
메모리 시스템은 서로 다른 용량, 가격, 접근 시간을 가지는 저장장치들의 위계(hierarchy)로 구성되어 있다. CPU cycle 수로 따져보면 일반적으로 다음과 같다.
- CPU register (0 cycle) < Cache (4~75) < Main memory(수 백 사이클) <<< Disk (수 천만 사이클)
6.1. Storage Technologies
Random Access Memory(RAM)
DRAM과 SRAM
SRAM은 Static RAM의 약자로, “bistable”한 특징을 가진다. 즉, LOW 또는 HIGH voltage를 항상 유지하려 하고, 다른 voltage가 주어지면 둘 중 하나로 수렴한다. SRAM은 트랜지스터 6개를 사용하며, 이 때문에 가격이 DRAM보다 비싸다. Bistablity로 전원이 켜져 있는 한 disturbance가 있어도 원 상태로 복원된다. 때문에 refreshing이 필요하지 않아 속도가 DRAM보다 빠르다.
반면 Dynamic RAM(DRAM)은 캐패시터의 전하 형태로 정보를 저장한다. 이 때문에 SRAM보다 disturbance에 취약하다. DRAM은 가만히 두면 leakage current 때문에 전하가 계속 손실되어 전압이 낮아진다. 따라서 주기적으로 refresh를 해주어야 해 속도가 느리다. 반면 트랜지스터를 2개만 사용해 값이 싸고 용량이 SRAM보다 크다.
전통적 DRAM의 구조
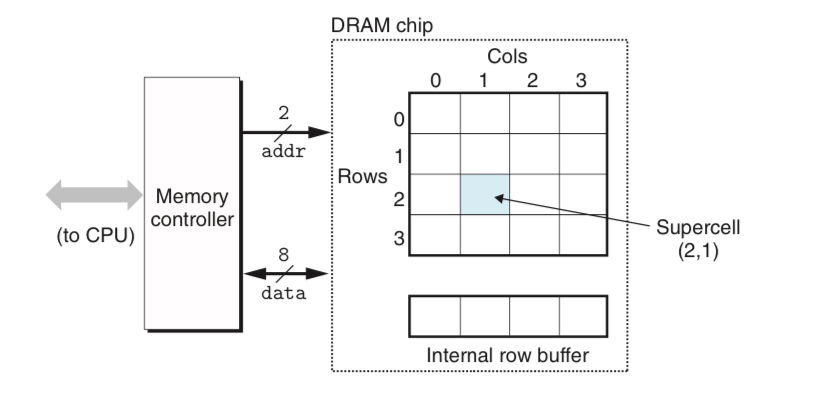
Conventional DRAM은 개의 supercell에 각각 개의 DRAM cell이 들어있어, 총 bit의 정보를 저장할 수 있는 방식이다.
- supercell은 의 2차원으로 배열되어 있다. ().
메모리 컨트롤러가 연결되어 있어 한번에 비트씩을 전송/수신할 수 있게 되어 있다.
e.g. supercell에서 정보를 읽어오려면 메모리 컨트롤러로 를 보낸 후(RAS, row access strobe) 를 보낸다(CAS, column access strobe)
이는 address pin의 개수를 줄이기 위함으로, 시간은 오래 걸린다는 단점이 있다 - Memory Module: DRAM은 메모리 모듈로 패키지되어 있다. 예를 들어 64MB module이 있다면, 8Mb x 8 = 64Mb의 DRAM chip을 8개 사용하여 8개가 각각 0~7번째 비트, 8~15번째 비트, …, 56~63번째 비트를 담당하도록 하는 식이다.
Enhanced DRAM
메모리 기술이 발전하면서 conventional DRAM의 큰 틀 자체는 변하지 않은 채로 조금씩의 변형이 추가되면서 SDRAM, DDR SDRAM 등이 등장하였다. 자세한 부분은 pp. 621-622에 나와있다.
비휘발성 메모리
비휘발성 메모리(Nonvolatile Memory)는 역사적인 이유로 Read-Only Memory(ROM)으로 불려왔으나, 실제로는 쓰기가 가능한 것도 있다. 대표적으로 PROM, EPROM, EEPROM, Flash Memory, SSD 등이 비휘발성 메모리에 속한다.
ROM 장치에 주로 저장되는 프로그램 중에는 펌웨어(firmware)가 있으며, BIOS 등 컴퓨터가 처음 켜질 때 작동하는 프로그램들이 주로 여기에 속한다.
