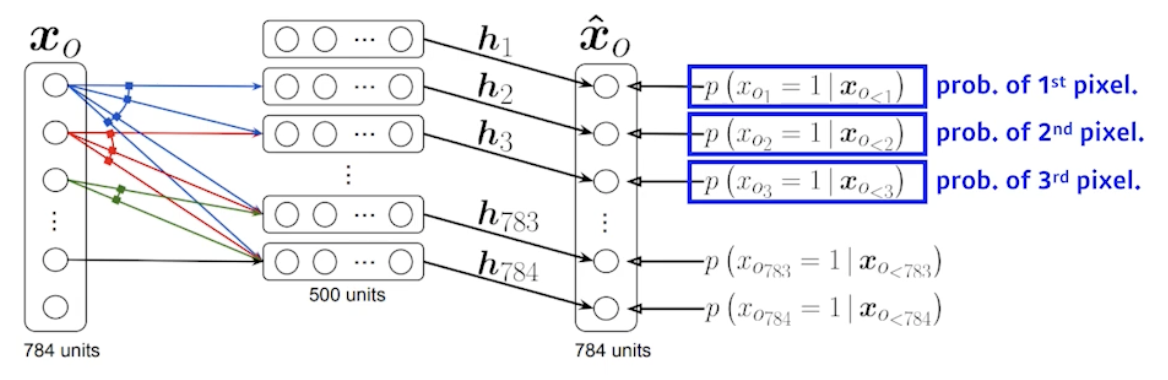
- NADE : Neural Autoregressive Density Estimator
- probability distribution of -th pixel : where
- NADE is an explicit model that can compute the density of the given inputs
- How can we compute the density off the given image?
- Suppose we have image with 784 binary pixels,
- Then, the joint probability is computed by where each conditional probability is computed independently
- In case of modeling continuous random variable, a mixture of Gaussian can be used
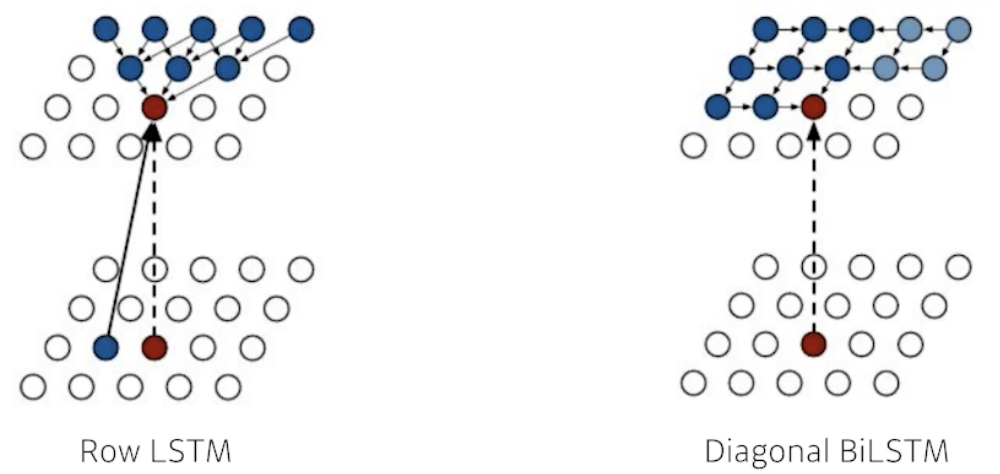
- Pixel RNN
- We can also use RNNs to define an auto-regressive model
- For example, for an RGB image,
- There are two model architectures in Pixel RNN based on the ordering of chain:
- Row LSTM
- Diagonal BiLSTM
[DL Basic] Generative Models 2
