핵심요약
-
"loop A x loop B 을 사용한 포함여부판별" 은 아래와 같이 개선될 수 있다.
- 전체 원소에 대해 dict 을 정의
- loop 를 통해 각 원소에 대한 substring 이 dict 에 존재하는지 비교, 포함여부 판별
-
zip 자체는 O(1), zip 에 따른 loop 사용은 O(N)
-
zip() 을 사용하여 이웃 간 묶음을 만들 수도 있다.
e.g.
# ["12","123","1235","567","88"]
list(zip(phoneBook, phoneBook[1:]))
=> [('12', '123'), ('123', '1235'), ('1235', '567'), ('567', '88')]문제
문제 설명
전화번호부에 적힌 전화번호 중, 한 번호가 다른 번호의 접두어인 경우가 있는지 확인하려 합니다.
전화번호가 다음과 같을 경우, 구조대 전화번호는 영석이의 전화번호의 접두사입니다.
구조대 : 119
박준영 : 97 674 223
지영석 : 11 9552 4421
전화번호부에 적힌 전화번호를 담은 배열 phone_book 이 solution 함수의 매개변수로 주어질 때, 어떤 번호가 다른 번호의 접두어인 경우가 있으면 false를 그렇지 않으면 true를 return 하도록 solution 함수를 작성해주세요.
제한 사항
phone_book의 길이는 1 이상 1,000,000 이하입니다.
각 전화번호의 길이는 1 이상 20 이하입니다.
같은 전화번호가 중복해서 들어있지 않습니다.
입출력 예제
phone_book return
["119", "97674223", "1195524421"] false
["123","456","789"] true
["12","123","1235","567","88"] false
입출력 예 설명
입출력 예 #1
앞에서 설명한 예와 같습니다.
입출력 예 #2
한 번호가 다른 번호의 접두사인 경우가 없으므로, 답은 true입니다.
입출력 예 #3
첫 번째 전화번호, “12”가 두 번째 전화번호 “123”의 접두사입니다. 따라서 답은 false입니다.
https://school.programmers.co.kr/learn/courses/30/lessons/42577
접근
접근 1) 정렬 이후, len 기준으로 substring 한 문자열 포함여부 판별
각 문자열에 대해 0~l 까지의 문자열을 포함하는지를 판별한다.
def solution(phone_book):
# len 기준으로 정렬
ph = sorted(phone_book,key=lambda phone_book: len(phone_book)) # O(N log N)
# 전화번호부 문자열 중 최대 길이
max_len = len(ph[-1])
# 전화번호부 문자열 중 최소 길이
min_len = len(ph[0])
# 최소~최대 길이의 substring 을 포함하는지 유무를 판별
for l in (min_len,max_len+1): # O(N)
# 포함유무를 임시저장하기 위한 dict
hashMap = dict()
for p in ph:
pOfLength = p[0:l]
# 만약 포함하지 않는다면 dict 에 추가 / 포함한다면 False 반환
if(hashMap.get(pOfLength) == None):
hashMap.setdefault(pOfLength,1)
else:
return False
return True- 주어진 phone_book 길이 기준으로 정렬한다.
- 전화번호부 문자열 중 최대 길이 / 최소 길이 를 구한다.
- 최소~최대 길이의 substring 을 포함하는지 유무를 판별한다.
- 각 길이 l 에 대해서
- 포함유무를 임시저장하기 위한 dict 를 선언
- 각 문자열에 대해 0~l 만큼의 substring 을 구함
- dict 에서 substring 이 존재하지 않는다면 dict 에 추가
- 존재한다면 이전 문자열이 해당 substring을 포함하고 있다는 뜻이므로 False 반환
- 각 길이 l 에 대해서
하지만 해당 접근은 의도대로 되지 않는다.
왜일까?
결론부터 말하자면 0~n 문자열을 0~m 문자열이 포함하는지를 따져야하기 때문에 해결되지 않는다.
0~n 문자열,0~m 문자열 모두 "12" 로 시작하는데 n,m 이 서로 일치하지 않는다면 다른 문자열이다.
(e.g "125", "1273")하지만 위 코드에서는 0~l 까지의 문자열 비교하므로 부분적인 문자열이 포함되어있기만 하는지 확인한다.
즉, 문자열 간 비교를 해야하는데 부분적 비교를 하므로 오류가 발생함
따라서 위 코드는 아래와 같은 케이스가 통과되지 않음
ph = ["123", "1197", "557713", "11987543"] # True
접근 2) 단순하게 접근 :: 모든 원소 간 비교 (feat.이중 loop)
이제 그럼 단순하게 접근을 해보자.
이중 loop 를 통해 모든 원소 간 비교를 (1:1) 하여 포함관계인지를 확인하자
-- startswith() / __contains__() 를 사용하면 str 의 포함유무를 확인 할 수 있다.
-- 속도 측면에서는 __contains__() 가 조금 더 빠르다. __contains__() 는 정적 타입만을 지원하는 반면, startswith() 은 모든 동적 타입을 지원하기 때문이다.
stackoverflow : Why is string's startswith slower than in?
def solution(phone_book):
sortedPhoneBook = sorted(phone_book,key=lambda x : len(x))
for i in range(0,len(sortedPhoneBook)):
for j in range(0,len(sortedPhoneBook)):
if(i == j):
continue
else:
if(sortedPhoneBook[i].startswith(sortedPhoneBook[j])):
return False
return True하지만 아쉽게도 시간복잡도를 초과한다.
