[논문리뷰] Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models

최근 CoT, ToT, GoT 등과 같이 prompt를 통해 thoughts를 생성하며 reasoning하는 방식들이 대두되고 있는데 buffer에 고차원 수준의 thought-template을 저장하고 갖다 쓰는 방식이 참신하여 리뷰하게 되었다.
Abstract
- Buffer of Thoughts(BoT) - thought-augmented reasoning approach
- 문제 해결 과정에서 추출된 thought-template을 저장하는 meta-buffer를 제안
- LLM의 정확성, 효율성, 강건성을 높이기 위해
- meta-buffer로부터 관련 있는 thought-template를 검색하고 적응적으로 인스턴스화하여 추론 수행
- 안정성, 확장성을 위해 meta-buffer를 동적으로 관리하는 buffer-manager를 제안
Introduction
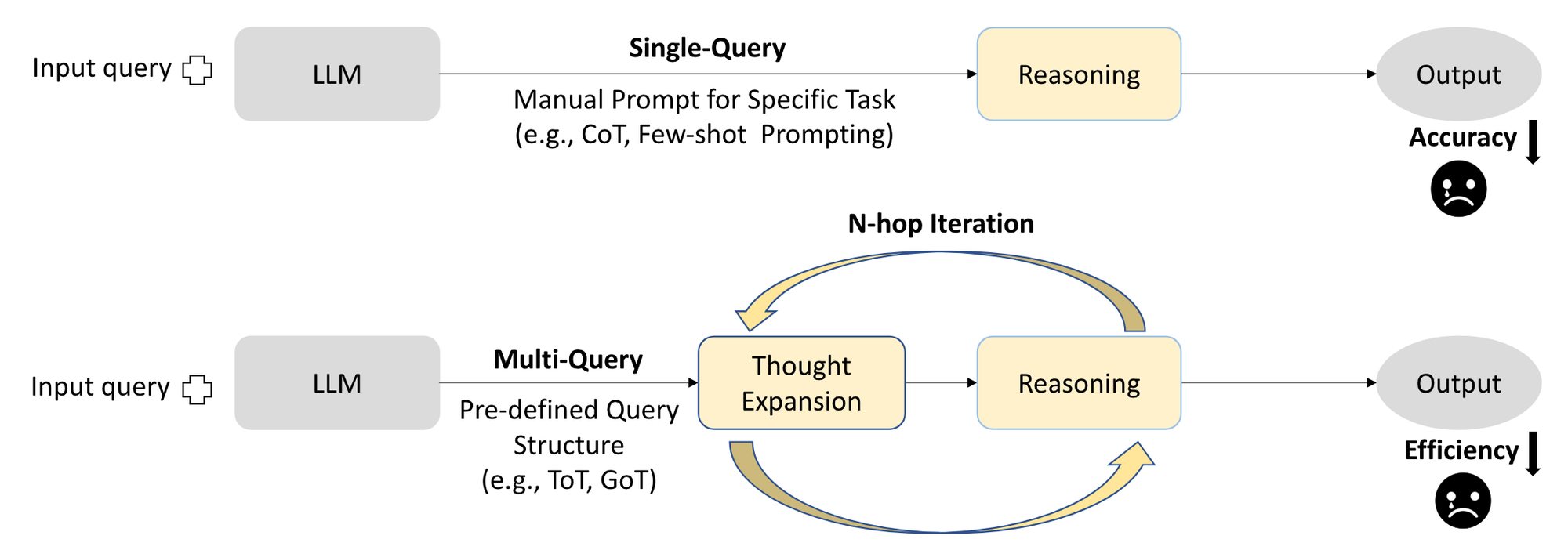
- 모델 크기를 확장하는 것 이외에 성능을 높이는 프롬프팅 방법
1. single-query reasoning → prompt engineering
- CoT(Let’s think step by step)
- 태스크 별로 예시(few-shot)가 필요하기 때문에 보편성, 일반화가능성, 정확성 부족
2. multi-query reasoning → 하위 문제로 분해하여 적절한 추론 경로를 도출
- ToT, GoT
- recursive expansion → computationally-intensive → 비효율적
- 두 방법 모두 추론 구조를 미리 설계해야 함 → 좀 더 일반적이고 높은 수준의 추론이 필요
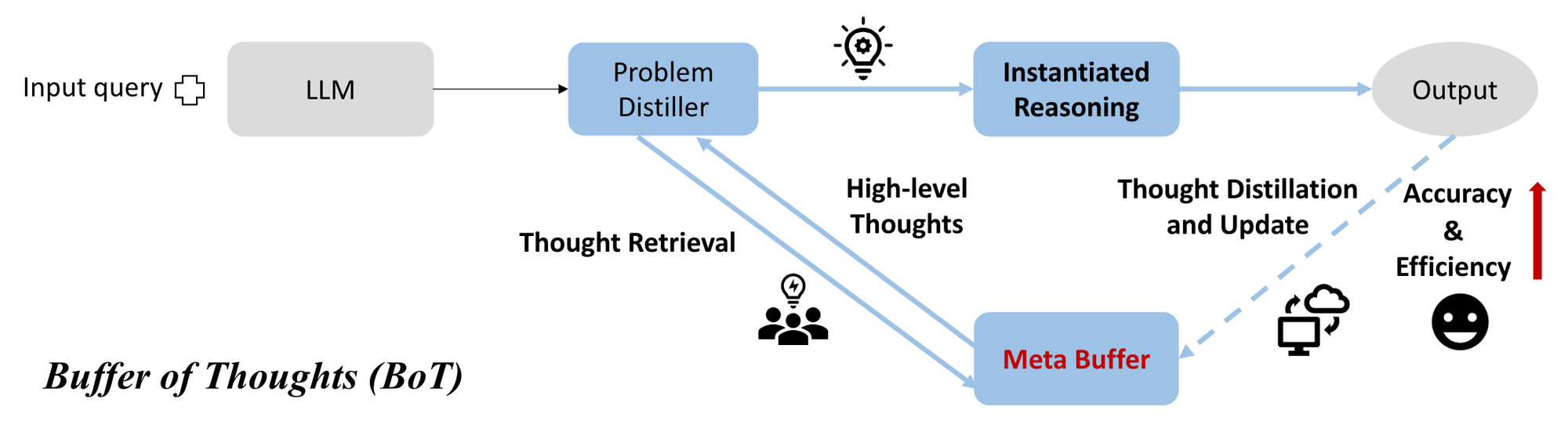
Contribution
- 정확성, 효율성, 여러 태스크에 대한 강건성을 가진 Buffer of Thoughts(BoT) 제안
- 추론 구조를 처음부터 구축하지 않고 공유된 thought-template를 사용 → 정확성
- 추론 과정에서 적절한 thought-template을 검색하여 추론에 사용 → 추론 효율성
- 인간의 사고 방식과 유사 → LLM이 유사한 문제를 일관된 방식으로 해결 → 모델 견고성
- meta-buffer : 다양한 문제 해결 과정에서 도출된(distilled) thought-template를 가진 작은 라이브러리
- 특정 작업을 해결하기 위해 thought-template를 적응적으로 인스턴스화(adaptively instantiate)
- 각 thought-template를 상황에 맞게 변화시켜 구체화하여 적용한다는 의미
- 특정 task에 특화된 template이 아닌 다른 task에도 적용할 수 있다는 특징을 강조
- 특정 작업을 해결하기 위해 thought-template를 적응적으로 인스턴스화(adaptively instantiate)
- buffer-manager : 다양한 문제 해결 상황에서 thought-template를 추출하고, meta-buffer를 동적으로 업데이트하며 버퍼의 용량을 향상
- 각종 benchmark 실험에서 성능 향상 달성하고 비용 효율성 상승 → Game of 24, Geometric Shapes, Checkmate-in-One
Related Work and Discussions
Retrieval-Augmented Language Models
- 특정 정보가 담긴 외부 데이터베이스를 사용하는 RAG와는 달리 series of high-level thought를 포함하는 meta-buffer를 검색 데이터베이스로 사용
Prompt-based Reasoning with Large Language Models
- CoT, ToT, GoT 등의 메타 프롬프팅 방식은 많은 context window를 필요로 하며 과거 정보를 활용하기 힘들고 유사한 다른 태스크에 적용하기 힘듦
Analogical Reasoning
-
