OLAP cube
일반적인 데이터를 가지고 있는 것은 의미가 없습니다. 왜냐면 여기에는 필요하지 않은 정보들도 있을 수 있기 때문입니다. 이 정보들을 추리기 위해 백엔드 개발자 혹은 데이터 분석가들은 카테고리(열)별로 분리해야 합니다.
분리된 데이터를 가지고 원하는 데이터를 조합하여 원하는 값을 도출할 수 있습니다.
1차원 큐브
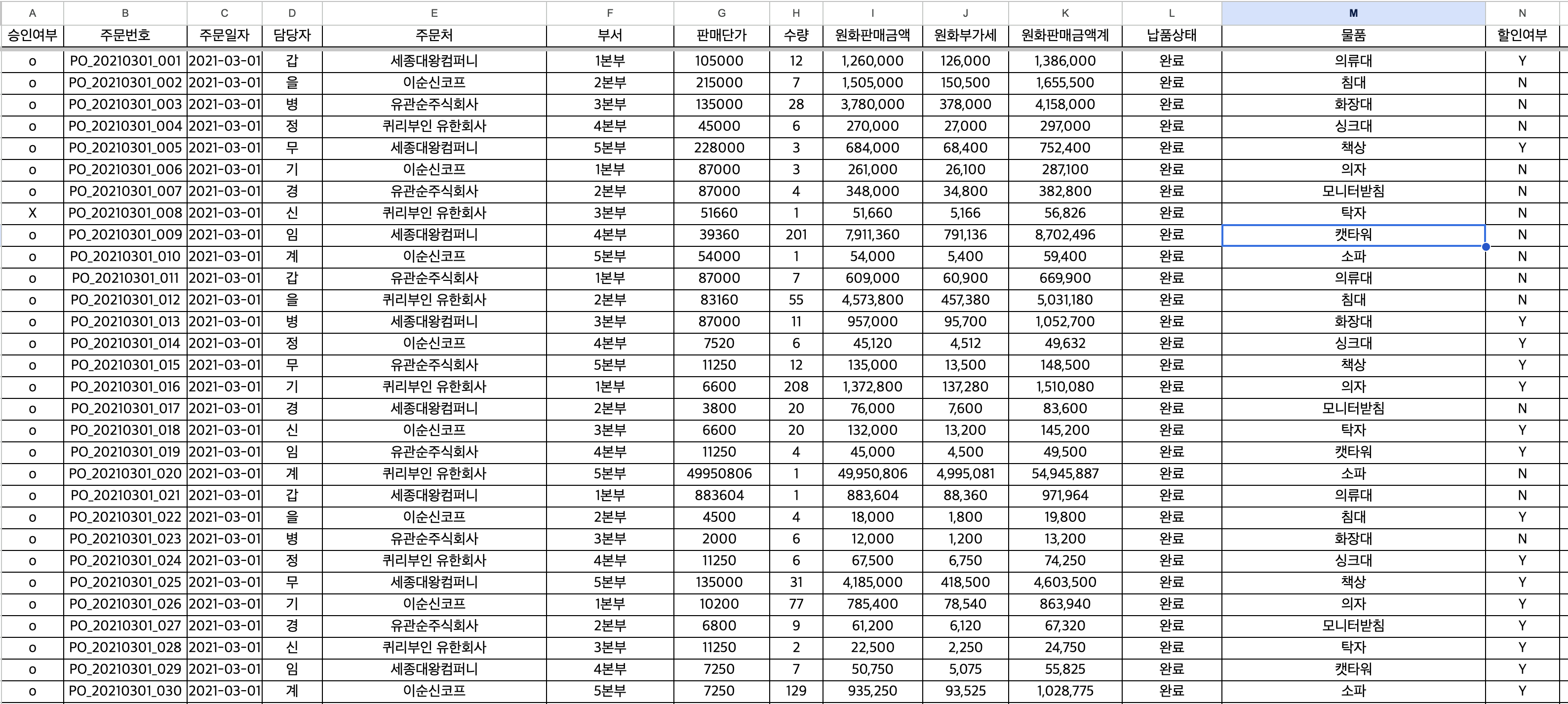
1차원 큐브는 row data의 '열' 부분입니다.
