★Substring with Concatenation of All Words★
https://leetcode.com/problems/substring-with-concatenation-of-all-words/description/
★다시 풀어봐야할 문제★ (못풀고 해설봄)
문제풀이, 해설이해까지 총 3시간 소요
문제 파악 [필수 작성]
문제이해
words 에 있는 모든 word의 순열조합의 시작 인덱스를 찾아서 반환하는 문제
제한 조건 확인
s의 길이는 최소 1 ~ 최대 10^4 -> 무조건 O(n) 만에 풀어라
word 갯수는 최대 5000번
word의 길이는 최대 30
영소문자
아이디어
순열조합의 길이는 무조건 단어갯수x단어길이 와 같아야한다.
words 로 만들수있는 permutation set 을 만든다
갯수만 일치하는지 확인하면 된다. 순서는 어차피 중요하지 않다.
words 를 갯수해시맵에 매핑시킨다.
슬라이더를 활용해 단어단위로 조회한다.
갯수햇시맵의 원소값들이 모두 0이 될 때까지(모든단어가포함될때까지)
계속 슬라이더를 늘리고 줄이고를 반복하다가 만족되는 순간이 발견되면
스타트 인덱스를 저장한다.
값을 중첩하면 안되기때문에 큐를 활용해서 해야할것같다.
큐에 삽입가능한 값은,
words_dict 에 있는 값이면서 카운트가 0 이상인 값들이다.
이때, 큐의 길이와 words의 길이가 같다는것은 words의 모든 단어가 포함되었다는 뜻이다.
s에 단어가 없을때까지 진행한다.
큐에 (단어,스타트인덱스) 페어로 한개씩 넣는다.
만약 삽입한 단어가 words_dict 에 키값이 없으면,
현재 큐에 있는 값들을 다 빼고 다음 단어부터 다시 시작한다.
만약 삽입한 단어가 count가 부족하다면,
방금 삽입한 거만 제외하고 현재 큐에있는 값들을 다뺀다.
만약 정상삽입 되었다면,
큐길이와 words길이를 비교한다.
만약 같다면,
큐에서 하나 팝한후 스타트인덱스를 저장한다.
시간복잡도
O(N)
자료구조
(word,스타트인덱스) 구성의 deque s
words_count_dict
deque
접근 방법 [필수 작성]
코드 구현 [필수 작성]
1차 시도
제출 버튼 눌렀는데 21번 테케에서 Fail
→ 코너케이스 찾는중
from collections import deque
from collections import Counter
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
result = []
word_len = len(words[0])
remain_q = deque([])
origin_word_count_dict = Counter(words)
tmp_word_count_dict = Counter(words)
tmp_q = deque([])
for start_idx in range(0,len(s),3):
remain_q.append((s[start_idx:start_idx+3],start_idx))
while remain_q:
#print("remain_q:",remain_q)
#print("tmp_q:",(tmp_q))
#print("tmp_word_count_dict:",tmp_word_count_dict)
#print("-------------------")
tmp = remain_q.popleft()
tmp_q.append(tmp)
if tmp[0] not in tmp_word_count_dict:
tmp_q = deque([])
elif tmp_word_count_dict[tmp[0]] == 0:
tmp_q = deque([tmp])
tmp_word_count_dict = origin_word_count_dict
tmp_word_count_dict[tmp[0]] -= 1
else:
tmp_word_count_dict[tmp[0]] -= 1
if len(tmp_q) == len(words):
head_tuple = tmp_q.popleft()
result.append(head_tuple[1])
tmp_word_count_dict[head_tuple[0]] += 1
return result2차 시도
1차시도의 반례
s = good word best good word
words = good word best word
아래 부분을 변경(while 문 안의 if 와 elif 문)
if tmp[0] not in tmp_word_count_dict:
tmp_q = deque([])
tmp_word_count_dict = origin_word_count_dict
elif tmp_word_count_dict[tmp[0]] == 0:
while True:
poped = tmp_q.popleft()
if poped[0] == tmp[0]:
break
else:
tmp_word_count_dict[poped[0]] += 1from collections import deque
from collections import Counter
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
result = []
word_len = len(words[0])
remain_q = deque([])
origin_word_count_dict = Counter(words)
tmp_word_count_dict = Counter(words)
tmp_q = deque([])
for start_idx in range(0,len(s),3):
remain_q.append((s[start_idx:start_idx+3],start_idx))
while remain_q:
print("remain_q:",remain_q)
print("tmp_q:",(tmp_q))
print("tmp_word_count_dict:",tmp_word_count_dict)
print("-------------------")
