이번 MSA 스터디의 마지막 장인 14장에서는 '분산 추적'을 사용해 마이크로서비스의 연동 방식을 파악하는 방법을 배운다. (공조 MS 시스템 환경 관리에 분산 추척 활용 가능)
EX) 외부에서의 API 호출 처리방법
- 스프링 클라우드 슬루스 : 추적 정보를 수집
- 집킨 : 추적 정보 저장 및 시각화
스프링 클라우드 슬루스와 집킨을 사용한 분산 추적
- 추적(trace) or 추적 트리 (trace tree) : 전체 workflow에 대한 추적 정보
- 스팬(span) :트리의 일부분으로, 기본 작업단위. 하위 스팬으로 구성돼 추적 트리를 형성
집킨 UI 는 스팬별로 추적이 된다
- 스프링 클라우드 슬루스--> 동기 방식 비동기 방식으로 집킨에 추적 정보를 전송
-- 동기 : HTTP를 이용 || 비동기 : 메시지 브로커(ex. RabbitMQ, 카프카 등)를 이용
❓ 집킨 서버에 대한 런타임 의존성 갖지 않게 하려면
--> RabbitMQ나 카프카를 사용해 비동기 방식으로 집킨에 추적 정보를 전송하는 게 좋음
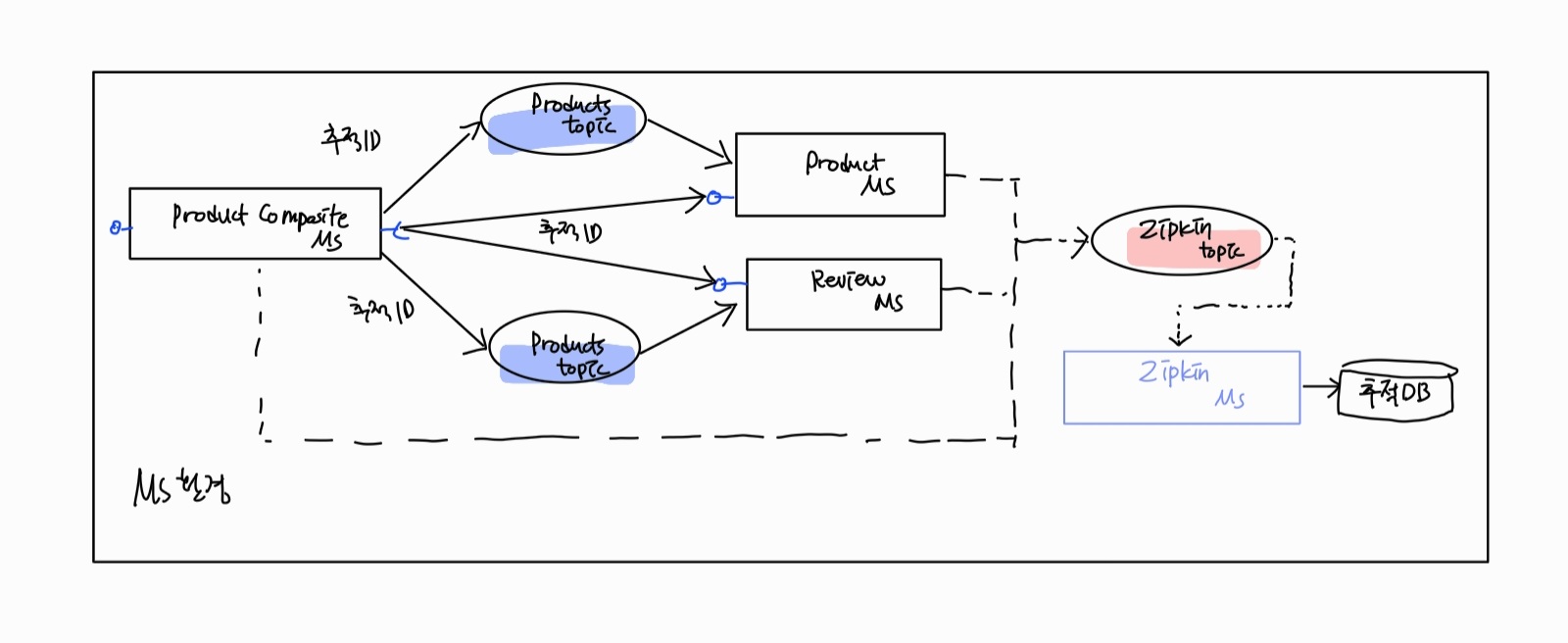
❓ 집킨은 어떤 추적정보를 저장 가능한가
메모리나 아파치 카산드라(Apache Cassandra), 일래스틱서치, MySQL에 추적 정보를 저장 可
이번장은 메모리에 추적 정보를 저장
소스 코드에 분산 추적 추가
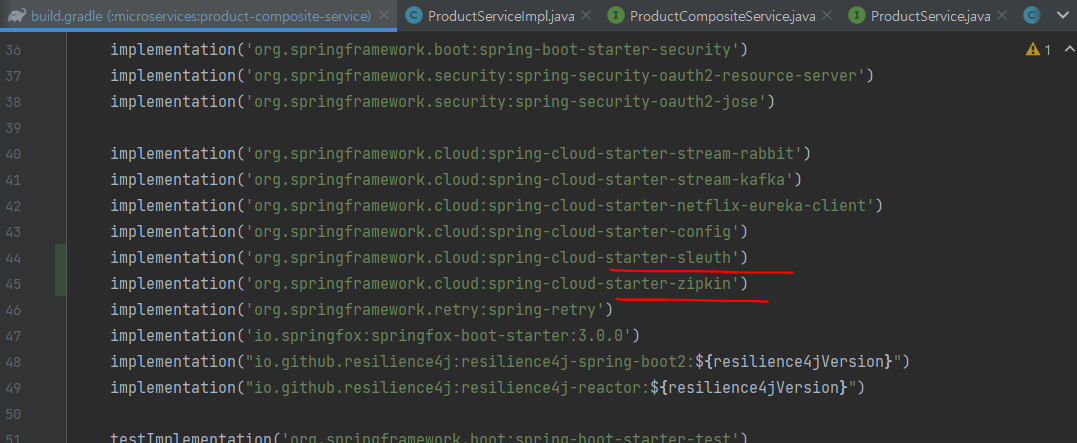
- 스프링 클라우드 슬루스를 활용해 집킨으로 추적 정보를 전송하고자 빌드 파일에 의존성을 추가
review, product, recommendation, product-composite에 추가
-
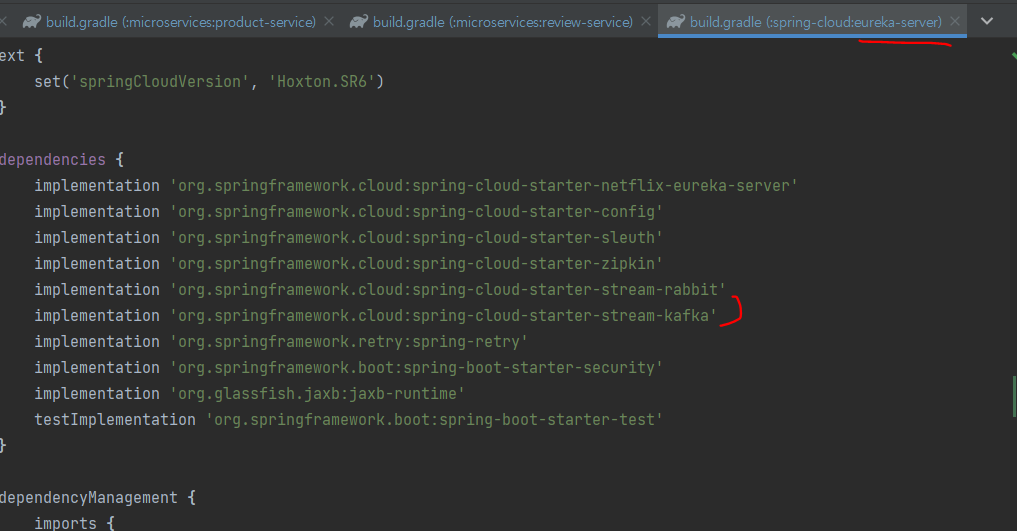
이전에는 RabbitMQ 및 카프카 의존성을 추가하지 않았던 스프링 클라우드 프로젝트(authorization-server, eureka-server, gateway)에 RabbitMQ 및 카프카 의존성을 추가.
-> 유레카, auth, 게이트웨이에 rabbit이랑 kafka 주기
-
RabbitMQ나 카프카로 집킨 서버에 추적 정보를 보내도록 마이크로서비스를 구성.
