파이썬의 딕셔너리 자료형은 key와 value로 이루어져 있고 key를 해시화 해서 메모리상 주소로 가지고 value를 key와 연결하여 저장시킨다. 해시화된 key는 중복된 값을 가질 수 없기 때문에 같은 key가 메모리상 들어오면 이후에 들어온 딕셔너리 객체로 대체된다.
이 딕셔너리 자료형의 특징을 이용하여 진행중인 사운드클라우드 클론 프로젝트에서 나의 대화기록을 불러 올 때 Message객체의 중복값을 제거해보자.
우선 메세지 객체를 전부 불러오자
>>> message_chunk = Message.objects.filter(Q(from_user_id = 1)|Q(to_user_id = 1)).order_by('created_at')
>>> message_chunk
<QuerySet [<Message: Message object (1)>, <Message: Message object (2)>, <Message: Message object (3)>, <Message: Message object (4)>, <Message: Message object (5)>, <Message: Message object (6)>, <Message: Message object (7)>, <Message: Message object (8)>, <Message: Message object (23)>, <Message: Message object (24)>, <Message: Message object (25)>, <Message: Message object (26)>, <Message: Message object (27)>, <Message: Message object (28)>, <Message: Message object (29)>, <Message: Message object (30)>, <Message: Message object (31)>, <Message: Message object (32)>, <Message: Message object (33)>, <Message: Message object (34)>, '...(remaining elements truncated)...']>
내가 id가 1번인 유저라고 가정했을 때, 내가 발신자가 된 메세지(from_user_id=1), 내가 수신자가 된 메세지(to_user_id)의 객체를 Q|Q를 사용하여 전부 가져온다.
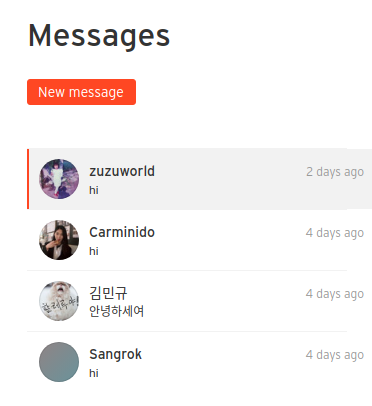
하지만 여기서 필요한 것은 그림과같이 내가 한 유저와 주고받은 메세지의 chunk가 하나의 객체가 되는 것이다. 즉, 나와 대화한 상대방을 한 메세지 chunk로 하고 그것을 리스트화 해야한다. 그래서 내가 대화한 상대방과의 메세지를 수신인기준으로 중복을 제거 해 줄 필요가 있다.
여기서 중복제거를 하기전에 일단 필요한 value들을 가져오자.
>>> datas=[{'to_user_id' : message.to_user_id, 'from_user_id' : message.from_user_id, 'last_message' : message.content, 'last_message_time' : message.created_at} for message in message_chunk]
>>> datas
[{'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 8, 51, 24, 133097, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 8, 52, 14, 234454, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 8, 58, 4, 335098, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 3, 14, 720437, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 4, 8, 28525, tzinfo=<UTC>)}, {'to_user_id': 3, 'from_user_id': 1, 'last_message': 'hi', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 4, 36, 846351, tzinfo=<UTC>)}, {'to_user_id': 4, 'from_user_id': 1, 'last_message': 'good', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 9, 23, 417197, tzinfo=<UTC>)}, {'to_user_id': 5, 'from_user_id': 1, 'last_message': 'not bad' .............위와같이 수신인이 1번유저, 발신인이 1유저인 경우의 메세지 객체들을 전부 가져왔다. 이제 to_user_id를 기준으로 to_user_id가 같은 객체는 중복으로 치부하고 중복제거를 해보자.
message_all = list({data['to_user_id'] : data for data in datas}.values())- 결국 중복이 되는것은 dictionary의 value값이다 그래서 dictionary의 value값을 key로하고, dictionary객체 자체를 value로 둔다.
- datas리스트를 for loop에 넣어준다.
>>> message_all = {data['to_user_id'] : data for data in datas}
>>> message_all
{3: {'to_user_id': 3, 'from_user_id': 1, 'last_message': None, 'last_message_time': datetime.datetime(2020, 3, 19, 13, 45, 17, 679253, tzinfo=<UTC>)}, 4: {'to_user_id': 4, 'from_user_id': 1, 'last_message': 'good', 'last_message_time': datetime.datetime(2020, 3, 15, 9, 9, 23, 417197, tzinfo=<UTC>)}, 5: {'to_user_id': 5, 'from_user_id': 1, 'last_message': 'oh also this is my new track', 'last_message_time': datetime.datetime(2020, 3, 16, 11, 46, 4, 365650, tzinfo=<UTC>)}, 1: {'to_user_id': 1, 'from_user_id': 117, 'last_message': '???', 'last_message_time': datetime.datetime(2020, 3, 21, 8, 7, 2, 631564, tzinfo=<UTC>)}, 117: {'to_user_id': 117, 'from_user_id': 1, 'last_message': '굿', 'last_message_time': datetime.datetime(2020, 3, 19, 18, 22, 41, 451767, tzinfo=<UTC>)}, 17: {'to_user_id': 17, 'from_user_id': 1, 'last_message': 'what the?', 'last_message_time': datetime.datetime(2020, 3, 16, 14, 15, 15, 676776, tzinfo=<UTC>)}, 29: {'to_user_id': 29, 'from_user_id': 1, 'last_message': 'how are you', 'last_message_time': datetime.datetime(2020, 3, 19, 13, 56, 34, 160223, tzinfo=<UTC>)}}
message_all을 values()없이 dictionary그자체로 찍어보면, 위와같이 values가 key가 되고 dictionary값 자체가 values가 되었다.
- values()를 통해서 키값은 버리고 dictionary객체 그자체만(여기서는 value) 가져온다.
