
01 개요
본 문서에서는 딥러닝 기반 추천 시스템을 다루기 위해, 추천 시스템 일반에 대하여 개괄적인 내용을 다룬다.
최종수정일 : 2023.11.23
02 추천시스템 구조
참조 : https://yamalab.tistory.com/117
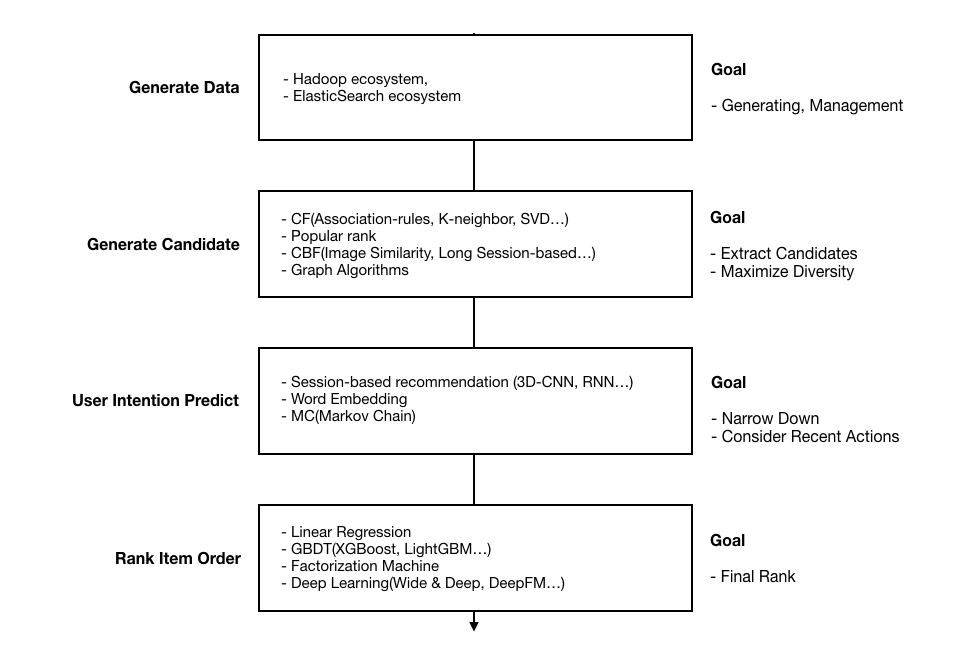
2019년 기준 추천 시스템은 일반적으로 아래와 같은 절차를 따른다고 한다.
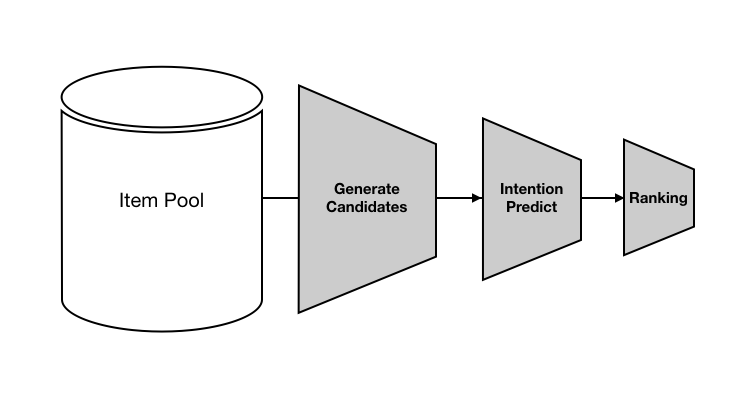
Candidate generate part
수많은 상품 중, 후보가 될 만한 상대적으로 적은 수의 상품으로 선택지를 줄이는 것을 목적으로 한다. 후보군 산출 단계에서는 여러 개의 전략들을 합쳐서(merge) 유저의 관심사가 최대한 많이 포함되도록 coverage를 넓히는 것이 좋다.
Intention prediction part
의도 예측 단계에서는 유저의 ‘최신 행동’에 기반하여 click, buy 등의 다음 행동을 예측한다.
Ranking part(prediction CTR/CR)
의도 예측 단계 후에, 지금까지 선정된 수백 개의 candidate를 내로우 다운(Narrow down) 형식으로 추려낼 필요가 있다. 이를 위해 CTR/CR(Click-Through Rate/ Click Rate)를 예측하는 모델을 통해 상품이 노출될 순위를 결정한다.
03 추천시스템의 평가
03.01 Basics
추천시스템을 평가하기 위하여는 아래 개념들에 대해 알아야 한다.
Precision
e.g. 범죄자라고 판단한 사람 중 진짜 범죄자가 몇명인가에 대한 비율이다.
e.g. 우리가 추천한 아이템 중에 사용자가 정말 관심있어하는 아이템의 비율이다.
