
Episode 📜
As / Is
사내 레거시 메인 API 가 PHP 로 작성되어있음 (Laravel)
엑셀 API 는 Java 로 작성되어있음 (Spring)
이렇게 구성한 이유는
1) Java 진영의 Apache POI 가 속도가 빠르고
2) 다양한 함수를 지원하고 있기 때문이었음이에 따라 Java 엑셀 모듈은 두 방안을 섞어서 처리되고 있었음
1) PHP 코드를 보고, 조회 쿼리 & 부수 비즈니스 로직처리를 clone
2) PHP 조회 API 자체를 호출하여 값을 그대로 엑셀에 매핑
Issue
Blocking I/O 로 이루어진 PHP API 가 모든 데이터를 fetch 하고 있음
Spring MVC 의 Blocking I/O 가 이를 호출
이로 인해 성능 상 이슈가 발생하게 되었음
ToBe
이를 해결할 방법으로 Spring Reactor 를 사용하는 WebFlux 를 사용하기로 함
About 💁♂️
Defects of Blocking I/O ✋
해당 섹션의 내용 대부분은 "스프링으로 시작하는 리액티브 프로그래밍" 책으로부터 내용을 발췌하였습니다.
하나의 스레드가 I/O에 의해서 차단되어 대기하는 것을 Blocking I/O라고 한다.
Blocking I/O 방식의 문제점을 보완하기 위해서
멀티스레딩 기법으로 추가 스레드를 할당하여 차단된 그 시간을 효율적으로 사용할 수는 있다.
그런데 이렇게 CPU 대비 많은 수의 스레드를 할당하는 멀티스레딩 기법은 몇 가지 문제점이 존재한다.
-
컨텍스트 스위칭(Context Switching)으로 인한 스레드 전환 비용이 발생한다.
-
과다한 메모리 사용으로 오버헤드가 발생할 수 있다.
- 일반적으로 새로운 스레드가 실행되면 JVM에서는 해당 스레드를 위한 스택 Stack 영역의 일부를 할당한다.
새로운 스레드의 정보는 스택 영역에 개별 프레임 StackFrame 의 형태로 저장된다. - JVM의 디폴트 스택 사이즈는 64비트의 경우 1024KB이다.
만약에 64,000명이 동시 접속을 한다면, 총 64GB 정도의 메모리가 추가로 필요하게 된다. - 일반적으로 서블릿 컨테이너 기반의 Java 웹 애플리케이션은 요청당 하나의 스레드 thread per request 를 할당한다.
- 만약 각각의 스레드 내부에서 또 다른 작업을 처리 하기 위해 스레드를 추가로 할당하게 된다면, 시스템이 감당하기 힘들 정도로 메모리 사용량이 늘어날 가능성이 있다.
- 일반적으로 새로운 스레드가 실행되면 JVM에서는 해당 스레드를 위한 스택 Stack 영역의 일부를 할당한다.
-
스레드 풀(Thread Pool)에서 응답 지연이 발생할 수 있다.
- Spring Boot은 자체적으로 톰캣 Tomcat 이라는 서블릿 컨테이너를 내장한다.
그리고 톰캣은 사용자의 요청을 효과적으로 처리하기 위해 스레드 풀을 사용한다. - 스레드 풀이란 일정 개수의 스레드를 미리 생성해서 풀에 저장해 두고 사용 자의 요청이 들어올 경우, 아직 사용되지 않고 있는 스레드가 있다면 풀에서 꺼내어 쓰는 저장소이다.
- 하지만 만약 대량의 요청이 발생하게 되어 스레드 풀에 사용 가능한 유휴 스레드가 없을 경우, 사용 가능한 스레드가 확보되기 전까지 응답 지연이 발생한다.
- 이러한 응답 지연에는 반납된 스레드가 사용 가능하도록 전환되는 지연 시간이 포함되게 된다.
- Spring Boot은 자체적으로 톰캣 Tomcat 이라는 서블릿 컨테이너를 내장한다.
