왜 CQRS를 적용?? 🤷♂️
우리 팀은 “단일장애지점 극복”이라는 대명목하에 CQRS 패턴을 적용하기로 했다.
그렇다면 CQRS를 적용하면 어떤 부분에 있어 장단점이 있을까?
CQRS 장점
- 코드 레벨
- Command, Query 역할과 책임을 분리함
- 단일책임 원칙을 지킬 수 있음
- 리팩토링 허들을 낮출 수 있음
- Command, Query 역할과 책임을 분리함
- 아키텍처 레벨
- 성능개선
- 조회 요청과 명령 요청의 트래픽이 분산처리 되므로 더 많은 트래픽을 처리할 수 있다.
- 이는 곧 성능을 끌어올릴 수 있다는 것을 의미!
- 장애극복
Command 와 Query에 대한 DB를 분리함으로서, 한 곳이 장애가 나도 극복이 가능하다.
- 만약 Primary DB에 장애가 발생한다면
- Secondary DB를 Primary DB로 승격시켜서 장애지점을 극복할 수 있다.
- 만약 Secondary DB에 장애가 발생한다면
- Primary DB를 Secondary DB로 복제한다
- 만약 둘 다 장애가 발생한다면
- 만들어둔 백업 DB를 활용하여 롤백한다.
- 만약 Primary DB에 장애가 발생한다면
- 성능개선
어떻게 하면 구현할 수 있을까?👇
Aurora 사용 제한사항
Aurora를 쓰면 한 큐에 해결된다.
(심지어 공식문서에서조차 Aurora 써줘잉하면서 현혹한다,,,역시 장사꾼들,,,)

Aurora는 Cluster 내부에 Primary DB와 여러 Secondary DB들이 내장되어있다.
- Primary DB
- read, write 모두 가능
- 클러스터당 하나씩만 존재
- Secondary DB
- read만 가능
- 최대 15개까지 지원하고, 하나의 엔드포인트만 애플리케이션에서 연결해도 여러 Secondary DB들로 로드밸런싱을 해준다.
- Secondary DB들은 별도의 가용영역에 위치하므로, 고가용성을 유지한다.
- Primary DB가 죽어도 자동으로 Secondary DB가 승격되는 failover 기능을 가지고 있다.
하지만 결국 가장 큰 문제점에 다달렀다. 문제는 Aurora의 Cost이다.

위 그림과 같이 t3.medium 만, 그것도 하나의 노드만 사용한다는 가정하에, 계산기를 두들려도 한달에 15,16만원씩 뜯어간다.
Route53, EC2, ELB, ECR 등등 여러 영역들을 활용하고 있는 우리 팀 입장에서는 현실적으로 무리였다.
그래서 우리는 그나마 현실적인 방법을 사용하기로 하였다.
AWS RDS 활용하기
Multi-AZ

Multi-az 배포에서 mysql RDS는 자동으로 서로 다른 AZ(가용 영역)에 동기식 예비 복제본을 프로비저닝하고 유지하여 데이터 이중화를 제공한다. (HA)
- 현재 Master db 인스턴스의 snapshot이 생성.
- 생성된 snapshot을 이용하여 다른 AZ에 대기 인스턴스가 생성.
- 기본 인스턴스와 Standby 인스턴스 간에 동기식으로 복제되어 데이터 중복성, snapshot 및 백업 중 I/O 중단 제거, 시스템 백업 중 지연 시간 급증을 최소화.
Multi-AZ를 사용 시, 가장 좋은 점은 standby replica를 만들어주고, 장애복구(failover)를 지원해준다는 것이다.
Multi-AZ를 활성화 한 경우, DB 인스턴스에 중단이 발생하면 자동으로 다른 가용 영역에 있는 Standby replica(예비 복제본)으로 switch된다.
장애 조치가 완료되는데 소요되는 시간은 기본 DB 인스턴스를 사용할 수 없게 된 시점의 데이터 베이스 활동 및 기타 조건에 따라 달라지지만, 대략적으로 60~120초 정도 소요된다.
실제 실시간 서비스라면 60~120초가 굉장히 큰일이라고 생각했다.
다만, 오히려 대용량 데이터라면 데이터가 살아있는게 다행이라고 느낄 것 같다.
만약 장애가 발생한다면 메인 DB가 죽었으니 서비스를 잠시 중단하고 DB Failover 이후에 재실행시키는 게 맞다고 생각한다.
Read Replica