tmp = remain_q.popleft()
tmp_q.append(tmp)
if tmp[0] not in tmp_word_count_dict:
tmp_q = deque([])
tmp_word_count_dict = origin_word_count_dict
elif tmp_word_count_dict[tmp[0]] == 0:
while True:
poped = tmp_q.popleft()
if poped[0] == tmp[0]:
break
else:
tmp_word_count_dict[poped[0]] += 1
else:
tmp_word_count_dict[tmp[0]] -= 1
if len(tmp_q) == len(words):
head_tuple = tmp_q.popleft()
result.append(head_tuple[1])
tmp_word_count_dict[head_tuple[0]] += 1
return result3차 시도
이번에는 19번 테스트에서 Fail
원래 통과할 수 있었테케가 갑자기 틀린다?
아래 3 을 → word_len 로 변경 (일반화)
→ 그래도 79번 케이스에서 Fail
→ 또 다른 코너케이스가 있는듯
for start_idx in range(0,len(s),3):
remain_q.append((s[start_idx:start_idx+3],start_idx))from collections import deque
from collections import Counter
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
result = []
word_len = len(words[0])
remain_q = deque([])
origin_word_count_dict = Counter(words)
tmp_word_count_dict = Counter(words)
tmp_q = deque([])
for start_idx in range(0,len(s),word_len):
remain_q.append((s[start_idx:start_idx+word_len],start_idx))
while remain_q:
print("remain_q:",remain_q)
print("tmp_q:",(tmp_q))
print("tmp_word_count_dict:",tmp_word_count_dict)
print("-------------------")
tmp = remain_q.popleft()
tmp_q.append(tmp)
if tmp[0] not in tmp_word_count_dict:
tmp_q = deque([])
tmp_word_count_dict = origin_word_count_dict
elif tmp_word_count_dict[tmp[0]] == 0:
while True:
poped = tmp_q.popleft()
if poped[0] == tmp[0]:
break
else:
tmp_word_count_dict[poped[0]] += 1
else:
tmp_word_count_dict[tmp[0]] -= 1
if len(tmp_q) == len(words):
head_tuple = tmp_q.popleft()
result.append(head_tuple[1])
tmp_word_count_dict[head_tuple[0]] += 1
return result4차 시도
직관적 이해가 쉽게 코드의 구조를 변경
→76번케이스에서 Fail
→ 원래 통과되던 거에서도 실패
→ 전체 소요시간 1시간 Over
→ 코너케이스 확인
→ 문제이해를 잘못한 것으로 확인
→ s에 들어올 수 있는 문자열은 반드시 word 의 길이만큼 분리되는 것이 아님.
→ 따라서 코드 로직 자체를 바꿔야함.
from collections import deque
from collections import Counter
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
result = []
word_len = len(words[0])
remain_q = deque([])
origin_word_count_dict = Counter(words)
tmp_word_count_dict = Counter(words)
tmp_q = deque([])
for start_idx in range(0,len(s),word_len):
remain_q.append((s[start_idx:start_idx+word_len],start_idx))
while remain_q:
print("remain_q:",remain_q)
print("tmp_q:",(tmp_q))
print("tmp_word_count_dict:",tmp_word_count_dict)
print("-------------------")
tmp = remain_q.popleft()
tmp_q.append(tmp)
if tmp[0] not in tmp_word_count_dict:
tmp_q = deque([])
tmp_word_count_dict = origin_word_count_dict
tmp_word_count_dict[tmp[0]] -= 1
if tmp_word_count_dict[tmp[0]] == -1:
while tmp_q:
poped = tmp_q.popleft()
tmp_word_count_dict[poped[0]] += 1
if poped[0] == tmp[0]:
break
if len(tmp_q) == len(words):
poped = tmp_q.popleft()
result.append(poped[1])
tmp_word_count_dict[poped[0]] += 1
return result5차 시도
아이디어 다 갈아엎고 처음부터 다시시작
→ 178번 테케에서 시간초과
→ O(n^2) 시간복잡도를 줄일 방법이 떠오르지 않음.
