조건 : txt파일에 다운로드하고자하는 여러개의 이미지주소가 있다. 이번의 이미지 개수는 165개
(예시) 이런식으로 이미지주소가 15개 있을 경우
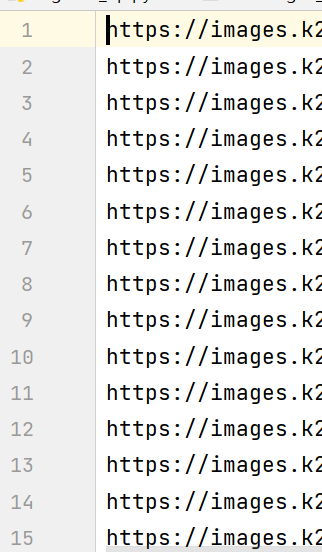
파일이름을 "image_url.txt"로 저장해두었음
사용할 코드는 다음과 같다.
import urllib.request
f = open("image_url.txt", 'r')
lines = f.readlines()
n=1
rs = ['', '', '', '', '', '', '', '', '', '',
'', '', '', '', '']
for i in range(0, len(rs)):
rs[i] = lines[i]
urllib.request.urlretrieve(rs[i], str(n)+".jpg")
print(str(i)+"번째 " +rs[i])
n+=1
print("download successful")
자세히 보자면
f.open()을 이용해 텍스트 파일을 열고,
f.readlines()를 이용해 lines 리스트에 내용을 저장한다.
동일한 크기(length)를 가진 빈 리스트rs[]를 생성하고, 반복문을 이용해 rs[]에 넣어준다.
그리고 urllib.request.urlretrieve()를 이용해 각 rs 이미지주소에 접근해서
1.jpg 2.jpg 3.jpg ...처럼 str(n)을 이용해 이미지의 이름을 생성해준다.
다운받아진 이미지는 다음과 같다.
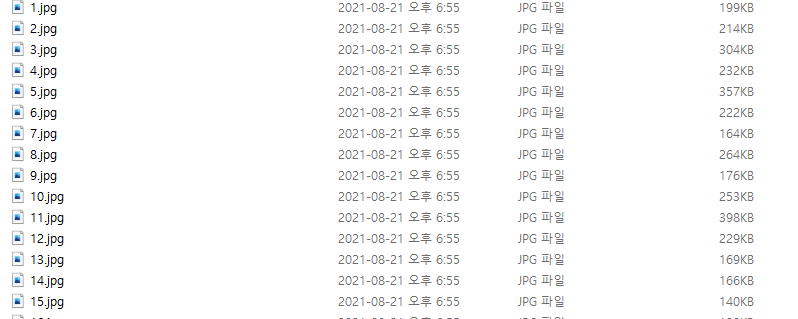
py파일이 쓰여진 폴더 내에 사진이 생성되기때문에 수월한 정리를 위해서 폴더를 따로파서 하는 것이 편리함.

HelloWorld! 같은 실수를 반복하지 말기위해 적어두자..