유추 → 유비에 근거한 추론 → 대상들 사이의 형태적, 관계적, 구조적 유사성을 찾아내어 그것을 근거로 추론
-
아래 그림의 경우 작은 원:큰 원 = 작은 사각형:큰 사각형을 유추할 수 있듯 다른 대상 간의 관계 및 특성으로부터 ?에 대한 추론이 가능
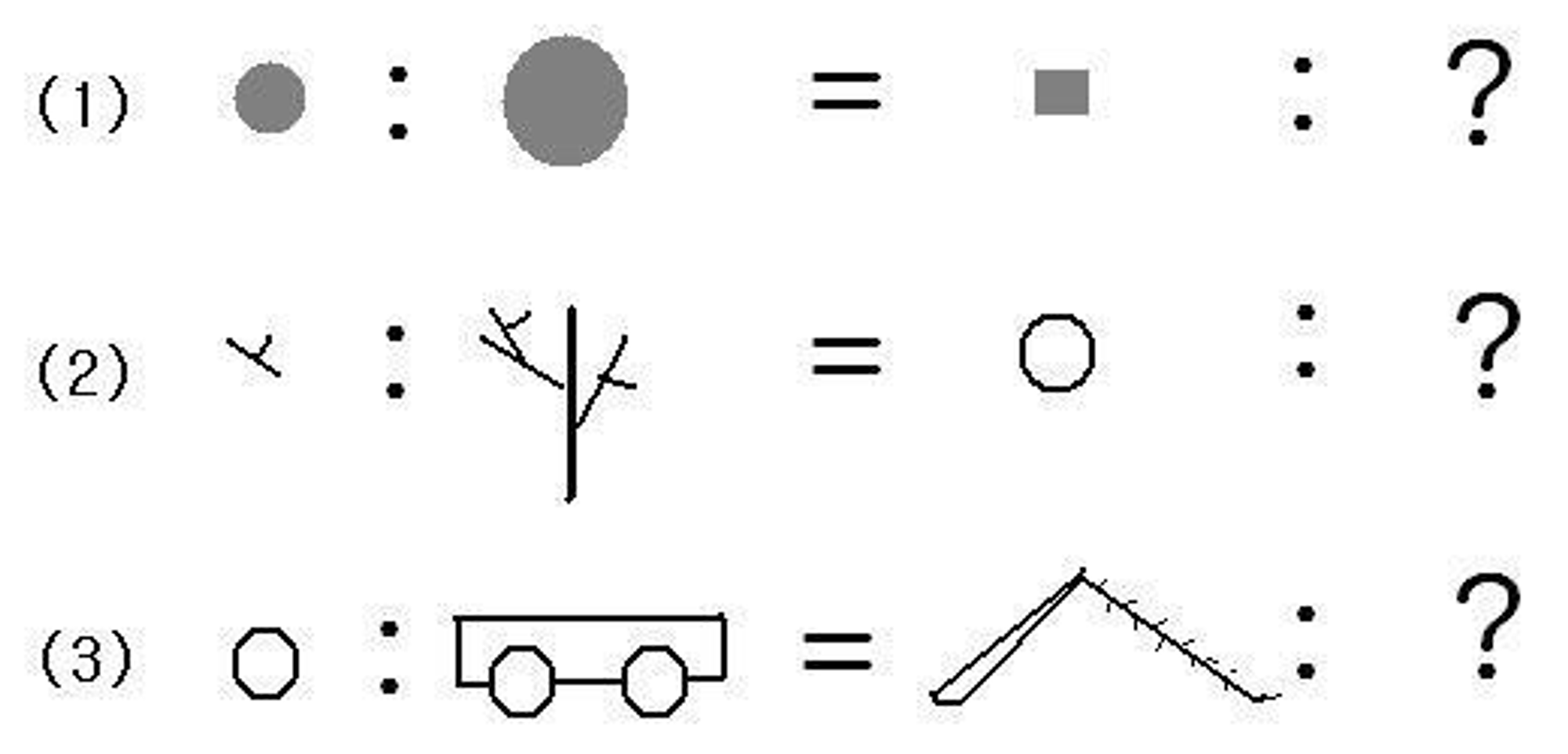 https://gooking.tistory.com/55
https://gooking.tistory.com/55 -
LLM이 직접 유사 문제를 생성하게 하고 문제에 대한 해결책을 찾도록 함
- 인간의 사고 방식과 유사하지만 최근 연구에 따르면 이러한 복합 추론은 아직 부족한 편
Buffer of Thoughts

- 매일 20장씩 팔리는 40위안짜리 셔츠가 있음
- 매출을 늘리기 위해 가격을 낮추기로 결정 -> 1위안 낮출 때마다 2개씩 더 팔림
- 해당 문제는 아래 캡쳐와 같이 이차방정식으로 나타낼 수 있으며 판별식을 통해 해를 구할 수 있음
- 여기서 판별식을 구하는 Thought Template를 사용하여 실제 추론에 인스턴스화시킴으로써 추론
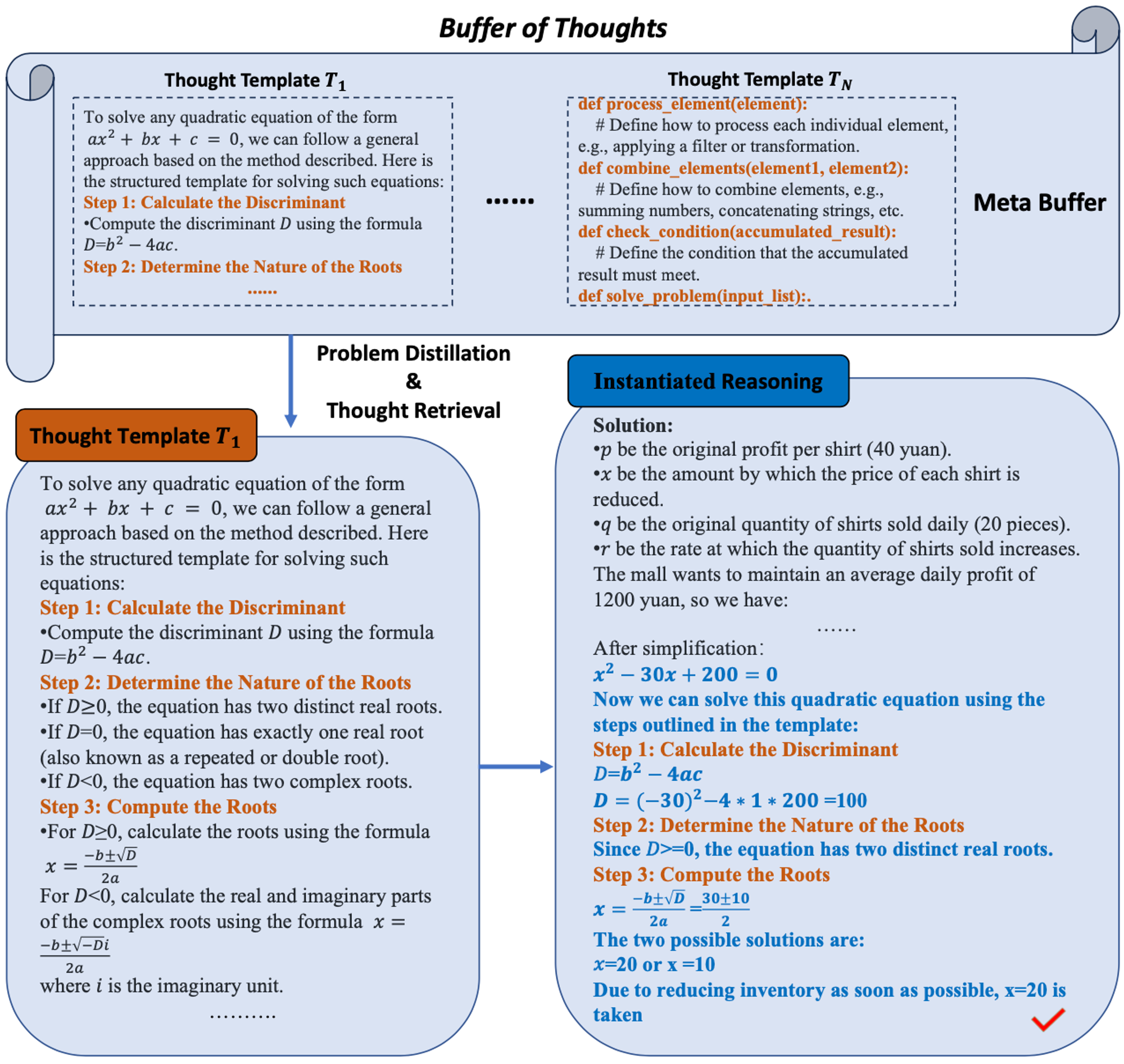
Problem Distiller
- 어떤 문제를 해결하기 위해 LLM은 중요 정보 추출, 잠재적 제약 조건 인식, 정확한 추론 수행 을 거쳐야 함
- 메타 프롬프트 설계 → 태스크 정보를 추출 및 정형화 → (는 입력 문장)

Problem Condensation and Translation
- distiller를 통해 추출된 핵심 요소 → 문제 해결을 위한 필수 파라미터 및 변수 추출 → 명확하고 이해하기 쉬운 형식으로 압축 및 변형
- 복잡한 실제 문제를 좀 더 고차원이면서 간단한 수식으로 분해
Thought-Augmented Reasoning with Meta Buffer
- 인간이 사용하는 문제 해결 사고 방식으로부터 영감을 얻어 상위 수준의 thought-template을 만들고 그것을 저장 및 관리
- buffer-manager를 통해 문제 해결 과정에서 이러한 thought-template를 얻고 meta-buffer에 저장 → 6가지 카테고리로 분류
6가지 카테고리
- 1. Text Comprehension
- 2. Creative Language Generation
- 3. Common Sense Reasoning
- 4. Mathematical Reasoning
- 5. Code Programming
- 6. Application Scheduling





Template Retrieval
- - thought template
- - template description
- - corresponding category
- - text embedding model
- - threshold (0.5~0.7) → 이보다 낮다면 새로운 task로 정의
- - distilled problem
Instantiated Reasoning
-
에 대하여 적절한 가 검색되는 경우 가 포함된 인스턴스화 추론을 통해 구체적으로 표현
- meta-prompt
- You are an expert in problem analysis and can apply previous problem-solving approaches to new issues. The user will provide a specific task description and a thought template. Your goal is to analyze the user's task and generate a specific solution based on the thought template. If the instantiated solution involves Python code, only provide the code and let the compiler handle it. If the solution does not involve code, provide a final answer that is easy to extract from the text.
