도입 배경
- 서비스가 커지면서 모든 데이터를 한 테이블, 한 서버에서 관리하려면 복잡하다
- 또한 용량이 커지면서 데이터 쓰기, 읽기 작업 성능이 감소함으로써 데이터베이스 서버가 병목되는 상황이 발생할 수 있다.
- 서비스 크기에 따라 분리하는게 좀 더 나을 수 있다. 분리하는 방식에는 파티셔닝과 샤딩이 있다.
예상질문과 답변
Q. 파티셔닝과 샤딩의 차이점?
- 파티셔닝과 샤딩은 모두 대용량 데이터를 효율적으로 처리하기 위한 데이터 분할 전략
- 파티셔닝은 하나의 테이블을 논리적으로 나누는 작업
- 주로 성능 향상과 관리 편의성을 위해 사용되며, 방식에는 수직 파티셔닝(컬럼 분할)과 수평 파티셔닝(레코드 분할)
- 실무에서는 수평 파티셔닝이 더 많이 쓰이는데,
예를 들어 날짜별로 주문 데이터를 2023년, 2024년으로 나누는 Range 파티셔닝이나,
사용자 ID를 해시로 분산하는 Hash 파티셔닝 방식 - 반면 샤딩은 데이터를 물리적으로 여러 DB 서버에 분산하는 방식
- 데이터량이 많아져서 단일 DB로는 처리 성능이 한계에 다다를 때, 수평 확장을 위해
- 대표적으로는 Range 샤딩과 Hash 샤딩이 있고, MongoDB 같은 NoSQL DB에서는 샤딩 기능 지원함
Q. 파티셔닝 / 샤딩 적용 사례?
- 파티셔닝에서는 주문, 로그, 결제와 같이 시간 기반 대용량 테이블 분할
- 샤딩에서는 지역기반 데이터 분산 (서울 서버, 부산 서버 등)
요약
-
파티셔닝은 하나의 DB 내에서 테이블 분할,
-
샤딩은 여러 DB로 데이터 자체를 분산하는 방식
구분 파티셔닝 샤딩 분할 단위 테이블 내부 DB 서버 단위 사용 목적 쿼리 성능, 인덱스 최적화 트래픽 분산, 수평 확장 예시 날짜별 주문 테이블 분할 user_id 기준으로 서버 A/B/C 분산
파티셔닝
파티셔닝이란?
- 하나의 테이블을 논리적으로 여러 개로 나누는 작업