메인 메모리로의 접근
DRAM과 프로세서간의 데이터 전송은 Bus를 통해 발생한다. 이를 Bus transaction이라고 한다.
- bus란 주소나 데이터, control signal을 옮기는, 병렬로 연결된 wire들의 집합이다.
- 주소와 데이터가 같은 버스를 사용할 수도, 다른 버스를 사용할 수도 있으며 여러 개의 장치가 같은 버스를 공유할 수도 있다.
일반적으로 프로세서와 DRAM 사이의 연결은 다음과 같은 구조로 되어 있다.
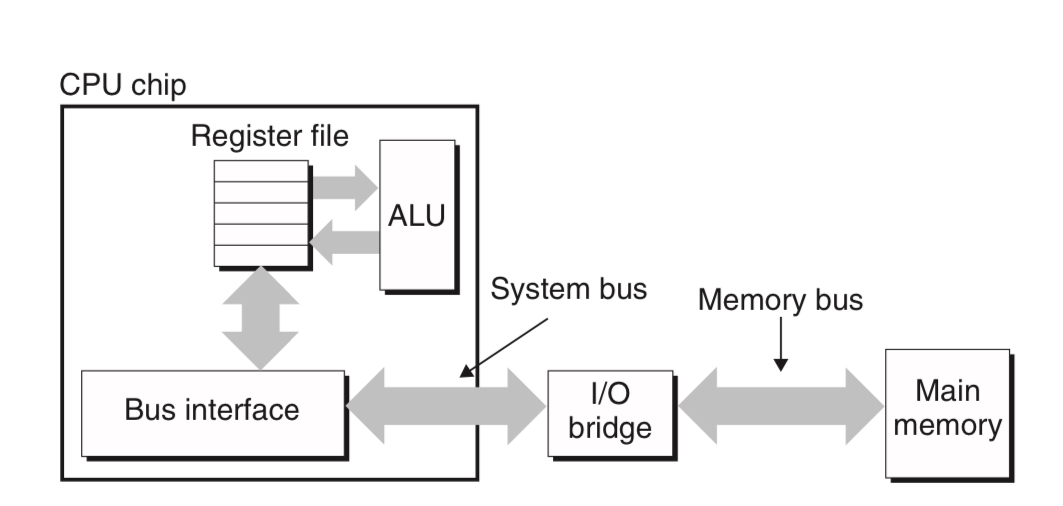
그림에 나와있듯이,
- 시스템 버스: CPU와 I/O bridge를 연결하는 버스
- 메모리 버스: I/O bridge와 메모리를 연결하는 버스
이며, I/O bridge는 중간에서 시스템 버스와 메모리 버스의 신호를 서로 번역해주는 역할을 한다. DRAM의 접근에 사용되었던 메모리 컨트롤러 또한 I/O bridge의 일부이다.
예를 들어서, 프로세서가 movq A, %rax라는 load instruction을 읽는다고 하면,
1. CPU가 address A를 시스템 버스에 놓고,
2. I/O bridge가 이를 메모리 버스로 전달하며
3. 메인 메모리가 A의 데이터를 읽어 다시 메모리 버스를 통해 전달하면
4. I/O bridge가 메인 메모리의 신호를 번역해 %rax로 값을 복사해주는 식으로 작동한다.
디스크 저장장치
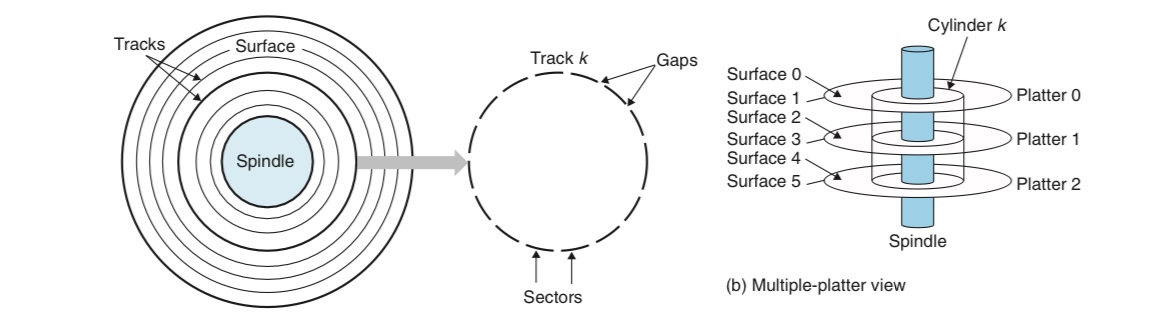
디스크의 구조는 위의 그림처럼 구성되어 있다. 이때 디스크의 용량을 결정하는 변수들에는
1. 기록 밀도(recording density): 트랙의 단위길이당 기록되는 비트의 수
2. 트랙 밀도(track density): 반지름의 단위길이당 트랙의 수
3. 면적 밀도(areal density): 위 둘의 곱
등이 있다.
