Intro (Issue Context)
깃허브의 이슈와 그에 따른 여러 댓글 시스템을 떠올려보자.
하나의 이슈(1) 에 대해서 여러 댓글(N)의 연관관계를 떠올릴 수 있을 것이다.
이에 따라 댓글이 이슈를 참조하게끔 외래키를 잡게 할 수 있을 것이다.
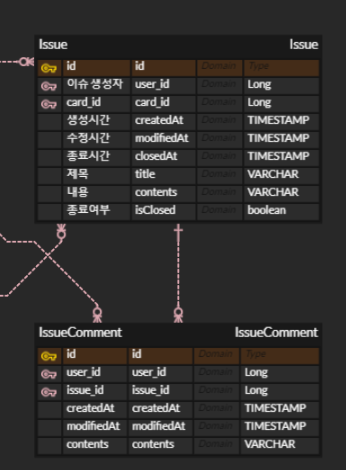
이렇게 설정한 ERD에 따라 아래와 같이 엔티티를 설정할 수 있을 것이다.
Issue
@Entity
@Table(name = "issue")
@Builder
@NoArgsConstructor
@AllArgsConstructor
@DynamicInsert
@DynamicUpdate
@Getter
public class Issue extends BaseEntity {
@OneToMany(mappedBy = "issue", cascade = CascadeType.ALL, orphanRemoval = true)
private final List<IssueComment> issueComments = new ArrayList<>();
@Nonnull
@JsonIgnore
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
,,,,
}IssueComment
@Entity
@Table(name = "issueComment")
@NoArgsConstructor
@Getter
public class IssueComment extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String contents;
@Nonnull
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
@Nonnull
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "issue_id")
private Issue issue;
}이렇게 설정된 엔티티에서, 부모 관계인 이슈를 조회하게 되면 어떻게 될까??
과연 우리의 의도대로 자식들을 가져와줄까?
List<Issue> issues = issueRepository.findAll();Issue :: 1개의 부모 Select Query => N개의 자식 Select Query
위와 같은 JPA Data 를 사용한 쿼리 -- 혹은 JPQL 쿼리 -- 를 날리게 되면 아래와 같이 찾아오게 된다.
SELECT * FROM issue;
-- Query for Issue 1
SELECT * FROM issueComment WHERE issue_id = 1;
-- Query for Issue 2
SELECT * FROM issueComment WHERE issue_id = 2;
-- Query for Issue 3
SELECT * FROM issueComment WHERE issue_id = 3;
...
-- Query for Issue N
SELECT * FROM issueComment WHERE issue_id = N;
Reason & Defects
Reason
아래는 JpaRepository 의 구현체인 SimpleJpaRepository 의 findAll()이다. 어떻게 돌아가는지 내부를 뜯어보자.

-
getQuery() 를 통해 주어진 도메인 엔티티에 따른 TypedQuery를 생성한다.
-
이 때, Proxy를 사용한 Example, ExampleSpecification 을 통해 생성될 쿼리에 대한 Specification 인터페이스를 제공한다
-
Example, ExampleSpecification 은
-
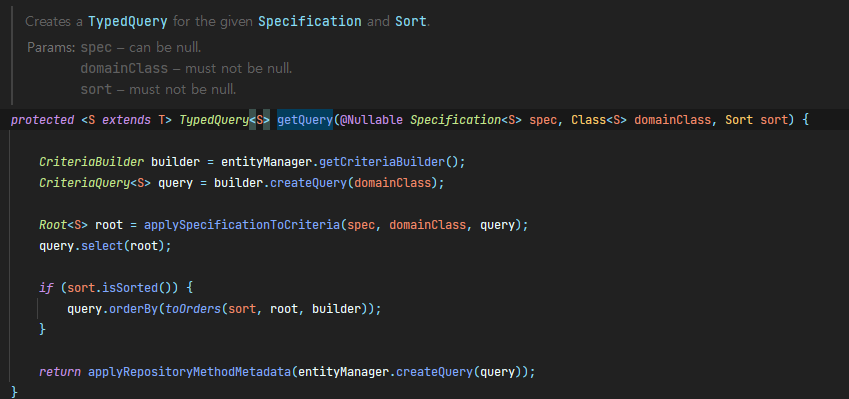
- 그 다음 Query를 수행한 뒤, List 에 결과값을 담는다.
위와 같이 JPA는 메서드 이름을 분석해서 JPQL을 생성하여 실행하게 된다.
JPQL은 SQL을 추상화한 객체지향 쿼리 언어로서 특정 SQL에 종속되지 않고 엔티티 객체와 필드 이름을 가지고 쿼리를 한다.
이에 따라 JPQL은 findAll()이란 메소드를 수행하였을 때 해당 엔티티를 조회하는 select * from issue 쿼리만 실행하게 되는것이다.
