
CockroachDB는 단연컨데 horizontally scale (확장하기 위하여 서버의 성능을 고성능으로만 올리는것이 아니라, 여러 인스턴스로 하는 것) 하기에 가장 쉬운 RDBMS 일 것이다.
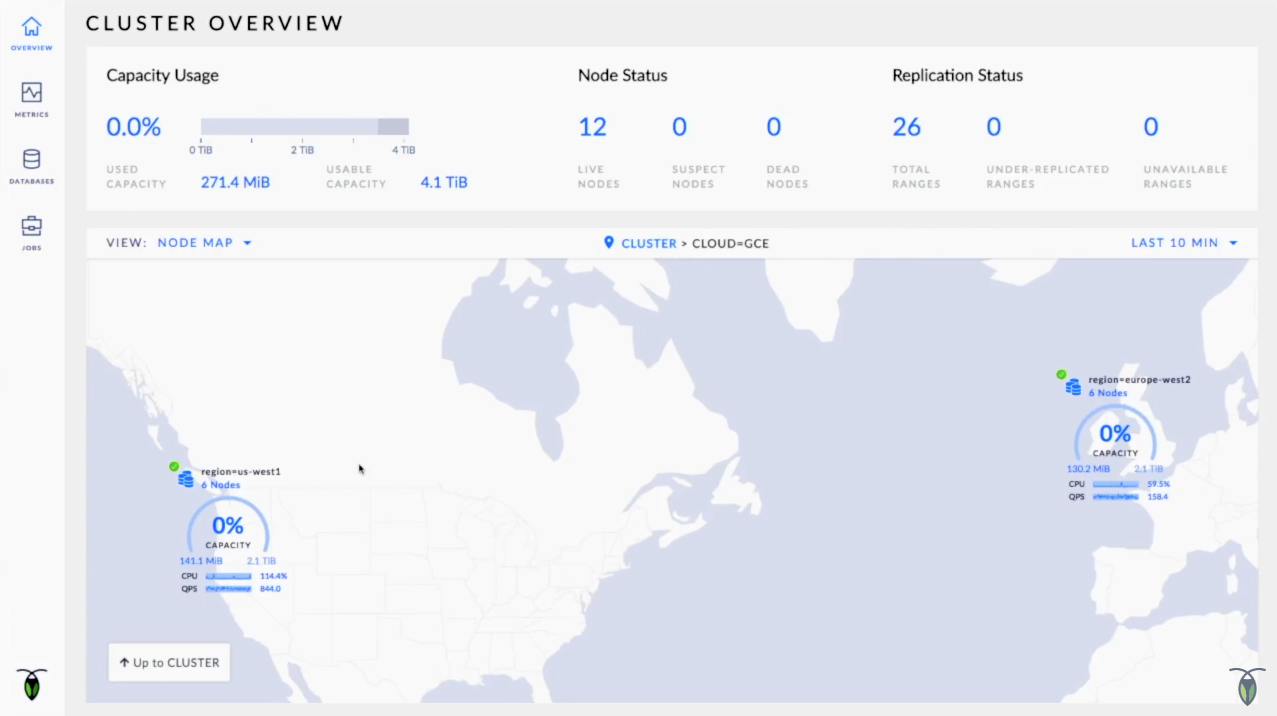
(출처:[Live Demo] Inside CockroachDB 2.0)
만약에 글로벌 서비스를 개발하고 있다면, 그리고 또 트래픽이 엄청난 서비스라면 CockroachDB를 고려해보는건 어쩌면 정말 좋은 선택 일 수도 있을 것이라고 생각한다.