디스크가 읽고 쓰는 동작 수행할 때는, actuator arm에 달린 Read/write head가 이를 담당하게 된다. 읽기와 쓰기는 섹터 크기의 블록 단위로 수행되며, 읽기/쓰기 속도에 영향을 미치는 다음의 3요소가 존재한다.
- seek time: 헤드가 목표 위치 위에 자리잡기까지 소요되는 시간으로, 이전 위치에 의존한다
- rotational latency: 트랙의 첫 비트를 찾아야 하는데 간발의 차로 놓쳤다면 한 바퀴를 다시 돌아야 한다. 으로 계산되며, 평균적으로는 이다.
- transfer time: 한 섹터 내에서 이동하는 데 걸리는 시간으로,
이다.
디스크는 이러한 복잡한 구조를 OS로부터 숨기고 섹터 크기의 logical disk block 개를 OS에 제공한다. 디스크 컨트롤러는 이를 실제 물리적 디스크와 매핑하는 역할을 수행한다.
I/O 장치의 연결
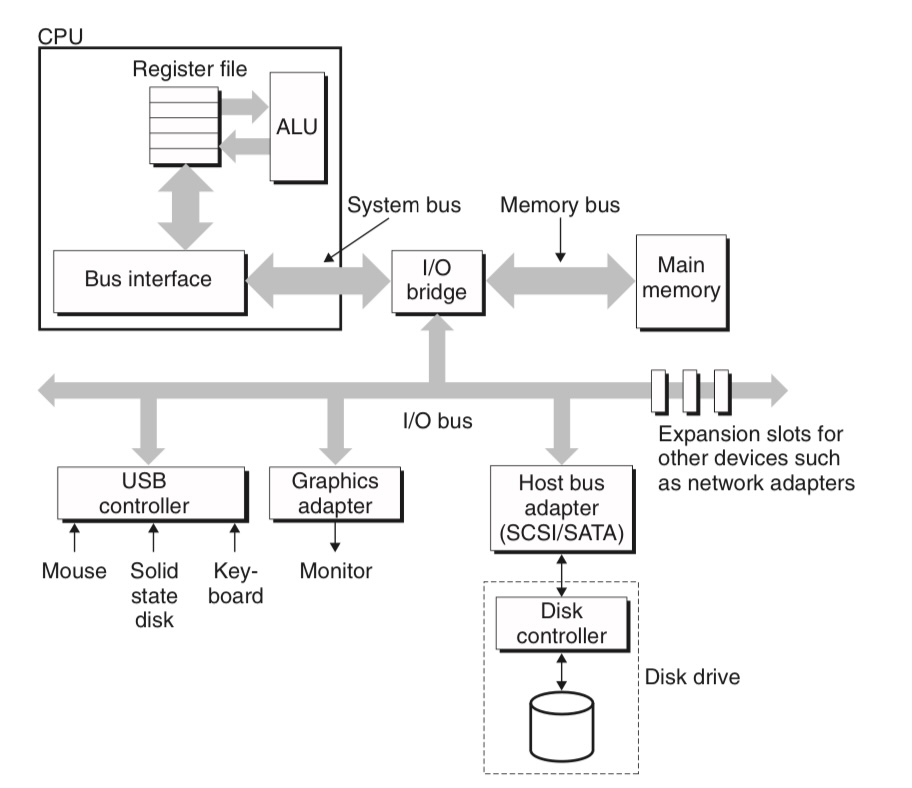
컴퓨터 시스템은 보통 다양한 third-party I/O 장치를 지원하며,
디스크를 포함해 키보드, 마우스, 그래픽 카드 등의 I/O 장치는 I/O 버스를 통해 시스템에 연결된다. CPU-specific한 시스템 버스, 메모리 버스와는 달리 I/O 버스는 CPU에 무관한 규격이다.
I/O 버스는 시스템 버스나 메모리 버스보다는 느리지만 훨씬 다양한 장치를 연결할 수 있도록 설계되어 있다. 그림에는 세 종류의 장치가 I/O 버스에 연결되어 있다.