AWS RDS에서는 Single RDS 에 대한 Read 전용 Replication DB를 제공해준다. (물론 유료지만 말이다)
AWS RDS의 Read Replica는 Primary DB를 복제한 Secondary DB로서, Read 작업만 수행가능한 인스턴스이다.
Read Replica로의 Write 작업은 허용하지 않는다.
RDS에서 제공하는 Read Replica는 다음과 같은 특성을 갖는다.
- Read Replica를 최대 5개까지 추가할 수 있음
- 동일 AZ, Cross AZ, Cross Region 가능
- 비동기 방식의 Replication
- 짧은 시간 동안 Replica와 Master 간의 데이터 차이가 발생할 수 있음
- Read Replica를 Master DB로 변경할 수 있음(Promotion)
Single vs Multi-AZ :: 데이터 동기화 지원의 차이점
가장 큰 차이점은 바로 동기화 지원 방식이다.
Read-Replica 는 비동기식 데이터 동기화를 지원한다.
즉, 조금이라도 딜레이 발생하면 데이터 정합성이 깨져버린다.
반면, Multi-AZ 는 동기식 데이터 동기화를 지원한다.
따라서 실시간 데이터에 대한 서비싱을 처리하는 경우, Multi-AZ를 사용하는 것이 좋다.
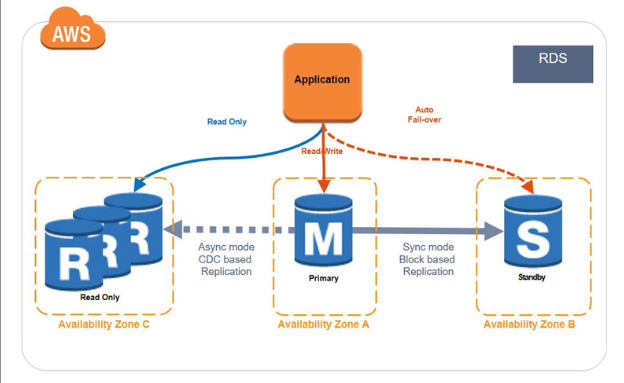
현재 우리는 Read-Replica를 채택하였다.
현재는 RDS에서 제공해주는 Read-Replica를 사용하고 있다.
조금 더 구성해보며 데이터 정합성을 위해 Multi-AZ를 사용할 예정이다.
왜냐하면 Multi-AZ 서비스 또한 무료지원이 아니기 때문이다.
또한 Async로 Replication을 지원하지만 생각보다 빠른 속도로 처리되었기 때문에
데이터 정합성의 문제가 발생하지 않아보였다
부하테스트를 돌려보며 Single Read-Replica의 한계점을 파악 후 Multi-AZ 로 마이그레이션 할 예정이다.
@Transational(readOnly) 에 따라서 Secondary DB 적용하기
자 이제 인프라 상, Primary 와 Secondary 에 대한 세팅은 완료하였다.
이제 코드 레벨로 각 Command / Query 에 따라 데이터소스를 달리해주면 된다.
근데 어떻게 할까?
@Transactional의 readOnly값에 따라서 Primary와 Secondary를 매핑시켜줄 수 있게 하였다.
다음 단계를 천천히 밟아나가보자. 모든 소스 코드는 여기를 보면 된다.
application-prod.yml 을 다음과 같이 구성해준다.
spring:
profiles:
active: prod
# DATASOURCE
datasource:
hikari:
primary:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://${DB_URL}/gream
username: ${DB_ID}
password: ${DB_PASSWORD}
secondary:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://${DB_READ_ONLY_URL}/gream
username: ${DB_ID}
password: ${DB_PASSWORD}
# JPA
jpa:
hibernate:
ddl-auto: none
properties:
hibernate:
auto_quote_keyword: true # 예약어 사용가능
globally_quoted_identifiers: true # 예약어 사용가능
show_sql: true # sql 로깅
# generate_statistics: true # 쿼리수행 통계
format_sql: true # SQL문 정렬하여 출력
highlight_sql: true # SQL문 색 부여나는 다음과 같이 ENUM 을 구성하여 READ_WRITE, READ_ONLY 로 구분해주었다.
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}이제 현재 트랜잭션이 readOnly 인지에 따라 DataSourceType 값을 매핑해주게끔 하는 헬퍼 클래스를 만들어주자.
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}이제 Config 클래스를 만들어서 DataSource 를 달리 매핑해줄 차례이다. 다음 프로세스와 같이 접근해주었다.
-
각각의 DataSource를 정의한다.
-
TransactionRoutingDataSource 값을 Key, 각각의 DataSource를 Value 인 Map 을 형성한다.
-
LazyConnectionDataSourceProxy를 사용하여 TransactionRoutingDataSource 의 값에 따라 DataSource를 달리한다.
@Configuration
public class TransactionRoutingDataSourceConfig {
@ConfigurationProperties(prefix = "spring.datasource.hikari.primary")
@Bean
public DataSource primaryDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
@ConfigurationProperties(prefix = "spring.datasource.hikari.secondary")
@Bean
public DataSource secondaryDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
@DependsOn({"primaryDataSource", "secondaryDataSource"})