- rabbitMQ
본 프로필에선 집킨으로 추적 정보를 보낼 때 RabbitMQ 사용
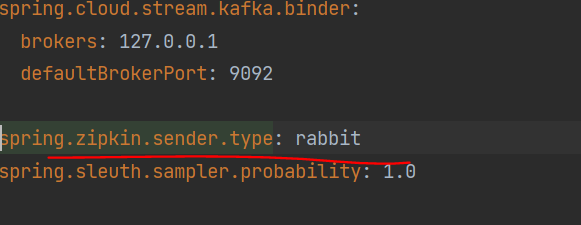
spring.sleuth.sampler.probability: 1.0으로 10%의 추적 정보만 집킨으로 보내는 기본 슬루스 설정에서 100프로 보내려면 1.0 주기
- kafka
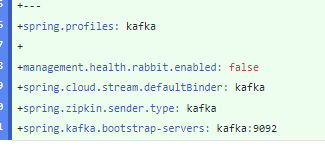
카프카를 사용해 집킨으로 추적 정보를 보내려면 kafka 스프링 프로필을 사용
(kafka 스프링 프로필)
- 도커 컴포즈 파일에 집킨 서버를 추가.
docker-compose 랑 docker-compose-partitions 에 집킨 서버 구성 추가
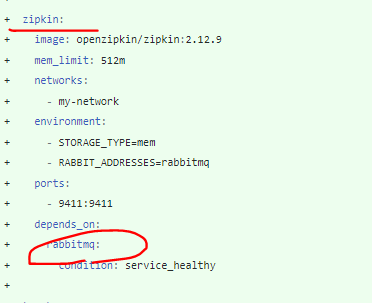
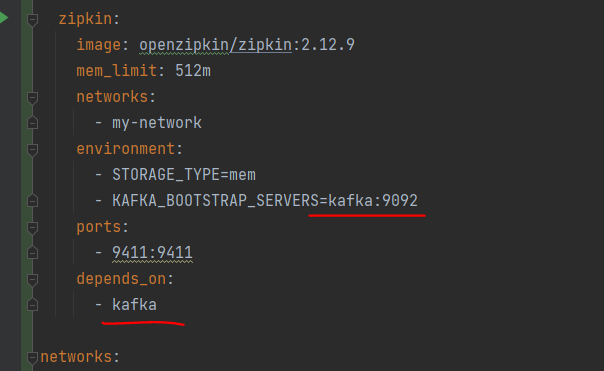
RABBIT_ADDRESSES=rabbitmq 환경 변수는 집킨이 RabbitMQ를 사용->
추적 정보를 수신 ++ rabbitmq 호스트 이름을 사용해 RabbitMQ에 연결
- docker-compose-kafka.yml 파일에 정의된 kafka 스프링 프로필을 스프링클라우드 프로젝트(authorization-server, eureka-server, gateway)에 추가.
분산 추적 수행 방법
- RabbitMQ를 대기열queue 관리자로 사용해 시스템 환경을 빌드, 시작, 검증.
./gradlew build && docker-compose build로 도커 이미지 빌드
그리고 테스트 스크립트로 실행하는걸 이론으로 봐보면
access token을 얻어서 api 호출
후
curl -H "Authorization: Bearer $ACCESS_TOKEN" -k
https://localhost:8443/product-composite/2 -w "%{http_code}\n" -o /dev/null -s를 보내면 200을 반환하면 정상
- 정상적인 API 요청을 보낸 후 이 API 요청과 관련된 추적 정보를 집킨에서 찾기.
그 상태로 집킨 UI 접속 시
http://localhost:9411/zipkin/.이 주소로 웹브라우저에서 들어가면
추정 정보가 검색 된다.
❓ 무엇이 보이나
- gateway 서비스가 요청을 수신.
- 요청 처리를 product-composite 서비스로 위임.
- product-composite 서비스는 병렬로 세 가지 핵심 서비스(product, recommendation,review)에 요청을 보냄.
- product-composite 서비스는 세 가지 핵심 서비스에서 받은 결과로 복합 응답 생성.
- gateway 서비스를 통해 호출자에게 복합 응답을 전송
각 스팬을 클릭하면 자세한 내용 볼 수있음 (모니터링 할 때 좋겠다 😋)
(완료하는 데 걸린 시간 까지 나온대)
- 비정상적인 API 요청을 보낸 후 이 API 요청과 관련된 추적 정보를 집킨에서 찾기
IF) 비정상 요청 보내면 추적이 되는가
존재하지 않는 제품을 검색 -> 404 코드 반환
목록의 맨 위에 실패한 요청이 빨간색으로 표시 -> 스팬 클릭 -> (상세 화면을 보면 product/12345를 호출했을 때 404(Not Found)가 반환됐기 때문에 오류가 발생했다) 자세한 내용 볼 수있음 ==> 이런 식으로 문제 근본 원인 찾기 쉽게
집킨을 사용해 상황에 대한 추적 정보 시각화
❓무슨 상황
- 정상적인 API 요청 및 비정상적인 API 요청
- 동기 방식의 API 요청 및 비동기 방식의 API 요청
- 비동기 처리를 유발하는 정상적인 API 요청을 보낸 후 이 요청과 관련된 추적 정보를 집킨에서 찾기
비동기로 처리되는 상황을 확인하고자 삭제 요청을 보내
서비스 작동 방식 ) product-composite 서비스는 메시지브로커를 통해 세 가지 핵심 서비스-> 삭제 이벤트를 보냄 --> 각 핵심 서비스는 비동기로 삭제 이벤트를 처리
❓슬루스 에서는
슬루스 덕분에 추적 정보가 추가된 이벤트가 메시지 브로커로 전송되며, 삭제 요청의 전체 처리 과정을 일관된 방식으로 볼 수 있음
집킨 UI에서는
- gateway 서비스가 요청을 수신.
