♠Group Anagrams♠
https://leetcode.com/problems/group-anagrams/description/
작성을 마치신 후 상태를 변경해 주세요!
♠꼬리에 꼬리를 물고♠ (python github 뜯어보기)
문제 파악 [필수 작성]
문제이해
문자를 재배치해서
같아질 수 있는 단어를 그룹으로 묶어라
제한 조건 확인
단어 갯수 최대 10^4 개 -> O(N) 또는 O(NlogN) 으로 풀어라
한단어 최소 0글자 최대 100글자
다 소문자 알파벳
아이디어
1차 아이디어
딱 eat 를 보자마자 tea 랑 ate 랑 같다는걸 알 수 있어야함
즉, 각 단어를 구성하는 알파벳의 갯수를 알면 됨.
-> 갯수 카운팅하는 함수?
-> 갯수카운팅으로는 풀기가 어렵다
-> 왜냐하면 dict는 unhashable type 이기 때문에
2차 아이디어
정렬로 풀면됨
각 단어를 sort 한 후 sort 한 단어를 key 값으로 하는 dict 의 원소에 추가해주면 됨
그리고 나서 각 value 들을 리스트의 원소로 반환
시간복잡도
700 * 10000
자료구조
접근 방법 [필수 작성]
코드 구현 [필수 작성]
#20분 소요
from collections import defaultdict
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
eigen_word = defaultdict(list)
for str in strs:
eigen_word[tuple(sorted(str))].append(str)
return list(eigen_word.values())배우게 된 점 [필수 작성]
unhashable type, type error
unhashable type 은 set 의 원소 또는 dict 의 key 값이 될 수 없다.
list나 dict 는 unhashable type 이기 때문에
dict 자체는 set 의 원소가 되거나, 또 다른 dict 의 key 값이 될 수 없다.


Counter([])
각 원소 갯수 카운팅 해서 dict 클래스로 만들어주는 함수
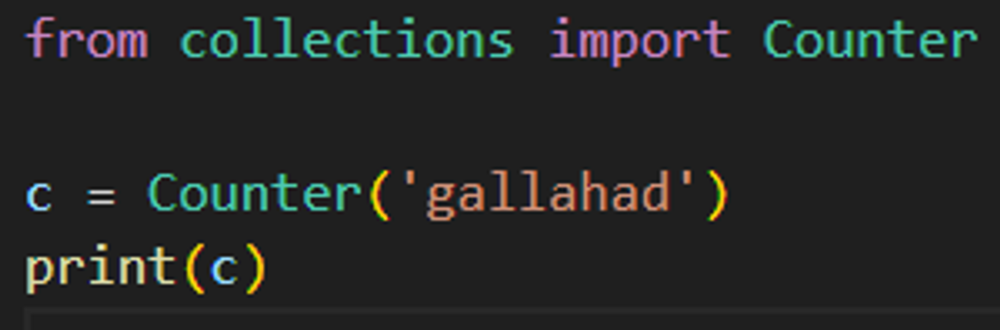

Counter 함수의 내부 구현이 궁금해서 python github 공식 문서를 찾아보던 도중, _ (underscore)의 규칙,의미 다시 한번 되새김.
