
Problem
LeetCode 1581. Customer Who Visited but Did Not Make Any Transactions
Solution
1. CTE & Sub-Qeury 사용
WITH t_visit_group AS (
select visit_id
from Transactions
group by visit_id
)
select
customer_id
, count(customer_id)
from
Visits
group by
customer_id
having not in t_visit_group;[ERROR] Syntax error : 어떤 부분이 잘못된 문법이었을까??
HAVING 은 aggregate functions 에 대한 filter group
GROUP BY 로 묶은 뒤, HAVING 을 CTE 에 대한 처리를 하였다.
하지만 HAVING 은 GROUP BY 이후 적용된 aggregate functions 에 대한 filter group 이다.
따라서 아래와 같이 고쳐야한다.
WITH t_visit_group AS (
SELECT visit_id
FROM Transactions
GROUP BY visit_id
)
SELECT
customer_id,
COUNT(customer_id) as count_no_trans
FROM
Visits
WHERE
visit_id NOT IN (SELECT visit_id FROM t_visit_group)
GROUP BY
customer_id;
하지만 비교적 느리다.
왜 느릴까? → Full Scan 을 5 번을 한다.
Datagrip 을 통해 Execute Plan 확인해보자.
Table Schema
Create table If Not Exists Visits(visit_id int, customer_id int) Create table If Not Exists Transactions(transaction_id int, visit_id int, amount int) Truncate table Visits insert into Visits (visit_id, customer_id) values ('1', '23') insert into Visits (visit_id, customer_id) values ('2', '9') insert into Visits (visit_id, customer_id) values ('4', '30') insert into Visits (visit_id, customer_id) values ('5', '54') insert into Visits (visit_id, customer_id) values ('6', '96') insert into Visits (visit_id, customer_id) values ('7', '54') insert into Visits (visit_id, customer_id) values ('8', '54') Truncate table Transactions insert into Transactions (transaction_id, visit_id, amount) values ('2', '5', '310') insert into Transactions (transaction_id, visit_id, amount) values ('3', '5', '300') insert into Transactions (transaction_id, visit_id, amount) values ('9', '5', '200') insert into Transactions (transaction_id, visit_id, amount) values ('12', '1', '910') insert into Transactions (transaction_id, visit_id, amount) values ('13', '2', '970')