- - solution of
- meta-prompt
-
적절한 가 검색되지 않는 경우(threshold 이하) 새로운 task로 정의하고 general coarse-grained thought-templates을 사용하여 인스턴스화

Buffer Manager
- 문제 해결 과정에서 얻은 high-level guidelines and thoughts 요약
- meta-buffer에 저장하여 다른 문제에 대한 해결 방식을 일반화할 수 있음
Template Distillation

- Core task summarization : 문제의 기본 유형 분류와 핵심 과제 파악 및 설명
- Solution steps description : 문제 해결을 위한 일반적인 단계 요약 → 문제 정의, 변수, 제약 조건, 해결 전략, 해결 방안 등
- General answering template : 앞 단계의 분석을 바탕으로 유사한 문제에 폭넓게 적용할 수 있는 문제 해결 템플릿 또는 접근 방식을 제안
Dynamic Update of Meta-Buffer
- distilled template을 meta-buffer에 업데이트
- 중복을 막기 위해 유사도 기반으로 필터링하여 동적 업데이트 → meta-buffer의 경량 특성 보장
Experiments
Datasets and Tasks
- https://paperswithcode.com/dataset/game-of-24
- https://github.com/suzgunmirac/BIG-Bench-Hard/tree/main/bbh
- https://github.com/google/BIG-bench/tree/main/bigbench/benchmark_tasks/checkmate_in_one
- https://github.com/google/BIG-bench/tree/main/bigbench/benchmark_tasks/date_understanding
- https://github.com/microsoft/PythonProgrammingPuzzles
- https://paperswithcode.com/dataset/mgsm

Implementation and Baselines
- GPT-4, Llama3-8B and Llama3-70B
- Standard Prompting
- Single-query Method
