1과목. 데이터 모델링의 이해
1장.데이터 모델링의 이해
데이터 모델링을 할 떄 유의점 - 비유연성
: 데이터의 정의를 데이터의 사용 프로세스와 분리 하는 것
데이터 모델링의 종류 구분 keyword
-개념적 모델링 : 추상화 수준이 높은, 포괄, 통합
-논리적 모델링 : key, 속성, 관계
-물리적 모델링 : 저장 방법
엔티티 : 2개 이상의 속성, 2개 이상의 인스턴스 필수 - 면적의 표현
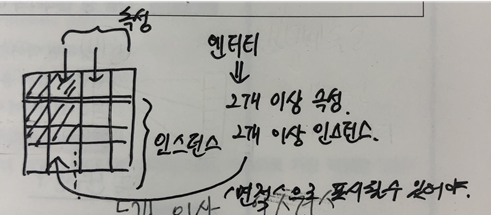
키엔티티: 자신만의 고유 주식별자 (예시: 사원, 부서, 고객, 상품, 자재 등)
엔티티의 이름부여 방법
-생성되는 의미대로 자연스레 부여
-약어 사용자제
-유일한 이름 부여
-현업의 업무용어 사용
속성(Attribute) : 인스턴스에서 관리하고자 하는 더이상 분리되지 않는 최소한의 데이터 단위.
도메인(Domain) : 속성에 대한 (type, 크기, 제약사항)과, 속성이 갖는 값에 대한 범위
관계의 표기법 3가지 :
-관계명
-관계차수 : 1:1, 1:N, M:N
-선택성(=선택사양) : 필수관계, 선택관계
관계 체크 사항 : 관계연결을 가능하게 하는 동사가 있는가
인조식별자 : 시스템상에서 부여한 식별자(시퀀스가 떠오름..) <> 본질식별자
부모엔티티의 주식별자를 자식엔티티에서 받아 손자엔티티까지 상속 가능
엔티티별 데이터 생명주기 관리
: 부모엔티티가 자식엔티티만 남기고 소멸할 수 있으면 비식별자관계
: 자식엔티티가 함께 소멸되면 식별자관계
2장. 데이터 모델과 성능
성능이 저하된 결과를 대상으로 데이터모델을 중심으로 튜닝한다 : 구조적 차원에서 손봐야
(틀림: 데이터모델보다는 문제발생 시점의 SQL중심으로 튜닝한다.)
성능데이터모델링 과정(설계 단계에서 진행)
정규화 -> 용량산정 -> 트랜잭션 유형파악 -> 반정규화 -> FK,PK,슈퍼/서브타입 조정
정규화 - 유투브 그리타님 강의를 보고 정리한 것
https://youtu.be/rVxcheAkMSk

반정규화를 이유 : 성능의 저하
-디스크 I/O양이 많아서
-경로가 너무 멀어 조인으로 인한
-칼럼을 계산해서 읽을 떄
자주 이용하는 칼럼 -> 칼럼을 모아 부분테이블로 추가
최근에 변경된 값만을 조회하는 것 -> 과도한 조인을 발생 시킴
지나치게 많은 조인 처리 : 뷰
대량데이터 처리 : 클러스터링, 인덱스
세개의 테이블을 하나로 통합할때 : 세 테이블을 구분할 수 있는 인자를 추가해주어야 함
(긴급사건,특수사건,일반사건을 통합한다면 사건분류코드를 추가해줌)
WHERE조건절에서 단일 상수값('='사용), 그 다음에 범위값('BETWEEN'사용)순으로 검색하는 것이 조회에 유리
FK도 인덱스가 필요
통합데이터(Global Single Instance) <> 분산데이터
2과목. SQL기본 및 활용
1장. SQL 기본
DML : 비절차적 데이터 조작어(접근방법에 관심없음. 어떤 데이터를 원하는지만 기술)
테이블명에 허용되는 문자 : A-Z, a-z, 0-9, "_", "$", "#"
테이블 생성 시 한 쿼리문 내의 기본키의 생성은 한번만
COUNT(*) -> NULL값 포함한 계산
COUNT(칼럼명) -> NULL값 제외한 계산
-> 만약 NULL값이 없는 칼럼이라면 COUNT(*)와 COUNT(칼럼명)의 결과값은 동일.