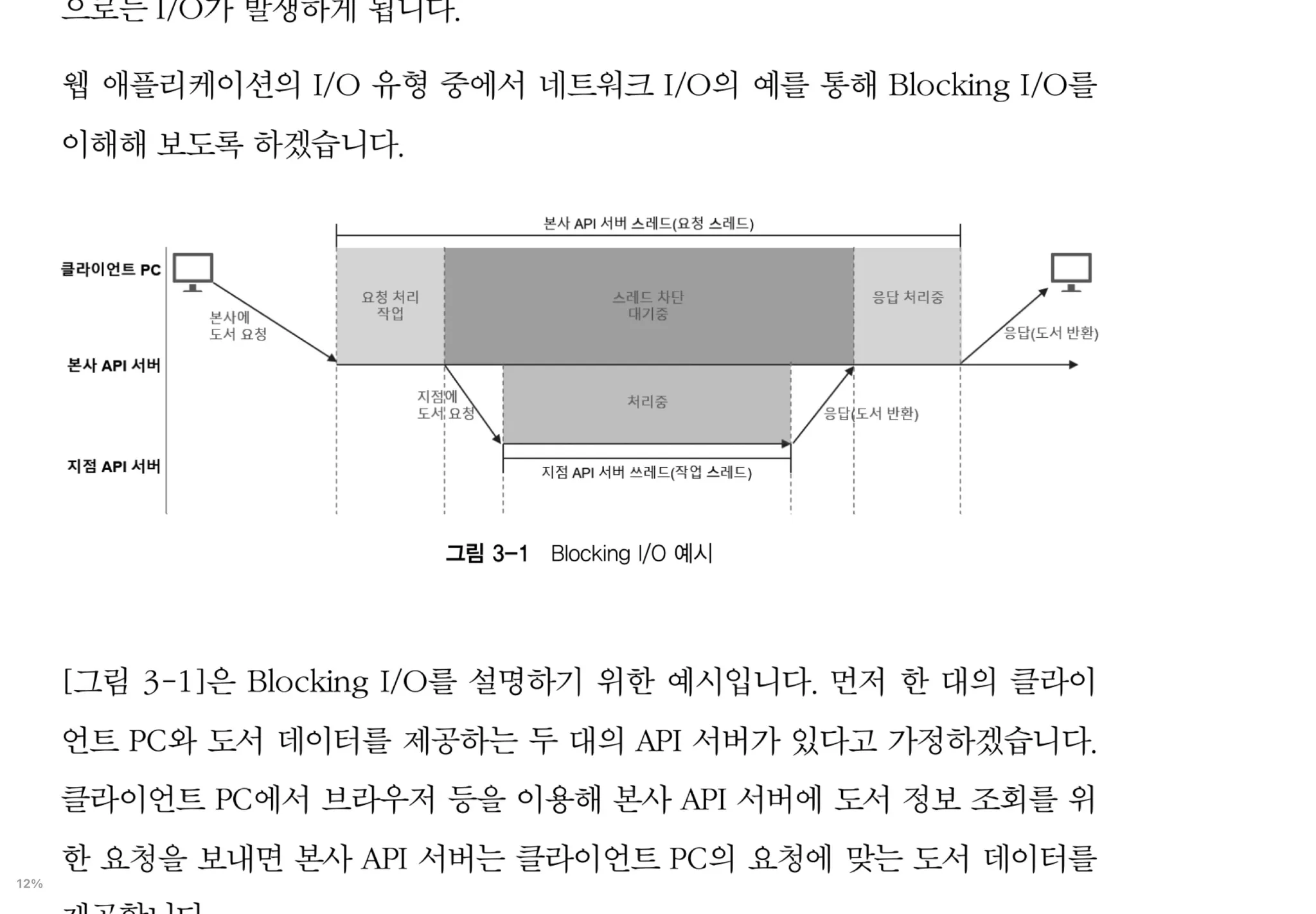
Non-Blocking I/O 💨
Non-Blocking I/O 방식의 경우, 작업 스레드의 종료 여부와 관계없이 요청한 스레드는 차단되지 않는다.
NonBlocking I/O 방식의 경우 스레드가 차단되지 않기 때문에 하나의 스레드로 많은 수의 요청을 처리할 수 있다.
즉, Blocking I/O 방식보다 더 적은 수의 스레드를 사용하기 때문에 Blocking I/ O에서 멀티스레딩 기법을 사용할 때 발생한 문제점들이 생기지 않는다.
따라서 CPU 대기 시간 및 사용량에 있어서도 대단히 효율적이다.
Is Non-Blocking a Silver Bullet ?? ✏
하지만 Blocking I/O 방식보다 뛰어난 성능을 보이는 Non-Blocking I/O 방식 에도 단점은 존재한다.
-
만약에 스레드 내부에 CPU를 많이 사용하는 작업이 포함된 경우에는 성능에 악영향을 준다.
- 이런 경우 Async 처리를 하여 작업을 병렬로 처리하여 CPU Workload Optimization 을 해주도록 하자
-
사용자의 요청에서 응답까지의 전체 과정에 Blocking I/O 요소가 포함된 경우에는 Non-Blocking의 이점을 발휘하기 힘들다.
- 사실 Non-Blocking IO 도입의 가장 큰 병목지점이다.
- 리소스 혹은 드라이버가 Non-Blocking 을 지원하지 않는다면 소용이 없기 때문이다.
- 해당 포스트에서는 다루지 않았지만 R2DBC 를 사용해야만 했는데, 학습곡선의 한계로 포기하였다. (QueryDSL 에 R2DBC 가 붙지 않아 코드베이스를 전부 다 들어내야하는 상황이었다 ㅠ)
- 따라서 필자는 해당 병목 IO 지점에 따로 스레드를 부여하여 우회처리를 해두었다.
What is Spring Reactor ?
