웹 서비스의 개발/운영 시 피할수 없는 문제가 바로 데이터베이스를 다루는 일이다
SQL 매퍼(MyBatis)를 사용해 업무를 하면 다음과 같은 상황이 생긴다
- 실제 개발하는 시간보다 SQL을 다루는 시간이 더 많아진다
- 객체지향 프로그래밍을 활용하지 못한다
- 객체 모델링보단 테이블 모델링에 집중, 객체는 단순히 테이블 형식에 맞추어 데이터를 전달하는 역할만 하는 기형적인 형태의 개발 진행
JPA(자바 표준 ORM)를 통해 객체지향 프로그래밍이 가능해진다
- SQL Mapper
- 쿼리를 매핑
- MyBatis, iBatis
- ORM
- 객체를 매핑
- JPA
아직 SI 환경에서는 Spring & MyBatis를 많이 사용하지만, 자체 서비스를 운영하는 회사를 중심으로 SpringBoot & JPA를 점점 표준으로 도입하고 있다
3.1 JPA 소개
현대의 웹 애플리케이션에서 관계형 데이터베이스는 빠질 수 없는 요소이다
따라서 객체를 관계형 데이터베이스에서 관리하는 것이 매우 중요하다
기존의 Web - RDB 구조에는 다음과 같은 문제가 있었다
단순 반복 작업
RDB가 웹 서비스의 중심이 되면서 현업 프로젝트 대부분이 애플리케이션 코드보다 SQL로 가득하게 되었다
이는 RDB가 SQL만 인식할 수 있기 때문이며, 이로 인해 각 테이블마다 기본적인 CRUD SQL을 매번 생성해야 한다
C: insert into user (id, name, ...) values (...);
R: select * from user where ...;
U: update user set ... where ...;
D: delete from user where ...;개발자가 아무리 자바 클래스를 효율적으로 설계해도 결국 SQL을 통해서만 RDB를 사용할 수 있으며, 이와 같은 SQL의 중복과 단순 반복 작업은 유지보수를 어렵게 만든다
패러다임 불일치
관계형 데이터베이스는 어떻게 데이터를 저장할지에 초점이 맞춰진 기술이라면, 객체지향 프로그래밍은 메시지를 기반으로 기능과 속성을 한 곳에서 관리하는 기술이다
객체지향의 추상화, 캡슐화, 정보은닉, 다형성 등의 개념을 관계형 데이터베이스에서 표현하긴 쉽지 않다
RDB와 OOP의 패러다임이 다른데, 객체를 DB에 저장하려고 하니 여러 문제가 발생하는 것을 패러다임 불일치라고 한다
객체지향 프로그래밍에서 부모 객체를 가져오는 코드는 다음과 같다
User user = findUser();
Group group = user.getGroup();User가 본인이 속한 Group을 가져오는 코드로 두 객체가 부모(User) - 자식(Group) 관계에 있다는 것을 쉽게 알 수 있다
하지만 여기에 관계형 데이터베이스가 추가되면,
User user = userDao.findUser();
Group group = groupDao.findGroup(user.getGroupId());User 따로, Group 따로 조회하게 되며 두 객체 사이의 관계를 파악하기 힘들다
상속, 1:N 등의 객체 모델링을 데이터베이스로는 구현할 수 없으며 웹 개발은 점점 데이터베이스 모델링에만 집중하게 된다
JPA는 이렇게 서로 지향하는 바가 다른 2개 영역(OOP, RDB)의 중간에서 패러다임을 일치시켜주기 위한 기술이다
개발자는 객체지향적인 프로그래밍을 하고, JPA가 이를 RDB에 맞게 SQL을 대신 생성, 실행하여 더는 SQL에 종속적인 개발을 하지 않도록 해준다
Spring Data JPA
JPA는 인터페이스로 자바 표준명세서이다
인터페이스인 JPA를 사용하려면 Hibernate, Eclipse Link 등의 구현체가 필요하지만 Spring에서 JPA를 사용할 때는 구현체를 직접 다루지 않고 Spring Data JPA라는 모듈을 이용한다
Spring Data JPA → Hibernate → JPA
이렇게 한단계 더 감싸놓은 Spring Data JPA가 등장한 이유는 크게 2가지이다
1) 구현체 교체의 용이성
Hibernate 외에 다른 구현체로 쉽게 교체하기 위함
Spring Data JPA 내부에서 구현체 매핑을 지원해 새로운 JPA 구현체가 대세로 떠오를 경우, 쉽게 교체 가능
2) 저장소 교체의 용이성
관계형 데이터베이스 외에 다른 저장소로 쉽게 교체하기 위함
관계형 데이터베이스에서 MongoDB로 교체가 필요하다면 개발자는 Spring Data JPA에서 Spring Data MongoDB로 의존성만 교체
위 사항들이 가능한 이유는 Spring Data 하위의 프로젝트들(Spring Data JPA, Spring Data MongoDB...)의 기본적인 CRUD의 인터페이스가 같기 때문이다
실무에서 JPA
실무에서 JPA를 사용하지 못하는 가장 큰 이유는 객체지향 프로그래밍과 관계형 데이터베이스를 두루 이해해야 하는 높은 러닝 커브이다
