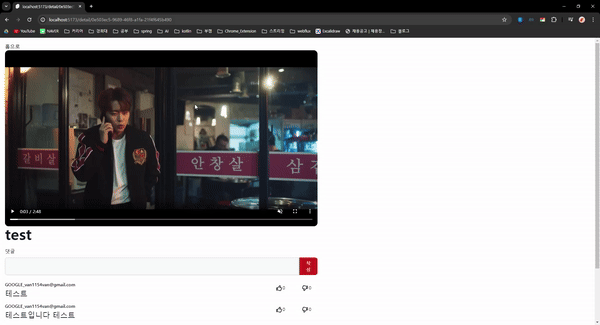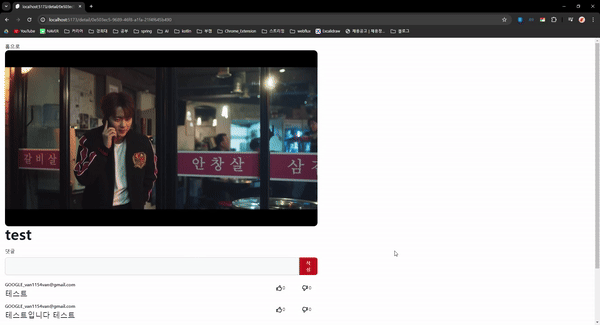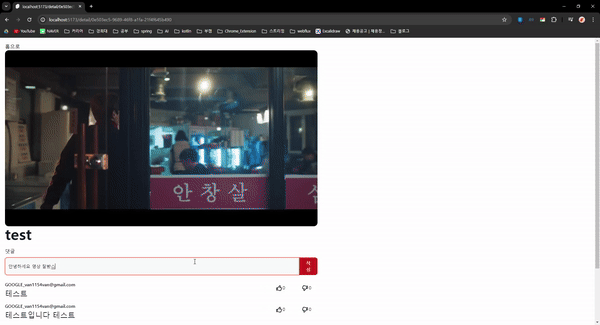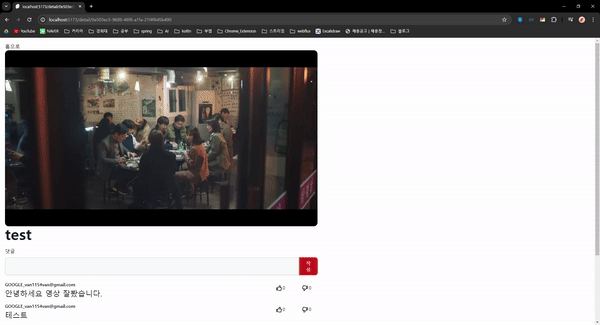
동영상 재생에 대한 구현은 이전에 마쳤으니 동영상에 댓글을 달고 좋아요와 싫어요를 누르는 기능을 구현하였다.
엔티티
data class Comment(
val message : String,
val userName : String,
val videoId: Long,
@CreatedDate
val createdDate : LocalDateTime = LocalDateTime.now(),
var good : Int = 0,
var bad : Int = 0,
@Id
val id : Long? = null
)DDL
create table comment
(
bad int null,
good int null,
id bigint auto_increment primary key,
created_date datetime(6) not null,
message varchar(255) null,
user_name varchar(255) null,
video_id bigint not null,
constraint comment_video_r2dbc_id_fk
foreign key (video_id) references video_r2dbc (id)
on update cascade on delete cascade
);
create index comment_user_name_index
on comment (user_name);R2DBC는 JPA와 달리 테이블을 자동으로 생성해주지 않아서 직접 작성하여야 한다. 너무 불편하긴 하지만 덕분에 공부를 하게 되기는 하는데 이걸 장점이라고 해야할지.. ㅋㅋㅋㅋ
Detail Service
@Service
class DetailService(
val videoRepository: VideoReadRepository,
val commentRepository: CommentReadRepository
) {
fun loadDetail(detailId : String): Mono<ResponseEntity<DetailResponse>> {
return videoRepository.findByUrl(detailId)
.flatMap {
Mono.zip(
commentRepository.findAllByVideoId(it.id!!).collectList(),
it.toMono()
)
}
.map {
ResponseEntity.ok(
DetailResponse(
videoR2dbc = it.t2,
comments = it.t1
)
)
}
.onErrorReturn(ResponseEntity.internalServerError().build())
}
}videoRepository에서 동영상정보를 commentRepository에서 댓글리스트를 불러왔다. 이때 생각한 방식이 두가지가 있었다.
생각한 두가지 방법
1. Join을 통해 동영상과 그에 대한 댓글 조회
이 방법을 제일 먼저 생각하였지만, R2DBC는 fetch join이나 연관관계 매핑을 자동으로 해주지 않기 때문에 직접 구현해주어야 해서 불편했다. 하지만 이 방법을 채택하지 않은 가장 큰 이유는 따로 있었다.
모든 댓글을 처음부터 조회할 것도 아니며, 동영상 재생이 우선이기 때문에 동영상이 재생된 후에 댓글을 천천히 불러오는 것을 구현하는 것이 사용자 경험에 훨씬 좋을 것이라고 생각했기 때문이다.
2. 동영상과 댓글에 대한 각각 조회
첫번째에서 작성한 것과 같은 이유로 join이 아닌 각각 쿼리를 날릴 수 있도록 구현하였다. 다만 아직 나의 프론트엔드 기술이 부족한 이유로 한 api에 각각의 조회를 통해 정보를 불러와서 응답하도록 하였다.
추후에 동영상 정보와 댓글 리스트 조회 api를 구분하며, 댓글은 Paging을 통해 api당 조회하는 양을 조절할 예정이다.
결과