1. 입력
첫째 줄에 가지고 있는 랜선의 개수 N개, 필요한 랜선의 개수 K개가 입력된다.이후 N+1 번째 줄까지 가지고 있는 랜선의 길이가 입력된다.
4 11
802
743
457
5392. 출력
K개 이상의 랜선을 만들 수 있는 랜선의 최대 길이를 출력한다.
200-
랜선의 길이가 200일 때, 길이 802의 랜선에서 4개, 길이 743의 랜선에서 3개, 길이 457의 랜선에서 2개, 길이 539의 랜선에서 2개 총 11개 (4+3+2+2)를 만들 수 있다.
-
랜선의 길이가 201일 때, 길이 802의 랜선에서 3개, 길이 734의 랜선에서 3개, 길이 457의 랜선에서 2개, 길이 539의 랜선에서 2개 총 10개 (3+3+2+2)를 만들 수 있다.
-
따라서, 랜선 11개를 준비하기 위한 랜선의 최대 길이는 200이다.
3. 풀이
본 문제는 이분 탐색 문제이다. 이분 탐색이란, 범위를 설정한 후에 범위 내에 찾고자 하는 값이 있을 때 범위를 절반으로 줄여나가며 최종적으로 값을 찾는 문제이다.
이분 탐색에 대한 개념을 확고히 하고자, 본 문제 풀이 방법을 구체적으로 서술하고자 한다.
3.1. 이진 분류
먼저 문제를 설정하는 것이 중요하다.
찾고자 하는 값을 x라고 가정하자. x는 K개 이상의 랜선을 만들고 싶을 때 랜선의 최대길이이다.
본 알고리즘의 목표를 이진 분류 문제로 접근하자면 "랜선의 길이가 L일 때, K개 이상의 랜선을 만들 수 있는가?"로 치환할 수 있다.
가령 랜선의 길이 L이 정답 x보다 짧거나 같다면, K개 이상의 랜선을 만들 수 있기 때문에 True를 반환한다.
혹은, 랜선의 길이 L이 정답 x보다 길다면,x가 K개의 랜선을 만들기 위한 최대길이기 때문에 False를 반환한다.
문제 : "랜선의 길이가
L일 때, 요구되는 랜선 개수K개 이상의 랜선을 만들 수 있는가?"
3.2 경우의 수
입력에 따른 이진 분류 문제의 출력은 arr = [T,...,T,T,F,F,...,F]와 같이 표현할 수 있다. 랜선 길이가 x보다 짧다면 무조건 True가, x보다 길다면 무조건 False가 반환되기 때문이다. arr에서 x는 True의 index 중 가장 큰 값이다.
탐색 범위의 최소값(low), 탐색 범위의 중앙값(mid), 탐색 범위의 최대값(high)의 조합은 다음과 같은 두 가지 경우의 수 하나가 될 수 있다.
경우 1. [T,T,F]
mid가 True기 때문에, mid 왼편의 모든 값은 True가 된다. 따라서, 탐색 범위를 mid 오른편으로 좁혀야 하며, low가 mid로 초기화된다.
(low = mid)
경우 2. [T,F,F]
mid가 False기 때문에, mid 오른편의 모든 값은 False가 된다. 따라서, 탐색 범위를 mid 왼편으로 좁혀야 하며, high가 mid로 초기화된다.
(high = mid)
탐색 범위를 계속 좁히다보면 [low, mid, high]가 오직 1씩 차이가 나도록 좁혀질 것이다. 자, 그렇다면 low, mid, high 중 어떤 값을 취해야 할까?
경우 1일 때, x는 두 번째 T기 때문에 mid를 취해주면 된다. 그러나 low가 mid로 초기화되기 때문에 low를 취해줘도 무관하다.
경우 2일 때, x는 첫 번째 T기 때문에 low를 취해주면 된다. 어차피 high가 mid로 초기화되기 때문에 나머지 두 값과는 관계가 없다.
결론적으로, 어떤 경우에도 low를 취해주면 정답이 된다.
3.2.1 [T,T,T]와 [F,F,F]
누군가는 경우의 수가 [T,T,F]와 [T,F,F]만으로 이루어지는 것에 의문을 가질 수 있다. [T,T,T]와 [F,F,F]의 경우의 수도 가능하다고 생각할 수 있기 때문이다.
제일 처음의 low와 high가 제대로 설정되어 있다면, 최초 arr은 경우 1 혹은 경우 2일 것이다. low는 무조건 True, high는 무조건 False기 때문이다.
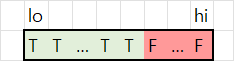
경우 1 [T,T,F]일 때는 low의 값이 mid가 된다.
기존의 mid가 True고, False인 high에는 변화가 없기 때문에 범위가 변하더라도 경우 1 혹은 경우 2로 귀결된다.
경우 2 [T,F,F]일 때는 high의 값이 mid가 된다. 마찬가지로, 기존의 mid가 False고, True인 low의 값엔 변화가 없기 때문에 새로운 범위도 경우 1 혹은 경우 2가 된다.
즉, [T,T,T]와 [F,F,F]는 절대 발생하지 않는다.
3.3 결론
결론적으로, while loop를 통해 탐색 범위를 계속 절반으로 좁힌 후에, low를 출력하면 정답이 된다. while loop가 돌아가는 동안 [low, mid, high]는 1씩 차이가 나는 상태가 되기 때문에, 세 값이 1씩 차이가 나지 않을 경우에 while loop를 탈출하면 된다.
4. 코드
import sys
# get input
input = sys.stdin.readline
N, K = map(int, input().split()) # N : 랜선의 개수, K : 필요한 랜선의 개수
lines = [int(input()) for _ in range(N)] # 각 랜선의 길이를 저장하는 배열
# 이진 분류 문제로 치환
def is_acceptable(lines, K, mid):
count = 0
for line in lines:
count += line//mid
if count >= K:
return True
else:
return False
# 이분 탐색
low = 1 # 랜선의 최소길이
high = max(lines)+1 # 랜선의 최대길이
while low + 1 < high:
mid = (low + high)//2
b = is_acceptable(lines, K, mid) # b stands for boolean
if b == True:
low = mid
else:
high = mid
print(low)4.1 비고 (실패 사례)
본 코드는 수정 전, 탐색 범위 설정 문제로 두 번의 실패를 경험했다.
lines = [802, 743, 457, 539]라고 가정한다.
사례 1. high = min(lines)
길이가 457인 랜선은 802로 나눌 수 없기에, 랜선 중 가장 짧은 값을 탐색 범위의 최대값으로 설정했었다.
그러나 lines = [10, 1, 1, 1]일 경우와 같이, 길이 10인 랜선을 자를 수 없는 경우가 발생하기 때문에 오류가 생긴다.
사례 2. high = max(lines)
실패 사례 1을 토대로 탐색 범위의 최대값을 길이가 가장 긴 랜선으로 설정하였다. 그러나 만약 필요한 랜선이 단 한개라면, 정답 x는 802가 된다. 그러나 high역시 802가 되기 때문에 가능한 이진 분류 출력이 모두 True가 되버린다. 즉, 앞서 언급한 [T,T,T] 문제가 발생하는 것이다. 따라서 이를 피하기 위해 max(lines)에 1을 더해주는 것으로 맨 마지막 값을 F로 바꿔준다.
