
TL;DR 🔰
- DBRider 는 DBUnit 을 통해 목업데이터 저장을 처리함
- DBUnit 은 쿼리에 대한 호출만 처리, commit() 은 호출하지 않음
ProxyConnection.close()처리 정책에 따라 데이터 롤백- 데이터 롤백을 방지하기 위해 테스트컨테이너 초기화 시,
HikariCP auto-commit : true설정
Episode 📜
필자는 사내에서 Testcontainer 와 유스케이스에 대한 테스트 환경을 격리하고, DBUnit 기반 DBRider 를 사용하여 테스트 데이터를 주입 및 초기화를 하고 있다.
그러던 중 새로운 프로젝트에 동일한 환경을 적용하여 사용 중에 있었는데,
갑자기 목업 테스트데이터들이 저장되지 않는 이상현상을 발견하게 되었다.
당시 상황을 재현하기 위해 PoC 를 진행하였다.
우선 프로젝트 설정에 아래와 같이 test-container 와 dbrider 를 추가해주자.
build.gradle
plugins {
id 'java'
id 'org.springframework.boot' version '3.4.4'
id 'io.spring.dependency-management' version '1.1.7'
}
group = 'hama.soombilab'
version = '0.0.1-SNAPSHOT'
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
def testContainerVersion = '1.20.6'
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
annotationProcessor 'jakarta.annotation:jakarta.annotation-api'
annotationProcessor 'jakarta.persistence:jakarta.persistence-api'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
runtimeOnly 'com.mysql:mysql-connector-j:8.3.0'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation "org.testcontainers:testcontainers:$testContainerVersion"
testImplementation "org.testcontainers:junit-jupiter:$testContainerVersion"
testImplementation "org.testcontainers:mysql:$testContainerVersion"
testImplementation 'com.github.database-rider:rider-spring:1.44.0'
testImplementation 'org.testcontainers:junit-jupiter'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
testImplementation 'com.github.gavlyukovskiy:p6spy-spring-boot-starter:1.9.1'
}
tasks.named('test') {
useJUnitPlatform()
}application.yaml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/testdb
username: root
password: asdf1234
hikari:
auto-commit: false
jpa:
database-platform: org.hibernate.dialect.MySQLDialect
hibernate:
ddl-auto: none
properties:
hibernate:
create_empty_composites:
enabled: true
jdbc:
time_zone: Asia/Seoul
batch_size: 1000
order_inserts: true
order_updates: true
auto_quote_keyword: true
globally_quoted_identifiers: true
show_sql: true
generate_statistics: true
format_sql: true
highlight_sql: true
lock_timeout: 777
format_sql: true
default_batch_fetch_size: 1000
open-in-view: false
defer-datasource-initialization: true
show-sql: true
logging:
level:
org.springframework.transaction: DEBUG
org.springframework.orm.jpa: DEBUG이후 Admin JPA 객체를 선언해주었다.
Admin.java
@Entity
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Table(name = "admin")
public class Admin extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long admIdx;
@Column(length = 50)
@Comment("관리자 아이디")
private String admId;
@Column(length = 50)
@Comment("관리자 비밀번호")
private String admPassword;
}
@Entity
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Table(name = "admin")
public class Admin extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long admIdx;
@Column(length = 50)
@Comment("관리자 아이디")
private String admId;
@Column(length = 50)
@Comment("관리자 비밀번호")
private String admPassword;
}이후 Admin 에 대해 목업데이터를 구성해주었다.
DBRider 는 테스트데이터를 처리하기 위해 개발자로부터 목업데이터 파일을 요구한다.
포맷은 json, csv, yml 이며 -- sql 지원이 없어 PR 을 올리고자 실험 중에 있다 -- 내부적으로 DBUnit 의 IDataSet 를 활용한다.