- Expert Prompting
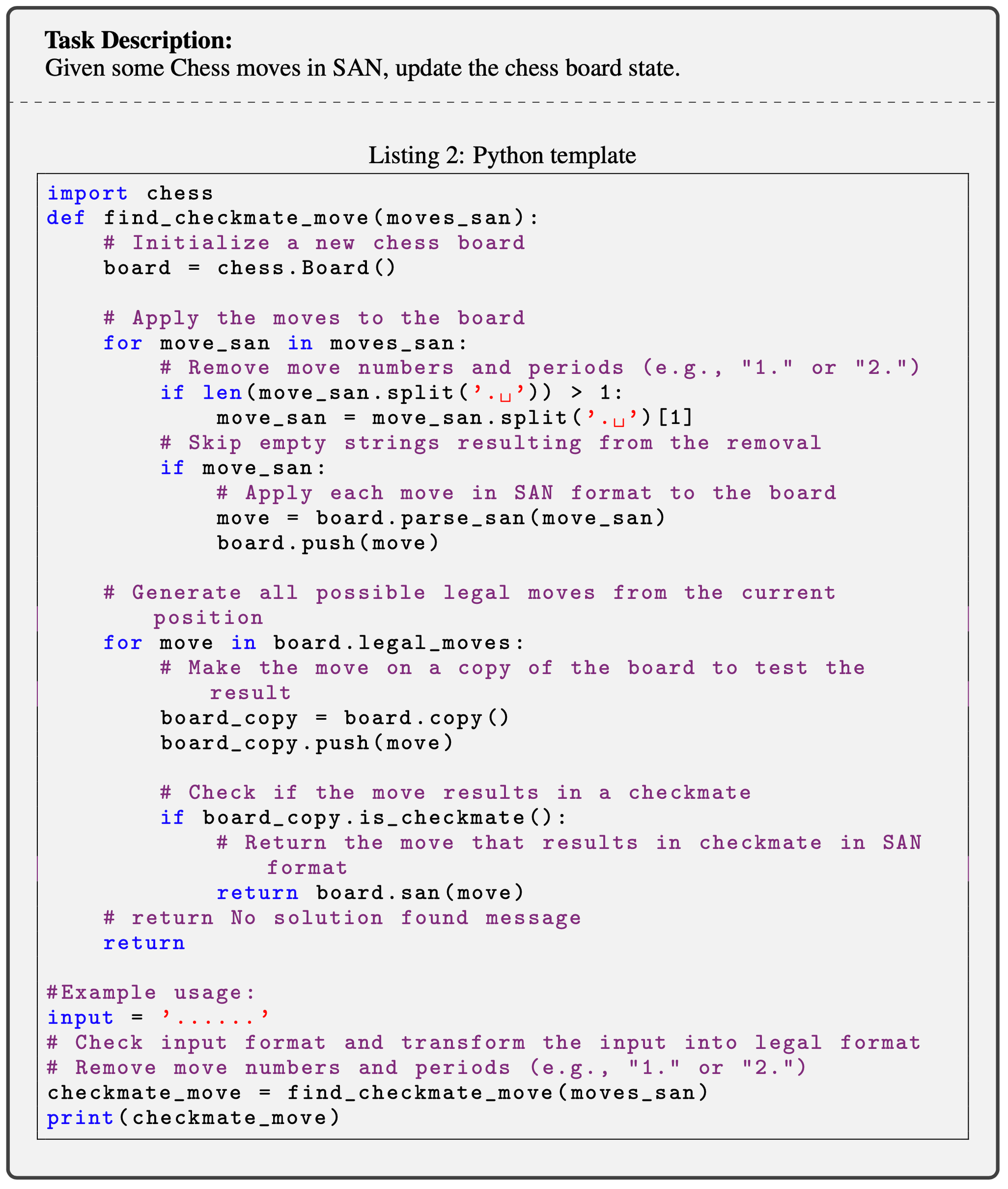
- 주어진 Instruction과 In-Context Demonstration을 가지고 LLM을 이용해 Expert Identity를 생성하고 그것을 본래 Instruction에 다시 덧붙여 증강 생성하는 방식으로 보임 (나중에 읽어봐야겠네요)
- 주어진 Instruction과 In-Context Demonstration을 가지고 LLM을 이용해 Expert Identity를 생성하고 그것을 본래 Instruction에 다시 덧붙여 증강 생성하는 방식으로 보임 (나중에 읽어봐야겠네요)
- PAL
- 코드 작성과 같이 변수에 미리 sub-task 결과를 할당하고 변수들을 활용해 문제 해결을 하는 방식 : 동일한 쿼리에 대해 기존 CoT보다 추론을 더 잘하는 것으로 보임 (이것도 나중에 읽어봐야 할 듯)

- 코드 작성과 같이 변수에 미리 sub-task 결과를 할당하고 변수들을 활용해 문제 해결을 하는 방식 : 동일한 쿼리에 대해 기존 CoT보다 추론을 더 잘하는 것으로 보임 (이것도 나중에 읽어봐야 할 듯)
