프로젝트 소개
주제
- SoundCloud홈페이지 클론코딩
구성원
- Frontend(2), Backend(2), Native(1)
기간
- 2주(20200309 ~ 20200320)
협업
- Trello를 스크럼방식 협업
- 주단위 백로그작성
- 일단위 스탠드업미팅
- git rebase : 커밋 관리
적용 기술
- Python, Django web framework
- Git
- BeautifulSoup, Pandas
- Bcrypt
- JWT
- Google Auth api(social sign-up)
- MySQL
- AWS EC2, RDS
- Docker
- CORS headers
프로젝트 Demo
- Postman API document
- 프로젝트 영상(APP)
깃허브
나의 역할
- Modeling(ERD)
- Sign up, Sign in
- Google Social Sign up
- Mesage
- Follow
- Notification
- status bar
- User Recommendation
- Comment
- Unit Test
- 데이터베이스 관리(MySQL)
- 크롤링(bs4, pandas)
- Docker image 생성
- AWS EC2에 프로젝트 배포
- AWS RDS 구축
{kind=link}
크롤링
정해진 기간동안 많은 기능을 구현하기 위해서 음원의 메타데이터는 지니 차트100에서 크롤링해왔다. bs4와 request를 사용해서 섬네일 이미지, 음원 제목, 아티스트를 가져왔으며 음악상세페이지로 들어가는 url을 for loop을 사용해서 들어가 가사, 앨범이미지를 가져왔다.
모델링(ERD)
-
모델링은 크게 song과 user로 나뉘었다. 유저가 곡을 생산해 공유하는 사운드클라우드의 취지상 유저는 곡의 소비자이자 생산자가 된다. 그래서 user와 song은 one to many 관계에 있다. 한명의 유자가 여러곡을 가질 수 있고, 한개의 곡은 한명의 유저에게만 속하기 때문이다.
-
음원사이트의 특성상 song, playlist, album이 복잡한 관계를 가진다. 우선 song과 playlist는 many to many관계에 있고, song과 album은 one to many 관계에 있다.
-
user가 특정 song에 like를 누르고 각각의 유저는 하나의 likelist를 가진다. playlist와 album도 마찬가지이다.
그래서 song_likes, playlist_likes, album_likes와 같이 user와 song의 중간테이블을 만들어 like의 경우를 따로 관리해준다. 중간 like테이블을 통해서 각각의 playlist, song, album은 몇개의 like를 가졌는지 count할 수 있게 되고, user들로 부터 많은 like를 가진 playlist, song, album들은 메인화면에 뿌려질 수 있다. -
사운드클라우드에서 가장 의아했던 모델은 repost인데 다른 유저가 만든 playlist를 내 피드에 공유할 수 있는 기능이다. 이는 어떻게보면 playlist_like와 비슷한 기능이지만(내 피드에 들어가서 내가like한 playlist를 볼 수 있다는 점에서) 사운드클라우드에서는 따로 있는 기능으로 두었다.
-
사운드클라우드 만의 특별한 댓글기능도 있었다.

위와같이 음악을 듣다가 댓글을 달면 해당 음악의 위치에 유저가 단 댓그리 표시된다는 점이다. 그래서 comment테이블에는 song_id와 position(위치)가 같이 저장되어야 한다. -
가장 복잡하다고 느꼈던 것은 tag이다. tag는 유저가 song, playlist, album을 등록할 때 생성할 수도 있고, 원래있는 tag를 사용할 수 도 있다. 그래서 모든 tag들을 모아놓은 tag테이블을 두고, song_tag, playlist_tag, album_tag의 중간테이블을 전부 따로두었다. 그리고 song의 경우에는 등록할 때 장르를 입력하게 되어있는데 장르와 tag를 따로불류하지 않고 tag테이블에 is_genre라는 컬럼을 두어 장르를 구분하였다. 그리고 사이트의 홈에 is_genre = True인 song들을 카테고리화 하여 뿌릴 수 있게 처리했다.
기억에 남는 기능과 코드
- Sign up, Sign in
- Google Social Sign up
- Mesage
- Follow
- Notification
- status bar
- User Recommendation
- Comment
많은 앤드포인트를 만들었고, 기억에남는 기능과 코드를 리뷰 해 보겠다.
uuid를 통한 유저 프로필 접근제한
try:
validate_email(data['email'])
[0] user = User.objects.create(
email = data['email'],
password = bcrypt.hashpw(data['password'].encode('utf-8'), bcrypt.gensalt()).decode('utf-8'),
age = data['age'],
name = data['name'],
gender = data['gender'],
[1] uuid = str(uuid.uuid3(uuid.NAMESPACE_DNS, data['email']).hex)
)
token = jwt.encode({'user_id' : User.objects.get(email = data['email']).id}, SECRET_KEY, algorithm = ALGORITHM)
[2] return JsonResponse({'token' : token.decode(), 'uuid' : user.uuid}, status = 200)
[0] 생성한 User객체를 변수에 담아주어 추후에 사용 가능하도록 한다.