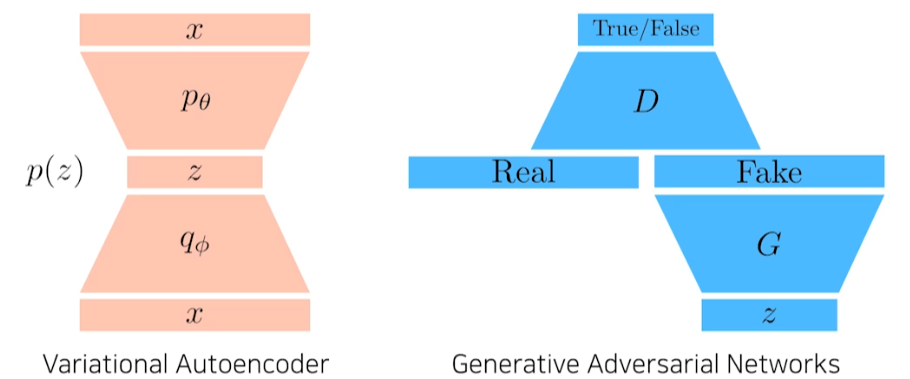
- Variational Auto-encoder
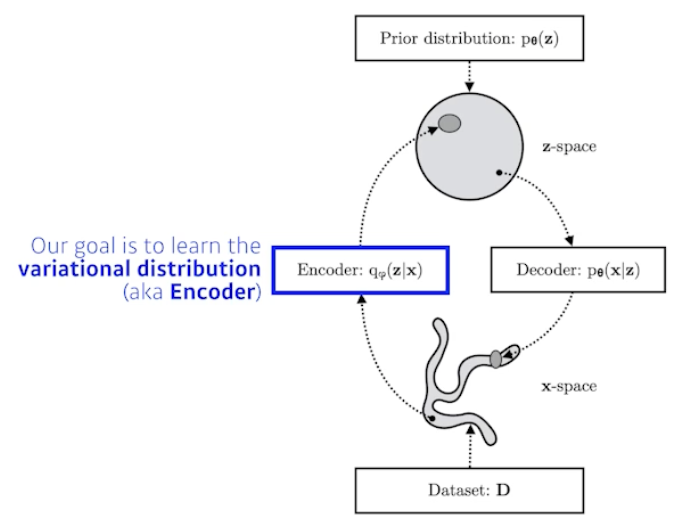
- Variational inference(VI)
- The goal of VI is to optimize the variational distribution that best matches the posterior distribution
- Posterior distribution :
- Variational distribution :
- In particular, we want to find the variational distribution that minimizes the KL divergence between the true posterior
- But how?
- ELBO can further be decompsed into
- Key limitation
- It is an intractable model(hard to evaluate likelihood)
- The prior fitting term must be differentiable, hence it is hard to use diverse latent prior distributions.
- In most cases, we us an isotropic Gaussian
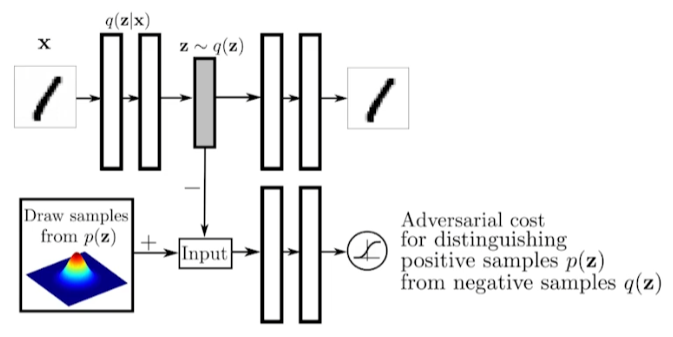
- Adversarial Auto-encoder