하지만, JPA를 사용함으로써 얻는 이점이 매우 크다
- CRUD 쿼리를 직접 작성할 필요가 없다
- 객체지향적 → 부모-자식 / 1:N / 상태와 행위를 한곳에서 관리
요구사항 분석
이 책의 구성
- 1장 ~ 2장: 환경설정
- 3장 ~ 6장: 게시판 웹앱 개발
- 7장 ~ 10장: AWS 무중단 배포
주요 기능
- 게시판 기능
- 게시글 조회
- 게시글 등록
- 게시글 수정
- 게시글 삭제
- 회원 기능
- 구글 / 네이버 로그인
- 로그인한 사용자 글 작성 권한
- 본인 작성 글에 대한 권한 관리
3.2 프로젝트에 Spring Data JPA 적용하기
먼저 build.gradle의 dependency 항목에 다음과 같이 의존성을 등록한다
// 스프링 부트용 Spring Data Jpa 추상화 라이브러리
compile('org.springframework.boot:spring-boot-starter-data-jpa')
// 인메모리 관계형 DB, 메모리에서 실행되므로 애플리케이션 시작시 마다 초기화 -> 테스트용
compile('com.h2database:h2')domain 패키지 생성
com.vencott.dev.springboot.domain
도메인: 게시글, 댓글 회원, 정산, 결제 등 SW에 대한 요구사항 혹은 문제 영역
MyBatis와 같은 쿼리 매퍼에선 dao 패키지를 생성하겠지만, 그간 xml에 쿼리를 담고 클래스는 오로지 쿼리의 결과만 담던 일들이 모두 도메인 클래스에서 해결
Posts 클래스
package com.vencott.dev.springboot.domain.posts;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import javax.persistence.*;
// 클래스 내 모든 필드의 Getter 메소드 자동 생성
@Getter
// 기본 생성자 자동 추가
@NoArgsConstructor
// 테이블과 링크될 클래스임을 나타냄
@Entity
public class Posts {
// 해당 클래스의 PK
@Id
// PK의 생성 규칙, 스프링 부트 2.0에선 GenerationType.IDENTITY 옵션을 추가해야만 auto_increment
// PK는 웬만하면 Long 타입의 auto_increment 추천
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// 테이블의 컬럼(생략 가능), 기본값 이외 추가로 변경할 옵션 기입
@Column(length = 500, nullable = false)
private String title;
@Column(columnDefinition = "TEXT", nullable = false)
private String content;
private String author;
// 해당 클래스의 빌더 패턴 클래스 생성
// 생성자 상단에 선언 시 생성자에 포함된 필드만 빌더에 포함
@Builder
public Posts(String title, String content, String author) {
this.title = title;
this.content = content;
this.author = author;
}
}어노테이션 순서
주요 어노테이션을 클래스에 가깝게
@Entity는 JPA, @Getter와 @NoArgsConstructor는 롬복의 어노테이션
롬복은 필수가 아니고, 코틀린 등의 새 언어 전환으로 롬복이 더이상 필요 없을 경우 쉽게 삭제 가능하므로 클래스와 멀리 배치
Entity 클래스
Posts 클래스는 실제 DB의 테이블과 매칭될 클래스
JPA를 사용하면 DB 작업을 할 때, 실제 쿼리를 날리기보단 이 Entity 클래스 수정을 통해 작업
Setter 메소드
자바빈 규약을 생각하면서 getter/setter를 무작정 생성하는 경우가 있는데, 해당 클래스의 인스턴스 값들이 언제 어디서 변해야 하는지 코드상으로 명확하게 구분 불가
Entity 클래스에서는 절대 Setter 메소드를 만들지 않는다
대신 필드 값 변경이 필요하면 명확히 그 목적과 의도를 나타낼 수 있는 메소드를 추가
// 잘못된 예
public class Order {
public void setStatus(boolean status) {
this.status = status;
}
}
public void 주문서비스의_취소이벤트() {
order.setStatus(false);
}
// 올바른 예
public class Order {
public void cancelOrder() {
this.status = false;
}
}
public void 주문서비스의_취소이벤트() {
order.cancelOrder();
}Setter가 없는 상황에서 어떻게 DB에 삽입?