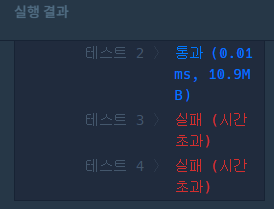
왜냐하면 위 코드는 O(N^3) 이기 때문이다.
-
정렬 : O(NlogN) -- tim sort
-
loop : O(N^3) -- {이중 loop:O(N^2)} X {startswith():C}
* 길이가 1~20 의 문자열이므로 startswith()는 C로 무시할만하다.
따라서 제한조건인 1 이상 1,000,000 이하인 phone_book의 길이로 인해 최대 1,000,000 ^ 2 만큼의 시간복잡도를 가지게 된다
어떻게 하면 개선할 수 있을까??
개선 1) 원소 간 1:1 비교가 아닌, hashMap 을 통해 존재여부 확인
이전 접근법의 문제는 간단하다.
"원소 A에 대한 loop X 원소 B에 대한 loop X 문자열 비교" 로 접근되었기 때문이다.
여기서 문자열 비교는 불가피하다.
그렇다면 loop 를 하나 제거해야만 한다. 어떻게 제거할 수 있을까?
바로 원소 간 1:1 비교가 아닌, hashMap(dict) 을 통해 존재여부 확인 하는 방법이다.
-
전체 원소에 대해 dict 을 정의한다.
-
loop 를 통해 각 원소를 substring, 해당 substring 이 dict 에 존재하는지 판단한다.
아래 예시를 살펴보자.
0 < N < M 길이 관계의 문자열이 존재한다고 보자.
0~N 문자열, 0~M 문자열 모두를 dict 에 저장한다.
이제 loop 를 통해 0~N 문자열, 0~M 문자열 각각에 접근한다.
이제 이 문자열들에 대해 0~1, 0~2 ,,, N,,, M 크기의 substring 을 하나씩 차근차근 만들게 된다.
이 때 0~M의 문자열의 substring 이 0~N 문자열이라고 가정해보자.
0~N 문자열은 dict 에 저장되어있으므로 해당 substring은 dict 에 존재한다.
따라서 substring 이 dict 에 있어 부분문자열이라고 판단, 비교로직을 종료하게 된다.
이제 코드를 살펴보자.
def solution(phone_book):
hashMap = {}
for nums in phone_book: # O(N)
hashMap[hash(nums)] = nums
for nums in phone_book:
arr = ""
for num in nums:
arr += num
if hash(arr) in hashMap and arr != nums:
return False
return True접근법에 따라 하나씩 코드를 분석해보자.
1. 전체 원소에 대해 dict 을 정의한다.
hashMap = {}
for nums in phone_book: # O(N)
hashMap[hash(nums)] = nums2. loop 를 통해 각 원소를 substring, 해당 substring 이 dict 에 존재하는지 판단한다.
for nums in phone_book:
arr = ""
for num in nums:
arr += num
if hash(arr) in hashMap and arr != nums:
return False이 접근법은 O(N) 시간복잡도이므로 훨씬 개선된 것을 볼 수 있다. -- 이전 : O(N^2)
-
전체 원소에 대해 dict 을 정의 : O(N)
-
substring 구한 뒤, dict 에 존재여부 판별 : O(1)
-
각 원소에 대한 loop : O(N)
-
원소의 각 index 에 대한 substring 계산 : C
* 각 원소의 길이가 1~20 이므로 거의 무시할만한 연산이다. -
dict 에 존재하는지 판별 : O(1)
-
-
개선 2) sort() 이후, zip() 에 의한 iteration 을 통해 부분포함 관계 판별
조금 더 영리하게 접근할 수 있다.
알파벳 순으로 정렬 이후 이웃 간 비교를 해주면 된다.
이에 따라 아래와 같이 접근할 수 있다.
- sort() 를 통해 알파벳 순으로 정렬해준다.
phoneBook.sort()- zip() 을 통해 이웃 간 묶음 처리를 해준다.
for p1, p2 in zip(phoneBook, phoneBook[1:]):- 이웃 간 묶음 간에 비교연산을 통해 판별한다.
for p1, p2 in zip(phoneBook, phoneBook[1:]):
if p2.startswith(p1):
return False
return True위 코드는 O(N) 으로 인해 개선된 점을 알 수 있다.
zip()과 sort()를 통해 의존도는 높아졌지만, 코드도 간결해지고 더욱 빨라졌다.
-
zip() 을 통해 이웃 간 묶음 처리 : O(1)
-
묶음 처리에 대한 loop : O(N)
-
startswith() : C
* 각 문자열의 최대길이가 20이므로 무시할만하다.
Reference
Tistory : [프로그래머스] 전화번호 목록 문제 풀이(해시 Lv. 2) - 파이썬 Python
출처: https://coding-grandpa.tistory.com/86 [개발자로 취직하기:티스토리]
python-zip
stackoverflow : time-complexity-of-zip-in-python
stackoverflow : Why is string's startswith slower than in?