- It allows us to use any arbitrary latent distributions that we can sample
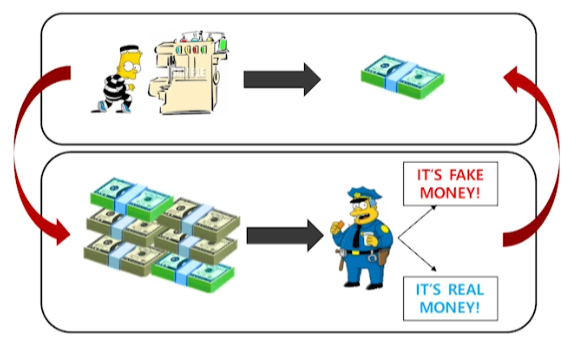
- GAN
- GAN vs VAE
- GAN Objective
- A two player minimax game between generator and discriminator
- For discriminator:
- where the optimal discriminator is
- For generator :
- Plugging in the optimal discriminator, we get
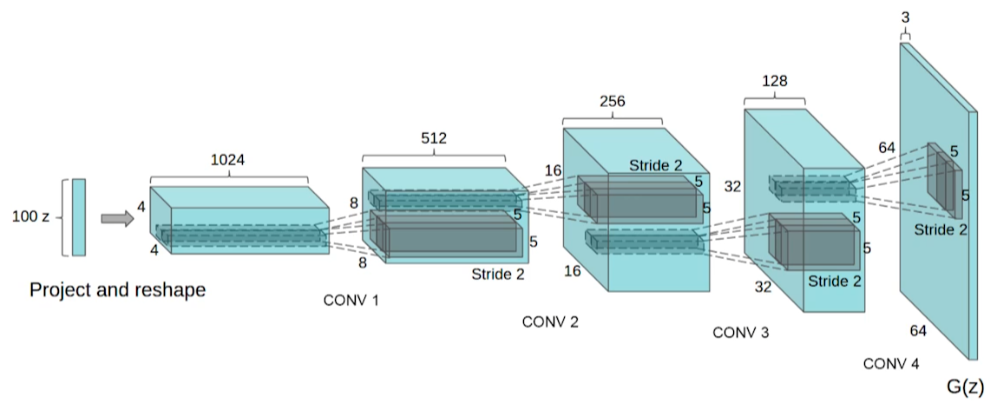
- DCGAN
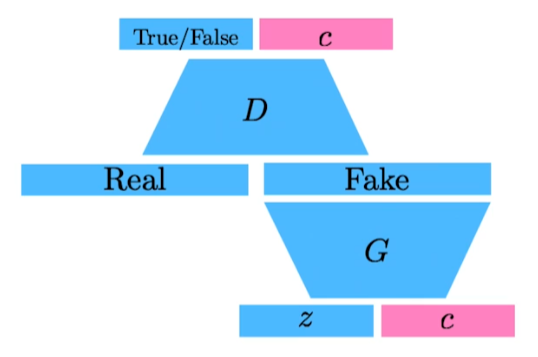
- Info-GAN
- Text2Image
- Puzzle-GAN
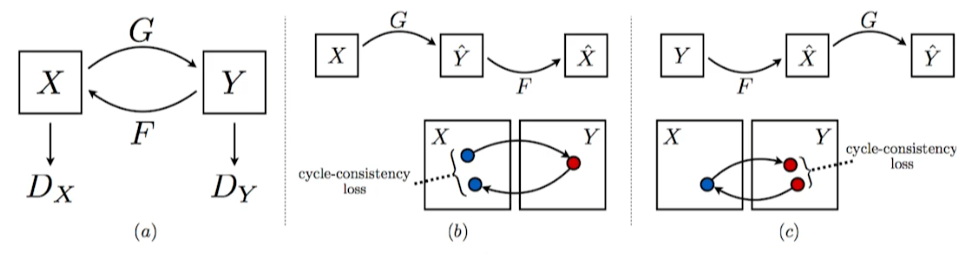
- CycleGAN
- Cycle-consistency loss
- Star-GAN
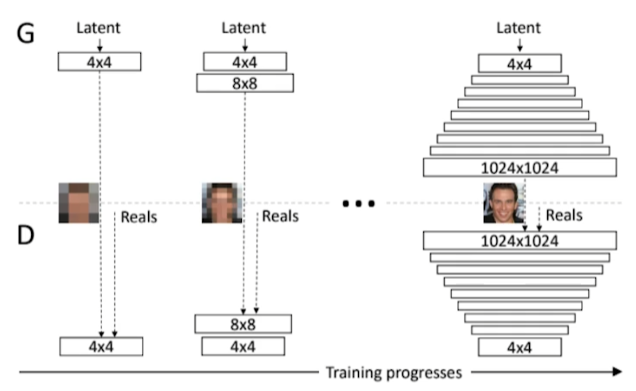
- Progressive-GAN






피어세션 정리
- 스페셜 피어세션
- 팀 회고록 작성
느낀점
기존에 공부했던 NLP외에 CNN 발전 모델과 GAN 등을 공부할 수 있었던 일주일이었습니다.
벌써 2주가 지났습니다. 목표로하던 대회, 공모전 참가는 아직 실행에 옮기지 못했습니다... 하루 빨리 대회 찾아서 참가라도 해보는 것에 의의를 두어야 할 것 같습니다.