[1] 유저가 account를 생성할 때 마다 고유 uuid를 저장한다.
[2] 유저마다 고유 uuid를 저장하고 프로필에 접근 할 때 endpoint뒤에 path parameter로서 넣어준다.
토큰을 통해 제한된 서비스에 대한 접근권한을 주지만 프로필은 유저 고유의영역이기 때문에 uuid와 같은 고유한 값으로 유저를 식별 해 보안을 더 강화시키도록 한다.
삼항연산자를 사용한 맞팔(mutual follow)여부 확인
class StatusView(View):
@login_required
def get(self, request):
user = request.user.id
[1] follow_status = (
Follow.objects
.filter(to_follow_id = user, is_checked = False)
.select_related('from_follow', 'to_follow')
.order_by('created_at')
)
[2] if not len(list(follow_status)):
return JsonResponse({'message' : 'EMPTY_UPDATES'}, status = 400)
return_key = {
'data' :
[{'follower_name' : status.from_follow.name,
'follower_id' : status.from_follow.id,
'follower_follower_count' : status.from_follow.follow_reverse.all().count(),
'follower_song_count' : status.from_follow.song_set.all().count(),
'follower_image' : status.from_follow.profile_image,
'follow_at' : status.created_at,
'is_checked' : status.is_checked,
[3] 'mutual_follow' : True if Follow.objects.filter(from_follow_id = user, to_follow_id = status.from_follow_id) else False}
for status in follow_status]
}
Follow.objects.filter(to_follow_id = user).update(is_checked = True)
return JsonResponse(return_key, status=200)
[1] 우선 토큰을 가지고 있는 유저가 팔로우를 당한 사람, 체크되어있지 않은상태의 팔로우를 동시에 만족하는 팔로우 객체들을 전부 가져온다.
[2] 만약 업데이트 상태가 없다면(필터를 통해 걸러져 가져온 쿼리셋이 없다면) empty update 메세지를 리턴한다.
[3] 상대방이 나를 팔로우 했는데 나또한 상대방을 팔로우 하고 있는 상태라면 True를, 아니면 False를 리턴한다.
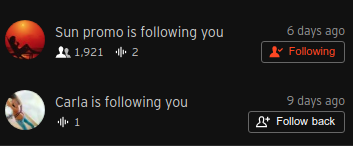
mutual_fallow가 False이면 내가 상대방을 팔로우하는 요청을 보낼 수 있는 'Follow back'이 활성화되고, 맞팔 상태이면 'Following'이라는 메세지가 활성화 되어있다.
if Follow.objects.filter(to_follow_id = data['to_follow_id']).exists():
Follow.objects.filter(to_follow_id = data['to_follow_id']).delete()
return JsonResponse({'message' : 'UNFOLLOWED'}, status = 200)
그리고 'Following'을 한번 더 클릭하면 unfollow상태가 되기 때문에 Follow 엔드포인트로 post요청이 들어가게 되고 이미 팔로우한 상태이면 해당 팔로우객체를 삭제해서 언팔로우 상태로 만든다.
딕셔너리 자료구조의 특징을 이용한 중복제거
파이썬의 딕셔너리 자료형은 key와 value로 이루어져 있고 key를 해시화 해서 메모리상 주소로 가지고 value를 key와 연결하여 저장시킨다. 해시화된 key는 중복된 값을 가질 수 없기 때문에 같은 key가 메모리상 들어오면 이후에 들어온 딕셔너리 객체로 대체된다.
이 딕셔너리 자료형의 특징을 이용하여 진행중인 사운드클라우드 클론 프로젝트에서 나의 대화기록을 불러 올 때 Message객체의 중복값을 제거해보자.
우선 메세지 객체를 전부 불러오자
>>> message_chunk = Message.objects.filter(Q(from_user_id = 1)|Q(to_user_id = 1)).order_by('created_at')
>>> message_chunk
<QuerySet [<Message: Message object (1)>, <Message: Message object (2)>, <Message: Message object (3)>, <Message: Message object (4)>, <Message: Message object (5)>, <Message: Message object (6)>, <Message: Message object (7)>, <Message: Message object (8)>, <Message: Message object (23)>, <Message: Message object (24)>, <Message: Message object (25)>, <Message: Message object (26)>, <Message: Message object (27)>, <Message: Message object (28)>, <Message: Message object (29)>, <Message: Message object (30)>, <Message: Message object (31)>, <Message: Message object (32)>, <Message: Message object (33)>, <Message: Message object (34)>, '...(remaining elements truncated)...']>
내가 id가 1번인 유저라고 가정했을 때, 내가 발신자가 된 메세지(from_user_id=1), 내가 수신자가 된 메세지(to_user_id)의 객체를 Q|Q를 사용하여 전부 가져온다.
