📌4. 라우팅 프로토콜
라우팅 테이블을 관리하는 방식에 따른 분류
- 디스턴스 벡터 알고리즘
- 링크 스테이트 알고리즘
4.1 디스턴스 벡터 알고리즘
디스턴스(Distance, 거리)와 벡터(Vector, 방향)만을 위주로 만들어진 알고리즘
- 라우터는 목적지까지의 모든 경로를 자신의 라우팅 테이블 안에 저장하지 않고 목적지까지의 거리(hop count 등)와 목적지에 가려면 어떤 인접 라우터를 거쳐야하는지에 대한 방향만을 저장한다.
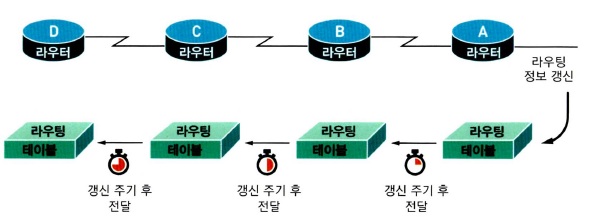
- 인접 라우터들과 주기적(RIP의 경우 30초에 한번 등)으로 라우팅 테이블을 교환해서 자신의 정보에 변화가 생겼는지를 확인한다.
장점 : 한 라우터가 모든 라우팅 정보를 갖고 있을 필요가 없어서 메모리를 저장하고, 라우팅의 구성이 간단해진다.
단점 : 라우팅 테이블의 변화가 없더라도 정해진 시간마다 업데이트가 일어나서 쓸데 없는 트래픽이 발생한다.
라우팅 테이블에 변화가 생길 경우 모든 라우터가 변화를 업데이트 하기 까지 걸리는 시간이 느리다.
👉라우팅 테이블의 변화가 생기면 인접 라우터에만 전달하므로 라우팅 테이블의 변화를 알아채는데 시간이 걸린다.
👉느린 업데이트 때문에 RIP의 경우에는 최대 홉 카운트가 15개로 제한된다. (라우터의 개수를 15개로 제한)
4.2 링크 스테이트 알고리즘
- 한 라우터가 목적지까지의 모든 경로 정보를 다 저장한다.
- 먼저 링크에 대한 정보를 토폴로지 데이터베이스로 만든다.
👉어디에 어떤 네트워크가 있고, 어떤 라우터를 통해 가야하는지에 대한 정보 - 토폴로지 데이터베이스를 가지고 라우터는 SPF(Shortest Path First) 알고리즘을 계산한다.
👉어디로 가야 가장 빠르게 갈 수 있는지를 계산
-라우터가 SPF 계산 결과를 갖고 SPF 트리를 만든다.
👉이를 이용해 라우팅 테이블을 생성한다.
장점 :
- 목적지까지의 모든 경로를 알고 있기 때문에 중간에 링크의 변화가 생겨도 이를 알아차리는데 걸리는 시간이 짧다.
- 라우팅 테이블의 교환이 자주 발생하지 않고, 교환이 일어나는 경우에도 테이블에 변화가 있는 것만을 교환하여 트래픽의 발생을 줄인다.
단점 :
- 라우터가 모든 라우팅 정보를 관리해야 하기 때문에 메모리를 많이 소모한다.
- SPF 계산 등 여러 계산을 하기 때문에 라우터 CPU에 부하가 크다.
예시)
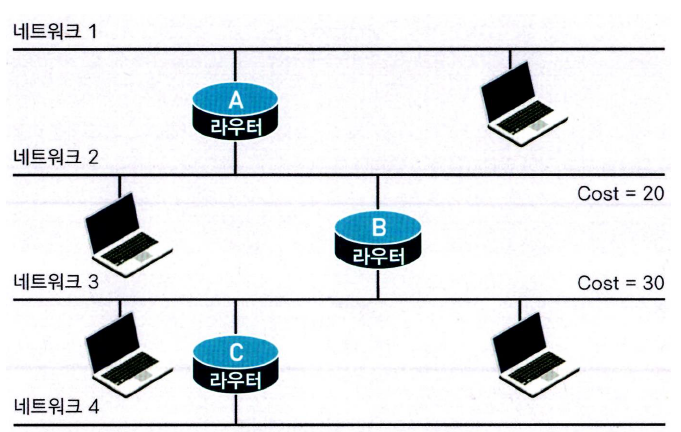
- 라우터 A는 네트워크 1과 네트워크 2에 직접연결 되어 있으므로 Cost 0 으로 도달한다.