문제는 JPQL 입장에서는 연관관계 데이터를 무시하고 해당 엔티티 기준으로 쿼리를 조회하는 것이다.
이로 인해 연관된 엔티티 데이터가 필요한 경우, FetchType으로 지정한 시점에 조회를 별도로 호출하게 된다.
즉, 1개의 쿼리에 대해, 연관된 엔티티 정보를 조회하기 위한 N개의 쿼리를 수행하게 되는 것이다.
이렇게 되면 단점이 뭐가 있을까??
Defects
The larger the value of N, the more queries will be executed and the larger the performance impact. And, unlike the slow query log that can help you find slow-running queries, the N+1 issue won’t be spotted because each individual additional query runs sufficiently fast to not trigger the slow query log.
The problem is executing a large number of additional queries that, overall, take sufficient time to slow down response time.
즉, N의 크기가 클수록 쿼리의 양이 많아져 리스폰스 타임이 길어지게 된다.
응답시간이 길어지면 스레드의 점유시간과 실행시간이 길어지고, 이는 곧 여러 트래픽을 처리하지 못 하는 이유가 되게 된다.
Resolution
EAGER를 지양한다.- Fetch Join / EntityGraph 를 사용한다.
- 다량의 데이터인 경우,
@Fetch(FetchMode.SUBSELECT)를 지양한다.
- SubQuery 사용 시, 테이블의 모든 row 에 대한 Full Scan 이 일어날 가능성이 있음(참조)
- 카테시안 곱이 발생하여 중복데이터가 존재할 수 있다.
- Set 컬렉션을 사용하여 해결
- Distinct 를 사용하여 해결
- 1대1 양방향 연관관계 지양한다.
- 자식 테이블이 크다면 양방향을 끊어주자.
왜 이렇게 해야하는지, 어떻게 적용할 수 있는지
하나하나씩 살펴보자.
1. EAGER 를 지양한다.
@ManyToOne의 default FetchType 은 EAGER 이다. 근데 왜 지양하라고 하는걸까?
그 이유는 간단하다. 모든 데이터를 다 가져와야 하기 때문이다.
관련된 모든 자식데이터를 미리 다 가져와야 하므로 (fetch eagerly) 자식 데이터만큼 SELECT 쿼리를 수행해야만 하게 되는 것이다.
-- N+1 문제가 아니더라도, 필요하지 않은 데이터에 관해 JOIN 연산을 하게 되어야하기에 최대한 지양하라는 코멘트도 보았다. eager-fetching-is-a-code-smell
따라서 EAGER 는 최대한 지양하자.
2. Fetch Join / EntityGraph 을 사용한다.
Fetch Join
QueryDsl 이나, JPQL을 통해 inner join을 하여 데이터를 가져오는 것이다.
(혹은 외래키 필드에 @Fetch를 사용할 수도 있다)
- QueryDsl
return qd.query()
.selectFrom(issue)
.leftJoin(issue.card, card) // fetch join of "issue" & "card"
.leftJoin(issue.user, user) // fetch join of "issue" & "card"
.leftJoin(issue.issueComments, issueComment) // fetch join of "issue" & "card"
.fetch();- JPQL
public interface IssueRepository extends JpaRepository<Issue, Long>, IssueRepositoryCustom {
@Query("select i from Issue i join fetch i.issueComments")
List<Issue> findAll();
}- 외래키 필드에 @Fetch 사용
public class Issue extends BaseEntity {
@OneToMany(mappedBy = "issue", cascade = CascadeType.ALL, orphanRemoval = true)
@Fetch(FetchMode.JOIN)
private final List<IssueComment> issueComments = new ArrayList<>();
}@Fetch(FetchMode.SUBSELECT) 를 사용하여 서브 쿼리를 통해 데이터를 가져올 수 있다.
"JOIN에 대한 성능저하를 피할 수 있지 않나?" 라는 생각에 사용해볼까 싶다면 다시 고려해보자.
SUBSELECT 는 아래와 같이 두 개의 쿼리가 나가게 된다. 코드 출처Hibernate: select ... from customer customer0_ Hibernate: select ... from order order0_ where order0_.customer_id in ( select customer0_.id from customer customer0_ )서브쿼리는 내부적으로 테이블의 모든 row를 스캔하게 된다. 데이터 청크가 작다면 빠를 수 있지만, 데이터 청크가 크다면 JOIN을 사용하는 게 나을 것이다.
inner join 을 통해 하나의 쿼리를 통해 부모, 자식 데이터를 가져올 수 있다.
물론, 자식 데이터가 필요한 경우에만 이렇게 사용하자.
필요도 없는데 join 을 사용하게 된다면 성능 저하를 야기하게 된다.