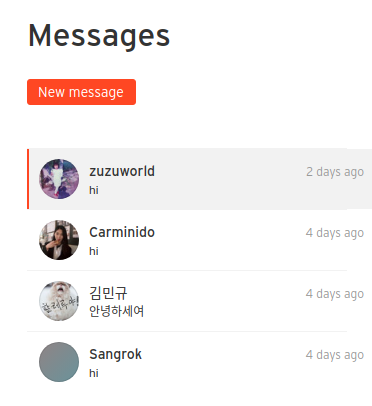
하지만 여기서 필요한 것은 그림과같이 내가 한 유저와 주고받은 메세지의 chunk가 하나의 객체가 되는 것이다. 즉, 나와 대화한 상대방을 한 메세지 chunk로 하고 그것을 리스트화 해야한다. 그래서 내가 대화한 상대방과의 메세지를 수신인기준으로 중복을 제거 해 줄 필요가 있다.
여기서 중복제거를 하기전에 일단 필요한 value들을 가져오자.
>>> datas=[{'to_user_id' : message.to_user_id, 'from_user_id' : message.from_user_id, 'last_message' : message.content, 'last_message_time' : message.created_at} for message in message_chunk]
>>> datas
[{'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 8, 51, 24, 133097, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 8, 52, 14, 234454, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 8, 58, 4, 335098, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 3, 14, 720437, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 4, 8, 28525, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 4, 36, 846351, tzinfo=<UTC>)}, {'to_user_id': 4, 'from_user_id': 1, 'last_message': 'good', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 9, 23, 417197, tzinfo=<UTC>)}, {'to_user_id': 5, 'from_user_id': 1, 'last_message': 'not bad' .............위와같이 수신인이 1번유저, 발신인이 1유저인 경우의 메세지 객체들을 전부 가져왔다. 이제 to_user_id를 기준으로 to_user_id가 같은 객체는 중복으로 치부하고 중복제거를 해보자.
message_all = list({data['to_user_id'] : data for data in datas}.values())- 결국 중복이 되는것은 dictionary의 value값이다 그래서 dictionary의 value값을 key로하고, dictionary객체 자체를 value로 둔다.
- datas리스트를 for loop에 넣어준다.
>>> message_all = {data['to_user_id'] : data for data in datas}
>>> message_all
{3: {'to_user_id': 3, 'from_user_id': 1, 'last_message': None, 'last_message_time': datetime.datetime(2020, 3, 19, 13, 45, 17, 679253, tzinfo=<UTC>)}, 4: {'to_user_id': 4, 'from_user_id': 1, 'last_message': 'good', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 9, 23, 417197, tzinfo=<UTC>)}, 5: {'to_user_id': 5, 'from_user_id': 1, 'last_message': 'oh also this is my new track', 'last_message_time': datetime.datetime(2020, 3, 16, 11, 46, 4, 365650, tzinfo=<UTC>)}, 1: {'to_user_id': 1, 'from_user_id': 117, 'last_message': '???', 'last_message_time': datetime.datetime(2020, 3, 21, 8, 7, 2, 631564, tzinfo=<UTC>)}, 117: {'to_user_id': 117, 'from_user_id': 1, 'last_message': '굿', 'last_message_time': datetime.datetime(2020, 3, 19, 18, 22, 41, 451767, tzinfo=<UTC>)}, 17: {'to_user_id': 17, 'from_user_id': 1, 'last_message': 'what the?', 'last_message_time': datetime.datetime(2020, 3, 16, 14, 15, 15, 676776, tzinfo=<UTC>)}, 29: {'to_user_id': 29, 'from_user_id': 1, 'last_message': 'how are you', 'last_message_time': datetime.datetime(2020, 3, 19, 13, 56, 34, 160223, tzinfo=<UTC>)}}
message_all을 values()없이 dictionary그자체로 찍어보면, 위와같이 values가 key가 되고 dictionary값 자체가 values가 되었다.
- values()를 통해서 키값은 버리고 dictionary객체 그자체만(여기서는 value) 가져온다.