- USB(Universal Serial Bus) 컨트롤러: peripheral device를 연결하는 데 가장 보편적인 규격
- Graphics adapter
- Host bus adapter: host bus interface라는 규격에 따라서 하나 이상의 디스크를 연결하는 역할을 한다. 대표적으로 많이 쓰이는 host bus interface에는 SATA와 SCSI가 있다.
- 일반적으로 SCSI가 SATA보다 빠르며, SATA가 하나의 디스크만을 연결할 수 있는 데 비해 SCSI는 여러 개의 디스크를 연결하는 것이 가능하다
디스크 데이터의 접근
CPU는 I/O 장치에 명령을 내리기 위해 Memory-mapped I/O라는 테크닉을 사용한다. Memory-mapped I/O에서, CPU는 address space의 일부를 I/O 장치와의 통신을 위해 할당한다. 여기서 할당된 주소들은 I/O port라고 한다. 예를 들어서 메모리 주소 중 0xa0부터 0xaf까지는 실제 메모리가 없고 여기에 읽기/쓰기를 하면 I/O 장치가 동작하는 식이다.
디스크의 한 섹터를 읽는 것을 예로 들어보자.
1. CPU가 0xa0에 세 번의 store operation을 한다. 이는 각각 initialize, logical block 번호, 해당 디스크 섹터가 저장될 메인 메모리 상의 위치를 나타낸다
2. 디스크가 읽기 작업을 수행하는 동안 CPU는 보통 다른 작업을 수행한다.
3. 디스크 컨트롤러는 CPU로부터 명령을 받아 logical block 번호를 섹터 주소로 번역하고 섹터를 읽어 메인 메모리로 가져온다. 이 과정에서는 CPU가 개입되지 않고 전부 I/O 장치가 스스로 수행하는데, 이를 Direct Memory Access(DMA)라 하며 데이터의 전송은 DMA transfer라고 한다.
4. DMA transfer가 끝나 디스크 섹터의 내용이 메인 메모리에 옮겨지면 디스크 컨트롤러는 CPU에 인터럽트 신호를 보내 알린다.
Solid State Disk(SSD)
SSD는 플래시 메모리 기반 저장장치로, I/O 버스에 연결되어 디스크와 동일한 행동을 한다.
- 디스크에 디스크 컨트롤러가 존재하듯, SSD에는 이와 대응되는 역할을 하는 flash translation layer가 있어 역할을 수행한다
- SSD는 여러 블록(block)으로 구성되고, 각 블록은 여러 개의 페이지(page)로 구성된다.
- SSD는 읽기보다 쓰기가 느리다는 특징을 가지는데, 이는 데이터를 페이지 단위로만 읽고 쓸 수 있기 때문이다. 쓰기를 하려면 먼저 해당 페이지를 전부 지워야 하는데, 이미 페이지에 내용이 있는 상태였다면 내용을 전부 옮겼다가 다시 불러와야 하기 때문에 속도가 느리다.
6.2. Locality
잘 짜여진 프로그램은 보통 좋은 locality를 가진다. 이는 최근 접근한 item 근처의 item에 자주 접근하는 경향이 있음을 나타낸다. 이를 Principle of Locality라 하며, HW와 SW의 디자인과 성능에 큰 영향을 끼친다.
Locality에는 temporal locality와 spatial locality가 있다. Temporal locality는 최근 접근한 item을 다시 접근하는 것을 말하며, spatial locality는 최근 접근한 item 근처의 item을 후에 다시 접근하게 된다는 것을 의미한다.
컴퓨터 시스템은 하드웨어 단계에서부터 OS, 애플리케이션 SW에 달하기까지 모든 단계에서 locality를 이용한다.
- HW의 경우 캐시(cache) 메모리가 최근 참조된 instruction이나 data의 블록을 hold하여 속도를 향상하는 방법을 사용하며,
- OS는 메인 메모리를 virtual address space나 디스크 블록에 대한 캐시로 사용한다.
- 애플리케이션 소프트웨어의 경우 웹 브라우저가 최근 접속한 사이트의 데이터를 캐시해두는 것을 예시로 들 수 있다.
다음의 프로그램을 보자.
int sumvec(int v[N]){
int i, sum = 0;
for(i = 0, i < N; i++){
sum += v[i];
}
return sum;
}이 프로그램을 보면, 변수 sum이 계속해서 접근되므로 sum에 대해서는 좋은 temporal locality를 가진다고 할 수 있다. 반면 sum은 스칼라 타입의 데이터이므로 인접한 데이터가 접근되지는 않아, spatial locality는 없다고 볼 수 있다.