- 데이터는 여전히 하나의 데이터베이스 안에 존재하지만, 내부적으로 분할되어 쿼리 성능 향상 및 관리 편의성을 얻을 수 있음
파티션의 필요성
- 대용량 데이터 테이블에서 성능 향상
- 관리 단순화 (인덱스 효율화, 백업/복구 범위 축소 등)
파티셔닝 방식
*수직파티셔닝볻 수평 파티셔닝이 자주 사용한다.
수직파티셔닝
- 컬럼(열)을 기준으로 테이블 분리
- 사용시점 :
- 자주 사용하지 않는 컬럼 분리
- 크기가 큰 컬럼이 있을 때
- 정규화 목적
수평파티셔닝
- 레코드(행)를 기준으로 분리
- 사용시점 :
- 테이블 크기가 커서 인덱스 비대화
- 시간/지역 등으로 범위 분리 필요할 때
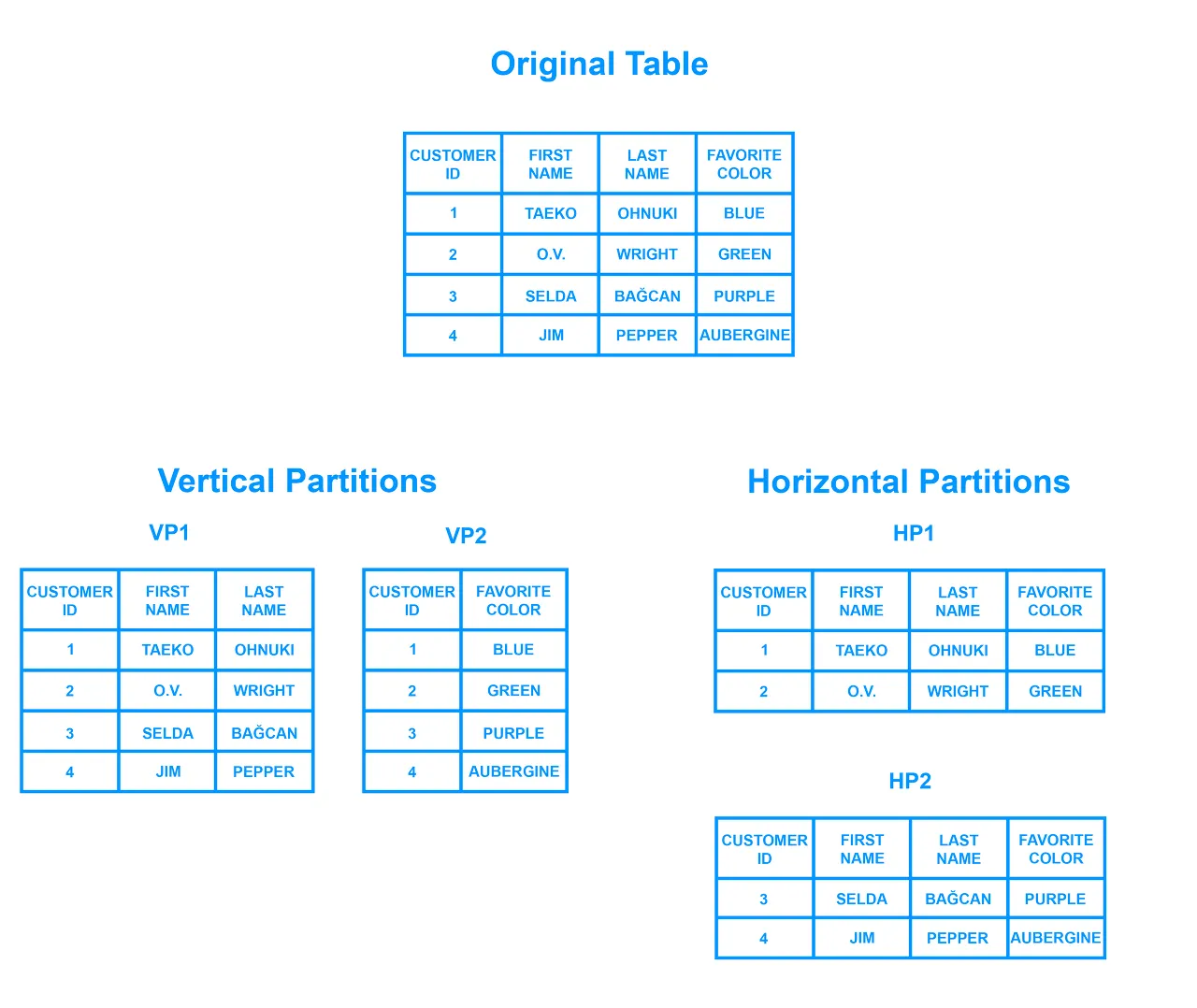
수평 파티셔닝 종류
Range Paritioning 범위기반 파티셔닝
- 날짜나 생년월일의 특정범위에 포함여부를 기준으로 분할하는 예시
- 그 밖에 예시 :
- 날짜 기반 데이터
- 범위 기반
- 파티션 키(파티션 기준점이 되는 컬럼 값) 위주로 검색되는 경우
List Partitioning 특정 값 목록 기반 파티셔닝
- 값 목록에 파티션을 할당
- 위 예시에서 보듯이 각 지역 속성값을 east, west, central과 같이 특정 목록형태로 나눌 수 있을 때
Hash Partitioning 해시 값 기반 파티셔닝
- 해시 함수 결과값에 따라서 분할
- 나머지가 0, 1, 2, 3 인지에 따라 테이블을 분리하는 경우
Composite Partitioning 위 여러 파티셔닝기법을 혼합한 파티셔닝
- 합성분할이라고 하며, 범위분할 + 목록분할 같이 위 파티셔닝 유형을 합쳐서 진행하는 것을 말함
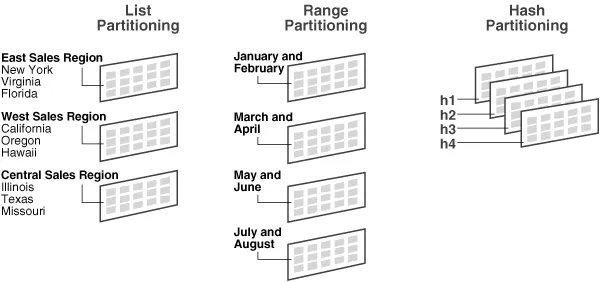
샤딩과 파티셔닝 차이
- 샤딩은 수평 파티셔닝의 일종이다. 차이점은 파티셔닝은 모든 데이터를 동일한 컴퓨터에 저장하지만, 샤딩은 데이터를 서로 다른 컴퓨터에 분산한다는 점이다.