- Multi-query Method
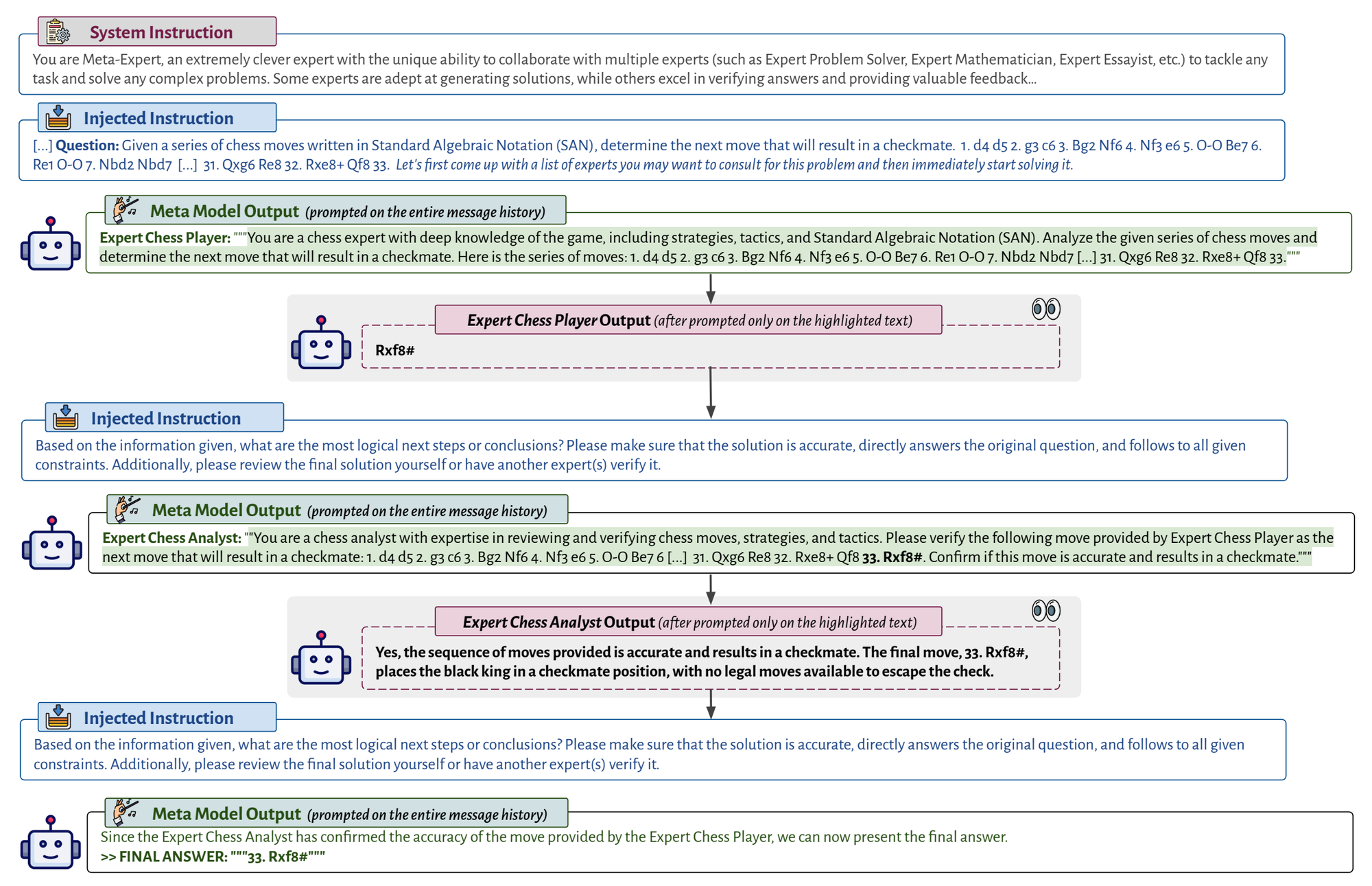
BoT Achieves Better Accuracy, Efficiency and Robustness
Reasoning Accuracy
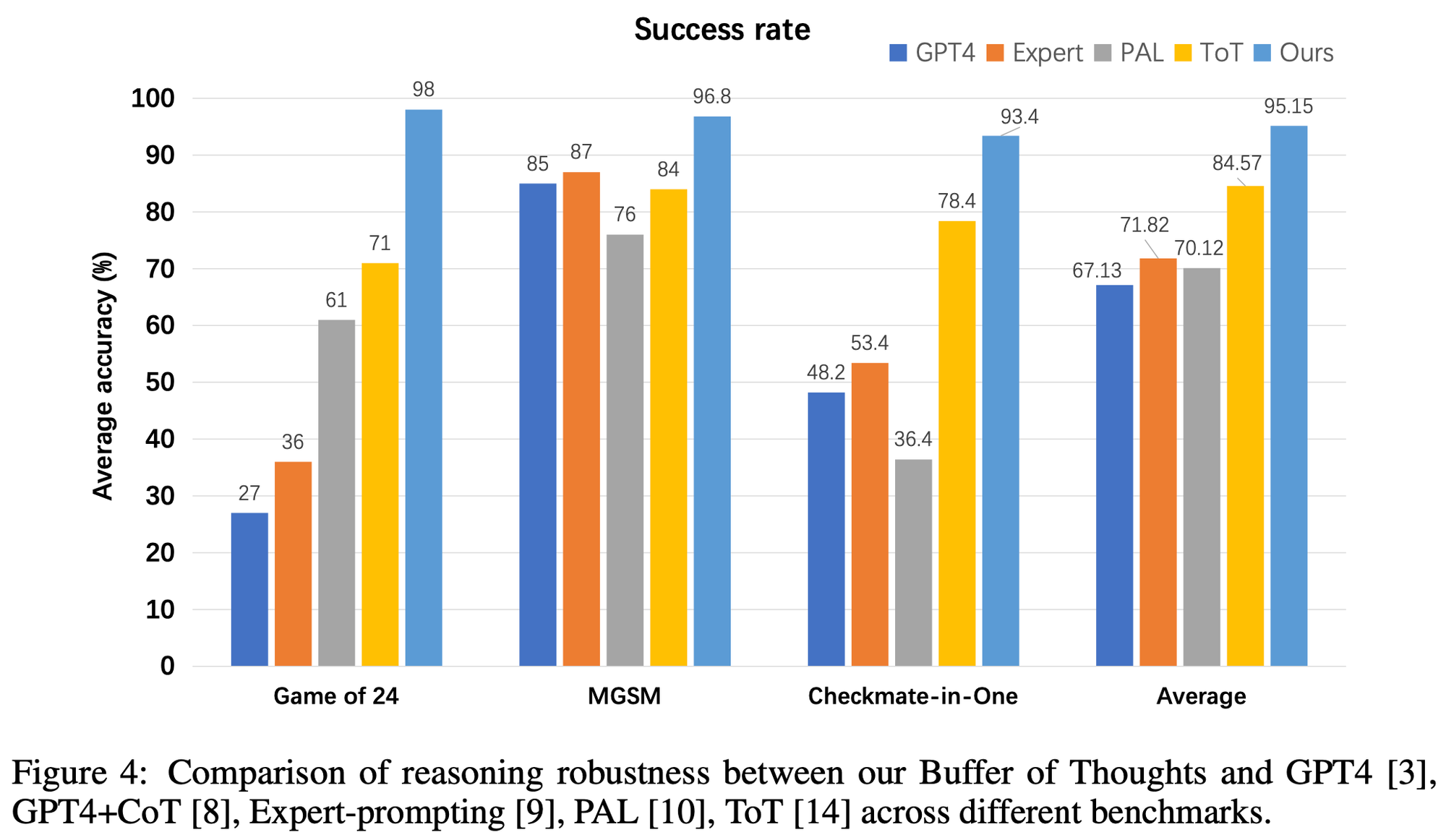
- significant accuracy improvements: 23% on Game of 24, 20% on Geometric Shapes and 51% on Checkmate-in-One
Reasoning Efficiency
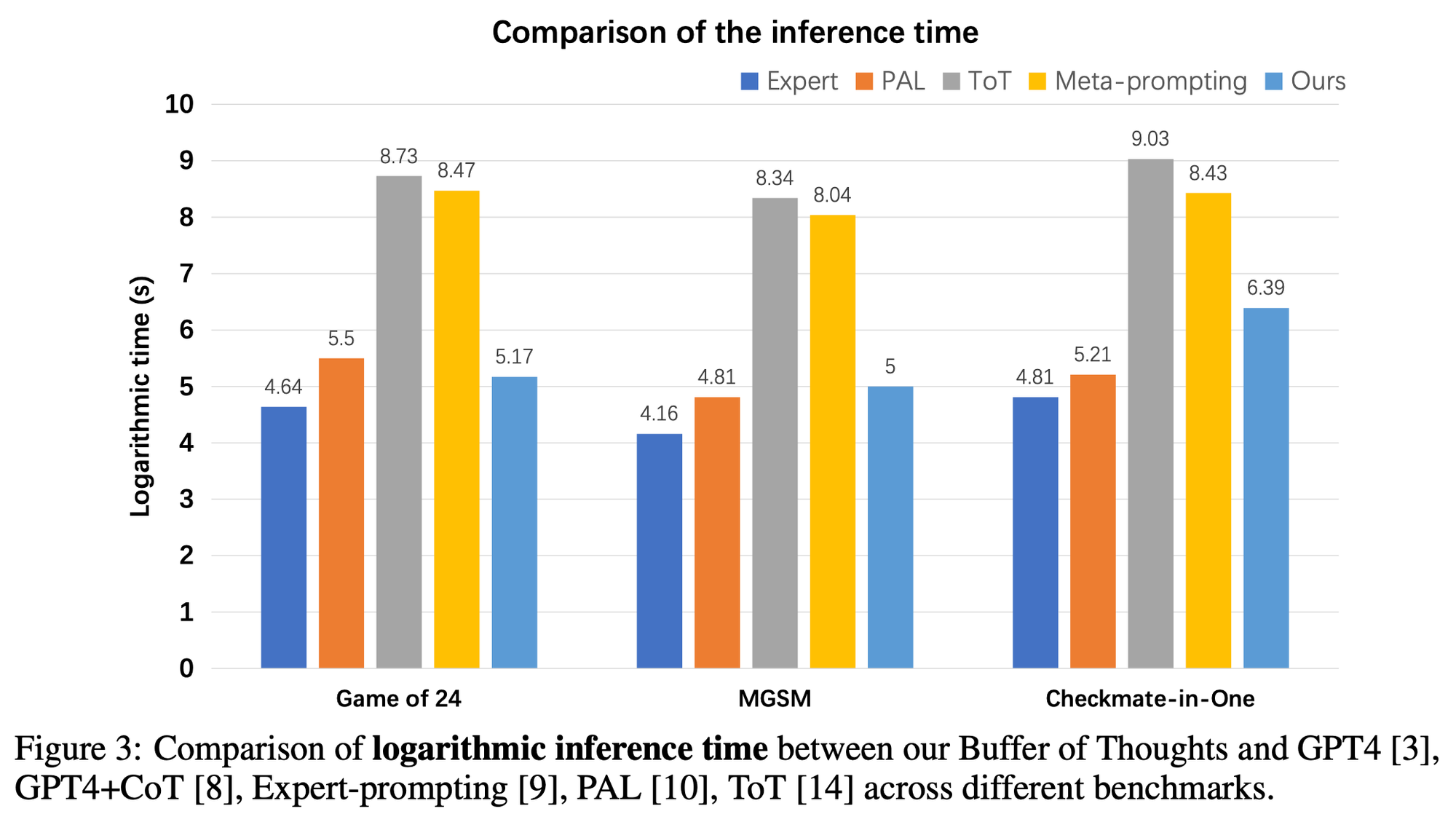
- BoT requires only 12% of the cost of multi-query methods
- single-query 방식과 비슷 / multi-query 방식보다 더 빠름
Reasoning Robustness
- success rate, which is used to assess the reasoning robustness