이 때 IDataSet 을 생성하기 위해 DBRider 는
-
TestContext 로부터 데이터베이스에 대한 Connection 을 추출
-
우리가 명시한 파일로부터 데이터들을 읽어서 IDataSet 구조체를 생성
하는 구조로 처리된다.
src/test/resources/mock/json/admin.json
{
"admin": [
{
"adm_idx": "2",
"created_at": "2024-05-24 10:18:01",
"updated_at": "2024-05-24 10:18:01",
"adm_id":"hama-admin-12",
"adm_password": "1234qwer!@"
}
]
}이후 유스케이스 테스트를 작성했다.
AdminRepositoryTest.java
@Testcontainers
@SpringBootTest
@DBRider
@DBUnit(caseInsensitiveStrategy = Orthography.LOWERCASE)
class AdminRepositoryTest {
@Container
static MySQLContainer<?> MY_SQL_FIXTURE = MySQLFixture.getInstance();
static {
JdbcDatabaseDelegate jdbcDatabaseDelegate = new JdbcDatabaseDelegate(MY_SQL_FIXTURE, "");
ScriptUtils.runInitScript(jdbcDatabaseDelegate, "mock/sql/admin.sql");
}
private final DatabaseOperation databaseOperation = DatabaseOperation.INSERT;
@Autowired
private AdminRepository adminRepository;
@DynamicPropertySource
static void overrideProps(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", MY_SQL_FIXTURE::getJdbcUrl);
registry.add("spring.datasource.username", MY_SQL_FIXTURE::getUsername);
registry.add("spring.datasource.password", MY_SQL_FIXTURE::getPassword);
}
@Test
@DisplayName("어드민 조회 시 성공합니다.")
@DataSet(
value = "mock/json/admin.json",
strategy = SeedStrategy.INSERT,
cleanBefore = true,
disableConstraints = true,
cleanAfter = true,
transactional = true
)
void 어드민조회시성공() {
// GIVEN
// WHEN
List<Admin> all = adminRepository.findAll();
// THEN
assertFalse(all.isEmpty());
all.stream().map(Admin::getAdmIdx).forEach(System.out::println);
}
}요골 그대로 가져다가 테스트를 돌려보면
insert 는 나가는데 데이터는 조회가 안 되는 신비로운 현상을 볼 수가 있다.
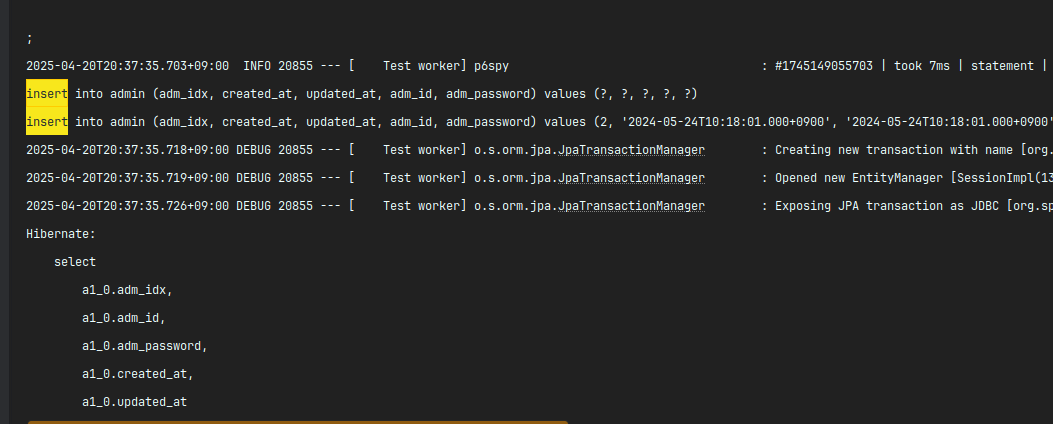
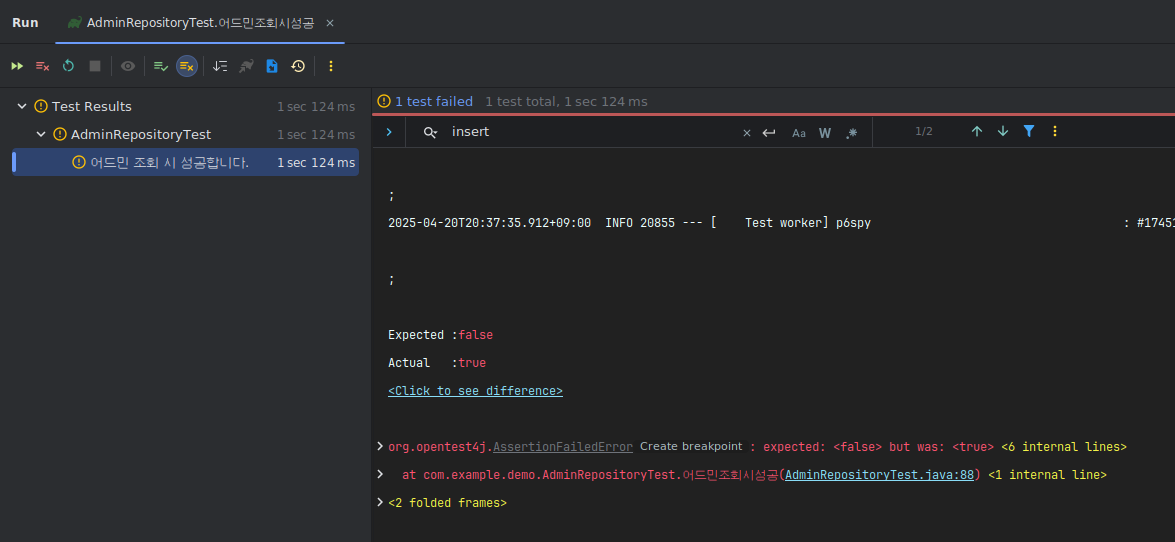
이에 따라 여러가지 가설을 세웠다.
-
테스트 컨테이너에 연결이 설정되지 않은 것일 수도 있음
=> X 연결 자체는 정상적으로 수행되는 것을 확인할 수 있었다. -
테스트 컨테이너 버전과 DBRider 버전 문제일 수도 있음