샤딩 Shard
샤딩이란?
- 여러 대의 데이터베이스 서버들에 데이터를 작은단위로 분할하여 분산저장하는 방식인데 이떄 작은 단위를 “샤드”라고 한다.
정의
- 하나의 큰 테이블을 분할하여 서로 다른 데이터베이스로 분산 저장하는 방식
- 파티셔닝이 논리적 분할이라면, 샤딩은 물리적 분산
- 각 샤드를 독립된 DB 서버나 인스턴스에 배포
- 샤딩은 물리적으로 서로 다른 데이터베이스 서버에 데이터를 저장하여 쿼리 성능 증가 데이터 작업으로 인한 서버 부하를 분산한다.
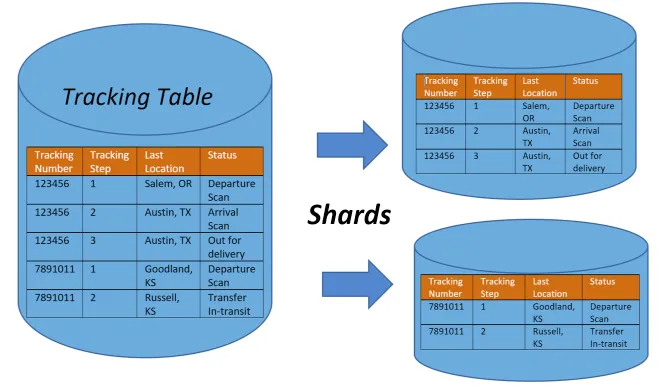
샤딩 필요성
- 분산환경구축용
- 대규모 데이터베이스의 성능과 확장성 개선
- 성능 확장성 (Scale-out)
- 서버 부하 분산
- 대규모 트래픽 대응
- 여러 DB서버에 데이터를 분산하면 쿼리를 병렬로 실행할 수 있으므로 응답 시간이 감소
- 각 샤드의 크기가 작기 때문에 데이터관리가 용이하고 백업도 용이
샤딩의 한계
-
복잡성이 증가
- 데이터베이스 분산은 인프라구축에 복잡성을 추가하여 유지 관리 어려워짐
- 데이터가 적절하게 분산복제되도록 해야하나 어려움, 전문적인 인프라 지식 요구된다. 적합한 분산 전략을 짜야한다.
-
데이터 일관성
- 여러 경로로 데이터가 분할되므로 데이터 일관성이 깨질 수 있다.
- 애플리케이션에서 DB간 서로 동기화되도록 해야하나 까다롭다
-
제한적인 유연성
-
수정된 스키마가 모든 분산환경에서 동시에 반영되어야 하므로 (데이터일관성지켜야하므로) 추가적으로 기능을 넣기가 어렵다.
-
스키마를 수정하면 적절하게 분산 전략도 수정해야한다.
-
샤딩 방식
샤딩에서 주로 사용하는 방식 두가지가 있다. 이를 사용하여 서버 분산 전략으로 사용한다.