생성자를 통해 최종값을 채운 후 DB에 삽입
값 변경이 필요한 경우 해당 이벤트에 맞는 public 메소드 호출
이 책에서는 생성자 대신 @Builder를 통해 제공되는 빌더 클래스 사용
빌더 패턴은 생성자와 동작 방식은 같으나, 지금 채워야 할 필드가 무엇인지 명확하게 지정 가능
Example.builder()
.a(a)
.b(b)
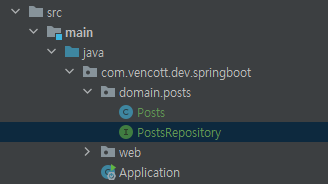
.build();PostsRepository 인터페이스
Posts 클래스로 DB를 접근하게 해줄 JpaRepository 생성
package com.vencott.dev.springboot.domain.posts;
import org.springframework.data.jpa.repository.JpaRepository;
public interface PostsRepository extends JpaRepository<Posts, Long> {
}보통 MyBatis 등에서 Dao라고 불리는 DB Layer 접근자
JPA에선 Repository라고 부르며 인터페이스로 생성
단순히 인터페이스 생성 후 JpaRepository<Entity 클래스, PK 타입>를 상속하면 기본적인 CRUD 메소드가 자동 생성됨
@Repository를 추가할 필요도 없으며 Entity 클래스와 Entity Repository는 함께 위치
Entity 클래스는 기본 Repository 없이는 제대로 역할 X
3.3 Spring Data JPA 테스트 코드 작성하기
PostsRepositoryTest 클래스 생성
package com.vencott.dev.springboot.domain.posts;
import org.junit.After;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
import static org.assertj.core.api.Assertions.assertThat;
@RunWith(SpringRunner.class)
@SpringBootTest
public class PostsRepositoryTest {
@Autowired
PostsRepository postsRepository;
// Junit에서 단위 테스트가 끝날 때마다 수행되는 메소드를 지정
@After
public void cleanup() {
postsRepository.deleteAll();
}
@Test
public void 게시글저장_불러오기() {
//given
String title = "테스트 게시글";
String content = "테스트 본문";
// posts 테이블에 insert/update 쿼리를 실행(id 있으면 update, 없으면 insert)
postsRepository.save(Posts.builder()
.title(title)
.content(content)
.author("jojoldu@gmail.com")
.build());
//when
// posts 테이블에 있는 모든 데이터를 조회해오는 메소드
List<Posts> postsList = postsRepository.findAll();
//then
Posts posts = postsList.get(0);
assertThat(posts.getTitle()).isEqualTo(title);
assertThat(posts.getContent()).isEqualTo(content);
}
}@SpringBootTest를 사용할 경우 H2 데이터베이스를 자동으로 실행
실제 쿼리 확인하기
테스트를 실행해보면 실제 쿼리 내용을 알 수가 없다
src/main/resources 디렉토리를 생성 후 application.properties 파일을 생성하고 다음과 같이 입력한다
spring.jpa.show_sql=true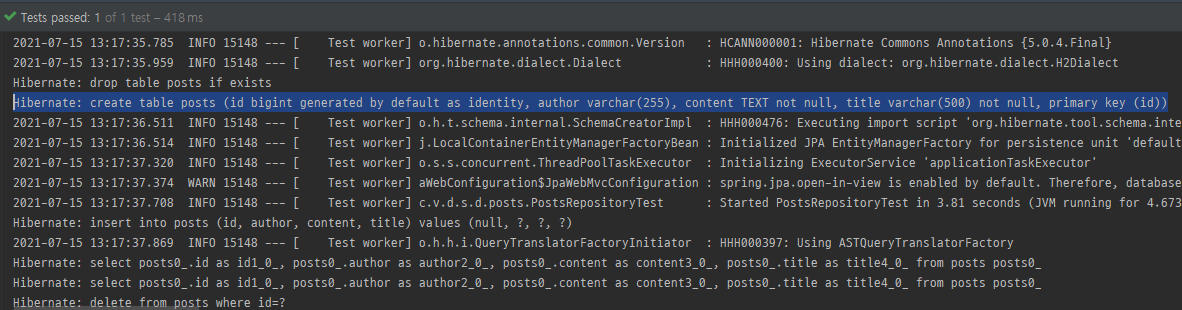
MySQL 쿼리로 변경
여기서 create table 쿼리를 보면 id bigint generated by default as identity 라는 옵션으로 생성된 것을 볼 수 있는데, 이는 H2의 쿼리 문법이 적용됐기 때문이다
H2는 MySQL의 쿼리를 수행해도 정상적으로 작동하기 때문에 이후 디버깅을 위해 application.properties에서 출력되는 쿼리 로그를 MySQL 버전으로 변경해준다
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect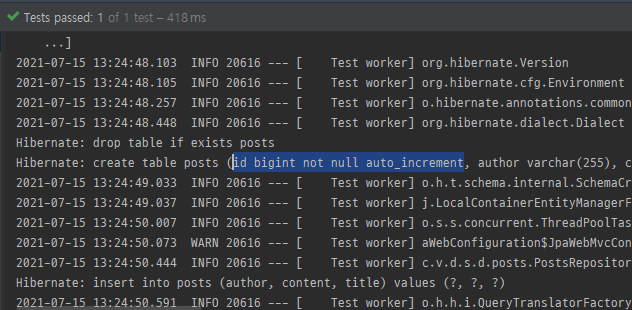
출처: 이동욱 저, 『스프링 부트와 AWS로 혼자 구현하는 웹 서비스』, 프리렉(2019)