왜 Table Full Scan 을 5번이나 할까???
이유는 아래와 같다.
- WHERE 절에 대한 Subquery가 실행되어서.
- Index 가 존재하지 않아서.
SELECT (select)
SEQ_SCAN (Table scan) table: <temporary>;
UNKNOWN (Aggregate using temporary table)
FILTER (filter) 7 0.95 <in_optimizer>(Visits.visit_id,Visits.visit_id in (select #2) is false)
SEQ_SCAN (Table scan) table: Visits; 7 0.95
SUBQUERY (Select) #2 (subquery in condition; run only once)
FILTER (filter) 1 7.47 7.47 ((Visits.visit_id = `<materialized_subquery>`.visit_id))
UNKNOWN (Limit) 1 7.38 7.38 1 row(s)
UNIQUE_INDEX_SCAN (Index lookup) table: <materialized_subquery>; index: <auto_distinct_key>; (visit_id=Visits.visit_id)
UNKNOWN (Materialize with deduplication) 5 7.38 7.38
SEQ_SCAN (Table scan) table: t_visit_group; 5 6.88 4.83
UNKNOWN (Materialize CTE t_visit_group) 5 4.31 4.31
SEQ_SCAN (Table scan) table: <temporary>; 5 3.81 1.76
TEMPORARY (Temporary table with deduplication) 5 1.25 1.25
SEQ_SCAN (Table scan) table: Transactions; 5 0.75 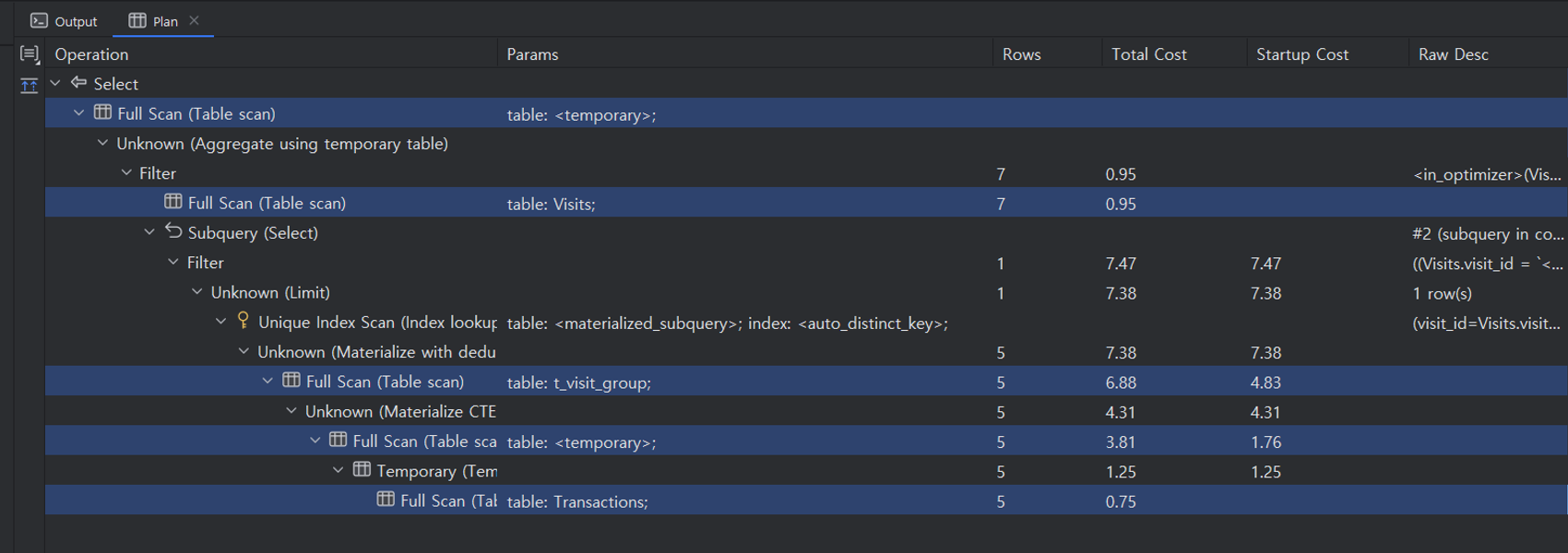
어떻게 하면 개선할 수 있을까??
Subquery 에서 DISTINCT 를 사용하여 개선
동일쿼리 내에서 개선할 수 있는 방법이 있다.
바로 id 에 대한 DISTINCT 처리를 하는 것이다.
아래와 같이 visit_id 에 대해 DISTINCT 를 처리하여 range 를 좁혔다.
과연 얼마나 빨라질까??
WITH t_visit_group AS (
SELECT visit_id
FROM Transactions
GROUP BY visit_id
)
SELECT
customer_id,
COUNT(customer_id) as count_no_trans
FROM
Visits
WHERE
visit_id NOT IN (SELECT **DISTINCT** visit_id FROM t_visit_group)
GROUP BY
customer_id;이전
이후
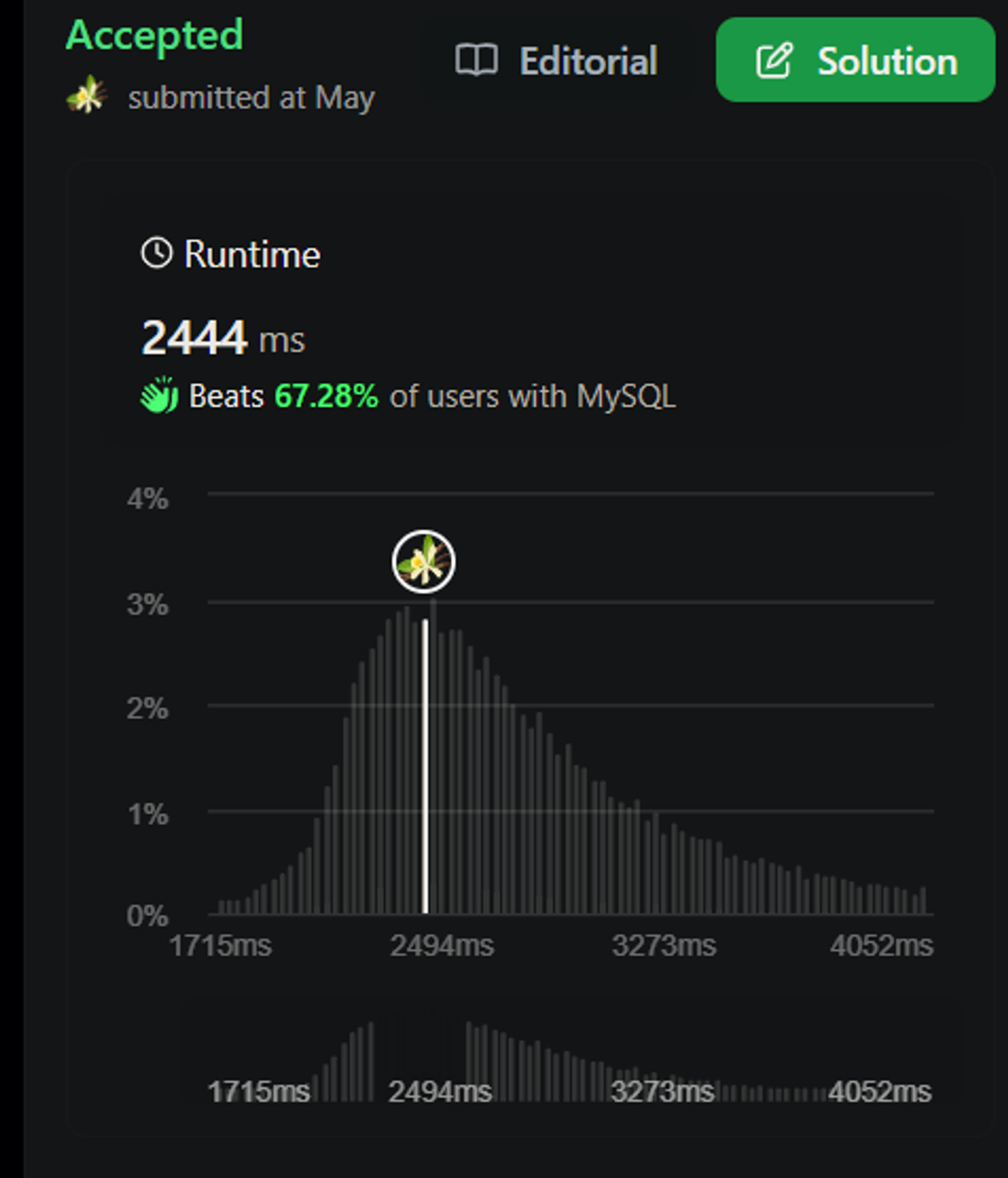
그렇다면 왜 빨라졌을까???
Datagrip 에서 Explain 을 처리해보자
SELECT (select)
SEQ_SCAN (Table scan) table: <temporary>;
UNKNOWN (Aggregate using temporary table)
FILTER (filter) 7 0.95 <in_optimizer>(Visits.visit_id,Visits.visit_id in (select #2) is false)