→ 문제 해설 검색
→ 해설 이해 (1시간소요)
'''
수도코드
s의 첫글자부터 한단어길이만큼 슬라이딩 탐색
만약 슬라이딩 탐색중 해당 단어가 words dict에 있으면
또 그다음 4개 탐색 시작
그런식으로 해서 연속되게 다 있는게 확인되면 첫 슬라이딩 시작 위치를 result에 저장
만약 하나라도 어긋나면 그 다음 슬라이딩 시작
슬라이딩은 0 ~ len(s)-word_len 까지 진행
자료구조
word_len
origin_words_remain_counter
tmp_words_remain_counter
tmp_q
'''
import copy
from collections import deque
from collections import Counter
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
word_len = len(words[0])
origin_words_remain_counter = Counter(words)
result = []
for start in range(len(s)-word_len+1):
tmp_search_word = s[start:start+word_len]
#print("start:",start)
#print("tmp_search_word:",tmp_search_word)
#print("------------------------------------")
if tmp_search_word in origin_words_remain_counter:
#print("!!!!!!!!!!!!!!Search Start!!!!!!!!!!!!")
tmp_q = deque([])
tmp_words_remain_counter = copy.deepcopy(origin_words_remain_counter)
pointer = start
tmp_q.append(tmp_search_word)
tmp_words_remain_counter[tmp_search_word] -= 1
while pointer < len(s)-word_len+1:
#print("tmp_q:",tmp_q)
#print("tmp_words_remain_counter:",tmp_words_remain_counter)
if len(tmp_q) == len(words):
result.append(start)
break
pointer += word_len
tmp_search_word = s[pointer:pointer+word_len]
#print("tmp_search_word:",tmp_search_word)
if tmp_search_word in tmp_words_remain_counter \
and tmp_words_remain_counter[tmp_search_word] > 0:
tmp_q.append(tmp_search_word)
tmp_words_remain_counter[tmp_search_word] -= 1
else:
break
return result
시간복잡도 Fail
읽고 이해한 해설글 링크
https://velog.io/@relighting123/Two-Pointer-문제-LEETCODE.115.-Distinct-Subsequences
해설글 코드
from collections import Counter
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
word_count = Counter(words)
word_len, num_words = len(words[0]), len(words)
total_len = word_len * num_words
ans = []
for i in range(word_len):
left, right = i, i
current_count = Counter()
while right + word_len <= len(s):
word = s[right:right + word_len]
current_count[word] += 1
right += word_len
while current_count[word] > word_count[word]:
current_count[s[left:left + word_len]] -= 1
left += word_len
if right - left == total_len:
ans.append(left)
return ans6차시도
카운터를 재사용하는 방식으로 다시 구현하였습니다.
테스트는 통과하였으나, 여전히 연산시간의 비효율이 발생하는 것으로 보입니다.
그러나 ★Minimum Window Substring★ 문제와 동일하게 어느부분을 포커스를 두고 최적화를 진행해야할지 모르겠습니다.