=> X 모든 버전을 테스트해봤고, 더 나아가 코드를 보면 버전 간 동작원리나 과정이 크게 바뀌는 것은 없었다. -
어떤 이유로 DBUnit 의 Preparedstatement 가 전혀 작동하지 않는 것일 수도 있음
=> X DBRider의 모든 로직을 모킹하여 테스트해봤지만 모두 성공했다. -
데이터 형식(.json)이 잘못된 것일 수 있음
=> X json 데이터셋에 대한 파싱 테스트 시 통과했다.
보시는 것과 같이 모든 가설이 다 들어맞지 않았음을 테스트 코드를 통해 확인할 수 있었다.
아래는 위 가설들에 대한 필자가 확인했었던 테스트 코드이다.
@Test
@DisplayName("DBRider로직모킹을 통해 목업데이터 저장 시 성공합니다.")
void DBRider로직모킹을통해목업데이터저장시성공() throws SQLException, DatabaseUnitException, IOException {
// GIVEN
Connection dbConnection = DriverManager.getConnection(
MY_SQL_FIXTURE.getJdbcUrl(),
MY_SQL_FIXTURE.getUsername(),
MY_SQL_FIXTURE.getPassword()
);
ConnectionHolderImpl connectionHolder = new ConnectionHolderImpl(dbConnection);
DataSetExecutorImpl dataSetExecutor = DataSetExecutorImpl.instance(connectionHolder);
IDataSet iDataSet = dataSetExecutor.loadDataSet("mock/json/admin.json");
// WHEN
RiderDataSource riderDataSource = dataSetExecutor.getRiderDataSource();
DatabaseConnection dbUnitConnection = riderDataSource.getDBUnitConnection();
databaseOperation.execute(dbUnitConnection, iDataSet);
// THEN
try (
PreparedStatement stmt = dbConnection.prepareStatement("SELECT adm_idx FROM admin LIMIT 1");
ResultSet rs = stmt.executeQuery()
) {
boolean hasValue = rs.next();
assertTrue(hasValue);
int admIdx = rs.getInt("adm_idx");
assertTrue(admIdx > 0);
System.out.println("adm_idx = " + admIdx);
} catch (SQLException e) {
e.printStackTrace();
fail("Query failed due to SQLException: " + e.getMessage());
}
}
@Test
@DisplayName("데이터베이스연결")
void 데이터베이스연결() throws SQLException {
// GIVEN
// WHEN
try (Connection connection = DriverManager.getConnection(
MY_SQL_FIXTURE.getJdbcUrl(),
MY_SQL_FIXTURE.getUsername(),
MY_SQL_FIXTURE.getPassword())
) {
// THEN
assertTrue(connection.isValid(2), "Database connection is not valid");
}
}
@Test
@DisplayName("JSON 데이터셋 파싱에 성공합니다.")