스스로에 대한 피드백
잘한점
- Git에 대한 이해도가 1차 프로젝트 때 보다는 생겨서 충돌발생을 줄이려고 노력 한 점이다. 처음에 모델링을 크게 user와 song으로 나누고 user부분을 담당했지만, SoundCloud의 특성상 유저가 음악의 생산자가 되기 때문에 거의 모든부분이 many to many 관계에 있었다. 그래서 서로의 song을 맡은 팀원도, user은 맞은 나도 서로의 모델링이 필요한 상황이었다. 그래서 풀을 당길 때 서로 충돌이 많이 일어날 가능성을 감안하여 many to many관계에 있는 모델들은 앱을 따로 만들어 주거나, import를 하지않고 path를 사용한 foreignkey참조를 만들어주는 등, 충돌을 피하기 위해 노력했다.
- Git rebase에 대해 배우고 실재로 push를 하기전 모든 커밋을 하나로 합쳐 커밋 기록을 정리 한 점이다. 복잡하고 많은 커밋기록을 한층 더 관리하기 편해졌다.
- 1차 프로젝트 때 프론트앤드와의 소통의 중요성을 깨닫고 많은 시간을 소통에 썼다. 코드를 치기 전 전체적인 기능, 만들 API에 대해 논의하고 api가 나오면 붙혀보는 것 부터 시작했다. 그 결과 내가 만든 api가 어떻게 프론트앤드 쪽에서 활용되는지 더 깊게 알 수 있었다.
아쉬운점
- migrate의 신중함에 대해 간과 한 점이다. migrate로 데이터베이스의 구조가 한번 잡히면 수정이 힘들다는 것이다. 내가 작업한 user 모델을 푸시해서 remote master에 반영되어서 내 동료가 pull을 당기고 migrate를 해서 데이터베이스의 구조가 만들어지고 이미 수많은 데이터가 들어간 상태였다. 이후 내가 모델을 수정할 일이 있어서 몇가지 수정을 하고 다시 remote에 push를 했다. 그리고 내 push가 반영된 remote를 pull하고 migrate를 했는데 데이터베이스가 변경되어서 migrate가 되지 않았다. 결국 데이터베이스를 dump하고 새로운 데이터베이스를 만들어서 데이터를 옮긴 이후, raw query로 데이터베이스 구조를 바뀐데로 다시 잡아줘야 하는 번거로움이 있었다.
- view를 만들기 전에 기능의 전체적인 그림에 대한 설계가 부족했 던 것 같다. 예를 들어 팔로우 기능의 경우 유저를 팔로우하고(POST), 내가 팔로우한 상대방을 보는 것(GET) 뿐만아니고 로그인을 했을때 header에 뜨는 notification, 상대방이 나를 팔로우 했을 때 사용되는 follow status view와 같이 팔로우와 연관된 많은 기능들을 생각히자 않고 단순히 follow view만 만들었기 때문에 나중에 프론트앤드와 연결을 하면서 새로운 필드를 추가하는일이 생기게 되었다.
개선방법
- 데이터베이스의 구조를 바꾸는 것은 안에있는 데이터의 손실을 감안해야 하기 때문에 큰 실수라는 것을 깨닫고초반 모델링과 기술의 설계에 최대한 많은 시간을 투자해서 전체적인 그림을 확실하게 그리고 모델링을 데이터베이스에 반영해야 한다고 생각했다. 그리고 이미 데이터베이스의 구조가 만들어졌다면 데이터를 넣기 전에 기능과 모델에 대해서 한 번 더 생각해 추후 변경이 없을 것이라는 어느정도 확신을 가지고 데이터를 넣어야 할 것 이다.
- django orm에서 지원되는 다양한 쿼리를 찾아서 활용해보지 못한 점이다. 이번에 쿼리를 통해서 해당되는 모든 데이터를 가져와서 if문을 통해서 걸려줬다면, django orm 쿼리문 자체에서 조건을 걸어 필터가 되는 쿼리를 사용해 가져올 때 부터 걸러서 가져와 코드의 효율을 높히도록 해야겠다.
느낀점
기능이 작동하는 것 뿐만 아닌 코드를 줄이고, 로직을 간단하게 만들기 위해서 노력했고, 복잡한 로직에 대해 어떻게 접근을 해야할지에 대한 자신감이 생겼다는 점에서 1차 프로젝트보다 성장했다고 느꼈다.
이번에도 가장 크게 느낀것은 프론트앤드와의 협업이다. 협업의 차원을 넘어서서 프론트앤드가 api호출을 통해 받은 데이터를 어떻게 처리하는지 어느정도 알고 있어야 기능이 작동하는 큰 그림을 이해 할 수 있다고 생각했고 프론트앤드와 웹의 전반적인 지식을 더 키워야 겠다.