반면 v[i]는 각 원소가 한번씩만 접근되므로 temporal locality는 없고, 연속된 원소가 계속해서 접근되니 좋은 spatial locality를 가진다고 할 수 있다.
- 위 프로그램에서의
v[i]와 같이 벡터의 원소가 연속적으로 접근되는 것을 stride-1 reference pattern이라 부른다. Stride는 특히 다차원 배열에서 중요하게 작용하며, 일반적으로 stride가 클수록 spatial locality는 떨어진다.

-
위와 같이 이중 루프의 순서를 바꾸는 것은 spatial locality를 크게 떨어뜨리며, 성능에 큰 영향을 주게 된다.
-
Instruction의 fetch 또한 메모리와 연관되므로 프로그램의 성능에 있어 locality의 영향을 분석할 수 있다.
6.3. The Memory Hierarchy
Memory hierarchy는 일반적으로 다음의 원칙에 따라 구성되어 있다.
level 의 빠르고, 작고, 비싼 저장장치가 level 의 느리고, 크고, 값싼 저장장치를 cache한다.
- 이 때 일반적으로 단계와 단계에서, 데이터는 똑같은 크기의 블록들로 분할되어 있다. 단계보다 단계의 블록 수가 더 많아 용량에 차이가 나는 식이다. 캐시를 할 때 단계의 저장장치는 단계에서 블록 단위로 데이터를 복사해온다. 이 때 블록을 transfer unit이라고 부른다.
- 일반적으로 인접한 레벨 사이의 transfer에 사용되는 블록의 크기는 일정하지만, 다른 단계의 쌍끼리는 블록 크기가 다르다. 예를 들어서, L1-L2 캐시의 전송에는 수십 바이트의 블록이 사용되지만 L4-L4 캐시끼리는 수백 바이트 이상 크기의 블록이 사용된다.
단계의 저장장치에서 찾고 있는 object가 운이 좋게 단계에서 발견된다면, 이를 cache hit이라 한다. 이 경우 단계에서 빠르게 데이터를 읽어들이면 된다. 반면 단계에 찾고 있는 데이터가 없다면 단계에서 데이터를 가져와 단계에 저장한 후에 이를 제공해야 해 시간이 오래 걸린다. 이 경우는 cache miss라고 불린다.
- Cache miss가 나서 단계에서 데이터를 가져왔는데 단계에 용량이 꽉 차서 저장할 공간이 없을 수도 있다. 이 경우 블록 중 하나(또는 그 이상)를 골라 덮어쓰기를 해야 하는데, 이를 evicting이라고 표현하며 덮어쓰기를 당하는 블록은 victim이라고 한다.
- replacement policy란 victim을 선택하는 방법을 의미하는데, 대표적으로 random replacement policy, least recently used(LRU) policy 등이 있다.
Cache miss의 종류
Cache miss가 일어나는 원인은 여러 가지가 있다.
- Compulsory miss: 캐시가 비어있기 때문에(cold cache) 불가피하게 발생하는 miss이다. 캐시가 계속 사용되고 나면 steady state에는 당연히 발생하지 않는다.
- Conflict miss: placement policy의 충돌로 인해 발생한다.
- placement policy란 단계의 특정 블록에는 단계의 몇번 몇번 블록만이 올 수 있는 식으로 제한을 두는 것을 말한다. 단계의 모든 블록이 단계의 모든 블록에 캐시될 수 있도록 한다면 좋겠으나 이는 너무 costly하기 때문에 placement policy가 정해져 사용된다.
- conflict miss가 발생하는 예시를 들자면, 단계의 같은 블록으로 매핑되는 단계의 두 블록이 번갈아서 접근되는 경우가 있다. 이런 경우 두 블록이 번갈아 evict되면서 계속해서 miss가 일어난다.
- Capacity miss: 프로그램의 현재 phase가 접근하는 “working set”이 캐시의 크기보다 큰 경우 불가피하게 miss가 일어날 수밖에 없다.
이렇게 캐시를 관리하기 위해서는 캐시 저장장치를 블록 단위로 나누고, 인접 레벨 사이에서 transfer를 시키며 hit/miss를 판별하고 처리하는 로직이 필요하다. 보통 이는 프로그램의 명시적인 컨트롤이 없어도 알아서 잘 작동하도록 설계되어 있다.
6.4. 캐시 메모리
컴퓨터가 발전하면서 CPU와 메인 메모리의 속도 사이 갭도 점점 커져갔고, 이에 따라 점점 더 많은 수의 캐시를 사용하게 되었다. 여기에서는 L1 캐시만이 있는 경우만을 다룬다.