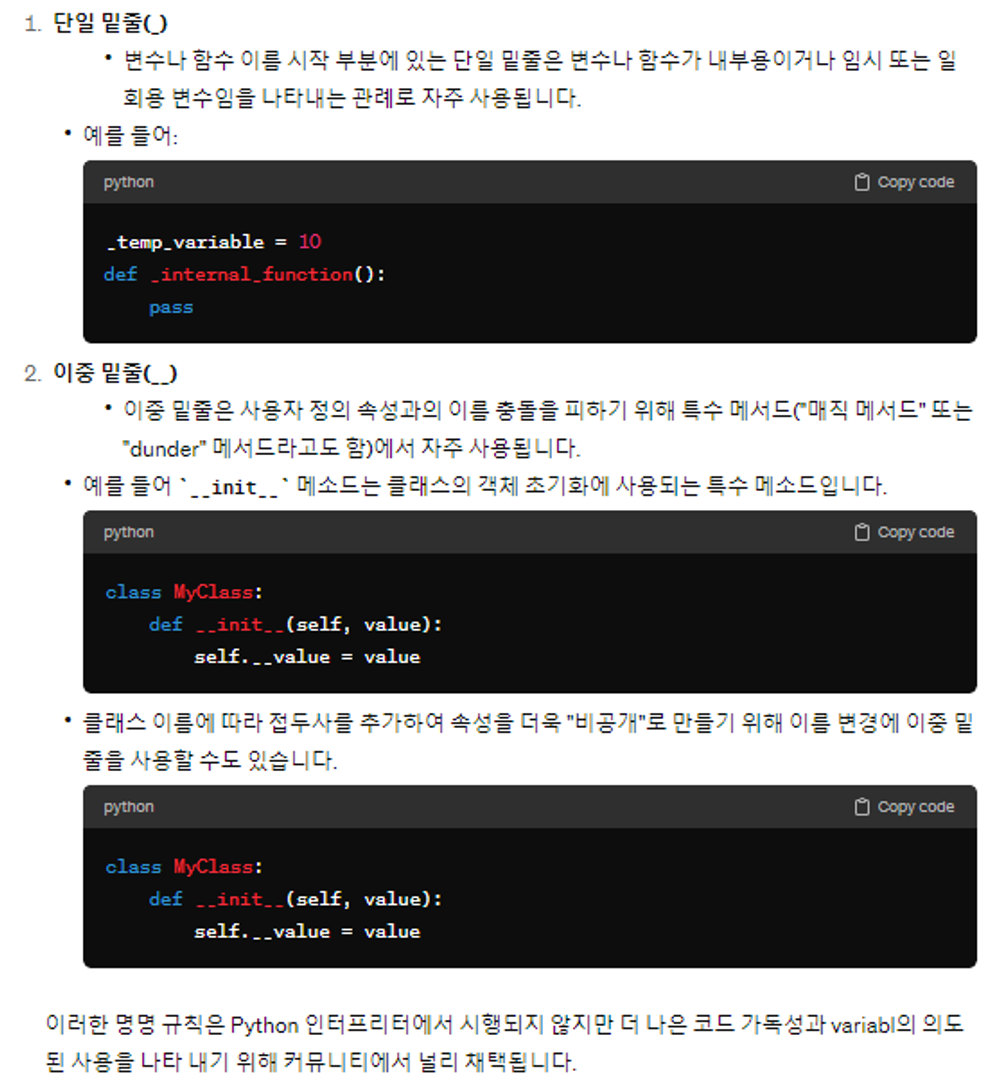
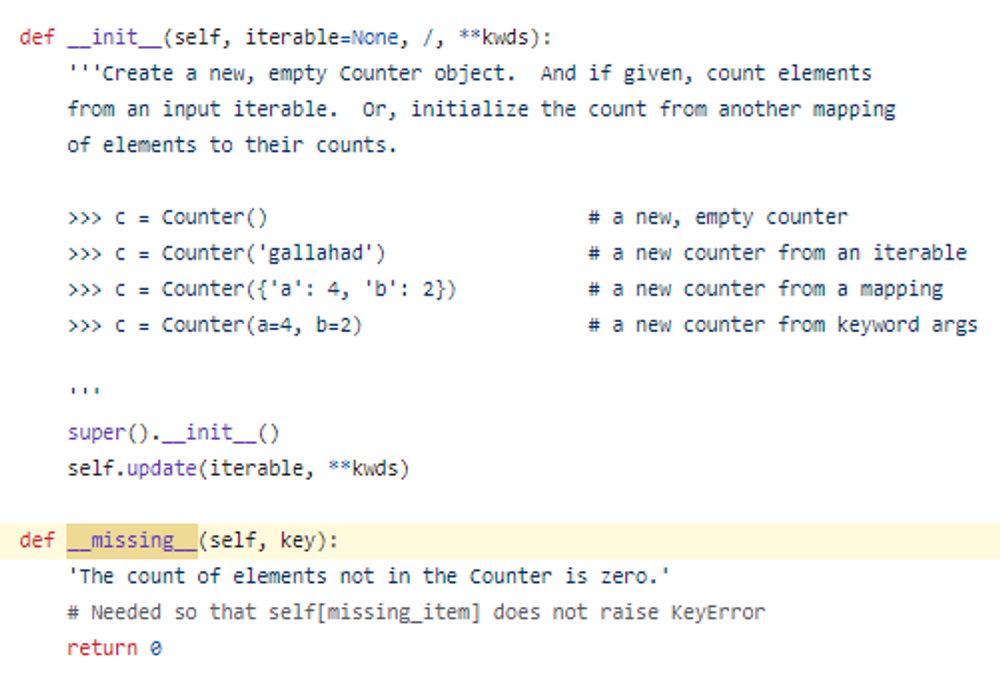
key 가 없는 값을 넣어도 0을 반환하길래 defaultdict(int) 인줄 알았는데
그게 아니고, missing key 값에 대해서는 0을 반환하게끔 구현이 되어 있음.
