챕터 5의 목표
확률적 분석과 랜덤화 알고리즘의 차이에 대해 설명하기
인디케이터 랜덤 변수 테크닉 소개하기
랜덤화 알고리즘 분석의 다른 예시 소개하기 (추가 배열 없이 배열 섞기)
채용 문제 (The Hiring Problem)
지배인은 에이전시를 통해서 직원을 고용하고자 합니다.
에이전시는 매일 한 명의 후보자를 보냅니다.
지배인은 각 후보자를 인터뷰하고 그 자리에서 고용 여부를 결정해야 합니다.
만약 새로운 사람이 고용되면, 현재 고용된 사람은 해고됩니다.
인터뷰 비용은 후보자 당 c_i / 고용 비용은 후보자 당 c_h 입니다.
고용 비용 c_h는 인터뷰 비용 c_i보다 크다고 가정합니다.
이 문제의 목표는 항상 현재까지 면접 본 후보자 중 가장 뛰어난 사람을 고용하는 할 때 발생하는 비용을 계산하는 것 입니다.
발생 비용 분석
만약 n명의 후보자 중에서 m명을 고용한다 가정하면, 총 비용은 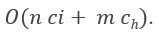
입니다.
(c_i = 인터뷰 비용, c_h = 고용 비용)
최악의 케이스(WorstCase)에서 지배인은 n명을 모두 한번씩 고용하게 됩니다.
(1명 인터뷰 하고 기존의 직원 해고 후 1명 고용)
이 때의 비용은
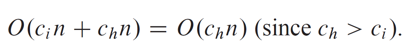
입니다.
확률적 분석
보통, 후보자들이 나타나는 순서는 제어할 수 없기에 우리는 후보자들이 무작위 순서로 등장한다고 가정합니다.
각 후보자마다 순위(rank)를 부여합니다. rank(i) 는 1부터 n까지 범위에 대한 고유한 정수입니다.
이 순위들로 이루어진 리스트 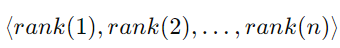
는 후보자들 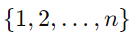
에 대한 순열로 볼 수 있습니다. 이 순위 리스트는 n!개가 존재할 수 있으며, 모든 순열은 동일한 확률입니다, 즉 이 순열은 균일한 무작위 순열(uniform random permutation)입니다.
인디케이터 랜덤 변수
인디케이터 랜덤 변수는 특정 사건(A)이 발생했는지의 여부를 나타내는 변수입니다.
인티케이터 랜덤 변수는 다음과 같이 정의됩니다.

즉, 사건 A가 발생하면 1을, 발생하지 않으면 0을 반환하는 이진 변수입니다.
인티케이터 랜덤 변수는 확률을 기댓값으로 변환하는데 유용합니다.
어떤 사건이 발생할 확률을 구해야 될 때 인디케이터 변수를 사용해 사건의 기댓값을 계산할 수 있습니다.

Lemma
주어진 사건 A에 대해, 인디케이터 랜덤 변수 I{A}의 기대값은 다음과 같습니다.
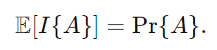
즉, 인디케이터 랜덤 변수의 기대값은 사건 A가 발생할 확률과 같습니다.
이를 증명하기 위한 과정은 다음과 같습니다:
사건 A의 보수(complement)인 /A 를 정의합니다.
기대값의 정의를 적용하면:
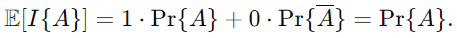
즉, 인디케이터 랜덤 변수의 기대값은 사건 A가 발생할 확률과 정확히 일치하게 됩니다.
Example
문제 - n번의 동전 던지기에서 앞면이 나오는 횟수의 기대값을 계산하기
먼저, X를 n번의 동전 던지기에서 앞면이 나온 횟수를 나타내는 확률 변수로 정의합니다.
그럼 X의 대한 기댓값은 다음과 같이 계산할 수 있습니다.