UNIQUE 무결성은 중복에 대한 것
EMP테이블에서 ENAME칼럼 삭제 : ALTER TABLE EMP DROP COLUMN ENAME;
STADIUM테이블의 이름을 STADIUM_JSC로 변경 : RENAME STADIUM TO STADIUM_JSC;
DELETE(/MODIFY) Action
1. cascade : mater 삭제 시 child 같이 삭제
2. set null : master삭제 시 child 해당 필드 null
3. set default : master삭제 시 child 해당 필드 default값으로 설정
4. restrict : child 테이블에 pk값이 없는 경우만 master삭제 가능
5. no action : 참조무결성을 위반하는 삭제/수정 액션을 취하지 않음
INSERT Action
1. automatic : master 테이블에 pk가 없는 경우 master pk 생성하고 child 입력
2. set null : master 테이블에 pk가 없는 경우 child fk를 null값으로 처리
3. set default : master 테이블에 pk가 없는 경우 child fk를 default값으로 처리
4. dependent: master 테이블에 pk가 존재할때만 child 입력 허용
5. no action : 참조 무결성을 위반하는 입력 액션을 취하지 않음
로그를 남기는 것 : DELETE
로그를 남기지 않는 것 : DROP, TRUNCATE
Oracle의 DDL 이후 : AUTO COMMIT(묵시적 커밋)
SQL SERVER 이후 : AUTO COMMIT 하지않음
(Oracle) INSERT INTO 서비스 VALUES('999', '', '2015-11-11');
이 쿼리문의 '' -> NULL값이 입력된다.
CASE WHEN LOC = 'NEWYORK' THEN 'EAST'
CASE LOC WHEN 'NEWYORK' THEN 'EAST'
COLESCE 처음 만나는 NULL이 아닌값 출력
AVG(COUNT(*))같은 중첩된 그룹함수의 결과값은 1개 -> SELECT절에서 사용할 수 없음
SELECT절에서 기술되지 않은 칼럼값으로 ORDER BY절에 사용할 수 없음
ORDER BY절에서는 Alias와 정수값(컬럼번호)을 혼용하여 사용할 수 있음
TOP함수의 옵션 - WITH TIES와 함께 사용되면, 값이 동일하면 함께 출력해준다.
TOP함수 예제 - 테이블에서 급여가 높은 2명을 내림차순으로 출력하는데, 같은 급여를 받는 사원이 있으면 같이 출력한다.
SELECT TOP(2) WITH TIES
FROM EMP
ORDER BY SAL DESC;
2장. SQL 활용
EXITS: 교집합 구하기
NOT EXITS: 차집합 구하기
제품과 생산라인 두 테이블 사이의 join -> cartesian join 사용
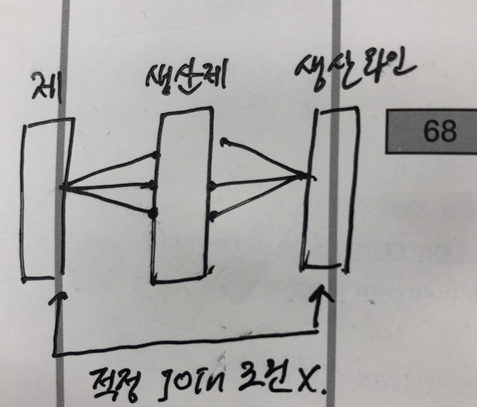
USING 뒤에는 항상 순수한 컬럼명이 와야함. Alias 사용불가능
83페이지 72번
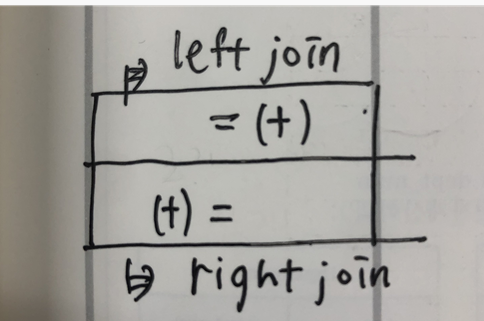
LEFT OUTER JOIN에서
WHERE 절에 조건에 들어가면 전체 데이터 출력
ON 절에 조건 들어가면 대상 데이터를 제한한 결과 출력
OUTER JOIN의 (+) 표기법
(+)이 있는 쪽의 반대가 드라이빙 테이블
(+)이 있는 쪽이 경우에 따라 NULL값 발생
UNION ALL
.
.
UNION
.
.
ㄴ 인 형태라면 연산의 가장 하단에 있는 UNION이 적용받아 중복을 모두 제거한게 최종결과값
루트노드의 레벨은 1. 루트로부터 멀어질때마다 1씩 증가.