Entity Graph
아래와 같이 Entity Graph 를 통해 자식 데이터에 대한 N+1 쿼리 이슈를 해결할 수 있다.
이 때, Fetch Join 과 다르게 Outer Join 을 통해 데이터를 가져온다.
public interface IssueRepository extends JpaRepository<Issue, Long>, IssueRepositoryCustom {
@EntityGraph(attributePaths = "issueComments")
@Query("select i from Issue i")
List<Issue> findAll();
}3. 1대1 양방향 연관관계 지양한다.
아래와 같은 1대1 양방향 관계가 있다고 치자.
@Entity
public class Manuscript {
@Id
@GeneratedValue
private Long id;
private byte[] file;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "fk_book")
private Book book;
...
}@Entity
public class Book {
@Id
@GeneratedValue
private Long id;
@OneToOne(mappedBy = "book", fetch = FetchType.LAZY)
private Manuscript manuscript;
...
}이러한 양방향 관계에 대해서 Hibernate는 다른 한 쪽의 엔티티를 Eagerly fetch 하게 된다.
왤까?
SELECT * FROM Book;
SELECT * FROM Manuscript WHERE book_id = 1;
SELECT * FROM Manuscript WHERE book_id = 2;
SELECT * FROM Manuscript WHERE book_id = 3;
그 이유는 "일대일 양방향" 이기 때문이다.
That’s because Hibernate needs to know if it shall initialize the manuscript attribute with null or a proxy class. It can only find that out, by querying the manuscript table to find a record that references this Book entity. The Hibernate team decided that if they have to query the manuscript table anyways, it’s best to fetch the associated entity eagerly.
Hibernate 는 manuscript 필드값이 null 로 초기화될지, proxy 로 초기화될지를 판단해야한다.
Hibernate 는 manuscript 테이블에 Book 엔티티에 연관된 데이터가 있는지를 찾고나서 이 판단을 매듭짓는다.
https://thorben-janssen.com/hibernate-tip-lazy-loading-one-to-one
따라서 복합키를 사용하여 양방향 관계를 끊어주라고 권장하고 있다.
@Entity
public class Manuscript {
@Id
private Long id;
@OneToOne
@MapsId
@JoinColumn(name = "id")
private Book book;
...
}4. 자식 테이블이 크다면 양방향을 끊어주자.
사실 대부분의 N+1 이슈는 생각없이 짠 양방향 연관관계에서 비롯되는 경우가 많다.
부모만을 조회했는데 쿼리가 N 개 나가는 경우를 보고 놀란 케이스들이다.
왜 그런 일이 있을까 곰곰히 생각해보았다.
나와 같은 경우는 "비즈니스 케이스에 있지도 않은데 생각없이 양방향을 집어넣은" 경우였다.
만약 연관관계 없이 자식 데이터를 가져오려고 했다면 어땠을까?
- QueryDsl 의 Projections 을 사용하여 가져온다.
- IssueComment 에 직접 접근한다.
- 양방향 연관관계가 필요하다는 것을 깨닫고, 이를 후행처리하여 N+1 이슈를 방지한다.
따라서 개발 초기에는 필수적인 부분만 -- 외래키에 대해서만 -- 연관관계를 잡는 것이 좋지 않을까 생각한다.
( 아마 개발 중반, 후반에는 엔티티를 더 이상 건드릴 일이 없을 것이다 )
무엇을 선택해야할까?
정답은 없다.
하지만 국내 대다수의 블로그에서는 이러한 이슈에 대해 거의 무조건적으로 QueryDsl 을 사용하게끔 권고하고 있다.
나는 조금 생각이 다르다.
그냥 굳이 필요가 없다면 차라리 양방향 관계를 안 걸어주는 게 낫다고 본다.
만약 그럼에도 자식 데이터를 가져와야 하는 경우라면 QueryDsl 을 사용하든, JPQL을 쓰던
fetch join 을 쓰거나 할 것 같다.
여기서 덧붙여 Join 으로 인한 성능이 저하된다고 판단되면 역정규화를 하던지 할 것 같다.
Hibernate 에 의한 이슈일 뿐, 비즈니스 컨텍스트에 맞는 해결법을 고르는 것은 개발자의 덕목이라고 생각한다.
Reference
- https://incheol-jung.gitbook.io/docs/q-and-a/spring/n+1
- https://vladmihalcea.com/n-plus-1-query-problem/
- https://vladmihalcea.com/the-best-way-to-map-a-onetoone-relationship-with-jpa-and-hibernate/
- https://www.ankushchoubey.com/n-plus-one-hibernate/
- https://www.baeldung.com/spring-hibernate-n1-problem
- https://thorben-janssen.com/hibernate-tip-lazy-loading-one-to-one