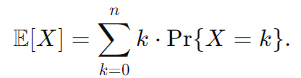
이 식은 이는 각 k(앞면의 개수)별로 해당 값이 나올 확률을 곱한 뒤 더하는 것을 의미합니다.
이 식은 인디케이터 랜덤 변수를 활용해 더 간단하게 만들 수 있습니다.
X_i를 정의하여, i번째 동전 던지기가 앞면이 나오는 사건을 나타내는 인디케이터 랜덤 변수로 설정합니다.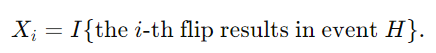
즉, i-번째 동전 던지기에서 앞면이 나오면 X_i=1, 나오지 않으면 X_i=0입니다.
동전 던지기에서 앞면이 나오는 총 횟수 X는 각 동전 던지기에서 앞면이 나왔는지 여부를 나타내는 인디케이터 랜덤 변수들의 합으로 표현될 수 있습니다.
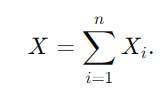
즉, 모든 n번의 동전 던지기에 대해 앞면이 나온 횟수는 각 인디케이터 변수 X_i들의 합입니다.
각 X_i의 기대값은 앞면이 나올 확률 Pr{H}와 같습니다. 즉, 균등한 동전을 가정할 때 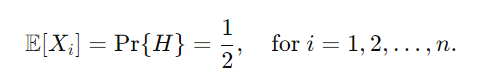
그리고 앞면이 나오는 총 횟수 X의 기대값은 모든 X_i의 기대값의 합으로 계산됩니다.
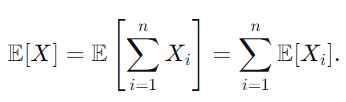
그러므로 n번의 동전 던지기에서 앞면이 나오는 기대값은 n/2로 계산됩니다.
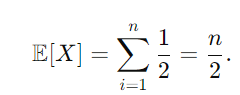
참고로 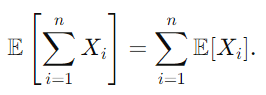
이게 가능한 이유는 기댓값의 선형성(Linearity of Expectation) 때문입니다.
기댓값의 선형성
기대값의 선형성은 기대값을 구할 때, 랜덤 변수들의 합의 기대값이 랜덤 변수들의 기대값의 합과 같다는 원리입니다. 중요한 점은 각 랜덤 변수들 간의 독립 여부와 상관없이 이 법칙이 적용된다는 점입니다.
즉, 기댓값을 구할 때
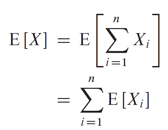
이렇게 바꿔서 구할 수 있습니다.
채용 문제 분석
이제 X_i를 다음과 같이 후보자가 고용되는 사건에 대한 인디케이터 랜덤 변수도 정의합니다.
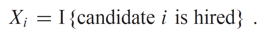
이제 다음의 특성을 활용해 채용 문제를 분석할 수 있습니다.
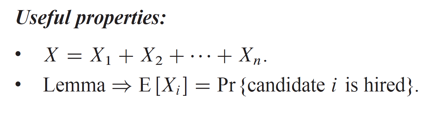
Pr{candidate i is hired} 즉, i번째 후보자가 고용될 확률은 i번째 후보자가 가장 뛰어날 확률로 볼 수 있습니다. 후보자들이 누가 가장 뛰어난 사람인지는 동일한 확률이기에 이는 1/i입니다. 이제 Lemma를 통해서 인디케이터 랜덤 변수 X_i의 기댓값이 1/i임을 알 수 있습니다.
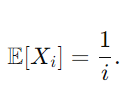
이제 고용 비용의 기대값, E{X}를 
다음과 같이 계산할 수 있습니다.
(조화급수의 합은 ln(n)으로 근사 가능)
(O(1)은 상수 항으로 n에 비례하지 않는 작은 값임)
따라서 기대 고용 비용은 다음과 같이 계산됩니다.