- randomly sample 1000 examples from various benchmarks as a test subset and evaluate different methods on this subset
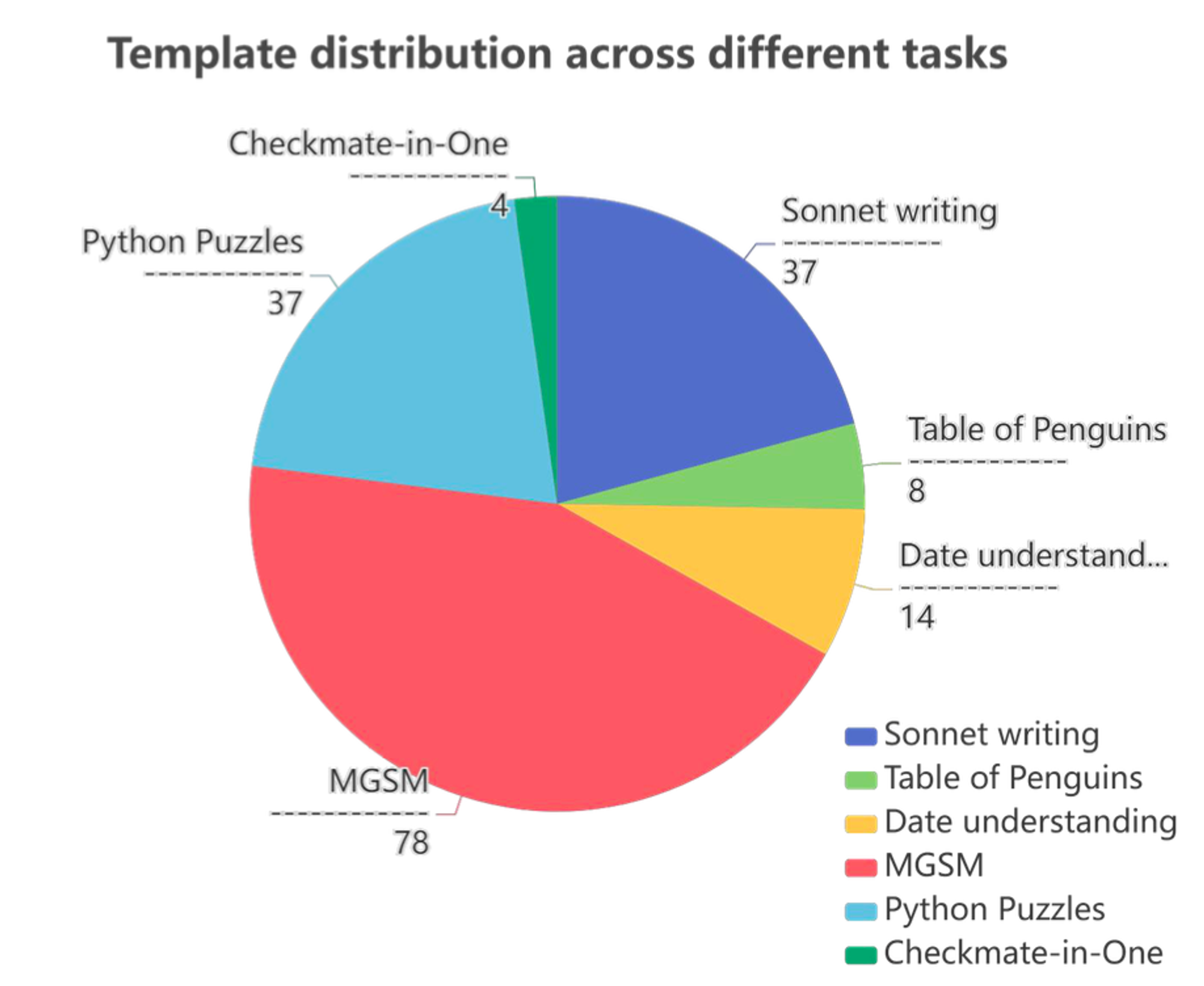
Model Analysis
Distribution Analysis of Thought-Templates
- 생성된 thought-template의 분포
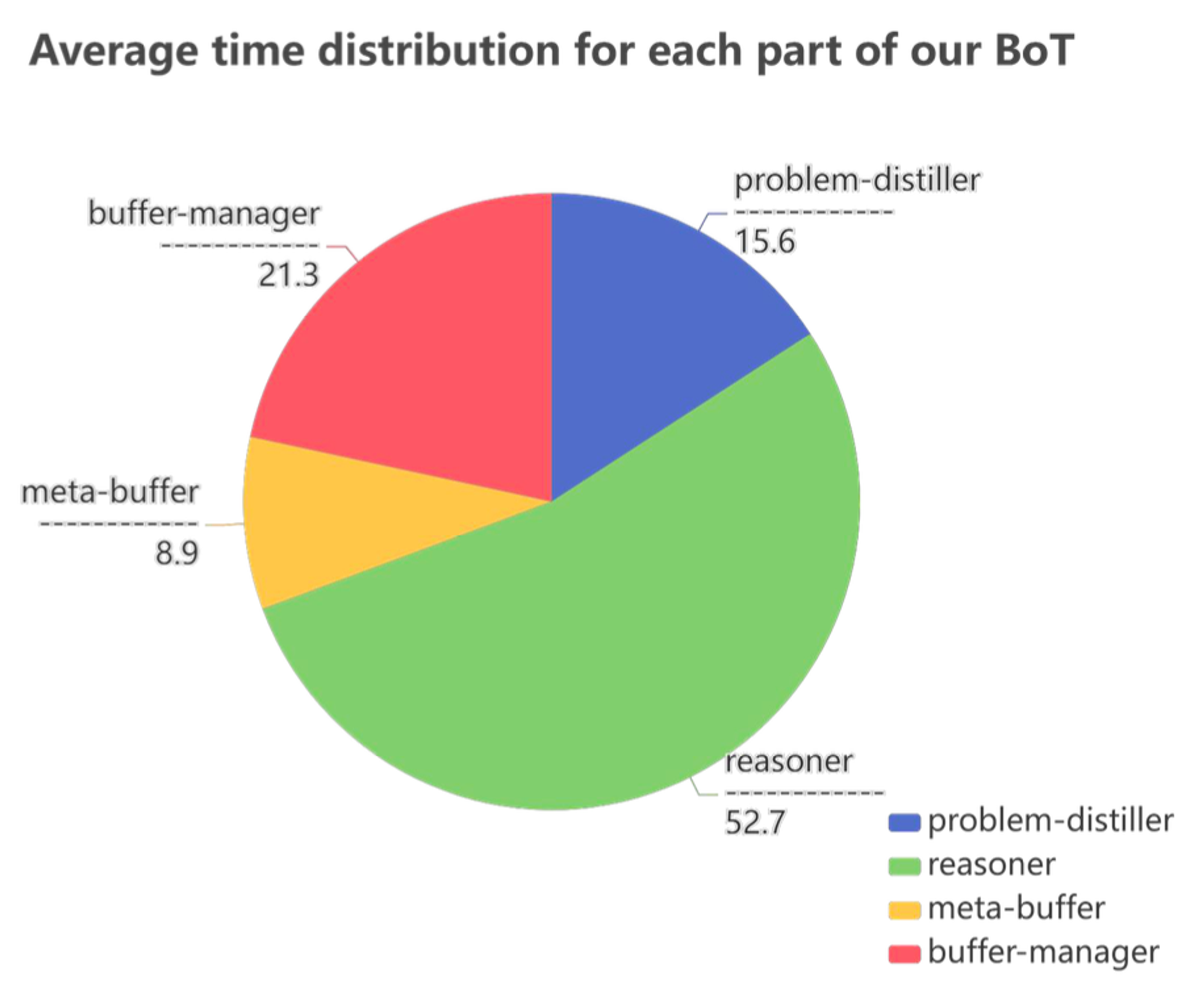
Distribution Analysis of Time Cost
- BoT의 각 파트 별로 경과한 평균 시간 분포
- 인스턴스화 시간이 오래 걸림
Better Trade-off between Model Size and Performance
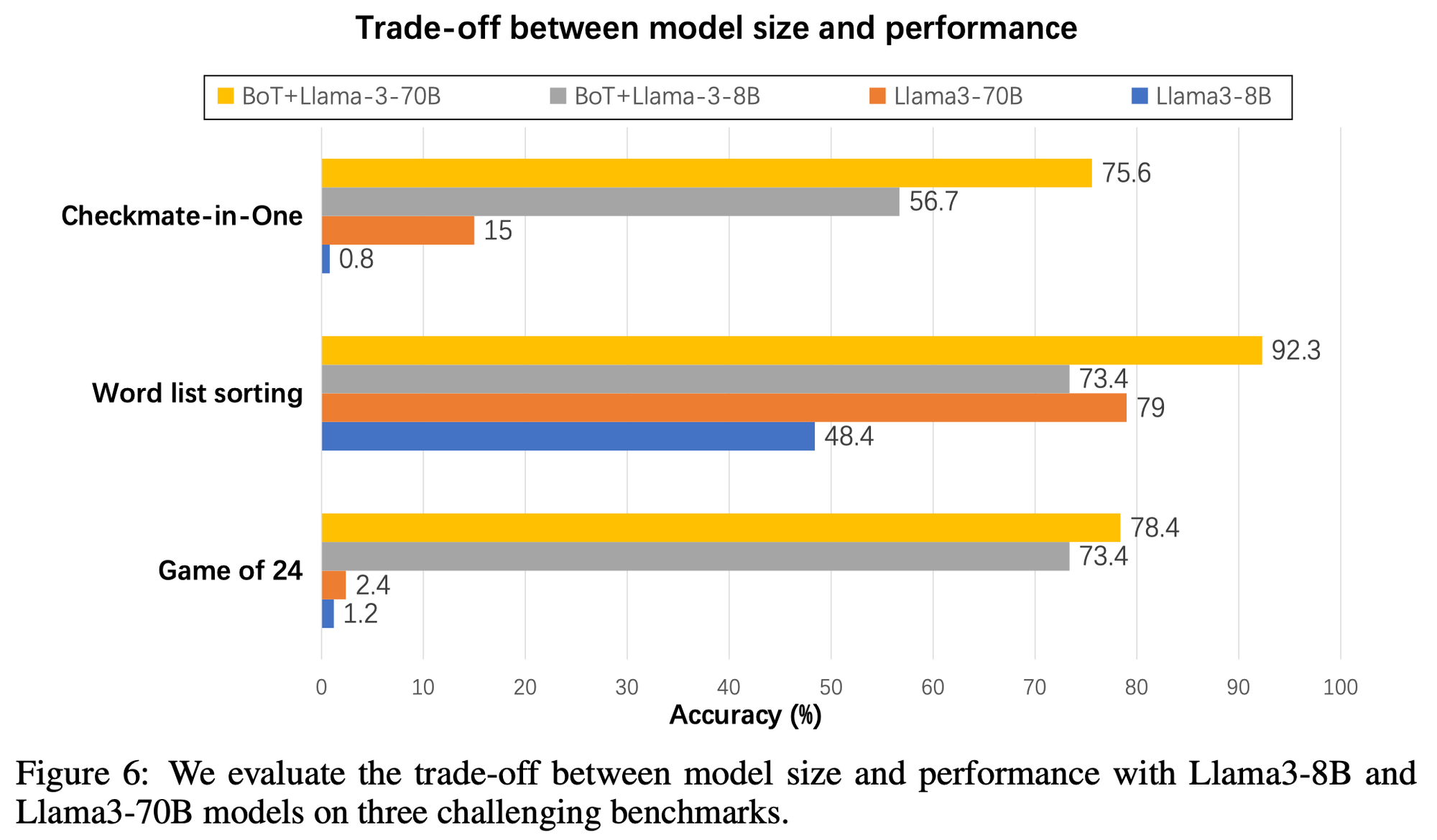
Ablation Study
Impact of Problem-Distiller
- task가 복잡해질수록 problem-distiller의 역할이 더 두드러짐
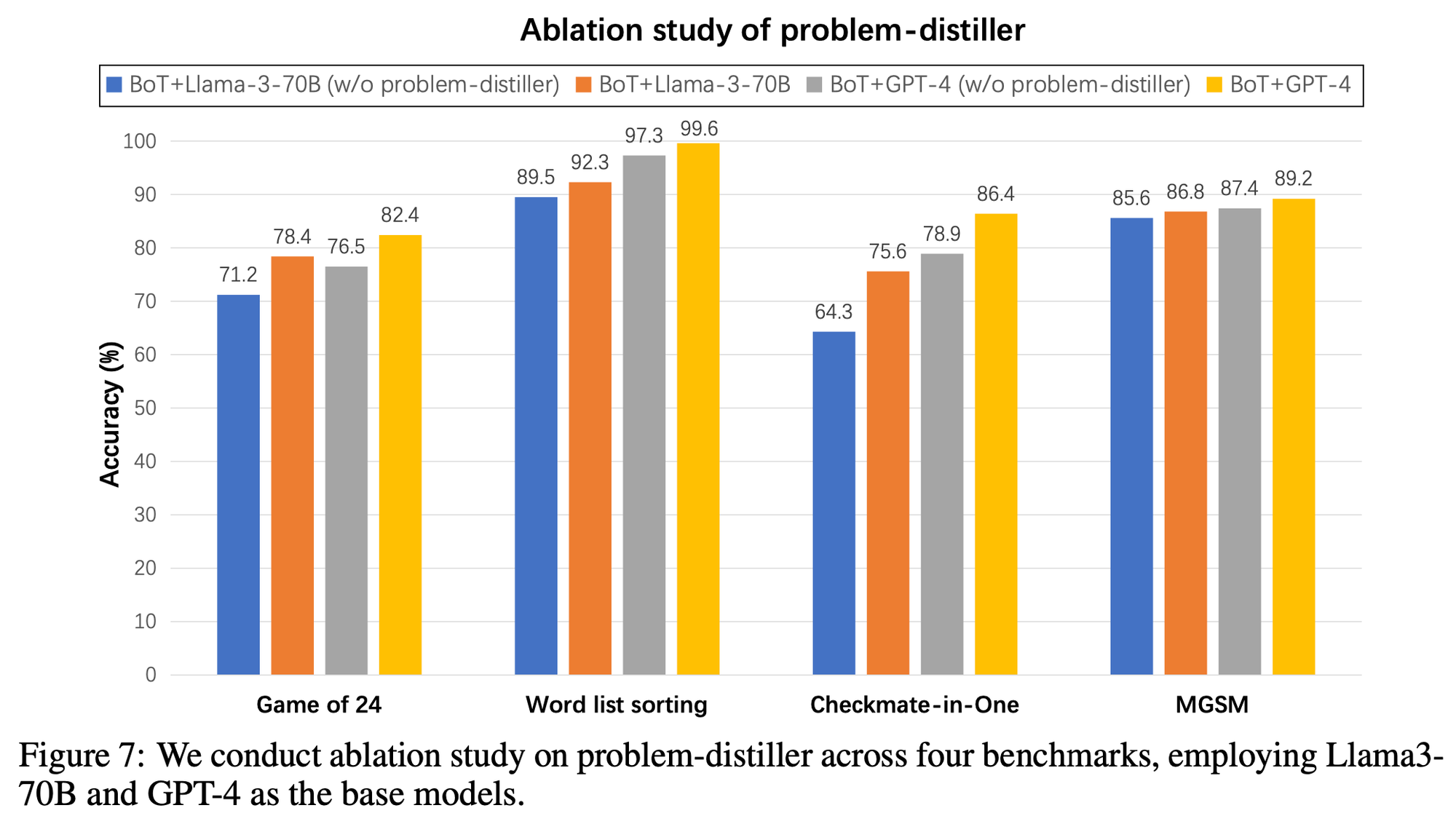
###Impact of Meta-Buffer
