캐시
접근 방법 [필수 작성]
제한 조건 확인
도시이름 최대 20자 영문(대소문자구분x)
캐시사이즈 0~30 정수
도시갯수 최대 10만개
가장 최근 사용 알고리즘 사용
캐시힛 1
캐시미스 5
아이디어
top 에 있을수록 우선순위가 높고 bottom 쓴게 우선순위가 낮다
큐에 쌓는다
근데, 캐시크기 안에서 가장 오래전에 쓰였어도, 사용횟수가 많으면 가장 오래전에 쓰인 더 적게 쓰인 도시이름부터 빠진다.
시간복잡도는 널널
알아야할 정보는 (캐시내에서 몇번 불렸는지, 언제들어왔는지)
업데이트 될때마다 각 원소가 어느 우선순위에 삽입될지 알아야함
몇번불렸는지가 더 우선순위, 그 다음 같은 횟수에서 불린것중 더 오래전에 쓰인것부터 삭제
추가할때 순서를 미리 맞춰놓고, pop 할때는 바로 pop 할 수 있게 구현
list(deque) 원소 형식 (count, city_name) 형식으로 구현 후 항상 정렬된 상태로 유지될 수 있게 구현 (오름차순)
왼쪽에 있는게 가장 먼저 빠져야할 시티네임
오른쪽에 있는게 가장 보존해야할 시티네임
count 는 몇번 불렸는지
시간복잡도
30*10만 -> 300만
생각보다 시간복잡도는 널널
매 삽입삭제 O(n) 걸려도 상관없음
자료구조
코드 구현 [필수 작성]
1차 시도 (1시간 소요)
몇가지 실제 테스트 케이스에 대해서 실패
(11,13,14,15,16,18,19,20)
코너 케이스 찾는중..
→ 프로그래머스 질문하기 탭에 있는 대부분의 반례들을 삽입해보았으나 다 통과
→ 코너케이스를 못찾겠습니다…
from collections import deque
def solution(cacheSize, cities):
exec_time = 0
cache = deque([])
lower_cities = []
for city in cities:
lower_cities.append(city.lower())
if cacheSize == 0:
return len(cities)*5
def add_city_to_cache_at(cache, update_city_count, update_city): #큐에 추가되어야할 위치를 반환
for index,elem in enumerate(cache):
count,city_name = elem
if count <= update_city_count:
continue
return index
return len(cache)
def find_city_index_from_cache(cache, target_city):
for index,elem in enumerate(cache):
count,city_name = elem
if city_name == target_city:
return index
return -1
for city in lower_cities:
target_city_index = find_city_index_from_cache(cache, city)
if target_city_index == -1: #탐색하려는 city 가 캐시에 없을때
exec_time += 5
if len(cache) == cacheSize: #이미 캐시가 꽉 찬 상태면
cache.popleft()
cache.insert(add_city_to_cache_at(cache, 1, city),(1,city)) #캐시에 추가
