-
이번에 진행하는 프로젝트에서 웹 크롤링 파트를 내가 맡게되었는데 구글링에 의존해서 하다보니 나한테 맞는 정보를 검색하느라 애썼다
( 1단계는 해냈으니 기억미화전에 적어두는 글) -
하고자 했던 것 :
ㄱ. 쇼핑몰에서 카테고리 들어갔을 때 나오는 쇼핑리스트에서 하이퍼링크 다 가져오기
ㄴ. 반복문을 이용해서 크롤링대상 페이지들을 List로 저장하기
ㄷ. 저장된 List에서 하나씩 꺼내와서 CSS태그를 이용해 텍스트들 가져오기
ㄹ. 찾고자 한 태그가 여러개일 경우의 텍스트 가져오기
ㅁ. 가져온 텍스트 txt 파일로 저장하기 -
개발환경 : groomide
(Python을 가상컴퓨터로 개발할 수 있는 ide ) -
개발을 위한 준비
- 크롤링할 대상 정하기
- 대상의 DOM태그 구조 제대로 파악하기
- 크롤링 해올 정보에 대해 파악하기
- 시작
ㄱ. 카테고리 검색시 나오는 부분 중에서 개발자모드(F12)로 보면
이렇게 class="productGridItem"에서 a 태그 href 속성으로 각각 상품의 링크를 얻을 수 있음.
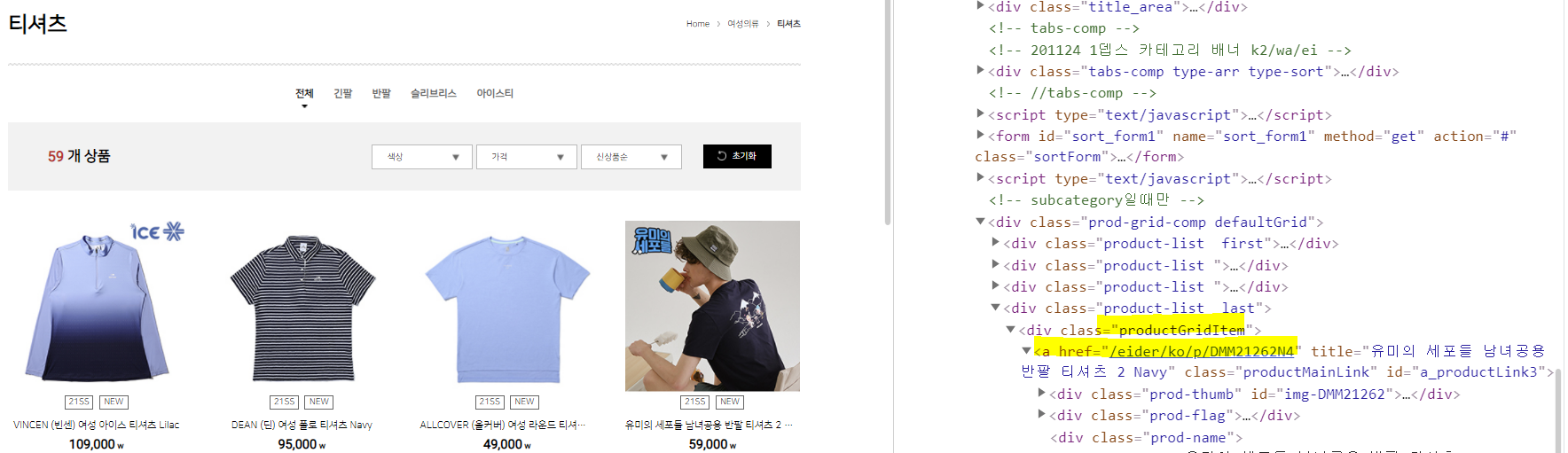
또, 페이지 당 공통점을 보면 url 링크가
~~앞부분링크에
/%EC%97%AC%EC%84%B1%EC%9D%98%EB%A5%98/%ED%8B%B0%EC%85%94%EC%B8%A0/c/EI002002000?q=%3Acreationtime-desc%3AmobileYn%3AFALSE&page=1 이런식으로 &기호다음에 page=으로 주고있음을 파악할 수 있다.
ㄴ.
