
좋아요 수를 조회해서 같이 조회하는 쿼리를 작성하면서 최적화하는 과정을 기록하고자 한다.
현재는 join을 통해 좋아요 row수를 세서 넣어주는 방식을 사용하였다.
결론에 한번 더 작성하겠지만, 이 방법은 더 좋은 방법으로 조만간 대체해야겠다. 응답시간이 너무 길다.
초기 좋아요 수 쿼리
explain select t.id, name, start_date, end_date, location, user_id, s.like_count as like_count
from trip t
join
(select count(id) as like_count, trip_id
from trip_like
where user_id = :userId
and trip_id > :cursorId
group by trip_id
order by trip_id) s
on t.id = s.trip_id
limit :sizeexplain을 통해 실행계획을 확인해 보니 다음과 같은 문제들이 나왔다.
Using fileSort
Using temporary
Using where
이중 Using fileSort와 Using temporary은 성능에 큰 문제가 발생할 수 있다.
Using fileSort
order by를 통해 정렬을 할 때 정렬할 컬럼이 인덱스화 되어 있지 않을 경우 발생한다. 인덱스에서 정렬되어 있다면 빠르게 정렬이 가능하지만, 그렇지 않다면 FileSort를 사용한다.
File Sort는 2가지 방법이 있는데
- 드라이빙 테이블만 정렬 ("Using filesort")
- 임시 테이블을 이용한 정렬 ("Using temporary, Using filesort")
두 방식 모두 레코드가 길어질 수록 성능이 매우 저하된다. 따라서 FileSort를 사용하게 되는 경우를 피하는게 좋다.
따라서Order By를 통한 조회를 피하고 인덱스를 넣기로 결정했다. 삽입,삭제,수정이 느려질 수있으나 조회하는 일이 더 빈번하기 때문이다.
explain select t.id, name, start_date, end_date, location, user_id, s.like_count as like_count
from trip t
join
(select count(id) as like_count, trip_id
from trip_like
where user_id = :userId
and trip_id > :cursorId
group by trip_id) s
on t.id = s.trip_id
limit :sizeUsing Temporary
임시 테이블을 사용해서 연산을 해야 할 때 Using Temporary 생기게 된다. 위에서 작성한 fileSort를 수행할 때 임시 테이블을 이용해 정렬하는 경우가 있다.
또한 Group by를 사용해 그룹핑할 때도 사용된다. 나의 쿼리에서는 group by쿼리를 사용할 때 발생하는 것으로 생각된다.
이를 해결하는 방법으로는 Group By를 사용하지 않는 것이겠지만, 사용해야 한다면 그룹핑할 컬럼을 인덱스화하면 해결할 수 있다. 서브쿼리에 trip_id를 인덱스화 해서 쿼리를 수정하였다.
select t.id, name, start_date, end_date, location, user_id, count(s.trip_id) as like_count
from trip t
join
(select trip_id
from trip_like
where user_id = :userId
and trip_id > :cursorId) s
on t.id = s.trip_id
group by s.trip_id
limit :size최종 결과

커버링 인덱스까지 적용된 것을 확인할 수 있었다.
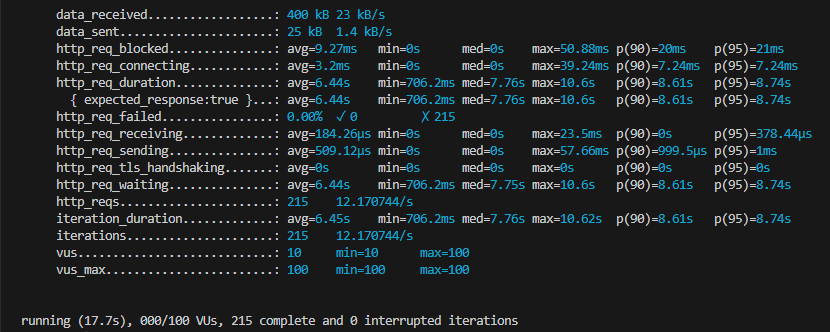
기존 쿼리보다 평균 응답시간이 절반으로 줄었지만, 여전히 응답시간이 매우 오래걸린다.
따라서 좋아요를 join을 통해 조회하는 방식은 다른 방법을 찾아봐야할 것같다.