관계가 있는 데이터끼리 열로 차원을 분리(정규화작업)하여 큐브의 측면을 담당하게 할 수 있습니다.
2차원 큐브
2차원 큐브는 1차원 큐브가 2개가 합쳐진 형태입니다.
SQL로 생각하면 두 개의 테이블을 join하는 형태가 되겠네요. 엑셀로 확인할 경우 다음과 같습니다.
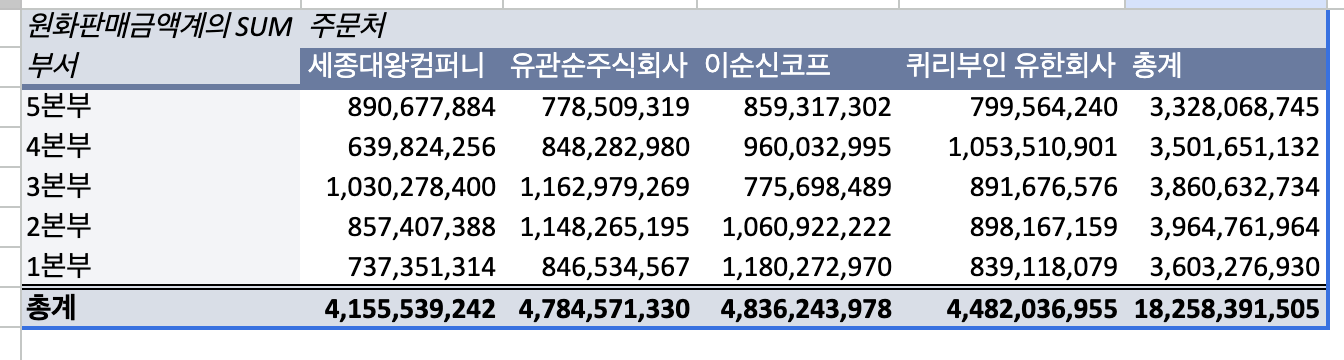
3차원 큐브
3차원 큐브는 1차원 큐브가 3개가 모여 데이터를 형성합니다.
SQL로 생각하면 세 개의 테이블을 join하는 형태가 되겠군요.

부서별 담당자와, 담당자가 판매한 판매금액을 볼 수 있습니다.
어..? 카테고리 별로 분리하여 조합하니 새로운 데이터를 확인 할 수 있습니다.
보너스를 받으실분이 보이는군요
n차원 큐브
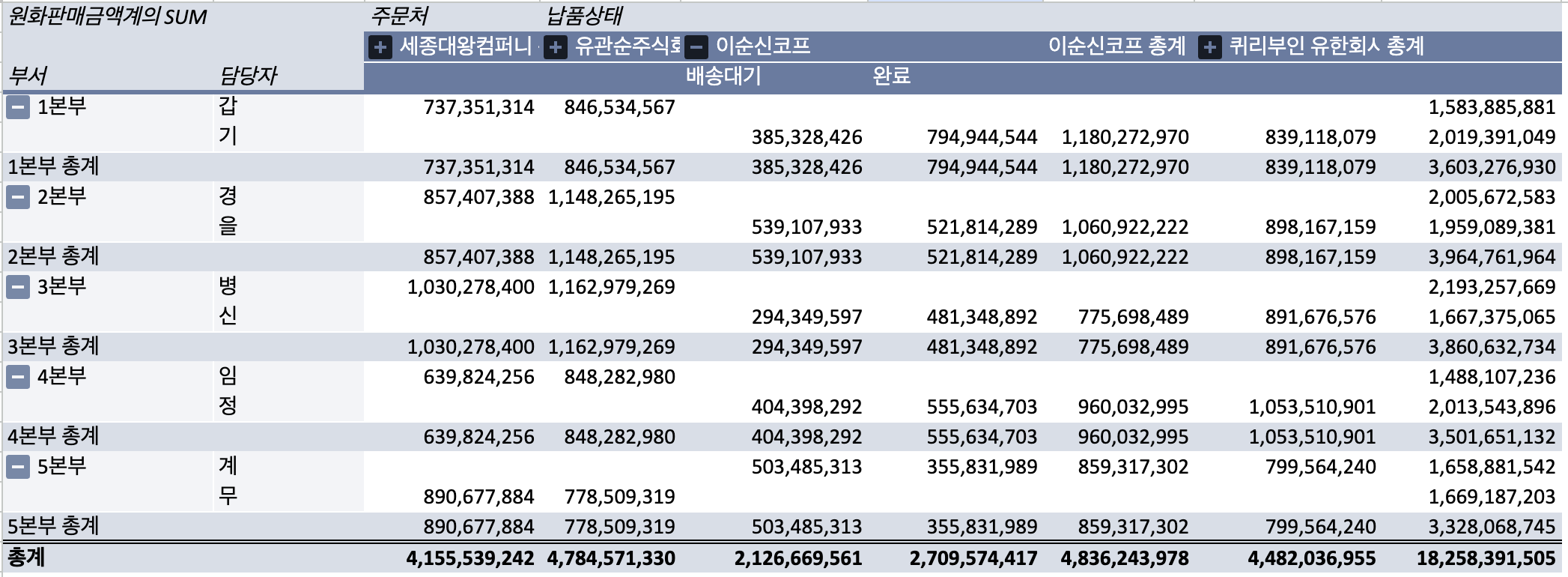