캐시 메모리의 일반적인 구조
메모리 주소가 비트, 즉 주소가 개인 컴퓨터 시스템을 고려하자.
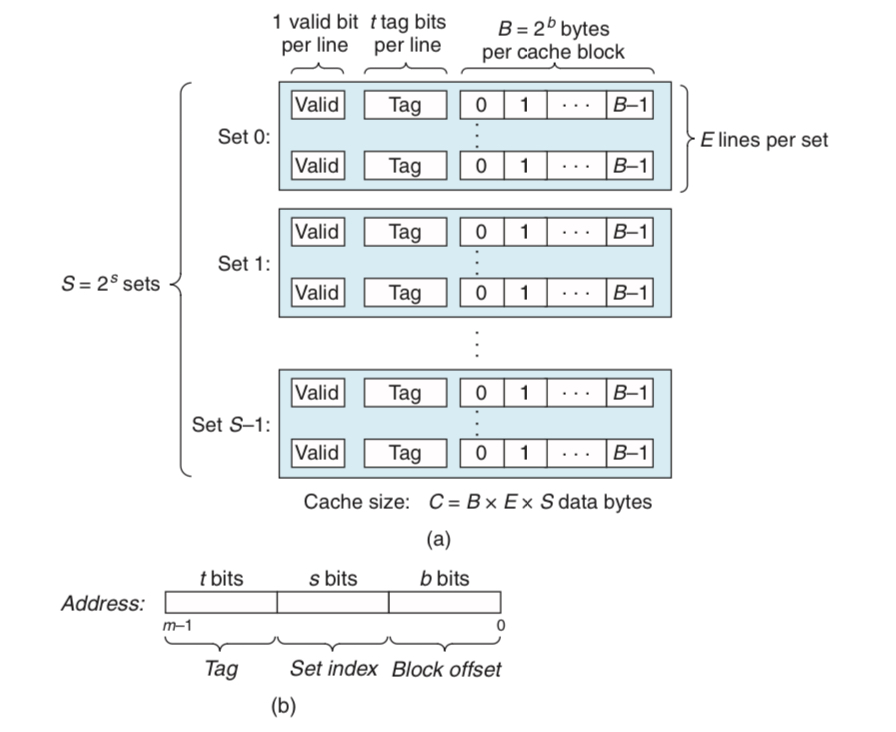
위 그림에서,
- 캐시는 개의 cache set으로 구성된다.
- 각 cache set은 다시 개의 cache line으로 구성된다.
- 각각의 cache line은
1. 바이트의 data block과
2. 1비트짜리 valid bit
3. 개의 tag bit로 구성되어 있다.
즉, 캐시의 구조는 순서쌍 으로 표현할 수 있으며 이 경우 용량은 이다. Tag나 valid bit은 용량에 포함되지 않고, 오로지 data block만이 용량을 셀 때 들어간다.
캐시는 match/miss를 판별하기 위해 위와 같은 간단한 해시(hash) 구조를 사용한다. CPU가 메모리의 주소 에 접근하고 싶어한다고 하자. 비트짜리 주소 는 앞에서부터 다음과 같이 분할한다.
- tag bit 비트
- set index 비트
- block offset 비트
그러면 접근은 다음과 같은 과정으로 이루어진다.
1. Set selection
주소에서 가운데 비트의 set index를 개의 cache set 중 몇 번째 set에 접근할 것인지 판별하는 데 사용한다.
2. Line matching
선택된 cache set의 개 cache line을 살펴보면서, tag가 address의 tag(맨 앞 비트)와 일치하는 것이 있는지 찾는다. 만약 일치하는 것이 있고 valid bit가 1이라면, 접근하고자 하는 데이터 블록이 캐시에 저장되어 있는 것이다.
* 만약 그런 것이 없다면 cache miss이다
3. Word extraction
Cache line의 data block에서 block offset번째 비트가 주소 에 해당하는 데이터이다.
캐시의 분류
캐시는 cache line의 개수 에 따라서 세 가지로 나뉠 수 있다.
- Direct mapped cache: 일 경우
- 즉, 각 cache set에 cache line이 하나밖에 없게 된다.
- Set associative cache: 인 경우
- cache set도 여러 개이고, cache line도 여러 개인 경우이다.
- Fully associative cache: , 즉 인 경우
- cache set이 하나밖에 없는 경우이다.
Direct Mapped Cache
Direct mapped cache는 한 cache set에 line이 하나밖에 없으니 이해와 구현이 가장 간단하다. 이 경우 데이터 접근 방법은 다음과 같다.
