진도: Chapter 03
유튜브 강의 : 6강 ~ 7강
교재실습 정리
📍코랩링크
03-1. 불필요한 데이터 삭제하기
#열 삭제하는 법
- loc로 슬라이싱
- loc에 불리언 배열 넣어서 제거
- drop() 매서드, 열 삭제 시 axis=1 넣어줘야함 (default값인 0은 행삭제)
- drop()에 inplace 매개변수 넣어주면 drop적용한 내용이 df에 덮어씌워짐
(df = df.drop()이랑 똑같음. 성능상 이득 없음)
- dropna() NaN이 하나 이상 포함된 행이나 열 삭제
- 모든 값이 NaN인 열만 지우고 싶을 땐 how 매개변수를 'all'로 지정
#행 삭제하는 법
-drop()함수에 숫자 인덱스 리스트 넣기
-[] 연산자와 슬라이싱
-[]연산자에 슬라이싱 사용하면 loc와 달리 마지막 인덱스 포함 X (ex [0:2] >> 0,1 행만 선택)
-[] 연산자와 불리언배열, loc에 써도 똑같음
#중복행찾기
- duplicated(), 컬럼 설정하고 싶으면 subset매개변수에 설정하고 싶은 컬럼 리스트 입력
- 어떤 데이터가 중복인지 확인하고 싶을땐 keep=False로 매개변수 설정 (중복된 행만 모두 True로 표시함)
#그룹별로 모으기
- groupby()함수, by매개변수에 행 합치는 기준이 되는 열 지정