Oracle의 계층형 질의문의 PRIOR 키워드는 CONNECT BY절 뿐만 아니라 SELECT절, WHERE절에서 사용가능
셀프조인 : 한 테이블내에 두 칼럼이 연관관계가 있을 때, 동일테이블 사용하는 것이니 Alias 필수
다중칼럼서브쿼리는 Oracle에서만 존재
서브쿼리에서는 ORDER BY절을 사용할 수 없음 : SELECT절에서 ORDER BY는 오직 한개만 쓸 수 있기 때문에 SELECT절의 가장 마지막 문장에 와야함
SELECT절에서 사용하는 서브쿼리를 스칼라서브쿼리라고 함
연관서브쿼리: 서브쿼리가 메인 쿼리를 포함하는 것
다중 행 연관 서브쿼리 : WHERE절
단일 행 연관 서브쿼리(=스칼라 서브쿼리) : SELECT절
INLINE VIEW : FROM절 (임시적, DB에 저장되지 않음)
연관 서브쿼리를 사용한 UPDATE
-WHERE절에서 UPDATE가 적용되는 데이터의 범위를 결정해줌
-WHERE절이 생략된다면? 모~든 데이터를 대상으로 함
VIEW의 장점 : 독립성 - 테이블의 구조가 변경되어도 뷰를 사용하는 응용프로그램은 변경되지 않음
GROUPING(칼럼) = 1 : 집계에 사용되었음을 의미
GRANT SELECT, UPDATE ON 사원정보 TO 홍길동;
DBMS에서 관리자가 사용자별로 권한을 관리해야하는 부담과 복잡함을 줄이기 위해, 다양한 권한을 그룹으로 묶어 관리할 수 있도록 사용자와 권한 사이에 중개역할을 하는 ROLE을 부여한다.
프로시저 & 사용자 정의함수는 작성자 기준 트랜잭션 분할이 가능하다.
프로시저 실행 방법 : EXCUTE 명령어로 실행. cf) 트리거는 생성 후 자동으로 실행
트리거는 데이터의 무결성과 일관성을 위해 사용한다.
트리거는 TCL(COMMIT, ROLLBACK)사용이 불가능하다.
3장. SQL최적화 기본원리
비용기반 옵티마이저 : SQL문을 실행하는데 소요될 처리시간 및 CPU, I/O자원량을 계산하여 가장 효율적인 실행계획을 선택하는 옵티마이저. cf) 규칙기반 옵티마이저
실행계획은 "예상"정보, 실제 처리 건수는 알수없음
규칙기반 옵티마이저의 우선순위 : 행에 대한 고유주소 사용
규칙기반 옵티마이저의 낮은순위 : 전체 테이블 스캔
인덱스 범위 스캔은 결과 건수만큼 반환한다. 만약 인덱스가 없다면? 단 한건도 반환하지 않는다.
데이터마이그레이션. 즉 대량의 데이터삽입 시에는 인덱스를 모두 제거하고 삽입이 끝난 뒤, 다시 인덱스를 재생성한다.
인덱스는 조회를 위한 것. 따라서, 삽입,갱신,삭제 시에 부하가 발생한다.
비용기반 옵티마이저에서는 비용계산에 따라서 인덱스가 있어도 전체스캔이 유리하다고 판단할 수 있다.
규칙기반 옵티마이저에서는 인덱스가 있으면 인덱스를 사용하라고 한다.
b-tree인덱스는 전체 테이블의 데이터 중에서 10%정도를 탐색할때 유리하다.
INDEX를 구성하는 칼럼 이외의 데이터가 UPDATE될 때는 INDEX로 인한 부하가 발생하지 않는다.
EXITS는 주로 SEMI조인과 함께 사용
HASH JOIN은 EQUI(=)조인 조건에서만 작동, 조인 칼럼 인덱스 대신에 해시함수를 사용.
Sort Merge Join : 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행. 스캔방식으로 데이터를 읽음. 넓은 범위의 데이터를 처리할때 이용되는 조인. 데이터가 너무 많아서 메모리에서 모든 정렬작업을 처리하기 어려운 경우에는 임시 영약(디스크)를 사용하므로 성능 저하.
NL join(Nested Loop join) : 랜덤 액세스 방식으로 데이터를 읽음
Join대상 테이블이 join키를 기준으로 이미 정렬되어 있다면 Sort Merge Join이 Hash Join보다 성능면에서 우수하다.
한국데이터산업진흥원의 SQL 자격검정 실전문제,
일명 "노랭이"의 SQLD 출제범위까지 문제 풀이 후 오답위주로 정리한 글입니다.
시험 전 복습 겸 정리를 위해 업로드 합니다.
반정규화 부분에 첨부한 필기노트는 유투브 그리타님의 영상을 보고 작성한 것임을 밝힙니다. (영상의 출처는 본문에 기재되어 있습니다.)
틀린 부분이 있다면 언제든지 알려주시길 바라며 SQLD 시험 하루전날, 포스팅을 마칩니다.
시험에 응시하시는 분들 모두 합격하시길 바랍니다!