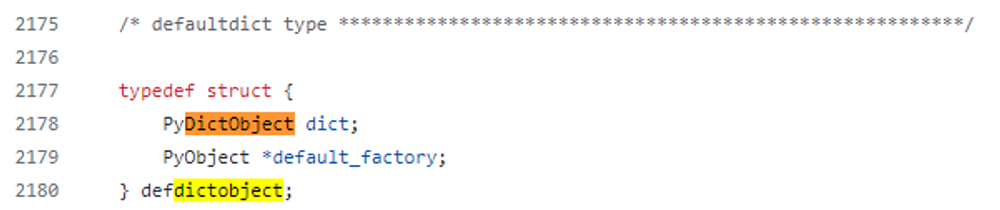
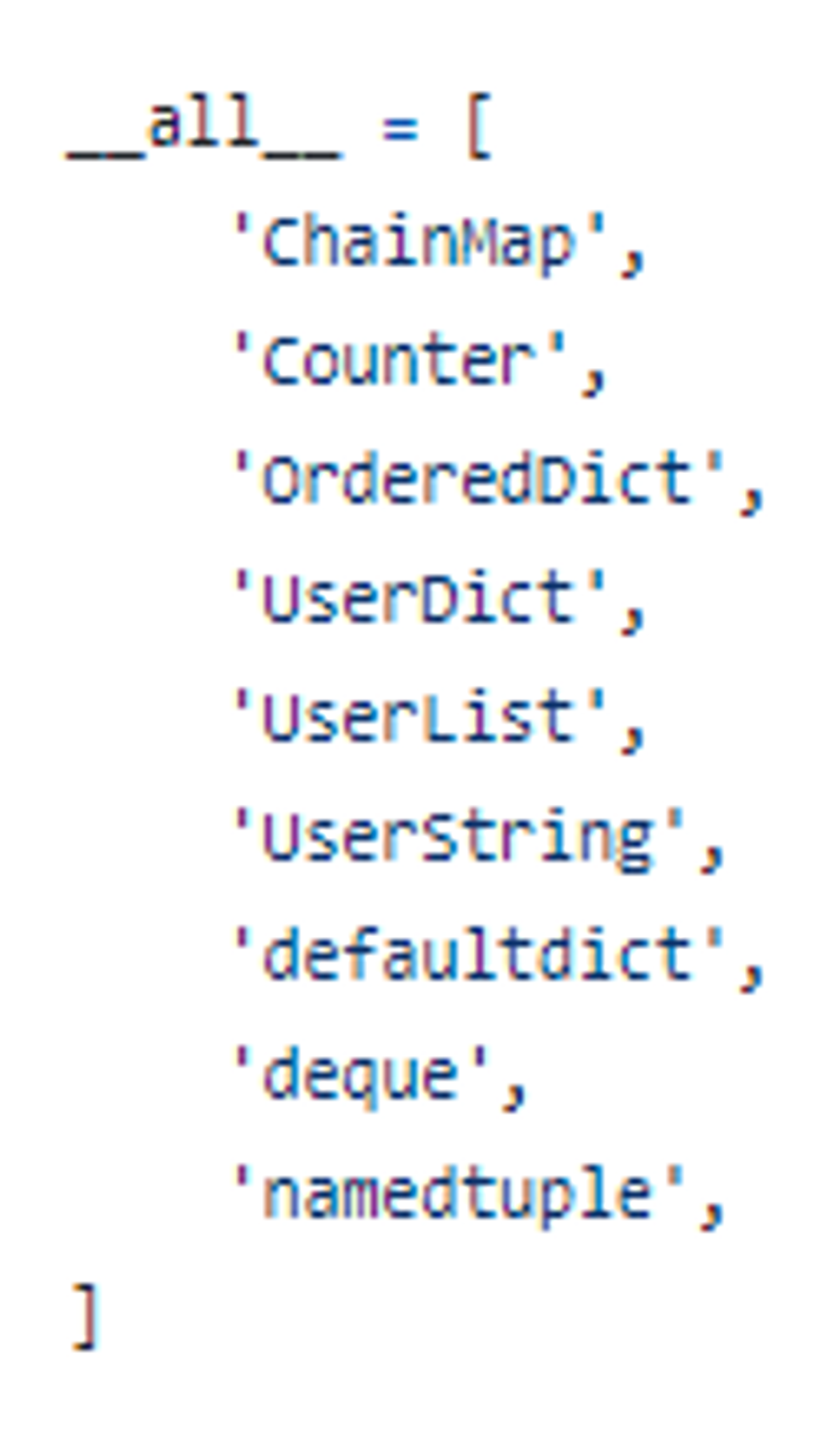
defaultdict 는 어디에 어떻게 구현되어 있는가?
https://github.com/python/cpython/blob/main/Lib/collections/__init__.py
질문 [ 필수 X ]
Q1.
defaultdict 는 어디에 어떻게 구현되어 있는가?
꼬리에 꼬리를 물고 궁금한게 생겨서 보는데,
collections 밑의 init 파일에는 위와 같은 내용이 있습니다.
그런데, _ all _ 을 보면 defaultdict 가 있지만,
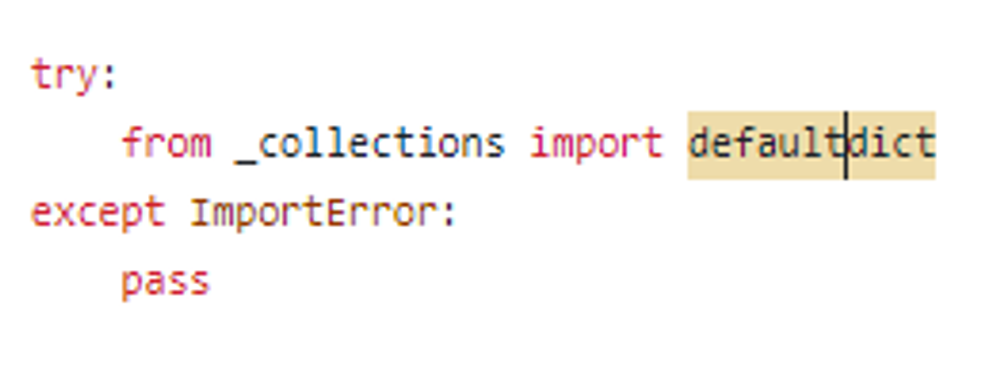
ctrl+f 로 아무리 찾아도 def defaultdict 같은건 보이지 않고,
defaultdict 가 _collections 밑에 정의되어있다고 하는 try 문도 찾았는데
_collections 라는 파일이나 폴더도 못찾겠습니다.
제가 뭘 놓치고 있는걸까요?
답변
cpython/Modules/Setup.bootstrap.in 파일을 보시면 _collections _collectionsmodule.c라는 내용을 통해 _collections에 대한 내용은 _collectionsmodule.c 파일에 구현되어 있음을 확인할 수 있습니다. 실제로 해당 파일에는 deque, dict자료구조 등이 구현되어 있음을 확인할 수 있습니다.