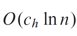
이 O(c_h ln(n)) 은 최악의 케이스에서 봤던 O(c_h n)보다 낮은데, 이를 통해 무작위 순서로 후보자를 면접할 때 기대되는 비용을 낮출 수 있다는 것을 알 수 있습니다.
랜덤화 알고리즘이란?
랜덤화 알고리즘은 동작이 난수 생성기(random-number generator)에 의해 결정되는 알고리즘입니다. 즉, 실행될 때마다 다른 결과를 내놓을 수 있습니다.
보통 RANDOM(a,b)으로 표시하며 RANDOM(a,b)는 a부터 b까지의 범위에서 동일한 확률로 난수를 선택해 반환합니다.
현실에선 완전히 무작위한 난수를 생성할 수 없습니다. 따라서 결정론적 방법으로 난수가 생성되지만 통계적으로 무작위처럼 보이는 의사 난수 생성기(pseudorandom-number generator)를 사용합니다.
랜덤화 알고리즘은 알고리즘이 실행될 때마다 다른 경로를 따를 수 있기에, 입력이 최적화되지 않았거나 예측 불가능한 경우에 최악의 성능을 유발하지 않도록 도와줍니다.
채용 문제에서 결정적 알고리즘과 랜덤화 알고리즘의 차이
-
결정적 알고리즘은 입력된 순서에 의존하여 고용 횟수가 결정되며, 이는 주어진 입력에서 항상 같은 결과를 산출합니다.
-
랜덤화 알고리즘은 입력 분포를 가정하지 않고, 입력에 무작위성을 부여함으로써, 후보자의 순서가 알고리즘의 성능에 미치는 영향을 줄일 수 있습니다.
배열을 무작위로 섞기
목표 : 균등한 무작위 순열(uniform random permutation)을 생성하기. 단, 배열의 모든 n!개의 가능한 순열 중 하나가 동일한 확률로 선택되야 함.
(여기선 각 요소 A[i]가 특정 위치로 이동할 확률이 1/n 임을 증명하는 것이 목표가 아님)
(대신에 전체 순열이 균등하게 분포되는지에 초점을 맞춤)
의사코드 (psedocode)

각 반복에서, 현재 처리 중인 A[i] 요소를 배열의 남은 부분에서 무작위로 선택된 요소와 교환합니다. 교환 후 A[i]는 다시 바뀌지 않으며, 그 자리에 고정됩니다.
시간 복잡도(Time Complexity)
각 반복(iteration)은 상수 시간(O(1))에 수행됩니다.
n번의 반복이 있으므로, 전체 알고리즘의 시간 복잡도는 O(n)입니다.
Lemma
무작위 배열 순열(Randomly Permuting an Array)은 균등한 무작위 순열을 생성한다.
Proof
-
루프 불변식 : i-번째 반복 직전까지의 부분 배열 A[1:i−1]에는 (i−1)-순열이 포함되어 있으며, 이 순열은 (n−i+1)!/n!의 확률로 발생합니다.
-
i=1 일 때, 0-순열(즉, 빈 순열)이 부분 배열 A[1:0]에 포함됩니다.
n!/n!=1이므로, 이 빈 배열은 100% 확률로 0-순열을 포함합니다.
즉, 배열이 비어 있고, 이 빈 배열은 확률 1로 0-순열을 포함하게 됩니다. -
i-번째 반복 직전까지, 부분 배열 A[1:i−1]에 (i−1)-순열이 포함되어 있다고 가정합니다. 이 부분 배열은 (n−i+1)!/n!의 확률로 해당 순열을 포함합니다.
알고리즘의 i-번째 반복에서, 배열 A[i]와 무작위로 선택된 요소가 교환됩니다. 이로 인해 배열의 무작위성이 유지됩니다. -
알고리즘이 n번 반복을 완료하고 종료될 때, 종료 시점에서는 배열 A[1:n]이 완전한 n-순열을 포함하며, 이 순열은 1/n!의 확률로 발생합니다.
따라서 모든 가능한 n-순열이 동일한 확률로 발생한다는 것을 보장합니다.