보통은 일반적인 RDBMS 에서 horizontally scale 을 한다면 다음과 같은 구조로 하게 된다:
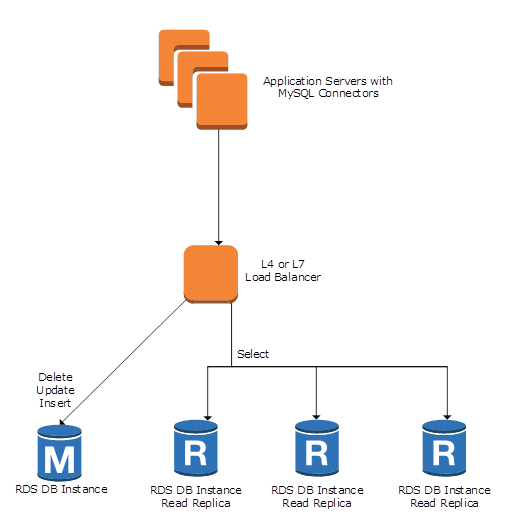
(출처: Scaling Your Amazon RDS Instance Vertically and Horizontally)
데이터베이스 한대는 DELETE, UPDATE, INSERT 작업을 할 수 있고 나머지는 SELECT 만 할 수 있는 형태이다.
또는, 샤딩을 하여 데이터를 분산시킬수도 있다.
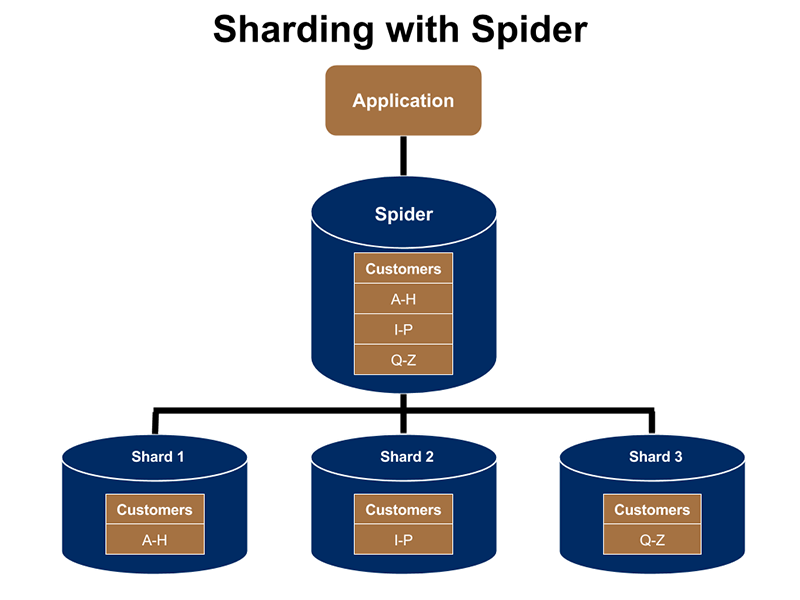
(출처: MariaDB 블로그)
하지만 CockroachDB 는 파티셔닝을 하지도 않으면서, 여러 인스턴스들이 같은 데이터들을 들고있는 형태이다.
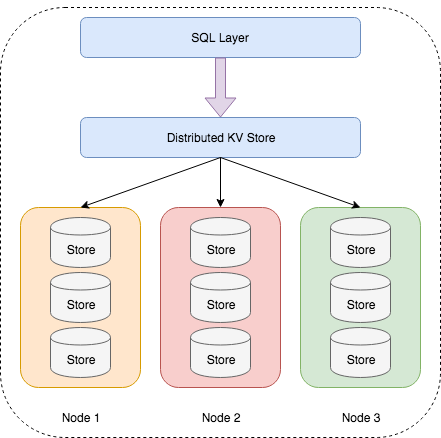
(출처: Scaleway)
CockroachDB 에서는 인스턴스에서 실행되는 서버를 노드라고 부르는데, 한 노드에서 데이터에 변화가 생기면 알아서 다른쪽으로 제대로 복사가 된다. 신기하게도 ACID 작업도 진짜 마법처럼 잘 작동한다.
데이터베이스 서버를 확장 할 때 downtime 없이 그냥 인스턴스를 추가하면 된다.
우리가 정적 파일들을 빨리 제공받기 위하여 CDN 을 사용하는 것 처럼, 데이터베이스도 마치 CDN 마냥 여러 지역에 펼쳐놓고, 백엔드 서버도 여러 지역에 펼쳐놓고, 가장 가까운 데이터베이스에서 가장 빠르게 전달받는것이 가능하다는 얘기이다.