else: #탐색하려는 city 가 캐시에 있을때
exec_time += 1
curr_cnt,_ = cache[target_city_index]
cache.remove(cache[target_city_index])
cache.insert(add_city_to_cache_at(cache, curr_cnt+1, city),(curr_cnt+1,city)) #캐시에 추가
return exec_time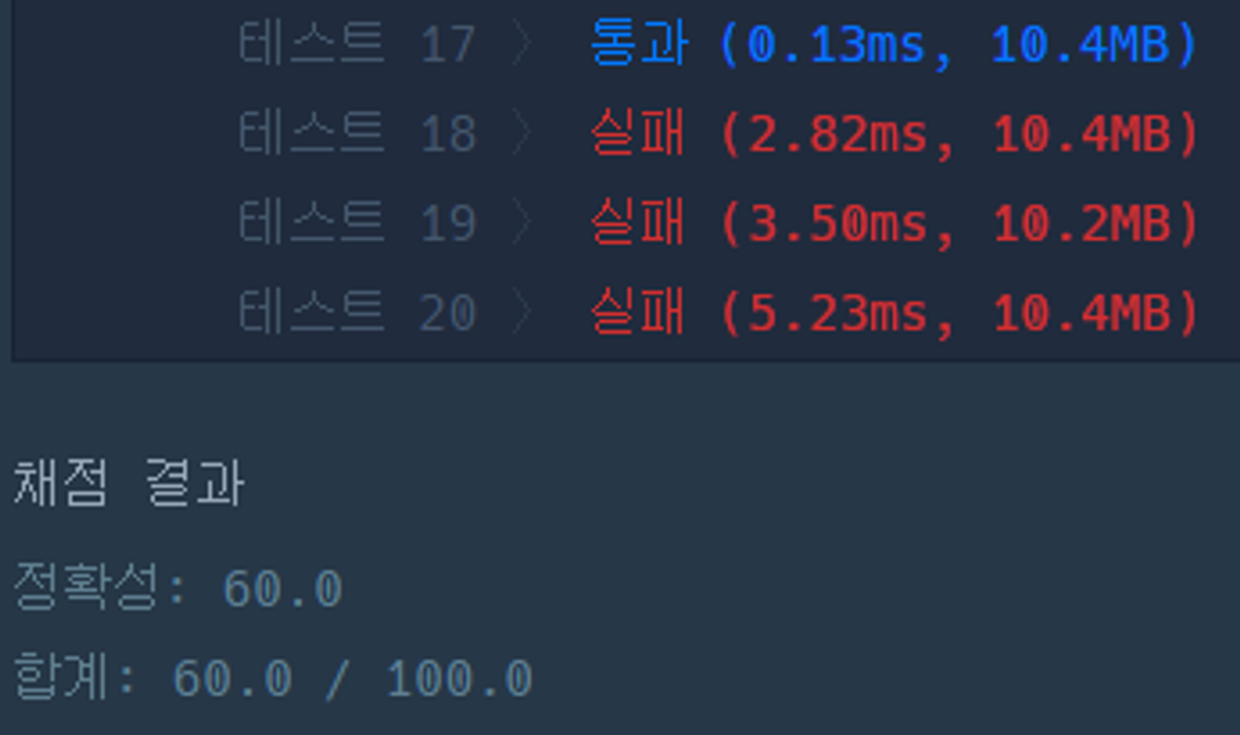
2차 시도 (코드 수정 5분)
LRU 캐시 알고리즘에 대해서 잘못 이해하고 있었다….
Least Recently Used 에서 Least 라는 의미 때문에 가장 적게 사용한 것중 가장 오래전에 쓴거부터 지우는건줄알았는데..
그냥 시간상으로 가장 오래전에 사용한것만 해당되는 거였다.
특정 알고리즘에 대해 기억이 잘 안날때는 구현전 정의를 확실하게 하고 가자 !
from collections import deque
def solution(cacheSize, cities):
exec_time = 0
cache = deque([])
lower_cities = []
for city in cities:
lower_cities.append(city.lower())
if cacheSize == 0:
return len(cities)*5
def find_city_index_from_cache(cache, target_city):
for index,city_name in enumerate(cache):
if city_name == target_city:
return index
return -1
for city in lower_cities:
target_city_index = find_city_index_from_cache(cache, city)
if target_city_index == -1: #탐색하려는 city 가 캐시에 없을때
exec_time += 5
if len(cache) == cacheSize: #이미 캐시가 꽉 찬 상태면
cache.popleft()
cache.insert(len(cache),city) #캐시에 추가
else: #탐색하려는 city 가 캐시에 있을때
exec_time += 1
cache.remove(cache[target_city_index])
cache.insert(len(cache),city) #캐시에 추가
return exec_time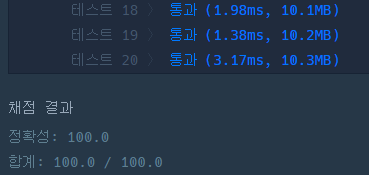
배우게 된 점 [ 필수 X ]
자유 형식
질문 [ 필수 X ]
Q1
→ 코너케이스를 못찾겠습니다… → LRU 캐시 알고리즘을 잘못이해하고 있었음…
피드백 [ 코치 작성 ]
LRU캐시 알고리즘에 대해 잘 못 이해하신 것 같습니다. LRU캐시 알고리즘은 캐시가 가득 찬 경우 가장 마지막에 참조된 데이터를 제거하고 새로운 데이터를 캐시에 넣는 방식으로 진행됩니다. 이 때 새로운 데이터는 가장 최근에 참조된 것으로 큐의 맨 앞에 위치해야 합니다. 현재 구현하신 방식은 새로운 데이터가 입력되거나 또는 기존에 큐에 있는 데이터가 참조되어 맨 앞으로 이동해야 할 때 맨 앞이 아닌 중간에 입력되고 있습니다.