1. Set selection
주소의 가운데 비트를 unsigned int로 취급해 set 번호를 알아내고, set을 선택한다.
2. Line matching
Set 내에서 line을 선택한다. 여기서는 line이 하나밖에 없으므로, 유일한 cache line에서 valid/tag bit를 확인해주면 끝이다.
3. Word extraction
Address의 맨 끝 비트를 block offset으로 취급해 block 내에서 원하는 데이터를 찾는다.
한편, cache miss가 발생할 시 다음 단계의 메모리로부터 원하는 데이터를 가져와야 한다. 이 때 모든 line의 valid bit가 1이라면 evicting이 불가피하게 되는데, direct mapped cache에서는 메모리 주소와 set line 사이의 매핑이 injection(다대일)이므로 victim이 바로 결정된다. (즉 replacement policy가 자명하다)
Direct mapped cache의 conflict miss
Direct mapped cache의 경우, 크기가 2의 거듭제곱인 배열 여러 개에 접근하면 conflict miss가 발생하기 쉽다. (p.658 참고) Set에 line이 하나뿐이기 때문에, set index가 같은
두 주소에 계속 접근하게 되면 load와 evict를 반복하는 thrashing이 일어나는 것이다. 이는 block size만큼의 padding을 더함으로써 set index를 다르게 만들어 쉽게 해결이 가능하다(p. 660).
Set Associative Cache
Cache set이 여러 개이고, 각 set당 line의 수도 여러 개인, 가장 일반적인 경우이다. 이 경우 여러 개의 set line중에 매칭되는 것(즉 tag가 같고 valid가 1인 것)이 있는지 전부 확인해야 하므로 구현이 direct mapped cache보다 복잡하다.
Set associative cache에서, associative는 associative memory에서 따온 것이다. Associative memory는 주소와 값 사이의 매핑인 conventional memory와 대조되는 개념으로, (key, value)의 집합을 저장해놓고 읽을 때는 key에 대응되는 값 value를 찾는 방식으로 작동한다.
Set associative cache에서는 tag가 바로 key의 역할을 수행하는 것으로 이해할 수 있다. 즉, set associative cache의 각 set은 associative memory이다.
Miss 발생 시의 line replacement
Set associative cache는 direct mapped cache와 달리 set line이 여러 개 있으므로 miss 발생 시에는 어느 line을 evict할 지를 결정해야 한다.
- 빈 line이 있으면 당연히 그 line을 쓰면 되지만,
- 모든 line이 valid라면 line 중 하나(victim)를 선택해서 evict하고, 당분간 프로세서가 victim을 참조하지 않기를 바라는 수밖에 없다.
앞에서도 살펴봤듯이 이를 위해 replacement policy가 필요하며, random replacement, least frequently used(LFU), least recently used(LRU) 등이 존재한다. Replacement policy를 구현하려면 복잡한 하드웨어가 추가되어야 하지만, 특히 memory hierarchy의 아래쪽으로 갈수록 miss penalty가 점점 커지기 때문에 보통은 그럴만 한 가치가 있다.
Fully Associative Cache
Fully associative cache는 cache set이 하나뿐으로, set selection 과정이 자명해지는 것을 제외하면 메모리 접근 방법은 set associative cache와 크게 다르지 않다.
그러나 이 경우 set line이 너무 많아져 line matching을 위한 하드웨어가 너무 복잡해지고 비용이 많이 들게 된다. 따라서 fully associative cache는 용량이 작은 경우에만 예외적으로 사용된다.
캐시 쓰기에 관련된 문제점
캐시 데이터를 읽는 과정은 앞에서 살펴본 바와 같이 간단하다. 그러나 캐시에 쓰는 과정은 더욱 복잡한데, 크게 write hit을 처리하는 방식과 write miss를 처리하는 방식에 따라 각각 두 가지로 분류할 수 있다.
먼저 쓰려는 데이터가 write hit(즉 특정 주소에 쓰기를 하려는데 해당 주소의 데이터가 캐시에 있는 경우)을 처리하는 방식은 다음이 있다.
- write-through: 즉시 아래 레벨에 업데이트된 데이터를 전달해 업데이트시킨다.
- write-back: 아래 레벨의 업데이트를 최대한 미뤄두다가, replacement algorithm에 의해 블록이 evict되면 그제서야 업데이트하는 방식이다.
Write miss(쓰기를 하려는 주소의 데이터가 캐시에 없는 경우)를 처리하는 방식은 다음으로 나뉜다.