TL;DR;
- Reactive Streams Specification/API
: non-blocking 에 대한 interface 와 프로세스 표준안- Reactor/RxJava
: 이러한 개념을 효과적으로 구현하는 데 필요한 도구인 Reactor와 RxJava입니다. 이 라이브러리는 Mono, Flux와 같은 API 유형을 제공- WebFlux
: 프로젝트 Reactor 라이브러리를 사용하는 웹 프레임워크
개발자가 리액티브한 코드를 작성하기 위해서는 이러한 코드 구성을 용이하게해 주는 리액티브 라이브러리가 있어야 된다.
이 리액티브 라이브러리를 어떻게 구현할지 정의해 놓은 별도의 표준 사양이 있는데, 이것을 바로 리액티브 스트림즈라고 부른다.
리액티브 스트림즈는 한마디로 ‘데이터 스트림을 Non-Blocking이면서 비동기적인 방식으로 처리하기 위한 리액티브 라이브러리의 표준 사양’이라고 표현할 수 있다.
리액티브 스트림즈를 구현한 구현체로 RxJava, Reactor, Akka Streams, Java 9 Flow API 등이 있는데,
Spring Team 에서 공식적으로 지원 및 개발 중인 Reactor 가 가장 대중적이고 다양한 기능들을 지원해준다.
WebFlux 는 Reactor 구현체 중 웹 프레임워크를 지원하는 라이브러리이다.
아래는 Reactive Stream 에 대한 기본적인 Component 들이다.
이 포스트에서는 깊게도 다루지 않고 언급조차 되지 않으므로 자세히 볼 필요는 없다.
다만 Reactor 에 대해 알고싶다면 반드시 알아야한다. 궁금하면 직접 구글링,,!

WebFlux 101 : Flux
Flux[N]: Reactor의 Publisher 타입은 크게 두 가지인데, 그중 한 가지가 바로 Flux이다.
Flux[N]이라는 의미는 N개의 데이터를 emit한다는 것인데,
다시 말해서 Flux는 0개부터 N개, 즉 무한대의 데이터를 emit할 수있는 Reactor의 Publisher이다.
Flux<String> stringFlux = Flux.just("Hello", "Baeldung");
StepVerifier.create(stringFlux)
.expectNext("Hello")
.expectNext("Baeldung")
.expectComplete()
.verify();WebFlux 101 : Mono
Mono[0|1]: Mono 역시 Reactor에서 지원하는 Publisher 타입인데,
Mono[0|1]과 같이 표현된 이유는 Mono가 데이터를 한 건도 emit하지 않거나 단 한 건만 emit하는 단발성 데이터 emit에 특화된 Publisher이기 때문이다.
Mono<String> helloMono = Mono.just("Hello");
StepVerifier.create(helloMono)
.expectNext("Hello")
.expectComplete()
.verify();WebFlux on WebClient
WebClient는 웹 요청을 수행하기 인터페이스이다.
이 인터페이스는 Spring Web Reactive 모듈의 일부로 만들어졌으며, 기존 RestTemplate을 대체할 예정이다.
RestTemplate 은 지원 중단 대상이지, Deprecated 대상이 아니다
또한 WebClient 는 HTTP/1.1 프로토콜을 통해 작동하는 Reactive Non-Blocking Solution 이다.
실제로는 Non-Blocking Client 이고 Spring WebFlux 라이브러리에 속하지만,
동기 및 비동기 작업을 모두 지원하므로 서블릿 스택에서 실행되는 애플리케이션에도 적합하다는 특징이 있다.
operation 을 blocking 하여 동기적인 결과값을 가져올 수 있는데, reactive stack 에서는 권장하지 않는다.
애초에, non blocking 하지 않을 거라면 webflux 를 가져다가 쓸 이유가 없다
Simply put, WebClient is an interface representing the main entry point for performing web requests.
It was created as part of the Spring Web Reactive module and will be replacing the classic RestTemplate in these scenarios. In addition, the new client is a reactive, non-blocking solution that works over the HTTP/1.1 protocol.
It’s important to note that even though it is, in fact, a non-blocking client and it belongs to the spring-webflux library, the solution offers support for both synchronous and asynchronous operations, making it suitable also for applications running on a Servlet Stack.
This can be achieved by blocking the operation to obtain the result. Of course, this practice is not suggested if we’re working on a Reactive Stack.
보통 이 WebClient 에 대한 Bean 을 생성하기 위해 Config 를 구현한다.
필자는 아래와 같이 구현했다.
똥코드 주의
@Configuration
@RequiredArgsConstructor
@Slf4j(topic = "WebClientConfig Logger")
public class WebClientConfig {
private final ApplicationContext applicationContext;
@Value("${php.base-url}")
private String baseUrl;
@Bean
public WebClient webClient(Builder builder) {
return builder
// PHP API 의존
.baseUrl(baseUrl)
// Header 처리
.defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
// 에러 발생 시 커스텀 예외 처리
.defaultStatusHandler(HttpStatusCode::isError, resp -> {
log.error("WebFlux 에러가 발생하였습니다. : {}", resp.toString());
return resp.bodyToMono(CustomException.class)
.flatMap(errorDetail -> Mono.error(new CustomException(ErrorCode.WEB_CLIENT_ERROR)));
})
// 메모리 사이즈 : UNLIMITED ! BAM!!!