그리고, 데이터 복제와 함께 데이터 자동복구 기능도 있어서, 노드중에 하나가 머신 자체에 결함이 생겨도, 데이터들이 살아남을 수 있다. 마치 바퀴벌레처럼.
이번에 벨로그를 개발하게 되면서, 트래픽이 늘어나도 서비스가 다운되지 않게 하기 위하여 처음부터 확장을 고려하여 설계를 하게 되면서 이전에 관심있었던 CockroachDB 를 사용하여 개발을 했었다. 그리고 백엔드 API 는 AWS Lambda 를 사용을 했기에, "만약에" 트래픽이 몰리면 데이터베이스 확장만 하면 되겠네! 하고 생각을 했었다. 그리고, PostgreSQL syntax 와 driver 랑 호환이 된다길래 조금 가벼운 마음으로 채택을 했는데... 이제 더 이상 사용하지 않으려고 한다.
우선 이 데이터베이스를 사용해보려고 한 것에 대해서는 후회하지 않는다.
분명히, 확장하기에 쉬운 데이터베이스인건 확실하다. 다른 RDBMS 대비하여 엄청나게 간단하다. 그저, 서버한대 준비하고 CLI 에 다른 서버의 주소들을 넣어서 실행해주면 된다.
내가 이 데이터베이스를 더 이상 사용하지 않겠다는 마음을 먹은건, 몇가지 이유가 있는데 한번 정리해볼까 한다.
1. 비용이 더 많이 든다.
CockroachDB 는 최소 3개의 노드가 있어야 제대로 작동을한다. 지금 t2.medium 1대, t2.small 2대, 그리고 t2.nano 에서 로드밸런서를 돌리고있는데, 이미 트래픽이 많은 서비스도 아니고, alpha 버전인 서비스에 이렇게 4대의 인스턴스가 사용되는건 조금 돈낭비라고 느껴졌다.
2. 왠지 모르지만 성능이 안좋다.
쿼리를 실행 할 때마다 조금 느리다는 느낌이 든다. 유사한 작업을 MariaDB 나 PostgreSQL 에서 할때는 굉장히 빨리되는 작업들이 여기서는 느리다... 성능에 최적화를 하기 위하여 시간을 투자하면 어찌저찌 해결 할 수 있을 것 같긴 하지만, 사이드 프로젝트여서 하루에 한시간씩만 투자를 하는지라 깊게 들어갈 시간이 없다.
3. PostgreSQL 이랑 호환이라지만 완벽 호환은 아니다.
일부 SQL 내장함수들이 존재하지 않는게 몇개 있고, 이번에 아예 PostgreSQL 로 전환하기로 마음을 먹게 된 계기는 MATERIALIZED VIEW 가 없다는 것.
지금 trending 페이지의 경우 포스트들의 점수를 연산하여 랭킹순으로 나열을 해줘야하는데, 여기서 성능부하가 꽤 있는 것 같아 MATERIALIZED VIEW 를 사용하려고 했더니, CockroachDB 에서 아직 지원을 하지 않는다. 물론, 내년쯤엔 왠지 구현이 될 것 같기는 한데....
추가적으로 테이블에서 JSON 값을 집어넣는 JSONB 타입의 경우엔 PostgreSQL 에선 예전부터 되던 기능이지만 CockroachDB 의 경우 올해 4월이 되서야 도입이 되었다.
즉.. 개발이 한발짝 늦다!
그래서..?
나는 velog 에서 사용하는 데이터베이스를 그냥 PostgreSQL 로 전환하려고 한다. 아마 2주 내에 진행을 하게 되지 않을까? 물론 시간이 더 많았더라면 조금 더 연구를 하고, 병목이 되는 부분을 최적화하는 형태로 CockroachDB를 계속 사용했을 것 같은데, 그럴만한 시간이 없으니까...
그리고 아직 scale out 할 단계도 아닌데 이런 설계를 사용을 한다는건 좀 잘못된 선택인 것 같기도 하다. 데이터베이스에서 사용되는 돈을 아껴서 차라리 레디스 캐시 서버에 사용을 하거나... 나중에 이벤트 용도로 사용하는게 더욱 쓸모 있을 것 같다.