void JSON데이터셋파싱성공() throws SQLException, DataSetException, IOException {
// GIVEN
Connection dbConnection = DriverManager.getConnection(
MY_SQL_FIXTURE.getJdbcUrl(),
MY_SQL_FIXTURE.getUsername(),
MY_SQL_FIXTURE.getPassword()
);
ConnectionHolderImpl connectionHolder = new ConnectionHolderImpl(dbConnection);
DataSetExecutorImpl dataSetExecutor = DataSetExecutorImpl.instance(connectionHolder);
// WHEN
IDataSet iDataSet = dataSetExecutor.loadDataSet("mock/json/admin.json");
// THEN
ITableIterator iterator = iDataSet.iterator();
while (iterator.next()) {
ITable table = iterator.getTable();
ITableMetaData tableMetaData = table.getTableMetaData();
String tableName = tableMetaData.getTableName();
Column[] primaryKeys = tableMetaData.getPrimaryKeys();
Column[] columns = tableMetaData.getColumns();
System.out.println("tableName = " + tableName);
System.out.println("primaryKeys = " + Arrays.toString(primaryKeys));
System.out.println("columns = " + Arrays.toString(columns));
}stackoverflow 에도 질문을 올려보는 둥, 무엇이 문제인지 한참 고민을 하던 와중에
DBRider 측에서 작성해주신 스프링부트 example code 로부터 힌트를 얻을 수 있었다.
Reason 🤷♂️
HikariCP auto-commit
DBRider 는 아래와 같은 맥락으로 호출하여 데이터를 저장하고, 롤백한다.
( 긴 이야기를 짧게 줄이기 위해 자세한 동작과정은 생략하겠다 )
DBRiderTestExecutionListener extends AbstractTestExecutionListener
RiderRunner
DataSetExecutor
DatabaseOperation // 여기서부터 DBUnit 사용
InsertOperation extends AbstractBatchOperation
AutomaticPreparedBatchStatement
HikariProxyCallableStatement즉, 결과적으로 DBRider 는 DBUnit 을 통해 PreparedStatement 를 만들어서 execute() 를 호출한다.
중요한 건 DBUnit 안에서 execute() 처리한 해당 쿼리에 대해 commit() 을 호출하지 않는다는 것이다.
왜 이것이 문제가 되느냐,
HikariCP 는 커넥션 종료 시점에 commit 여부를 확인하여 , commit 이 실행되지 않았고 autocommit 이 false 라면 rollback 을 시키기 때문이다.
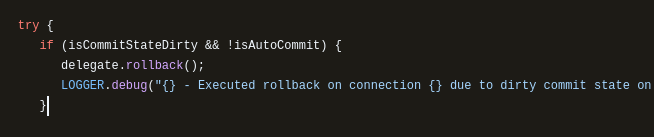
필자는 커넥션을 줄이고자 HikariCP 의 auto-commit 을 false 로 두었다.
( auto-commit 을 true 로 두면 커넥션을 잡아먹기 때문이다. 참고1 과 참고2 를 확인해보자 )
스프링부트의 @Transactional 이 내부적으로 알아서 begin/commit 을 호출하고 있어 걱정할 필요가 없었기 때문이다.
하지만 Test Method 에는 @Transactional 도, 명시적인 commit 도 없었다.
더군다나 DBUnit 내부적으로도 쿼리만 호출할 뿐, commit 은 하고 있지 않았다.
