트위터 크롤링 하는 방법? 쉽다. 많다.
하지만 나에게도 쉬울거란 보장은 없음.
여러가지 방법 시도 후 가장 쉽고 오류가 안나는 방법으로
트위터 크롤링 가이드를 가지고 왔습니다.
*네이버의 어떤 분 블로그 참고하였음. 감사합니다!
트위터 크롤링 하는 법
-
트위터 개발자 계정 신청 후 api key 받기
https://developer.twitter.com/en -
import 해줄 것
import tweepy
import snscrape.modules.twitter as sntwitter
import pandas as pd- 키 입력
# 트위터 API에 접근하기 위한 개인 키를 입력
consumer_key = "blahblah"
consumer_secret = "blahblah"
access_token = "blahblah"
access_token_secret = "blahblah"
# OAuth 핸들러 생성 & 개인정보 인증 요청
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
# 액세스 요청
auth.set_access_token(access_token, access_token_secret)
# api instace 생성
api = tweepy.API(auth)- 본격 크롤링
# 트윗 크롤링 후 담을 리스트 생성
tweets_list = []
# TwitterSearchSc,ㅡ .raper를 이용하여 해당 트윗을 긁어와서 리스트에 넣기 ('검색어 since:시작날짜 until:끝나는날짜)
# 무료 버전은 트윗 수 5000개 이하로 제한
for i,tweet in enumerate(sntwitter.TwitterSearchScraper('단짠단짠 since:2020-01-01 until:2022-08-18').get_items()):
if i>5000:
break
tweets_list.append([tweet.date, tweet.content, tweet.likeCount])
# 데이터 프레임으로 저장
tweets_df = pd.DataFrame(tweets_list, columns=['Datetime', 'Text', 'Like'])
tweets_df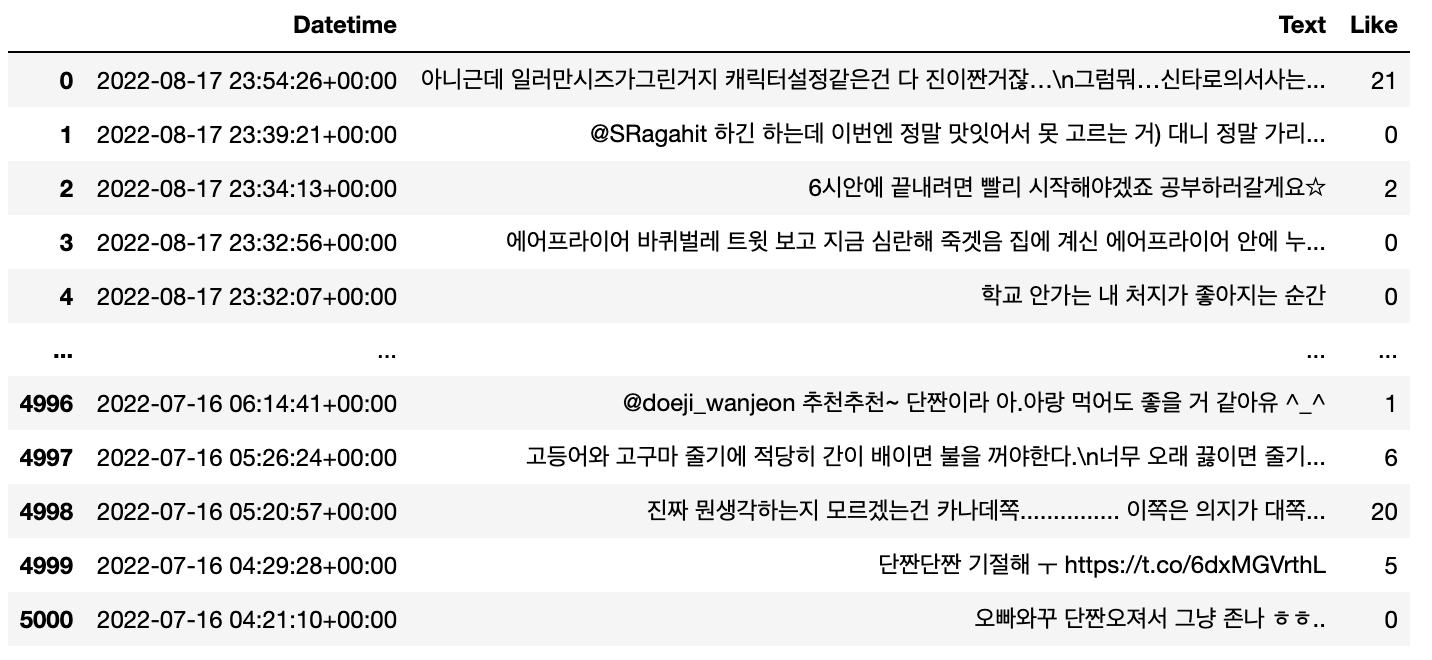
이 방법으로 누구나 손쉽게 크롤링 할 수 있기를-!

velogon