- 요청 처리를 product-composite 서비스로 위임
- product-composite 서비스는 3개의 이벤트를 RabbitMQ로 보냄
- 처리를 완료한 product-composite 서비스는 gateway 서비스를 통해 호출자에게 HTTP 상태 코드 200을 return
- 핵심 서비스(product, recommendation, review)는 삭제 이벤트를 수신하면 비동기 방식으로 각자 독립적으로 처리
하는 삭제 요청 처리과정이 나오고
스팬을 클릭하면
메시지 브로커를 통해 input 채널로 들어온 이벤트에 의해 product 서비스가 동작한다는 것까지 확인 가능

RabbitMQ와 카프카를 사용해 집킨 서버로 마이크로서비스 추적 이벤트 전송
- RabbitMQ에서 집킨으로 전송된 추적 정보를 모니터링하는 방법
http://localhost:15672/#/queues/%2F/zipkin에서는 RabbitMQ의 웹 UI를 사용하면 RabbitMQ를 통해 집킨으로 전송된 추적 정보를 모니터링 가능!
알수 있는 정보 )
Message Rates라는 그래프를 보면 평균적으로 초당 1.2개의 추적 메시지가 집킨으로 전송된다
(음.. 생각보다 알수있는 내용이 적네.. 그냥 정보만추적하고 있다 정도인듯)
- 대기열 관리자를 카프카로 전환하고 이전 단계를 반복
카프카는 rabbitmq처럼 웹 UI 부재 --> 커맨드로 확인
정리 및 느낀점
14장에서는 분산 추적을 사용해 마이크로서비스의 공조(共助 = 함께 돕는 방식 == 그냥 서로 협력하면서 처리하는 방식 이야기하고싶어하는 듯) 방식을 파악하는 방법을 배움
스프링 클라우드 슬루스를 사용해 추적 정보를 수집하는 방법과 집킨을 사용해 추적 정보 를 저장하고 시각화하는 방법을 봤는데 슬루스와 집킨 중 한개는 수집하고 한개는 시각화하므로 떼려야 뗄 수 없는 사이라는 것을 인지했음
문득 여기서도 비동기 서비스가 삭제로 설정되어있는 것을 우리 프로젝트를 설계하면서 눈에띈다. 비동기를 자주 다는 이벤트가 삭제인걸까? 궁금하기도 하다 .
3부 부터는 쿠버네티스를 이용해 마이크로서비스를 배포하고 관리하는 방법을 배우는데 아마도 프로젝트가 마무리되는 시기인 11월 말까지는 최대로 만들 수 있는 것이 2부 전까지의 내용일 것이라고 생각이 든다 (혹은 gateway 까지라던지)
한달이 조금 넘는 시간동안 마이크로서비스 아키텍처라는 것에 대해서 '스프링부트를 활용한 마이크로 서비스 개발' 이라는 책으로 MSA1 를 그리고 이 책으로 MSA2 스터디를 진행했다.
빠르게 내용을 살피고 아직 복습을 하지 않았지만 대략적으로만 살핀다는 생각으로 진행하였다.
현재 프로젝트의 구조인 모놀리틱에서 이제
1. 새로운 기능 추가로 인한 서비스 증가로 -> 2개의 서비스를 만들고
2. 원래 서비스에서 인증 서비스만을 빼서 3개의 서비스로 만드는 방법으로 남은 기간을 보낼 것 같다.
진행하면서 맞닥뜨리는 문제들이 겁이난다. 이 스터디는 이 문제를 해결할 실마리를 주는 스터디가 아니라 문제를 덜 만나도록 구성을 설계하는 데에 도움이 되길 바란다.
물론 마주치는 문제들을 해결한 과정은 계속 블로그에 적어 나갈 예정이다.
그럼 .. 파이팅 .. 가보자고 ...