Recall
e.g. 현재까지 본 범죄자들 중에서 실제로 범죄자라고 판단한 경우가 몇명인가에 대한 비율이다.
e.g. 실제로 사용자가 관심있어하는 아이템 중에 우리가 추천한 아이템의 비율이다.
우리가 추천한 아이템 개수: 5
추천한 아이템 중 사용자가 관심있어하는 아이템 개수 : 2
실제로 사용자가 관심있어하는 아이템 개수 : 3Precision = 2/5
Recall = 2/3
~@K
추천된 리스트 중에서 상위 K개만큼만 추출하여 평가하겠다는 의미이다.
03.02 Precision@K
추천한 K개의 아이템 중 사용자가 관심있어하는 아이템의 수이며, 순서 등은 고려되지 않는다.
03.03 Recall@K
사용자가 관심있어하는 아이템의 수 대비 추천된 실제 관심있는 아이템의 수이며, @K의 경우 K개를 넘을 수 없다.
03.04 MRR : Mean Reciprocal Rank
MRR은 각각의 질의 Q에 대해, 추천해 준 품목 중 사용자의 선호가 있는 항목이 최초로 등장한 것이 몇번째인지 파악하고, 그 역수를 취한다. 첫번째만 취하므로, 최적의 상품이 무엇인가에 대해 초점을 둔다.
첫번째 질의에서, 사용자가 선호하는 아이템이 두번째에, 두번째 질의에서 사용자가 선호하는 아이템이 세번째에 있었다면 계산식은 다음과 같다.
03.05 MAP : Mean Average Precision
Average Precision
P(i) : 해당 인덱스 i까지의 Precision
rel(i) : 해당 인덱스 i에서 user engagement가 일어났는지 여부(0 | 1)
| Recommandations | Precision@K(k=3) | AP@K(k=3) |
|---|---|---|
| [0, 0, 1] 추천 3, 선택1(3번) | [0, 0, 1/3] | (1/3)(1/3) = 0.11 |
| [0, 1, 1] 추천 3, 선택2(2,3번) | [0, 1/2, 2/3] | (1/3)(1/2+2/3) = 0.38 |
| [1, 1, 1] 추천 3, 선택3(1,2,3번) | [1/1, 2/2, 3/3] | (1/3)(1+1+1) = 1 |
| [0, 1, 0] 추천 3, 선택1(2번) | [0, 1/2, 0] | (1/3)(1/2) = 0.17 |
위 AP는 한명의 사용자에 대한 것으로, 전체 사용자에 대해 AP를 평균 낸 것을 mAP라고 한다.
03.06 nDCG@K : Normalized Discounted Cumulative Gain
DCG
또는
DCG는 추천항목의 관련성(별점 등)을 순위에 로그를 취해 나눈 값으로 나누어 순차적으로 합한 값이다. 후순위의 항목일수록 분모가 커지고, 관련성이 높을수록 분자가 커지므로 점수가 높을수록 더 뛰어난 성능을 나타낸다.
IDCG(Ideal DCG)
IDCG는 연관성이 높은 항목 순으로 높은 순위에 배치한 이상적인 DCG값을 이야기 한다. 연관성이 [5,4,3,2,1]인 항목이 있는 경우, IDCG는 다음과 같다.
nDCG
DCG를 IDCG로 나누어 얻은 정규화된 값을 nDCG라고 부른다.
03.08 MAE : Mean Absolute Error
MAE는 추천항목의 적절성을 평가하는 것이 아니고, 항목의 평점예측을 수행하여 평가한다.
03.07 RMSE : Root Mean Square Error
RMSE는 추천항목의 적절성을 평가하는 것이 아니고, 항목의 평점예측을 수행하여 평가한다.
04 추천시스템 종류 및 방법론
[ 추천을 받는 대상자 / 추천되는 대상 / 추천 규칙 자체] 중 어느쪽에 중점을 두는지에 따라 크게 [ Collaborative / Content-based / Rule-based ] 로 나뉜다. 조합되는 경우 Hybrid로 부른다. 이에 대한 내용은 깊게 다루지 않는다.
대신, 위 분류와 상관 없이, 독립적으로 또는 복합적으로 적용되는 추천 방법론들에 대해 다룬다. 아래 방법론들은 중복되거나 서로 포함관계에 있을 수 있다.
(작성중 - 예상되는 주요 방법론 :)
04.01 Simple Rule based
04.02 Matrix factorization based
04.03 Sequential based
04.04 Embedding based
04.05 Deep Learning based
04.06 Transformer based
04.07 Generative model based