import copy
from collections import deque
from collections import Counter
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
word_len = len(words[0])
origin_words_remain_counter = Counter(words)
result = []
for start in range(word_len):
tmp_q = deque([])
tmp_words_remain_counter = copy.deepcopy(origin_words_remain_counter)
pointer = start
while pointer < len(s)-word_len+1:
#print("tmp_q:",tmp_q)
tmp_search_word = s[pointer:pointer+word_len]
if tmp_search_word in tmp_words_remain_counter \
and tmp_words_remain_counter[tmp_search_word] > 0:
tmp_q.append(tmp_search_word)
tmp_words_remain_counter[tmp_search_word] -= 1
elif tmp_search_word not in tmp_words_remain_counter:
tmp_q = deque([])
tmp_words_remain_counter = copy.deepcopy(origin_words_remain_counter)
start = pointer+word_len
elif tmp_words_remain_counter[tmp_search_word] == 0:
tmp_q.append(tmp_search_word)
tmp_words_remain_counter[tmp_search_word] -= 1
while tmp_q and tmp_words_remain_counter[tmp_search_word] < 0:
poped = tmp_q.popleft()
tmp_words_remain_counter[poped] += 1
start += word_len
if len(tmp_q) == len(words):
result.append(start)
poped = tmp_q.popleft()
tmp_words_remain_counter[poped] += 1
start += word_len
pointer += word_len
return result
배우게 된 점 [필수 작성]
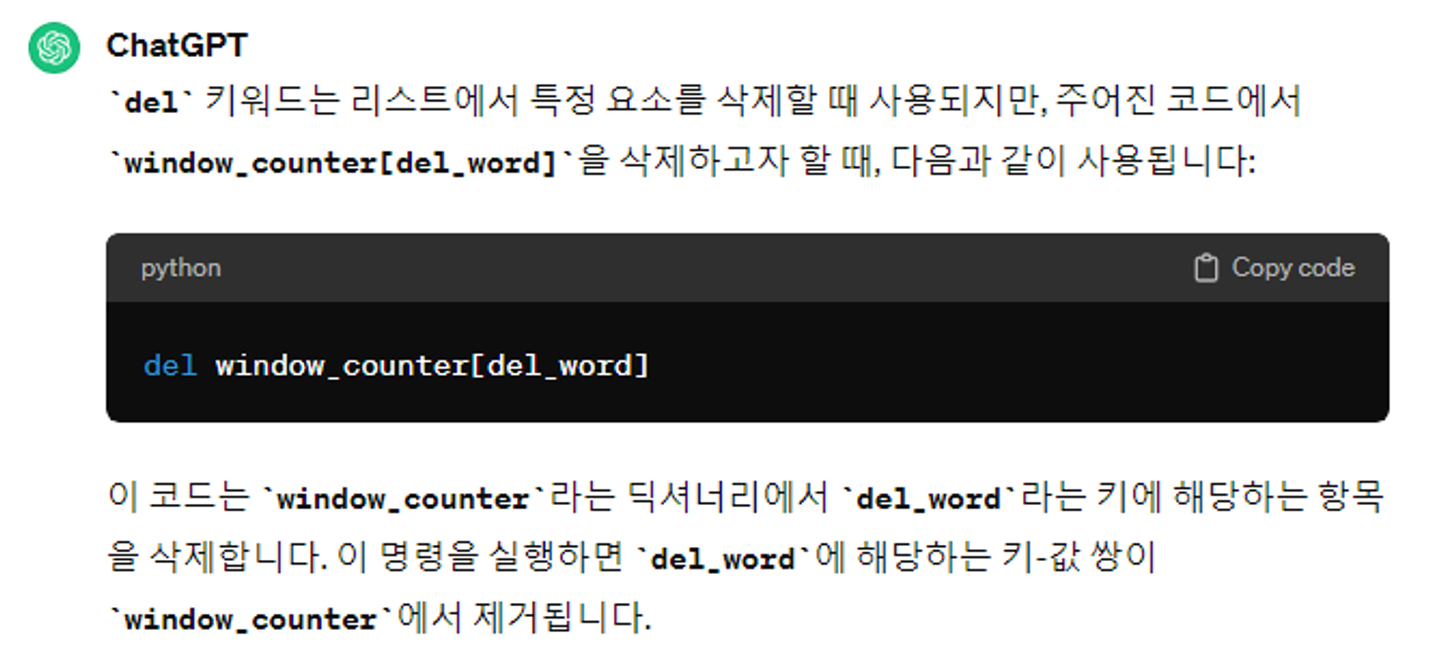
킬캠 해설코드 리뷰
del window_counter[del_word]
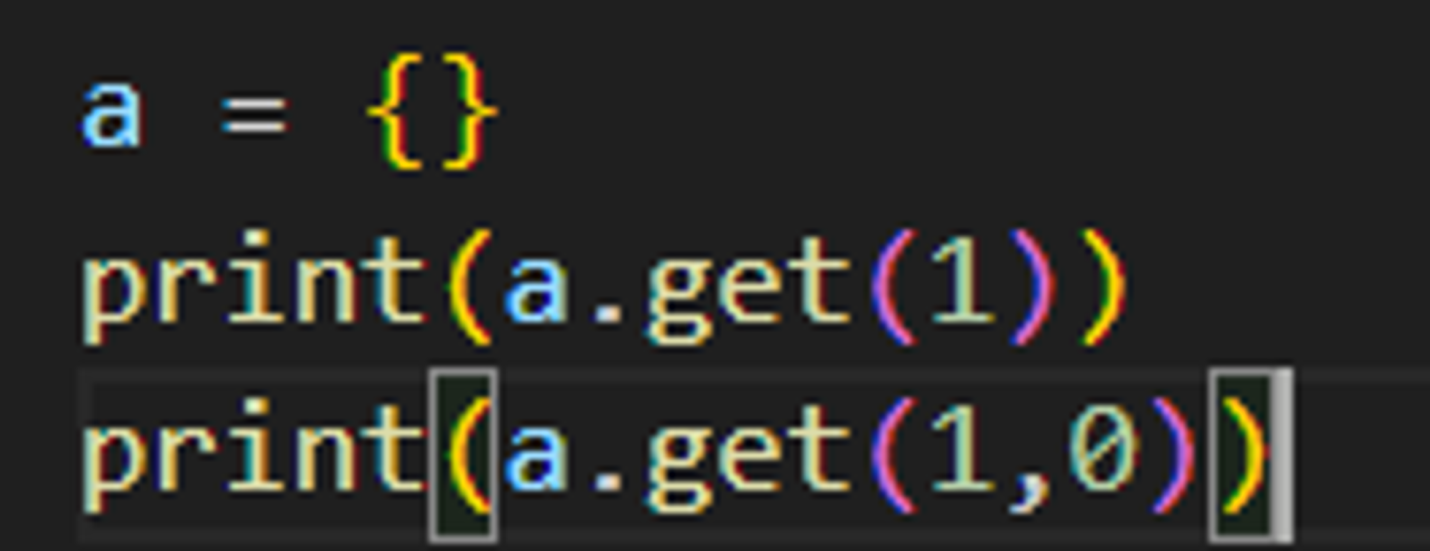
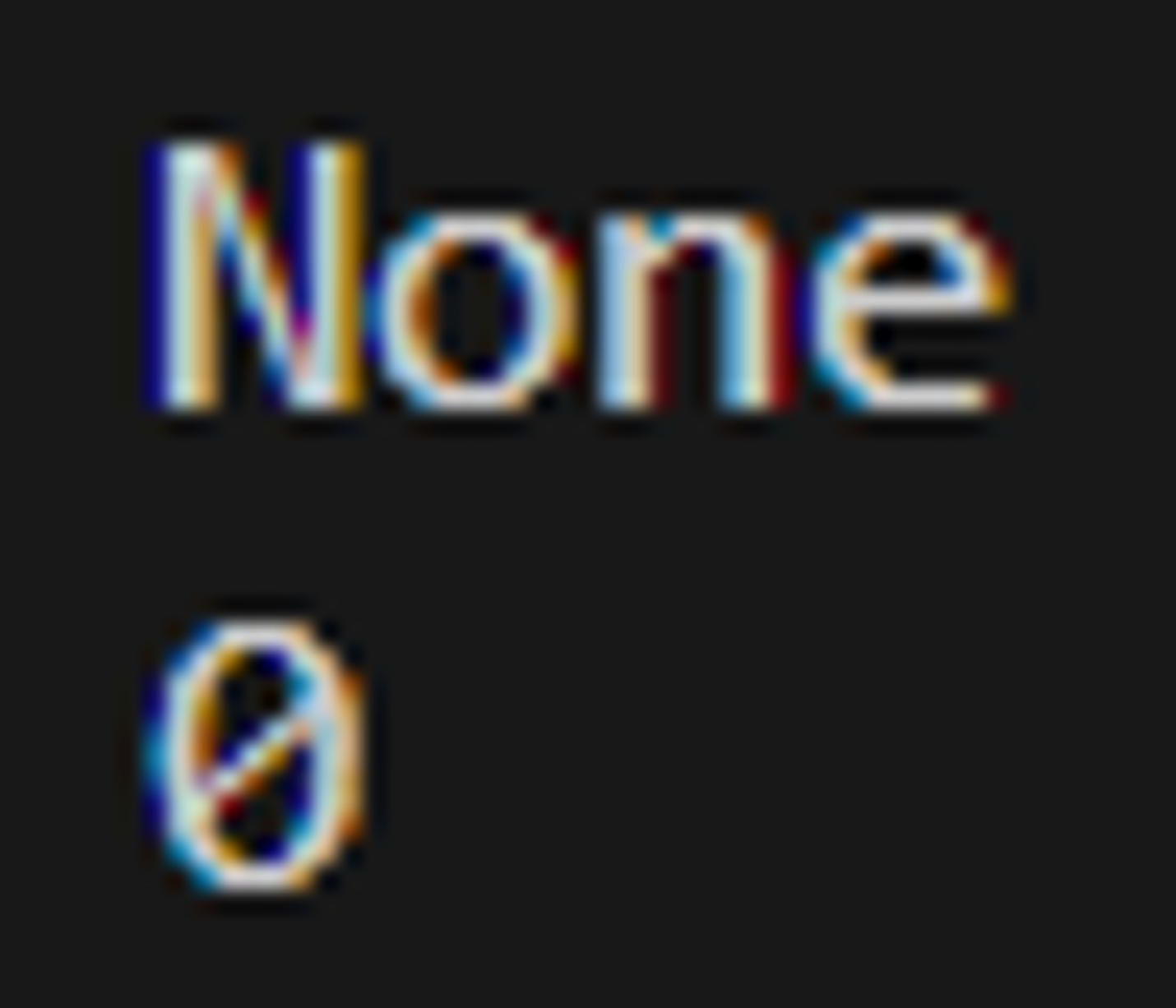
dict.get()