.exchangeStrategies(ExchangeStrategies
.builder()
.codecs(codecs -> codecs
.defaultCodecs()
.maxInMemorySize(-1))
.build())
.build();
}
}JWT on WebClient
JWT 토큰을 헤더에 담아서 API 를 호출하고 싶다면 어떻게 해야할까?
- 토큰을 외부로부터 — FE 가 호출하는 서버 Controller method 의 인자값 — 받는다.
- 이 토큰을 잠시 저장하고 있을 TokenHolder 를 구현한다.
- 이 TokenHolder 를 WebClient 생성 시 주입한다.
- WebClient 를 통해 API 호출 시 Token 을 헤더에 넘겨준다.
필자는 아래와 같이 코드를 작성해보았다.
@Slf4j
@Component
@RequiredArgsConstructor
public class JwtRequestInterceptor extends OncePerRequestFilter {
private final WebClientTokenHolder webClientTokenHolder;
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
String token = request.getHeader("Authorization");
if (token != null && token.startsWith("Bearer ")) {
token = token.substring(7);
webClientTokenHolder.setToken(token);
}
filterChain.doFilter(request, response);
}
}@Getter
@Setter
@Component
@AllArgsConstructor
@NoArgsConstructor
public class WebClientTokenHolder {
private String token;
}@Slf4j
@Component
@RequiredArgsConstructor
public class PhpApiHandler {
private final WebClient webClient;
private final WebClientTokenHolder webClientTokenHolder;
public <T> List<T> getApiResponseList(
String targetUrl,
String queryString,
ParameterizedTypeReference<PhpClientResDto<T>> typeReference
) {
final String url = queryString == null ? targetUrl : targetUrl + queryString;
return webClient.get()
.uri(url)
.headers(h -> h.setBearerAuth(webClientTokenHolder.getToken()))
.retrieve()
.onStatus(HttpStatusCode::isError, WebClientErrorHandler.handleClientResponseMonoFunction())
.bodyToMono(typeReference)
.map(tPhpClientResDto -> tPhpClientResDto.getData()
.getResult()
.getList())
.block();
}
public <T> Mono<List<T>> getApiResponseListMono(
String targetUrl,
String queryString,
ParameterizedTypeReference<PhpClientResDto<T>> typeReference
) {
final String url = queryString == null ? targetUrl : targetUrl + queryString;
return webClient.get()
.uri(url)
.headers(h -> h.setBearerAuth(webClientTokenHolder.getToken()))
.retrieve()
.onStatus(HttpStatusCode::isError, WebClientErrorHandler.handleClientResponseMonoFunction())
.bodyToMono(typeReference)
.map(couponQueryResponseDtoPhpClientResDto -> couponQueryResponseDtoPhpClientResDto.getData()
.getResult()
.getList())
.subscribeOn(Schedulers.boundedElastic());
}
}Test on WebClient (feat. StepVerifier)
그렇다면 WebClient 에 대한 Test 는 어떻게 해볼 수 있을까?
두 가지 방법이 있다.
-
MockWebServer 를 통한 WebClient Mocking
- Spring Development Team 에서 공식적으로 추천하는 방법
-
StepVerifier 를 통한 API 호출 로직 및 결과값 검증
Testing Reactive Streams Using StepVerifier and TestPublisher | Baeldung
필자는 귀찮아서 StepVerifier 를 통한 로직과 값 검증만 진행하였다.
@SpringBootTest
class CouponQueryServiceTest {
private CouponQueryService couponQueryService;
@Autowired
private WebClient webClient;
@BeforeEach
void setUp() {
String token = JwtFactoryForTest.generateJwtTokenOfYoonGu(Boolean.TRUE);
WebClientTokenHolder webClientTokenHolder = new WebClientTokenHolder(token);
PhpApiHandler phpApiHandler = new PhpApiHandler(webClient, webClientTokenHolder);
CouponApiHandler couponApiHandler = new CouponApiHandler(phpApiHandler);
CouponAdapterImpl couponAdapter = new CouponAdapterImpl(couponApiHandler);
this.couponQueryService = new CouponQueryService(couponAdapter);
}
@Test
@DisplayName("쿠폰 엑셀결과 목록 조회 모노 성공합니다.")
void 쿠폰엑셀결과_목록조회_모노_성공() {
// GIVEN
String queryString = "";
// WHEN
Mono<ExcelCreateData> excelCreateDataMono = couponQueryService.handleMono(queryString);
// THEN
assertNotNull(excelCreateDataMono);
StepVerifier
.create(excelCreateDataMono)
.expectNextMatches(excelCreateData -> {
List<Map<String, Object>> excelData = excelCreateData.getExcelData();
if (excelData.isEmpty()) {
return false;
}
excelData
.forEach(stringObjectMap -> {
System.out.println("작성자 : " + stringObjectMap.get("작성자"));
});
return excelData
.stream()
.anyMatch(stringObjectMap -> Objects.nonNull(stringObjectMap.get("작성자")));
})
.expectComplete()
.verify();
}
}Apply 🧑💻
Subscriber & Spring Controller
Reactive Stream 은 Publisher 와 Subscriber 이 사용된다.