- 라우터 A는 라우터 B까지 Cost 20으로 도달한다.
👉네트워크2를 거쳐서 B로 갈때 Cost 20이 발생한다. - 라우터 B는 네트워크 2와 네트워크 3에 직접연결 되어 있으므로 Cost 0으로 도달한다.
- 라우터 B가 라우터 A까지는 Cost20, 라우터 C 까지는 Cost 30이 든다.
- 라우터 C는 네트워크 3과 4에 Cost 0으로 접속하고, B에는 30으로 접속한다.
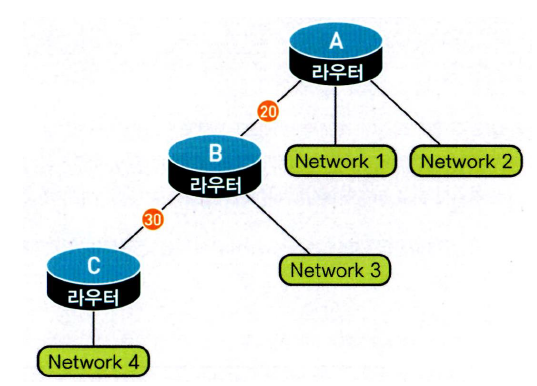
위 정보를 토대로 토폴로지 데이터베이스를 작성한다.

위 토폴로지 데이터베이스로 라우터 A의 SPF 트리를 구성한다.
👉라우터 A를 트리의 루트로 두고 각 목적지까지의 코스트를 계산한다.
4.3 핑과 트레이스
라우터를 구성한 후 네트워크와의 연결에 이상이 없는지 테스트하는 프로그램
👉출발지에서 목적지까지 연결에 이상이 없는지, 이상이 있다면 어디에서 이상이 발생했는지 찾아낼 수 있다.
4.3.1 단순형 핑
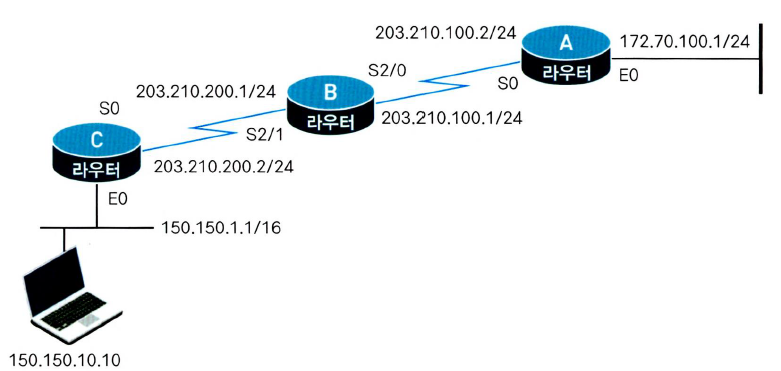
목적지가 172.70.100.1일때 에코 패킷의 출발지 IP주소 : 203.210.200.2
👉출발지 주소는 라우터를 떠나는 인터페이스 주소가 된다.
4.3.2 확장형 핑
에코 패킷의 출발지를 지정하거나, 에코 패킷의 크기, 반복횟수(디폴트는 5번) 등 옵션을 선택할 수 있다.
4.3.3 트레이스
- 핑 : 에코 패킷이 중간에 어디를 거쳐서 가는지, 예를 들어 얼마의 시간이 걸렸다면 각 구간별로는 얼마만큼의 시간이 소요되었는지 등에 대한 경로 정보를 얻을 수 있다.
- 트레이스 : 출발지에서 목적지 뿐 아니라 중간에 거친 경로에 대한 정보와 소요 시간까지 확인할 수 있다.

-
TTL (Time To Live) : 라우터 하나를 거칠 때마다 1씩 감소하여 0이 되면 패킷을 버리면서 에러가 발생하도록 한 값 👉 루핑을 방지하기 위해 사용한다.
-
트레이스를 시작할때 맨 처음에는 TTL 1로 패킷을 보낸다.
👉첫 라우터를 넘어가면서 TTL이 0이 되면 에러 메시지가 발생하고 돌아온다. -
그 다음에는 TTL 값을 2로 보내고 두번째 라우터에서 TTL이 0으로 바뀌고, 다시 에러 메세지를 출력한다.
-
이런식으로 TTL을 하나씩 증가시키면서 목적지로 보내서 돌아오는 메세지를 가지고 경로를 추적한다.