@Bean
public DataSource routingDataSource(
@Qualifier("primaryDataSource") DataSource primary,
@Qualifier("secondaryDataSource") DataSource secondary) throws SQLException {
TransactionRoutingDataSource routingDataSource = new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = Map.of(
DataSourceType.READ_WRITE, primary,
DataSourceType.READ_ONLY, secondary
);
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(primary);
return routingDataSource;
}
@DependsOn({"routingDataSource"})
@Primary
@Bean
public DataSource dataSource(DataSource routingDataSource) {
return new LazyConnectionDataSourceProxy(routingDataSource);
}
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager jpaTransactionManager = new JpaTransactionManager();
jpaTransactionManager.setEntityManagerFactory(entityManagerFactory);
return jpaTransactionManager;
}
}이제 Slf4j 를 통해 log 를 사용하여 어떤 커넥션이 매핑되었는지 최종확인 해준다.
private final DataSource dataSource; // @RequiredArgs 를 통해 DI
,,,
log.info("current db url : " + dataSource.getConnection().getMetaData().getURL());CQRS 패턴에서 Command 내에서 조회를 해야한다면 ??
Service 레이어에서 CQRS를 나누자니, Command 코드 내부적으로 Query를 사용해야하는 일이 있었다
하지만 한 가지 우려되는 것이 있었다.
Command Service 내부적으로 Query 를 사용하게 되는데 이 때 DataSource 매핑이 꼬여버리면 어떻게 하지??
즉, 아래와 같은 이슈가 염려되었다.
- Command 사용한 로직 내부에서 Query를 사용하게 되는 로직을 사용하게 되면 서로 다른 DB를 사용하게 됨
- Command ⇒ Primary DB
- Query ⇒ Secondary DB
그래서 우리는 실험을 통해 이러한 염려사항을 확인해보았다.
다행히,,, 그런 일은 없었다,,,
Outer Method 레이어의 트랜잭션에 의해서 Datasource 가 꼬이는 일은 없었다!
우리는 Service Layer 에서 Command 와 Query 로 나누어 관심사에 따른 코드 분리를 하기로 하였다.
- Service Layer
- Busniess Layer
- CUD 처리(Create,Update,Delete)
- “CUD를 위한” READ 처리
- Primary DB 사용
@Transactional(readOnly = false)사용- 접근 제한은 어떻게 할 것인가??
- Query Layer
- 순수한 Read 처리
- Secondary DB 사용
@Transactional(readOnly = true)만을 사용- Command Layer에서 접근 X
- 접근 제한은 어떻게 할 것인가??
- Busniess Layer
- Repository Layer
- ReadOnlyRepository를 커스터마이징하자는 의견도 있었으나 서비스에서 Segregation 하였으므로 하지 않아도 괜찮다 판단
Creating a Read-Only Repository with Spring Data | Baeldung - Spring에서 DI해주는 SimpleJpaRepository을 사용하기로 하자
- ReadOnlyRepository를 커스터마이징하자는 의견도 있었으나 서비스에서 Segregation 하였으므로 하지 않아도 괜찮다 판단
다행히도, 가장 상위 계층의 트랜잭션이 전파됨에 따라 DataSource 매핑이 꼬여버리는 현상은 없었다.
실험을 해보니 가장 상위 계층의 트랜잭션 전파됨에 따라, DataSource 매핑 또한 상위 계층 트랜잭션에 영향을 받은 것을 볼 수 있다.
- 만약 Outer :
@Transactional, Inner :@Transactional(readOnly=true)인 경우
@Transactional로 처리됨- 예상과 달리 내부에서 Secondary를 쓰지 않음
- Query 또한 Primary에 접근하여 처리
- 반면 Outer :
@Transactional(readOnly=true)인 경우, 설정한 Config 에 따라 Secondary DB에 접근하는 것을 볼 수 있었다.
실험 코드의 예시를 짤막하게 살펴보자.
예시 코드를 간략하게 설명하자면 다음과 같다. BuyProvider 내에서는 다음과 같은 서비스가 사용된다.
- SellService
- CoupounService
- OrderService
우선 일차적으로 sellService 를 통해 판매입찰 데이터를, coupounService 를 통해 쿠폰 데이터를 조회한다. -- Query
다음으로 판매입찰 데이터와 쿠폰 데이터를 적용하여 주문을 생성하고 저장한다 -- Command
BuyController