Publisher 는 말 그대로 Reactive Stream 을 생성해주는 역할이고,
Subscriber 는 Publish 된 Reactive Stream 에 대해 구독하여 활용하는 역할이다.
거칠게 표현하자면 이렇다 ㅎㅎ
그렇다면 Spring Framework 에서 누가 Publisher 와 Subscriber 역할인가?
Spring Framework 의 Controller 에서 Mono 를 반환하는 경우, Spring Framework 가 Subscribe 를 처리하는 주체가 된다.
WebClient의 디폴트 HTTP 클라이언트 라이브러리인 Reactor Netty 가 내부적으로 처리를 하게끔 되어있다.
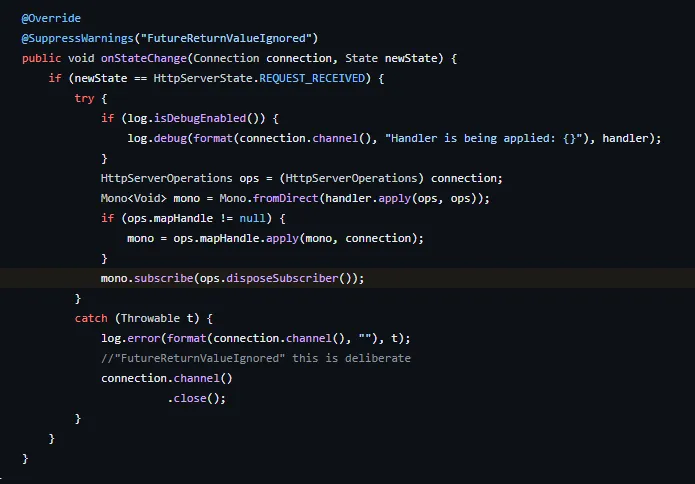
물론 내부적으로 Subscriber 선언하여 다양한 Reactive Stream 처리를 할 수 있다. 다만 Netty 가 기본적으로 이렇게 처리하고 있다는 것이다.
해당 포스트에서는 어떻게 Subscriber 선언하여 다양한 Reactive Stream 처리할 수 있는지에 대해서 다루지 않는다.
It's the framework (spring-webflux) that subscribes to the returned
MonoorFlux.For example if you use Netty (that's the default), then subscription happens here based on my debugging:
Also, this article might be of help to understand what happens when: https://spring.io/blog/2019/03/06/flight-of-the-flux-1-assembly-vs-subscription
At what point does the subscription take place? (spring webflux)
적용 코드
대강 개념을 훑었으니 이제 코드를 적용할 차례이다.
Excel 에 대한 Reactive 처리는 다음과 같은 순서로 처리된다.
- PHP API 에 대해 NonBlocking 호출
- PHP API 결과값에 반환 : Mono
- 결과값에 대해 엑셀데이터로 변환 : Mono
- 변환된 엑셀데이터에 대해 엑셀 생성 : Mono
- 생성된 엑셀을 반환 : Mono
아래는 필자가 적용한 코드이다.
아래 예제에서는 Scheduler 를 적용하지 않은 예제임을 주의해라
Controller
@CustomExceptionDescription(SwaggerResponseDescription.EXCEL_DOWNLOAD)
@Operation(summary = "쿠폰 관리 목록 Excel 비동기 처리", description = "요청값에 대해 https://www.notion.so/hama-lab/af840717044d4183b88d56ba9b1a5f47 참고.")
@GetMapping("/api/coupon/download-excel/mono")
public Mono<ResponseEntity<?>> downloadExcelMono(HttpServletRequest request) {
// Mono API 데이터
Mono<ExcelCreateData> dataMono = couponQueryService.handleMono(queryString);
// Mono 엑셀
Mono<ResponseEntity<?>> responseEntityMono = dataMono.flatMap(
excelCreateData -> ExcelResponseCreator.buildExcelResponseMono(excelCreateData, fileService, log));
return responseEntityMono;
}ExcelResponseCreator
public static Mono<? extends ResponseEntity<?>> buildExcelResponseMono(ExcelCreateData excelCreateData, FileService fileService, Logger log) {
return Mono.fromCallable(() -> buildExcelResponse(excelCreateData, fileService, log));
}CouponQueryService
public Mono<ExcelCreateData> handleMono(String queryString) {
// API 호출
Mono<List<CouponExcelResponseDto>> excelResponseDtoListMono = couponAdapter.getCouponExcelResponseDtoListMono(queryString);
// Mono 에 대해 엑셀로 변환
return ExcelCreateDataGenerateUtils.generateExcelCreateDataMonoFrom(
HEADERS_MAP,
excelResponseDtoListMono,
"쿠폰목록.xlsx",
"쿠폰목록 엑셀 파일을 다운로드 했습니다."