SEQ_SCAN (Table scan) table: Visits; 7 0.95
SUBQUERY (Select) #2 (subquery in condition; run only once)
FILTER (filter) 1 7.47 7.47 ((Visits.visit_id = `<materialized_subquery>`.visit_id))
UNKNOWN (Limit) 1 7.38 7.38 1 row(s)
UNIQUE_INDEX_SCAN (Index lookup) table: <materialized_subquery>; index: <auto_distinct_key>; (visit_id=Visits.visit_id)
UNKNOWN (Materialize with deduplication) 5 7.38 7.38
SEQ_SCAN (Table scan) table: t_visit_group; 5 6.88 4.83
UNKNOWN (Materialize CTE t_visit_group) 5 4.31 4.31
SEQ_SCAN (Table scan) table: <temporary>; 5 3.81 1.76
TEMPORARY (Temporary table with deduplication) 5 1.25 1.25
SEQ_SCAN (Table scan) table: Transactions; 5 0.75 아예 바뀐 게 없었다.
사실 distinct 는 데이터를 줄여주는 역할만 수행해주었을 뿐이다.
그래서 최적화가 되는 것처럼 보였을 뿐, 그저 된 것이 아니다.
그저 데이터를 줄였기에 조회 속도가 빨라진 것이다.
Stackoverflow 에서는 SubQuery 의 IN 절 에서 DISTINCT 를 쓰는 것은 일반적인 최적화가 되지 않는다고 한다.
The
SELECT DISTINCTin theINsubquery does nothing. Nothing at all. TheINimplicitly does aSELECT DISTINCTbecause if something is in(1, 2, 3), then that something is in(1, 1, 1, 2, 2, 3).
Distinct in subquery : stackoverflow
2. LEFT JOIN 사용
SELECT V.customer_id, COUNT(V.visit_id) AS count_no_trans
FROM Visits V
LEFT JOIN Transactions T ON V.visit_id = T.visit_id
WHERE T.transaction_id IS NULL
GROUP BY V.customer_id;[Join X] Full Scan 5번 → [Join O] Full Scan 3번

SELECT (select)
SEQ_SCAN (Table scan) table: <temporary>;
UNKNOWN (Aggregate using temporary table)
FILTER (filter) 7 4.26 (T.transaction_id is null)
UNKNOWN (Left hash join) 7 4.26 (T.visit_id = V.visit_id)
SEQ_SCAN (Table scan) table: V; 7 0.95
HASH_UNIQUE (Hash)
SEQ_SCAN (Table scan) table: T; 5 0.107 LEFT hash join 을 함으로써 Full Scan 횟수를 줄일 수 있었다.
이로써 SubQuery 는 Join 보다 일반적인 성능이 좋지 않다는 것을 또 다시금 느낄 수 있었다.
Reference