dict.get() 메서드를 활용하여 키 에러를 방지할 수 있다.
a.get(키값,없을때리턴값)

Counter를 활용한 부등호연산과 의도치 않은 오류
???
질문 [ 필수 X ]
Q1.
위 코드는 시간복잡도가 O(n) 이고 제 코드는 시간복잡도가 O(n^2) 인것 같은데 제 생각이 맞나요?
Q2.
제 코드도 첫 단어가 일치하는게 발견이 되면, word_len 만큼 이동하게 구현하였는데, 정확히 어떤 부분이 반복되고 있어서 시간초과가 나는 것인지 정확하게 모르겠습니다.
substring 을 매번 새롭게 다시 쌓아나가기때문에 그런것 같은데
제 코드의
if len(tmp_q) == len(words):
result.append(start)
break이 부분을 앞에거를 지우고 뒤에꺼를 이어붙여나가는 식으로 구현하면 시간초과가 해결이 될까요?
Q3 (추가질문)
최적화가 어렵습니다.
→ 답변이해: 즉, words 의 갯수가 5000처럼 클때는 words 갯수를 아예 처음부터 다시 다 새로 복사해오는데 오래걸린다는 의미. 그냥 한 3개 잘못됐으면, 3개 다시 추가하고 하면되는건데, 5000개 다시 다 복사오기때문에 여기서 오버헤드가 발생하는 것으로 추정.
답변
- 맞습니다.
- 카운터를 재사용 할 수 있으나 한 번 답을 찾을 경우 종료해 버린 후 카운터를 재생성하기에 해당 과정에서 많은 시간 소모가 발생하게 됩니다.
- 수정된 코드입니다. 깊은 복사가 지나치게 자주 발생해 생기는 것으로 추정됩니다.