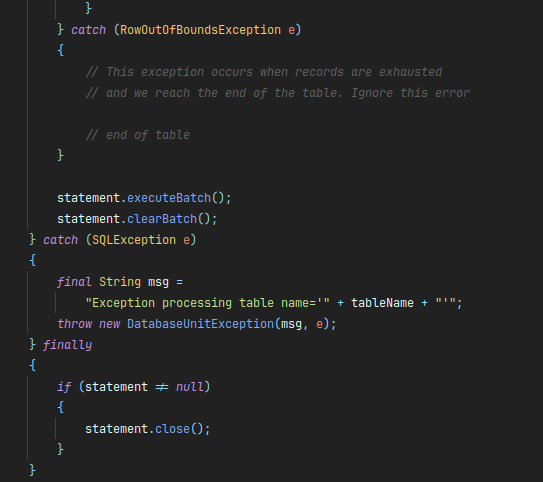
결과적으로 쿼리는 호출되어 실행되었어도, HikariCP 에 의해 rollback 이 된 것이다
Fix 🔧
이를 위해 필자는 테스트 컨테이너에 한하여 hikari.auto-commit 를 true 로 두었다.
@DynamicPropertySource
static void overrideProps(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", MY_SQL_FIXTURE::getJdbcUrl);
registry.add("spring.datasource.username", MY_SQL_FIXTURE::getUsername);
registry.add("spring.datasource.password", MY_SQL_FIXTURE::getPassword);
registry.add("spring.datasource.hikari.auto-commit", Boolean.TRUE::booleanValue);
}Hikari 의 auto-commit 에 대한 옵션은 커넥션 점유를 줄여 성능상의 이점을 가져가기위한 설정이다.
따라서 이와 같은 설정은 유스케이스에 대한 로직 확인을 하는 유닛테스트에서는 필요가 없다.
만약 성능 테스트를 해야한다면 해당 옵션은 논외이다. 성능 테스트는 아예 동일한 환경을 미러링해야하기 때문이다.
Remark on 'Why DBRider?' 💬
테스트 목업 생성 방법론
저마다 각기 다른 포맷의 데이터와 다양한 주입방법이 있겠지만 DBRider 를 사용한 이유는 독립성 유지와 간편성이다.
우선 테스트에 대해서 아래와 같은 기준을 충족해야만 했다.
- 사용하기 쉬울 것
- 각기 다른 테스트케이스 별로 독립적으로 처리되어야 할 것
- 어느 개발자가 실행되더라도 멱등하게 작동할 것
- 목업 및 Assertion 이 알아보기 쉬울 것
이에 따라 DBUnit , @Sql & @Transactional 이 거론되었으나, DBUnit 은 XML 과 데이터셋 구성이 너무 복잡하였고, @Sql 은 @Transactional 이외에는 데이터를 롤백하는 방법을 찾기가 어려웠다.
더군다나 필자는 테스트에 대해 @Transactional 사용을 지양하는 편인데, 이유인 즉슨 비즈니스 로직에 영향을 줄 수 있기 때문이다.
( 이에 대해 향로님의 좋은 의견 이 있어 덧붙여 본다 )
이를 모두 보완하는 라이브러리가 DBRider 였다.
데이터 저장과정에 대한 tx 또한 따로 잡을 수 있고, cleanBefore, cleanAfter 를 지원하여 목업 데이터 처리 전처리를 지원할 수 있다.
다만 아직 SQL 문에 대해 미지원중에 있는데 이에 대한 PR 을 진행 중에 있다.
진척도나 특이한 이슈가 있으면 해당 포스트에 공유하도록 하겠다 :-)
2025.04.01
돌아보니 원작자의 의도를 간과하였다.
executeBefore 를 통해 SQL 문들을 처리하고, IDataSet 구조체를 통해 데이터 상태를 선언하여
멱등성을 보장하는 구조로 짜여져있었다.
따라서 Input/Output 에 대해 파일형태로 관리하게끔 한 것이다.
결과적으로 SQL 파일은 IDataSet 에 적합하지 않다.