);
}CouponAdapter, CouponApiHandler
public Mono<List<CouponQueryResponseDto>> getCouponResponseDtoListMono(String queryString) {
return phpApiHandler.getApiResponseListMono(TARGET_URL, queryString, TYPE_REFERENCE);
}
public <T> Mono<List<T>> getApiResponseListMono(
String targetUrl,
String queryString,
ParameterizedTypeReference<PhpClientResDto<T>> typeReference
) {
final String url = queryString == null ? targetUrl : targetUrl + queryString;
return webClient.get()
.uri(url)
.headers(h -> h.setBearerAuth(webClientTokenHolder.getToken()))
.retrieve()
.onStatus(HttpStatusCode::isError, WebClientErrorHandler.handleClientResponseMonoFunction())
.bodyToMono(typeReference)
.map(couponQueryResponseDtoPhpClientResDto -> couponQueryResponseDtoPhpClientResDto.getData()
.getResult()
.getList());
}적용 결과
우리의 최고 관심사는, 아니 최고 우려사항은 아래와 같다.
- API 호출 시 다량의 데이터에 따라 서버가 죽어버리지 않을까?
- 엑셀 파싱작업에 의해 굉장히 느리지는 않을까?
- 과연 Non-Blocking 적용 시 얼마나 개선되는가?
이에 대해 아래와 같은 결과를 확인할 수 있었다.
- Non-Blocking 이므로 상대적으로 적은 수의 스레드가 사용된다.
- 다만 다량의 데이터 처리 시 PHP 서버에 장애가 발생할 확률은 존재하긴 한다.
- 엑셀 파싱작업에 대해 스레드풀을 따로 부여하여 느린 작업을 더욱 빠르게 처리하도록 하였다.
- 결과적으로 99.88% 개선되었다.
WebFlux 적용 이전과 이후에 대해 평균시간과 평균사용된 스레드 수를 비교하였다.
WebFlux 적용 이전
Execution time: 1189179000 nanoseconds
Thread count before: 20
Thread count after: 20- 테스트코드
@Test @DisplayName("쿠폰 엑셀결과 목록 조회 블로킹 성공합니다.") void 쿠폰엑셀결과_목록조회_블로킹_성공() { // GIVEN String queryString = ""; // WHEN ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean(); int threadCountBefore = threadMXBean.getThreadCount(); long startTime = System.nanoTime(); List<CouponExcelResponseDto> couponExcelResponseDtoList = couponAdapter.getCouponExcelResponseDtoList(queryString); long endTime = System.nanoTime(); int threadCountAfter = threadMXBean.getThreadCount(); // THEN assertNotNull(couponExcelResponseDtoList); boolean mbNameIsNotEmpty = couponExcelResponseDtoList .stream() .anyMatch(couponExcelResponseDto -> !couponExcelResponseDto.mbName().isEmpty()); assertTrue(mbNameIsNotEmpty); long duration = (endTime - startTime); System.out.println("Execution time: " + duration + " nanoseconds"); System.out.println("Thread count before: " + threadCountBefore); System.out.println("Thread count after: " + threadCountAfter); }
WebFlux 적용 이후
Execution time: 1484200 nanoseconds
Thread count before: 20
Thread count after: 20- 테스트코드
@Test @DisplayName("쿠폰 엑셀결과 목록 조회 모노 성공합니다.") void 쿠폰엑셀결과_목록조회_모노_성공() { // GIVEN String queryString = ""; // WHEN ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean(); int threadCountBefore = threadMXBean.getThreadCount(); long startTime = System.nanoTime(); Mono<List<CouponExcelResponseDto>> excelResponseDtoListMono = couponAdapter.getCouponExcelResponseDtoListMono(queryString); long endTime = System.nanoTime(); int threadCountAfter = threadMXBean.getThreadCount(); // THEN assertNotNull(excelResponseDtoListMono); StepVerifier .create(excelResponseDtoListMono) .expectNextMatches(couponExcelResponseDtos -> { if (couponExcelResponseDtos.isEmpty()) { return false; } couponExcelResponseDtos .forEach(couponExcelResponseDto -> { System.out.println("mbName : " + couponExcelResponseDto.mbName()); }); return couponExcelResponseDtos .stream() .anyMatch(couponExcelResponseDto -> !couponExcelResponseDto.mbName().isEmpty()); }) .expectComplete() .verify(); long duration = (endTime - startTime); System.out.println("Execution time: " + duration + " nanoseconds"); System.out.println("Thread count before: " + threadCountBefore); System.out.println("Thread count after: " + threadCountAfter); }
Schedulers.boundedElastic() ??
우리가 publish, subscribe 를 처리할 때, 이 reactive stream 을 처리하는 스레드의 주체는 main thread 가 된다.
만약 publish stream 과 subscribe stream 에 대한 스레드 주체를 변경하고 싶다면 어떻게 해야할까?
이를 지원하기 위해 Schedulers ,publishOn(), subscribeOn() 개념이 나온다.
- Schedulers : 스레딩에 대한 사용자 제어를 제공하기 위한 하나의 인터페이스로서 stream 에 대한 worker thread 를 지정한다.