- meta-buffer가 있고 없고의 차이(thought-template)
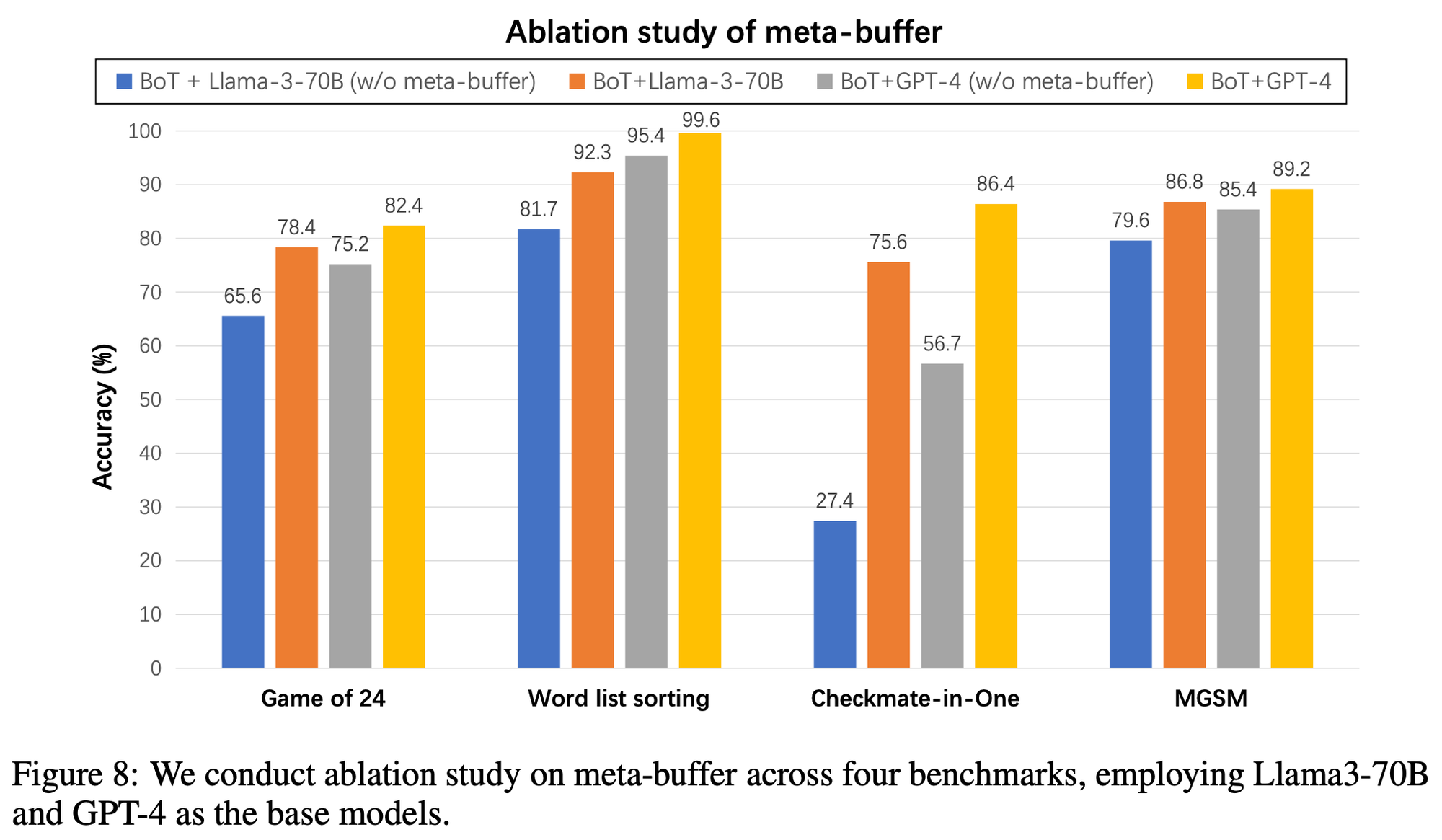
Impact of Buffer-Manager
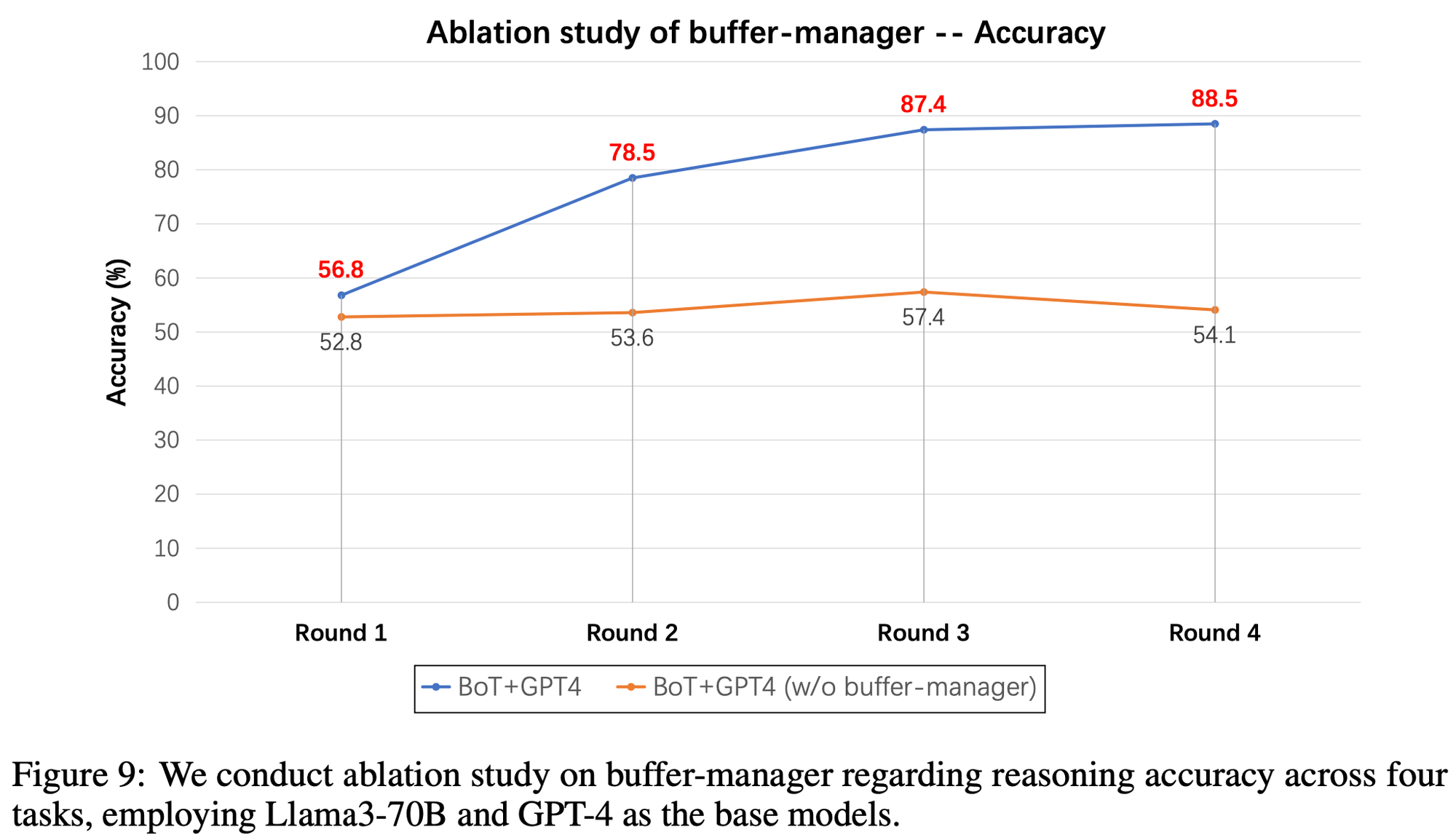
- 각 라운드마다 각 벤치마크 별 50개 문제를 샘플링
- 이후 라운드마다 50개씩 더 샘플링
- buffer-manager를 통해 thought-template이 풍부해질수록 성능이 올라가는 것을 확인
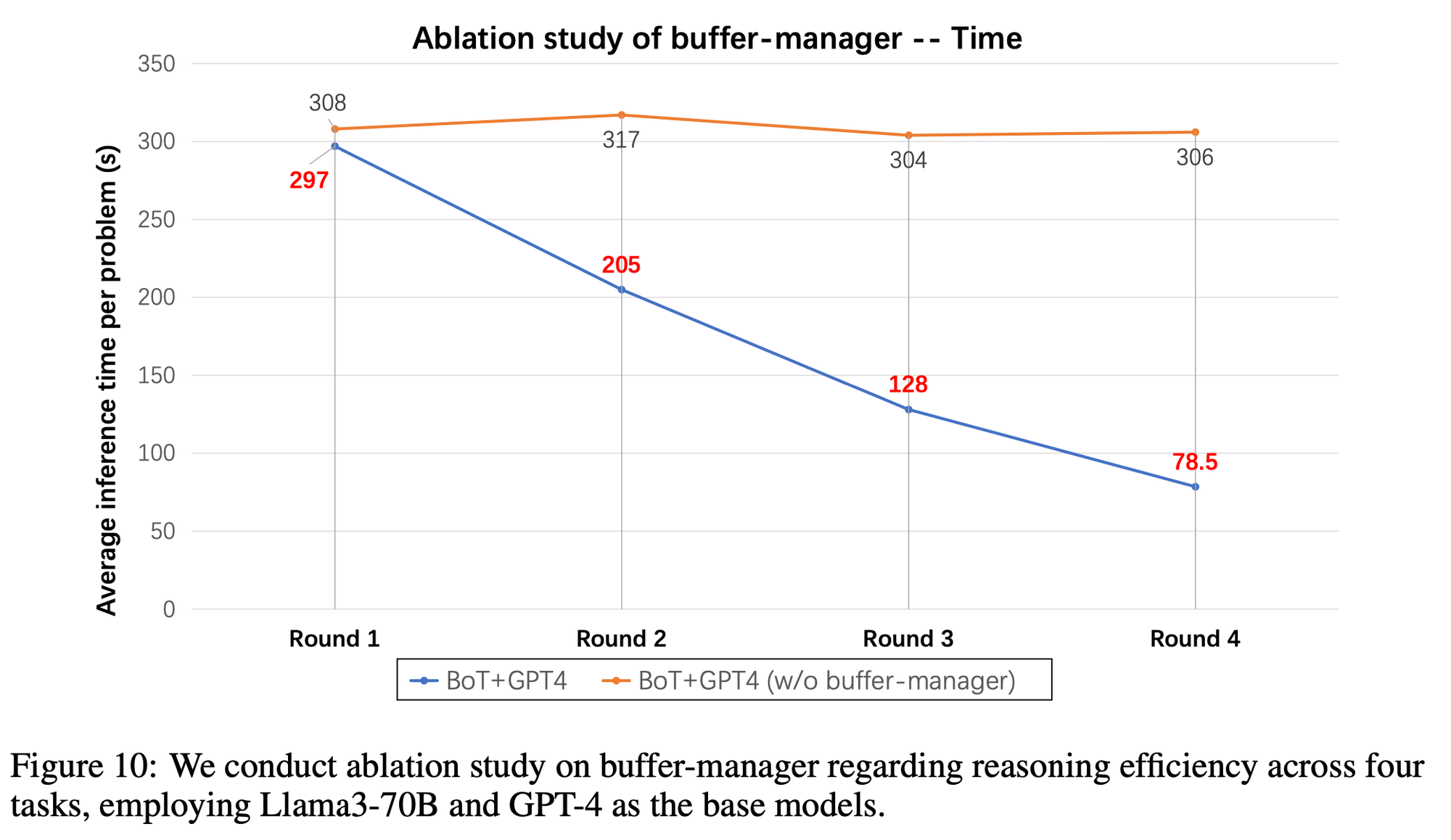
- 추론 시간의 경우에도 유의미한 차이를 보임
Discussion
- 창의성이 필요한 문제에서 제약이 좀 있음
- 사용 모델에 따라 meta-buffer 초기화 성능이 낮아질 수 있음 → 최선의 thought-template이 생성되지 않을 수도, 선택되지 않을 수도 있음
- 외부 리소스 통합의 여지가 있음
- thought-template distillation 최적화를 통해 더 복잡한 문제에 대한 template의 품질을 향상시킬 수 있음

일단 합니다
잘 읽고 갑니다 ~