aggregation은 데이터 처리 파이프 라인을 구현한 것이다.
아래 사진을 보자.
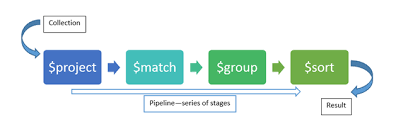
어떤 데이터가 순서대로 정제된 후
result로 나오는 그림이다.

즉 각 stage는 이전 stage의 결과값에 그대로 적용되는 방식!
덕분에 데이터를 불러올 때 매우 편하다.
const CatAvg = await Keywords.aggregate([
{ $match : {'cate_id':{$in : categories}, round_no:roundNo}},
{ $sort : {create_dt:-1}},
{ $group : {_id:'$cate_id', prices : {$push:{$toInt: '$prc_avg'}}}},
// 300개 잘랐음.
{ $project:{average : {$avg:{$slice:["$prices",300]}}}},
])해당 코드는
아래와 같은 절차를 따른다.
categories라는 배열 안에cate_id값이 있고,round_no === roundNo를 찾음
- 만들어진 날짜를 기준으로 내림차순 sort
cate_id를 이용하여 group화를 하는데, prices라는 array 형태의 새로운 field를 만들어서 거기에prc_avg값을 집어넣음.
- prices field의 평균을
average라는 field를 만들어 계산한다.
같이 공부하던 팀원 덕에 돌아갈 것도 지름길로 갈 수 있었다.
감사!