- publishOn() : publishOn() 이후의 모든 연산자 호출은 제공된 Schedulers 에서 실행된다.
- subscribeOn() : 지정된 Schedulers 에서 subscribe(), onSubscribe(), request() 등의 초기 source emission 을 처리한다.
이러한 스레드 할당방법에 따라서 Schedulers 에는 여러 종류의 구현체들이 있다.
그중에서 Schedulers.boundedElastic( ) 은 ExecutorService 기반의 스레드 풀 Thread Pool 을 생성한 후,
그 안에서 정해진 수만큼의 스레드를 사용하여 작업을 처리하고 작업이 종료된 스레드는 반납하여 재사용하는 방식이다.
기본적으로 CPU 코어 수 x 10만큼의 스레드를 생성하며,
풀에 있는 모든 스레드가 작업을 처리하고 있다면 이용 가능한 스레드가 생길 때까지 최대 100,000개의 작업이 큐에서 대기할 수 있다.
보통 데이터베이스를 통한 질의나 HTTP 요청을 통해 데이터소스를 받는다.
이러한 작업은 대부분 Blocking I/O 작업으로 처리되는 경우가 많다.
Schedulers.boundedElastic( )은 바로 이러한 Blocking I/O 작업을 효과적으로 처리하기 위한 방식이다.
즉, 실행 시간이 긴 Blocking I/O 작업이 포함된 경우, 다른 Non-Blocking 처리에 영향을 주지 않도록 전용 스레드를 할당해서 Blocking I/O 작업을 처리할 수 있다.
public staticScheduler boundedElastic()
The common boundedElastic instance, a
Schedulerthat dynamically creates a bounded number of workers.Depends on the available environment and specified configurations, there are two types of implementations for this shared scheduler:
- ExecutorService-based implementation tailored to run on Platform
Threadinstances. Every Worker isExecutorServicebased. ReusingThreads once the Workers have been shut down. The underlying daemon threads can be evicted if idle for more than60seconds.- As of 3.6.0 there is a thread-per-task implementation tailored for use with virtual threads. This implementation is enabled if the application runs on a JDK 21+ runtime and the system property
DEFAULT_BOUNDED_ELASTIC_ON_VIRTUAL_THREADSis set totrue. Every Worker is based on the custom implementation of the execution mechanism which ensures every submitted task runs on a newVirtualThreadinstance. This implementation has a shared instance ofScheduledExecutorServiceused to schedule delayed and periodic tasks such that when triggered they are offloaded to a dedicated newVirtualThreadinstance.Both implementations share the same configurations:
- The maximum number of concurrent threads is bounded by a
cap(by default ten times the number of available CPU cores, seeDEFAULT_BOUNDED_ELASTIC_SIZE). Note: Consider increasingDEFAULT_BOUNDED_ELASTIC_SIZEwith the thread-per-task implementation to run more concurrentVirtualThreadinstances underneath.
- The maximum number of task submissions that can be enqueued and deferred on each of these backing threads is bounded (by default 100K additional tasks, see
DEFAULT_BOUNDED_ELASTIC_QUEUESIZE). Past that point, aRejectedExecutionExceptionis thrown.Threads backing a new
Scheduler.Workerare picked from a pool or are created when needed. In the ExecutorService-based implementation, the pool is comprised either of idle or busy threads. When all threads are busy, a best effort attempt is made at picking the thread backing the least number of workers. In the case of the thread-per-task implementation, it always creates new threads up to the specified limit.Note that if a scheduling mechanism is backing a low amount of workers, but these workers submit a lot of pending tasks, a second worker could end up being backed by the same mechanism and see tasks rejected. The picking of the backing mechanism is also done once and for all at worker creation, so tasks could be delayed due to two workers sharing the same backing mechanism and submitting long-running tasks, despite another backing mechanism becoming idle in the meantime.
Only one instance of this common scheduler will be created on the first call and is cached. The same instance is returned on subsequent calls until it is disposed.
One cannot directly
disposethe common instances, as they are cached and shared between callers. They can however be allshut downtogether, or replaced by achange in Factory.Returns:the ExecutorService/thread-per-task-based boundedElastic instance. A
Schedulerthat dynamically creates workers with an upper bound to the number of backing threads and after that on the number of enqueued tasks.
Schedulers.boundedElastic() 적용 이전과 이후
BoundedElastic 을 사용하면 얼마나 개선될까?
아래 테이블에서 볼 수 있듯이 적절하게 사용되는 경우 상대적으로 훨씬 빠른 것을 볼 수 있다.
물론 스레드가 늘어나 단점은 존재하지만, 다량의 데이터를 Bulk Fetch 하는 작업이므로 각각의 작업에 대한 스레드를 할당해주는 것은 필연적이라고 생각한다.
아니면 parallel() 을 사용할 수 있겠다만, 스레드 풀이 아닌 스레드를 무한정으로 생성해내기 때문에 Blocking API 호출에는 부적합하다.
아래는 BoundedElastic 적용 방법들에 따른 코드와 성능시간들이다.