BuyProvider

{~~Domain}QueryService 내부적으로 @Transactional(readOnly = true) 를 걸어주었기에, 우리가 설정한 LazyConnectionDataSourceProxy 에 따라 Secondary Read Only DB 에 연결될까 싶었다.
이에 따라 위 사진과 같이 log.error() 를 통해 어떤 커넥션을 매핑시키는지 보았다.
다행히도, Outer Method 가 @Transactional 이므로 Primary DB 에 연결되는 모습을 볼 수 있었다.
아래 사진과 같이 로그가 찍히는 것을 볼 수 있었다.


🤔 부작용 :: 모델분리 / AWS 의존적 구현
이러한 적용은 다음과 같은 부작용을 초래했다.
- CQRS 모델 분리를 하지 않아 자칫 CQRS 를 해보고 싶어서 적용한 것으로 오해를 살 수도 있다.
- SPOF, Primary/Secondary 에 대한 핸들링을 오롯히 AWS에게 맡겼다. 이러한 점은 여러 부작용을 야기한다.
- Vendor Lock-In : 모든 리소스를 AWS에 의존하여 AWS Vendor 에 Lock-In 되는 현상을 말한다. 상황이나 비용에 맞춰 다른 Cloud Service 사용하거나 커스텀할 수 있어야 하는데 그러지 못 하게 된다.
- 굉장한 비용부담 : RDS 자체적으로도 굉장히 비싼 편에 속한다. 실제로 100$/1m 중 30%가 RDS와 ELB 였다. 부하테스트"만" 돌렸는데도 이 정도라면 -- 100만건도 안 돌렸다, 최대 5만건이 전부였다 -- 실제 서버를 돌린다면 정말 엄청난 서버비를 낭비하게 될 것이다.
위와 같은 부작용은 어떻게 해결할 수 있을까?
CQRS 모델 분리
CQRS 에서의 모델 분리는 어찌보면 당연한 수순이다.
만약 아래와 같은 Aggregate 를 조회해야한다고 치자. Query Model 을 분리하는 게 필연적일 것이다.
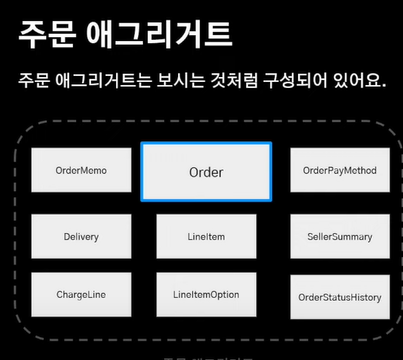
나는 이러한 복잡한 Query Model 이 아닌 경우에는 분리를 하지 않는 게 오히려 낫다고 판단했다.
왜냐하면,,,
-
조회 별로 Model 을 분리하는 게 올바른 관리법이라고 생각했다.
-
이에 따라 각 요청에 따른 Query Model 을 관리해야만 한다.
-
Query Model 이 늘어나면 늘어날수록 관리허들이 높아진다.
우리는 아래와 같이 단순한 조회 기능만을 지향하고 있기에, 추가적인 Query Model 분리는 하지 않았다.
-
상품 데이터 조회 (이름, 가격 등등)
-
모든 구매입찰가
-
모든 판매입찰가
만약 Aggregate 를 통해 가져오는 게 낫다고 판단되면 영상과 같이 Model 분리를 할 것 같다.
다만 이렇게 되는 경우, 역정규화를 통한 DB 분리로 Sync 를 맞춰야하는 이슈가 발생해서 관리허들이 높아질 것으로 예상되기도 한다.
AWS 에서 벗어나기
우리가 AWS를 사용한 이유는 단 하나다.
"내가 안 해도 AWS 사용하면 가능해"
그렇다면 탈 AWS 를 하려면 어떻게 할까??
방법은 간단하다. 직접 MHA 를 구성해주면 된다.
MHA 의 구성방법을 이해하면 내부적으로 구축을 하든, 어떤 클라우드 서비스이든 갈아끼우면 되기 때문이다.
다만 이 글의 핵심에서 벗어나기에, MHA 구성방법에 대해서는 따로 글을 작성할 예정이다.