- Range Sharding : PK 값에 범위를 지정하여 Sharding
- Hash Sharding : PK에 모듈러(나머지연산)을 사용해 Sharding
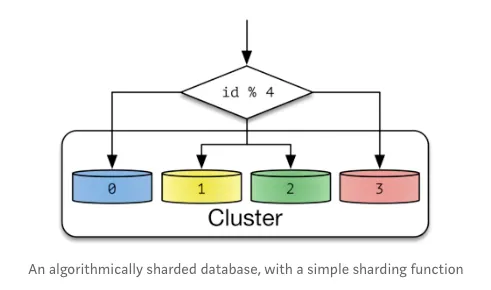
Hash Sharding
- Modular Sharding은 PK값의 모듈러 연산 결과를 통해 샤드를 결정하는 방식이다.
- 총 데이터베이스 수가 정해져있을 때 유용하다. 데이터베이스 개수가 줄어들거나 늘어나면 해시 함수도 변경해야하고, 따라서 데이터의 재 정렬이 필요하다
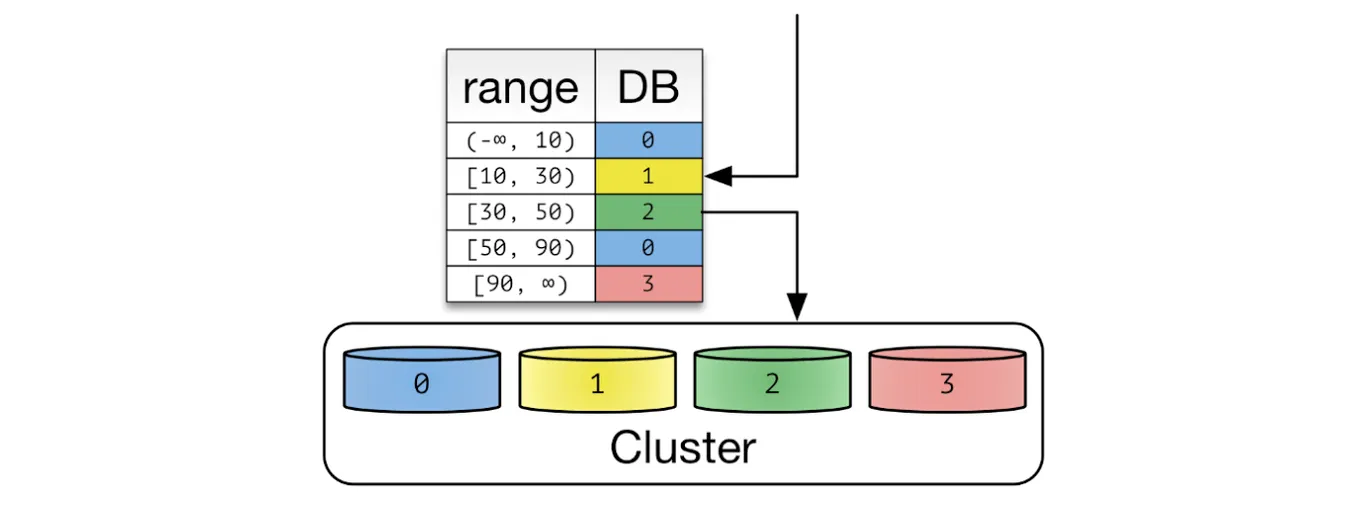
Range Sharding
- PK 값을 범위로 지정하여 샤드를 지정하는 방식이다.
- 예를 들어 PK가 1~1,000 까지는 1번 샤드에, 1,001~2,000 까지는 2번 샤드에, 2,001~ 부터는 3번 샤드에 저장할 수 있다
- Hash Sharding 대비 데이터베이스 증설 작업에 큰 리소스가 소요되지 않는다. 따라서 급격히 증가할 수 있는 성격의 데이터는 Range Sharding 을 사용함이 좋아보인다.
구현 위치에 따른 샤딩
샤딩은 물리적으로 분산환경에서 사용되는 기법으로 데이터베이스 차원이 아닌 애플리케이션 차원에서 구현하는 것이 일반적이다.
- 애플리케이션 샤딩
- 애플리케이션에서 샤딩 로직을 직접 관리
- 미들웨어 샤딩
- DB앞단에서 프록시나 미들티어가 샤딩을 담당
- DB내장 샤딩
- 데이터베이스 엔진이 자체적으로 샤딩
- MongoDB

welcome