왼쪽부터
- 블로킹
- 변환 이후에 스레드 할당
- 변환 로직 자체에 스레드 할당
- API 호출 ←
subscribeOn& 변환 로직 ←publishOn
순으로 적용해보았다.
| Metric | Blocking IO | Terminal Point | Initial Point | SubscribeOn + PublishOn |
|---|---|---|---|---|
| Average Execution Time (ns) | 2,514,679.7 | 2,728,078.0 | 1,588,389.9 | 1,360,942.0 |
| Final Thread Count | 51 | 41 | 40 | 55 |
블로킹
- Code
ExcelCreateData excelCreateData = couponQueryService.handle(queryString); ResponseEntity<?> responseEntity = ExcelResponseCreator.buildExcelResponse(excelCreateData, fileService, log); return responseEntity; - Execution Time
Execution time: 22895799 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 190499 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 195100 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 208999 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 255400 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 124499 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 179401 nanoseconds Thread count before: 45 Thread count after: 45 Execution time: 232700 nanoseconds Thread count before: 47 Thread count after: 47 Execution time: 571899 nanoseconds Thread count before: 49 Thread count after: 49 Execution time: 292501 nanoseconds Thread count before: 51 Thread count after: 51
boundedElastic()on Terminal Point: 변환 이후에 스레드 할당
- Code
Mono<ResponseEntity<?>> responseEntityMono = couponQueryService.handleMono(queryString) .flatMap(excelCreateData -> ExcelResponseCreator.buildExcelResponseMono(excelCreateData, fileService, log)) .publishOn(Schedulers.boundedElastic()); return responseEntityMono; - Execution Time
Execution time: 14997200 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 2728501 nanoseconds Thread count before: 43 Thread count after: 43 Execution time: 3028000 nanoseconds Thread count before: 42 Thread count after: 42 Execution time: 152400 nanoseconds Thread count before: 42 Thread count after: 42 Execution time: 3067400 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 127901 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 187700 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 138000 nanoseconds Thread count before: 41 Thread count after: 41 Execution time: 125600 nanoseconds Thread count before: 41 Thread count after: 41
boundedElastic()on Initial Point: 변환 로직 자체에 스레드 할당
- Code
Mono<ResponseEntity<?>> responseEntityMono = couponQueryService.handleMono(queryString) .publishOn(Schedulers.boundedElastic()) .flatMap(excelCreateData -> ExcelResponseCreator.buildExcelResponseMono(excelCreateData, fileService, log)); return responseEntityMono; - Execution Time
Execution time: 14123100 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 140200 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 153000 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 150701 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 209799 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 194299 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 283801 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 300300 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 199300 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 129399 nanoseconds Thread count before: 40 Thread count after: 40
subscribeOn+publishOn: API 호출 ←
subscribeOn: 변환 로직 ←
publishOn
- Code
public <T> Mono<List<T>> getApiResponseListMono( String targetUrl, String queryString, ParameterizedTypeReference<PhpClientResDto<T>> typeReference ) { final String url = queryString == null ? targetUrl : targetUrl + queryString; return webClient.get() .uri(url) .headers(h -> h.setBearerAuth(webClientTokenHolder.getToken())) .retrieve() .onStatus(HttpStatusCode::isError, WebClientErrorHandler.handleClientResponseMonoFunction()) .bodyToMono(typeReference) .map(couponQueryResponseDtoPhpClientResDto -> couponQueryResponseDtoPhpClientResDto.getData() .getResult() .getList()) .subscribeOn(Schedulers.boundedElastic()); }Mono<ResponseEntity<?>> responseEntityMono = couponQueryService.handleMono(queryString) .publishOn(Schedulers.boundedElastic()) .flatMap(excelCreateData -> ExcelResponseCreator.buildExcelResponseMono(excelCreateData, fileService, log)); return responseEntityMono; - Execution Time
Execution time: 14123100 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 140200 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 153000 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 150701 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 209799 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 194299 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 283801 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 300300 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 199300 nanoseconds Thread count before: 40 Thread count after: 40 Execution time: 129399 nanoseconds Thread count before: 40 Thread count after: 40
결제에 대한 성능비교
결제 API 에 대한 테스트 결과를 그냥 버리기 아쉬워 이렇게 남겨본다.
99.888564603031 % 개선되었다.
특히 1.8초씩 걸리던 걸 0.002 초 대로 개선되었다는 게 놀라웠다.
| Scenario | Average Execution Time (nanoseconds) | Average Execution Time (seconds) | Final Thread Count |
|---|---|---|---|
| Order > Advertise > Mono X | 1,782,762,000 | 1.782762 | 44 |
| Order > Advertise > Mono & subscribeOn & publishOn O | 1,986,627 | 0.001986627 | 50 |
Reference
At what point does the subscription take place? (spring webflux)
Schedulers (reactor-core 3.6.8)
Mocking a WebClient in Spring | Baeldung
Testing Reactive Streams Using StepVerifier and TestPublisher | Baeldung
책 "스프링으로 시작하는 리액티브 프로그래밍”