- Write-allocate: missing data를 아래 단계의 메모리에서 찾아 캐시에 가져온 후에 업데이트 시킨다.
- No-write-allocate: 캐시를 건너뛰고 아래 단계의 메모리에 직접 업데이트시킨다.
일반적으로 write-through와 no-write-allocate가 함께 사용되고, write-back은 write-allocate와 함께 사용된다. 이중 더 많이 사용되는 것은 후자인데, 다음 절에서 프로그램 최적화를 설명할 때에는 후자의 모델을 가정한다.
캐시의 실제 구조
위에서는 데이터를 저장하는 캐시(d-cache)만을 다루었지만, 실제로 캐시는 데이터뿐만 아니라 instruction 또한 저장할 수 있다. 이를 i-cache라고 한다. 둘을 한꺼번에 저장하는 unified cache도 존재하지만 최근에 나오는 프로세서는 보통 i-cache와 d-cache를 분리시킨 구조를 채택한다. 이렇게 하면
- 데이터와 instruction을 동시에 읽을 수 있고
- 일반적으로 읽기전용인 i-cache에 d-cache와는 다른 최적화 방법을 적용할 수 있으며
- 데이터와 instruction이 서로 conflict miss를 일으키는 것을 방지할 수 있다.
캐시 파라미터들이 성능에 미치는 영향
캐시의 성능을 측정하는 척도로는 크게 다음이 있다.
-
miss rate와 hit rate
-
hit time과 miss penalty
으로 나타내었던 변수들을 포함해 여러 캐시 파라미터들이 캐시의 성능에 어떤 영향을 끼치는지 알아본다. -
캐시 용량의 영향: 캐시의 크기가 크면 hit rate는 올라가겠지만, 너무 크면 hit time이 커지는 효과가 생긴다.
-
블록 크기의 영향
블록의 크기가 크면 spatial locality를 잘 활용할 수 있게 되지만, 용량이 고정되어 있을 때 블록의 크기가 커진다는 것은 cache line의 개수가 줄어든다는 것을 의미한다. 이 경우 spatial locality보다 temporal locality가 강한 프로그램의 경우 성능이 낮아질 수 있다.
또한 블록이 크면 transfer time이 커지기 때문에 miss penalty가 커지는 효과가 생긴다. -
Associativity()의 영향
, 즉 set당 line의 개수가 많아지면 conflict miss의 가능성이 낮아진다. 그러나 동시에 구현이 어려워지고 빠르게 만들기가 힘들어진다. 또한, LRU(least recently used) replacement policy로 구현된 캐시의 경우 state bit가 더 많이 필요하게 되며 control logic도 복잡해져 hit time이 길어진다. -
Writing Strategy의 영향
- Write-through: 구현이 쉽고 write buffer를 사용할 수 있다. 또한 write-back 캐시에서 read miss시 evict 후 write-back이 일어날 수 있는 데 비하여 read miss에 상대적으로 관대하다.
- Write-back: transfer가 적게 일어나 bandwidth를 적게 차지한다. 즉 다른 I/O device에게 BW를 양보하게 된다. Hierarchy의 아래쪽으로 내려갈수록 이는 더 큰 장점이 되는데, 아래쪽으로 갈수록 transfer time이 늘어나 BW가 중요해지기 때문이다.
6.5. 캐시친화적인 코드를 짜는 법
캐시친화적인 코드로 성능을 향상시킬 때에는 두 가지 원칙을 따라야 한다.
- Make the common case go fast
- Minimize number of cache misses in the inner loop
위에서 봤던 프로그램을 다시 가져와보자.
int sumvec(int v[N]){
int i, sum = 0;
for(i = 0, i < N; i++){
sum += v[i];
}
return sum;
}위 프로그램을 보면,
- 지역변수
i와sum에 반복적으로 접근하고 있으므로, optimizing compiler라면 hierarchy의 최상위 메모리인 CPU 레지스터에 이를 저장할 것이다. 이는 temporal locality가 매우 좋음을 의미한다. - 또한
v[i]에 stride-1 reference로 접근하고 있으므로 spatial locality 또한 좋다.- 일반적으로, stride- reference의 경우 캐시의 블록 크기가 일 때, 평균 번의 miss를 일으킴이 알려져 있다.
다중루프로 다차원 배열을 접근할 때 캐시친화성에 특히 유의해야 하는데, 반복문의 순서에 따라서 실질적 stride가 1이 될수도, 배열의 폭이 될수도 있기 때문이다. 책의 예시에서는 무려 25배의 속도 차이가 난 경우를 보여주고 있다.
