HTML
HTML(Hyper Text Markup Language) : 웹 문서를 만들기 위하여 사용하는 기본적인 웹 언어의 한 종류.
인터넷에서 웹을 통해 접근되는 대부분의 웹 페이지들은 HTML로 작성된다. 각종 태그들로 이루어져있으며 요새는 HTML5 표준을 사용!
HEAD tag : 눈에 보이진 않지만 문서에 필요한 헤더 정보를 보관
title : 탭 제목
BODY tag: 눈에 보이는 정보를 보관
p(paragraph) : 문장
html태그는 아래와 같이 이루어져있다.
<!DOCTYPE html>
<html>
<head>
<title>Very Simple HTML Code By ZeroBase</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">
Happy ZeroBase.
<a href="http://www.pinkwink.kr" id="pw-link">PinkWink</a>
</p>
<p class="inner-text second-item">
Happy Data Science.
<a href="https://www.python.org"target="_blink" id="py-link">Python</a>
</p>
</div>
<p class="outer-text first-item" id="second">
<b>Data Sience if funny.</b>
</p>
<p class="outer-text">
<i>All I need is Love</i>
</p>
</body>
</html>BeautifulSoup
- HTML, XML 문서를 구조적으로 분석하여 원하는 데이터를 쉽게 추출하게 도와주는 모듈
- open : 파일명과 함께 읽기(r), 쓰기(w) 속성을 지정
- html.parser : BeautifulSoup의 html을 읽는 엔진 중 하나, 더 빠른 lxml도 사용가능
- prettify() : html 출력을 예쁘게 만들어 줌
from bs4 import BeautifulSoup
page = open("./data/03. test_first.html","r").read()
soup = BeautifulSoup(page,"html.parser")
print(soup.prettify())
.body : body태그가 속한 부분을 반환
-
특정 태그 찾기
-
find("찾을 태그, 속성") : 가장 먼저 찾은 태그 하나를 출력
id의 경우 HTML 내에 하나만 존재한다! -
findall("찾을 태그, 속성") : 찾은 태그 모두를 출력, id나 클래스(class="찾을클래스")처럼 지정가능, list형태로 반환함
-
select_one : find와 같은 기능
-
select : find_all과 같은기능, >를 이용해 내부 1단계 뎁스에서 찾기 가능, .을 이용해 클래스찾기 가능
soup.select("head > title")
soup.selet(".value")
-
soup.p
soup.find("p")
soup.find("p", class_="inner-text first-item")
soup.find("p",{"class":"outer-text first-item", "id":"first"})
-
텍스트 부분 출력
- .text()
- .get_text()
-
태그에서 속성 출력
- .get("속성명")
- ["속성"] 으로도 접근 가능!
soup.find_all("a")
soup.find_all("a")[0].get("href")
soup.find_all("a")[0]["href"]
for each in soup.find_all("a"):
href = each.get("href")
text = each.get_text()
print(text + " => " + href)
크롬 개발자 도구
크롬설정 - 도구 - 도구더보기 - 개발자도구 또는 ctrl + shift + i 또는 F12를 사용해 실행가능.
선택을 이용해 특정 html위치 찾기 용이
환율정보 가져오기
urllib.request : 웹주소(URL)에 접근할 때 필요한 모듈
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
page = urlopen(url)
# response, res라는 변수명도 많이 사용 !, page.status를 사용해 http상태코드 출력가능
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify)
# 환율 정보를 찾기
soup.find_all("span",class_="value")
# class 생략해도 됨
soup.find_all("span","value")import requests
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
response #request 모듈은 바로 http 상태코드 출력됨
soup = BeautifulSoup(response.text,"html.parser")
# id => #
# class => . exchangeList = soup.select("#exchangeList > li")
#내부에 알고싶은 정보를 찾기
title = exchangeList[0].select_one(".h_lst").text
exchange = exchangeList[0].select_one(".value").text
change = exchangeList[0].select_one(".change").text
updown = exchangeList[0].select_one("div.head_info> .blind").text
baseUrl = "https://finace.naver.com"
baseUrl + exchangeList[0].select_one("a").get("href")
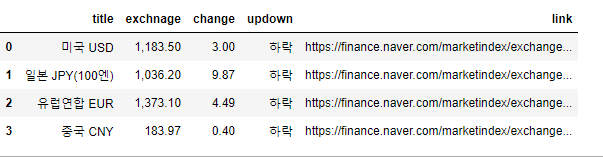
# 띄어쓰기는 클래스 속성값 2개가 있다로 생각하면됨, 그래서 . 으로 써줘야됨import pandas as pd
exchange_datas = []
baseUrl = "https://finace.naver.com"
for item in exchangeList:
data = {
"title":item.select_one(".h_lst").text,
"exchange":item.select_one(".value").text,
"change":item.select_one(".change").text,
"updown":item.select_one("div.head_info> .blind").text,
"link" : baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfiance.xlsx",encoding="utf-8")