- groupby()로 데이터를 집계할 때 기본적으로 by에 지정된 열에 NaN이 있는 행은 삭제함. 계산에 포함하고 싶으면 dropna=False 설정필요
#원본 데이터 업데이트하기
- set_index() : 지정한 열을 인덱스로 설정할 때 사용
- update() : 다른 데이터프레임을 사용해 원본 데이터프레임 값 업데이트 할 때 사용 (원본데이터프레임.update(다른 데이터프레임))
- reset_index() : 인덱스 재설정할 때 사용
#기타 배운것들
- df.columns 속성은 Index 클래스, list처럼 숫자인덱스로 조회 가능
- != 비교연산자 : is not 의미
- 넘파이 배열(like 파이썬 리스트), 넘파이는 배열을 효율적으로 다룰수있는 파이썬 패키지
- df.loc[불리언배열]이랑 df.loc[불리언배열, :]은 똑같음
- drop_duplicates() 중복된 행 삭제, duplicate와 동일하게 subset, keep 매개변수 제공
- ~ 연산자 : 배열 반전 시킬때 사용
- 열 순서 변경 []연산자에 원하는 열이름 순서대로 전달
- 다른 데이터프레임 비교 시 equals() 메서드 사용기본 미션
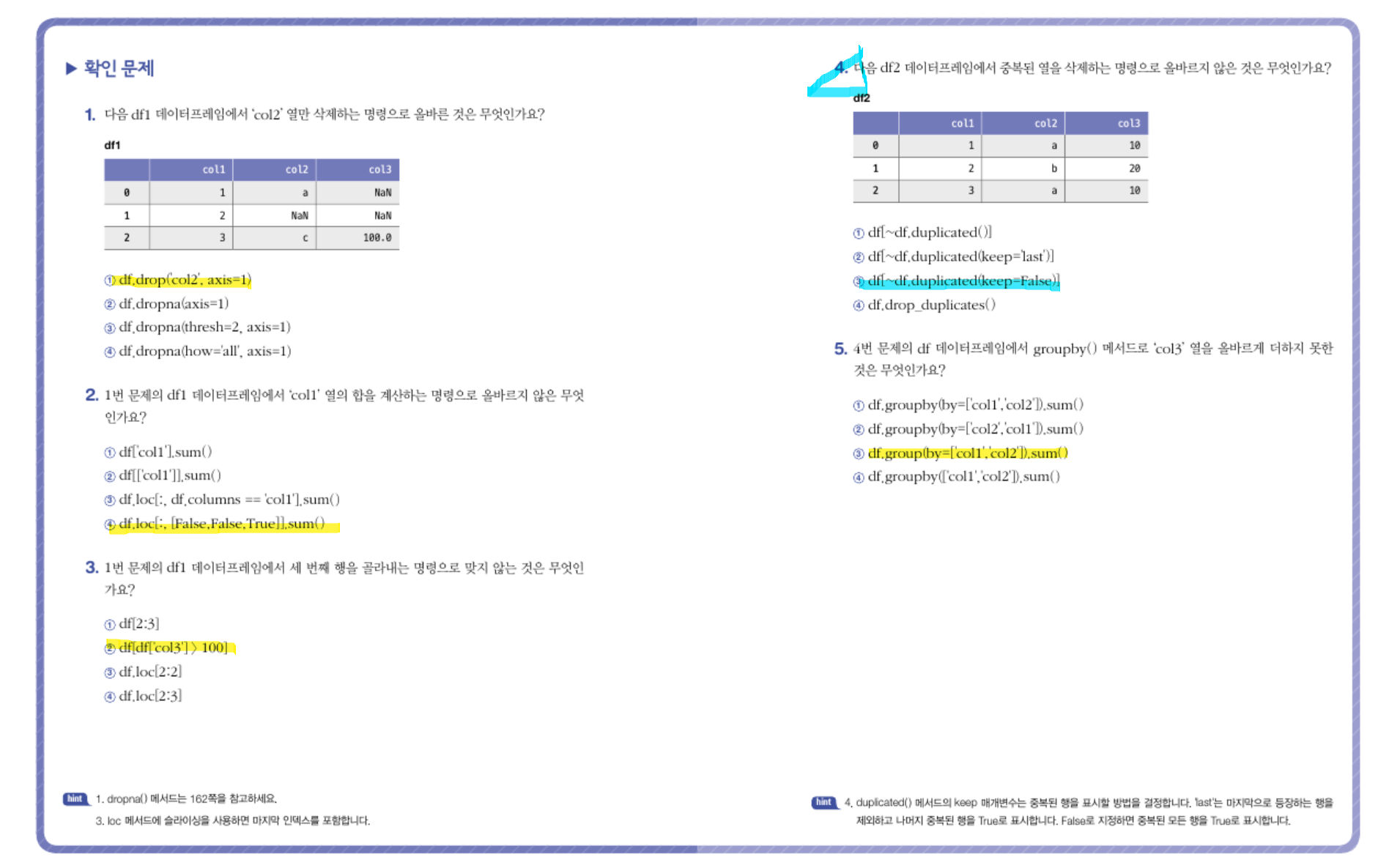
p. 182의 확인 문제 2번 풀고 인증하기
선택 미션
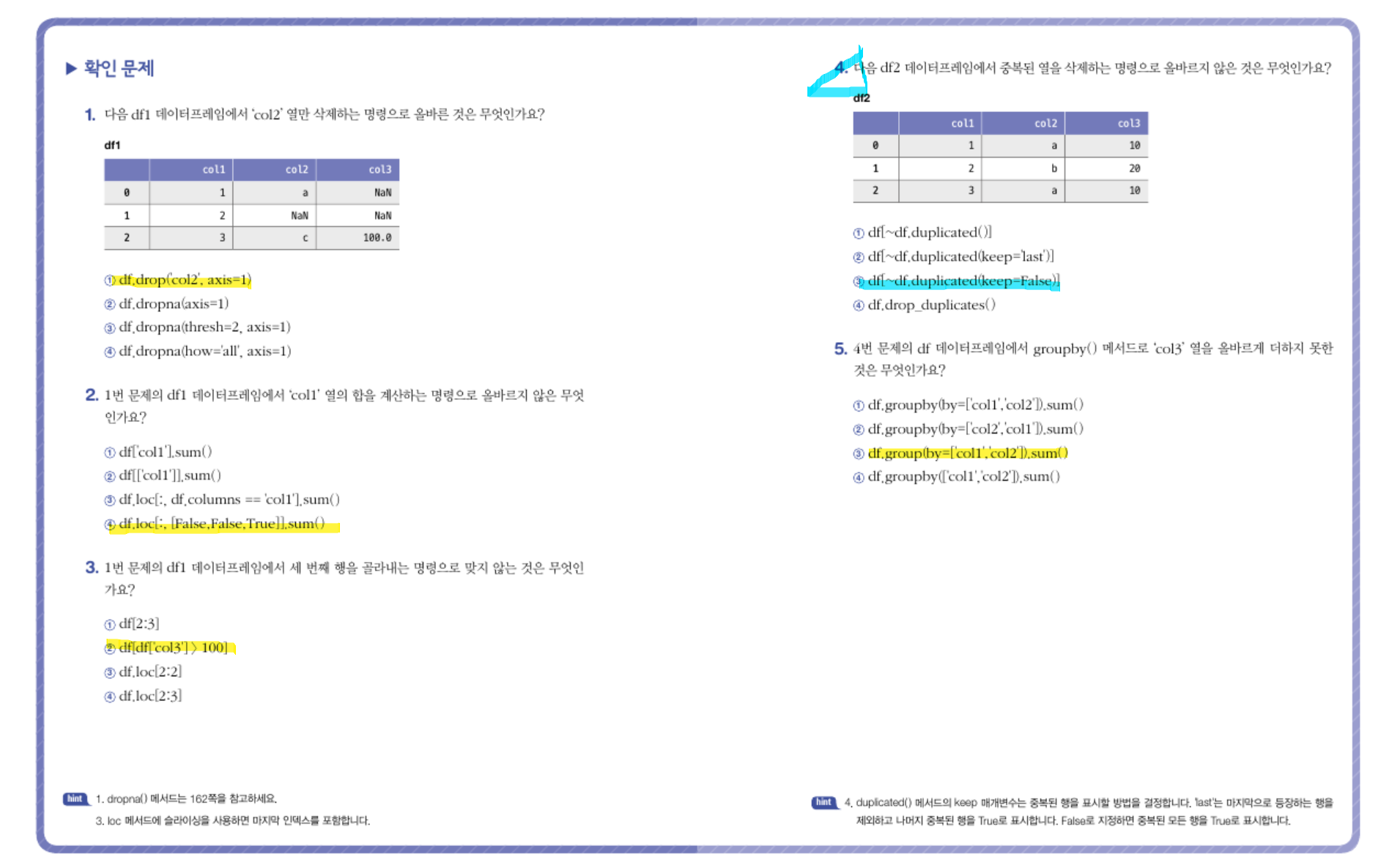
p. 219의 확인 문제 5번 풀고 인증하기

꽤 행복한 사람😎