그래서 크롤링하고자하는 모든 상품의 링크를 얻기위해 python에서 코드를 짜보면 (request 와 BeautifulSoup 라이브러리를 사용)
import urllib.request
from bs4 import BeautifulSoup
f = open("텍스트이름.txt", 'w')
#for 반복문으로 각 상품 링크 저장한다.
#크롤링대상 페이지가 페이지별 &page=0 또는 &page=1 이기 때문에 str(i)를 이용해서 반복문
#나는 3페이지까지 있기 때문에 반복문 3번돌리기
for i in range(0,3,1):
url = "여기에 크롤링대상 페이지 주소 넣고 ~~ /c/EI002002000?q=%3Acreationtime-desc%3AmobileYn%3AFALSE&page="+str(i)
req = urllib.request.Request(url)
sourcecode = urllib.request.urlopen(url).read()
soup = BeautifulSoup(sourcecode, "html.parser")
#f = open("페이지링크모음012.txt", 'w')
for href in soup.find("div", class_="prod-grid-comp defaultGrid").find_all("div", class_="productGridItem"):
print(href.find("a")["href"])
f.write(href.find("a")["href"]+'\n')
i+=1
f.close()만일 bs4가 없다는 경고가 뜨면 pip install bs4를 이용해서 다운로드를 해주어야함.
ㄴ. 저장된 텍스트는 전체 url이 아니기 때문에
저장된 텍스트를 한줄씩 읽어와서 전체 url로 만들어 List 저장하고,
-> readLines()이용해 한줄씩 읽어서 lines라는 변수로 리스트에 저장.
lines 크기만큼의 빈 rs List변수를 만들고, 거기에 한줄씩 반복문 이용해 저장
for i in range(0,len(rs)):
rs[i]= 'http://www.eider.co.kr'+lines[i]ㄷ. 저장된 List에서 하나씩 꺼내와서 CSS태그를 이용해 텍스트들 가져오기
with urlopen(rs[i]) as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.select("#div_productCode"):
data = "\t"+anchor.get_text()for anchor in soup.select() 를 이용하면 CSS태그를 이용해서 가져올 수 있음.
class 로 찾을경우 -> .클래스명
id 로 찾을경우 -> #id명
조건에 해당하는 텍스트만 가져올때는 .get_text()를 이용하기
다른 곳을 구글링할때는 조건태그 한개만 가져오는 예시를 들었으나 내가 필요한건 여러 텍스트를 가져오려고함 (ex, 상품별 코드, 상품명, 가격, 색상 ,,,) 그럴 때에는
for anchor in soup.select("#div_productCode"):
data = "\t"+anchor.get_text()
for anchor in soup.select("#p_productName"):
data =data+'\t'+ anchor.get_text()
for anchor in soup.select("#em_color"):
data =data+'\t'+ anchor.get_text()로 여러번 사용하면 여러 텍스트를 가져와서 한 곳 (data)에 저장할 수 있다.
일반적으로 data += anchor.get_text()사용하면 되고,
가져오는 애들 사이에 탭만큼 띄고싶으면 data = "\t"+anchor.get_text()
엔터만큼 띄고 싶으면 data = "\n"+anchor.get_text() 사용
ㄹ. 찾고자 한 태그가 여러개일 경우의 텍스트 가져오기
ㅁ. 가져온 텍스트 txt 파일로 저장하기
from bs4 import BeautifulSoup
from urllib.request import urlopen
f = open("상의링크모음012.txt", 'r') #txt파일을 열어서
lines = f.readlines() #한줄씩 읽는다
f.close()
#print(lines) #lines 변수에 리스트로 저장되어있음
rs = ['','','','','', '','','','','',
'','','','','', '','','','','',
'','','','','', '','','','','',
'','','','','', '','','','','',
'','','','','', '','','','','',
'','','','','', '','','','']
#len(rs) #59
f = open("Top_코드이름색상.txt", 'w')
for i in range(0,len(rs)):
rs[i]= 'http://www.eider.co.kr'+lines[i]
with urlopen(rs[i]) as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.select("#div_productCode"):
data = "\t"+anchor.get_text()
for anchor in soup.select("#p_productName"):
data =data+'\t'+ anchor.get_text()
for anchor in soup.select("#em_color"):
data =data+'\t'+ anchor.get_text()
#csvWriter.writerow(data)
#print(i+"번째 " +data+"\n")
f.write(data)
f.close()
이제 저장된 txt를 가지고 사용하면 된다.
1단계 끝!