하지만 CockroachDB 를 사용해본건 확실히 좋은 경험이였고, 나중에 서비스가 실제로 scale 해야 되는 상황이 오면 분명히 고려해볼 것 같다.
근데 PostgreSQL 로 전환했는데도 동일한 이슈가 발생한다면 어쩌지...? 그건 그때가서 고민해야겠다!
여기까지 써놓고, 실제로 데이터베이스 덤프 떠서 PostgreSQL 에 집어넣고 (다행히도 호환이 잘 됐다) Lambda 로 처리해보니까 빨라진게 확실히 느껴졌다. 확실히 데이터베이스 문제였던것을 확인하고, 마이그레이션하는거 연습하고 오늘 성공적으로 마이그레이션까지 했다!
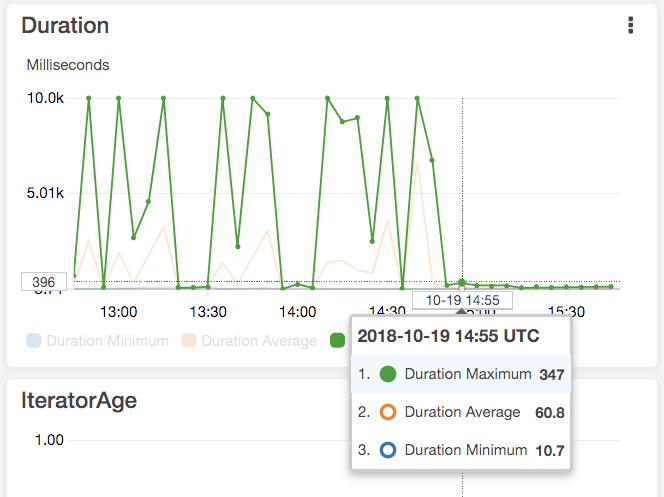
기존에는 계속해서 데이터베이스가 너무 느려서 요청이 10초이상 걸려서 timeout 되는 증상이 있었는데, 마이그레이션 후에는 그 증상이 (아직까진) 발생하지 않았다.
개이득! 이로 인하여 돈도 굳었다! (CockroachDB 를 구동하기 위하여 사용되던 4대의 인스턴스 - 3 노드, 1 로드밸런서 를 없앰)
CockroachDB 는 분명 멋진 데이터베이스이지만, 아마 내가 잘못된 서비스에서 적용을 한 듯 싶다. 그리고, 이것을 최적화하기엔 나의 시간이 부족했던것이지 절대 데이터베이스가 구린게 아닐 것이다. 솔직히 velog 를 시작 할 시점엔 이렇게 야심차게 개발할지몰라서 CockroachDB 가 굉장히 멋진 것 같아서, 특히 Lambda 랑 같이 쓰면 굉장히 멋질 것 같아서 그냥 실험적으로 CockroachDB 를 사용하긴 했지만.. 만약에 지금 마음으로 velog 를 다시 개발한다면 CockroachDB 를 처음부터 채택하지 않았을 것이다.
정말 혹시나, 이걸 읽고있는 당신이 CockroachDB 를 사용 할 계획이라면 When is CockroachDB a good choice? 를 읽어보고 정말 거기에 해당 할 때에만 사용하기를 바란다.
그리고..
이로 인하여 velog 는 다시 빠른 속도를 회복했습니다! 정확히 어떤 이유때문에 느렸는지는.... 잘 파악이 안가지만 어쨌든 데이터베이스를 바꾸면서 다행히 해결이 됐네요 :) 더 나은 서비스를 개발하기 위하여 앞으로도 노력하겠습니다!!

7개의 댓글


다 읽어보고 글에 좋아요를 누르고 싶었는데 글 마지막 부분에 좋아요 버튼이 없네요ㅠㅠ 다시 위로 올라가서 좋아요를 눌렀습니다 ㅎㅎㅎ


뭐
뭐지...? Cockroach db 찾아보다 안쓰기로 마음 먹었다는 글을 봤는데, 그게 벨로그 창시자셨어....? ㅡㅁㅡ??? 헐 ㅋㅋ


ㅋㅋㅋ 썸네일 사진이 압권이네요