부서와, 담당자, 주문처, 납품상태 4가지의 1차원데이터를 한곳으로 모아 데이터를 구성하였습니다.
n차원이라는 이름에 맞게, 1차원 데이터을 추가하여 계속하여 큐브를 구성할 수 있습니다.
근데 왜 이런 형태를 큐브라 하는거지?
3차원 큐브를 그림으로 그려보았습니다.
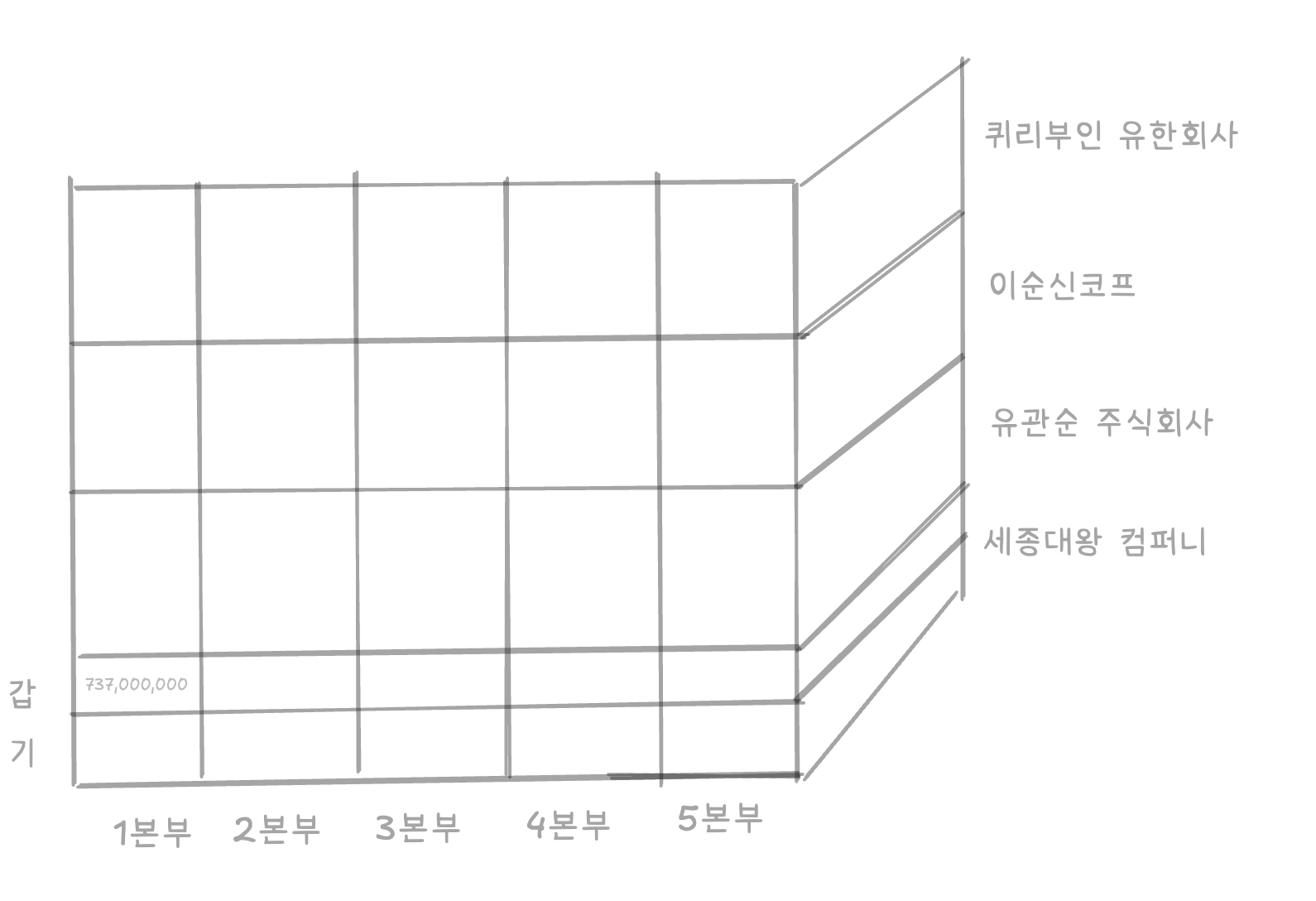
큐브로 시각화를 하니 1본부의 담당자 갑씨가 세종대왕 컴퍼니에 약 7억3천7백만원를 판매한걸 바로 확인할 수 있었습니다.
cube의 뜻은 정육면체 입니다. 3개의 차원을 하나로 합칠 경우, 처음으로 현실에 있는 정육면체의 형태가 나타나 큐브라고 이름지은것 같습니다.
그런데 나는 데이터를 다뤄야 하는 개발자인데..?
엑셀로 n년치 데이터를 언제 분석 언제하지..?
그런 분들을 위해 무료 오픈소스인 duckdb를 비롯한 제품들이 있습니다. 직접은 못해보고, 해당 작업이 어떻게 진행되는지 알아보겠습니다.
차원분리(Dimension) 모델링
예제 데이터에서는 테이블에 많은 정보가 혼합되어 있습니다.

Dimension
비정규화는 모든것이 단일 행에 저장된다는 것을 말합니다. 예시 데이터처럼 직원과 납품처, 배송 물품이 섞여있고 중복된 데이터들이 발생하고 있는 상태입니다.
만약, 주문처의 주문 물품이 바뀐다면, 주문 수량이 바뀐다면, 데이터베이스에서 하나 하나 정보를 찾은 뒤 업데이트 쿼리를 실행해야 합니다.
무엇보다 OLAP는 쓰기 보다는 읽는 작업에 우선순위를 두고 대용량 데이터를 기반으로 복잡한 쿼리를 빠르게 실행해야 합니다.
그러므로, 데이터의 중복을 피하기 위해 차원분리 작업을 해야 합니다. (데이터베이스 정규화 작업과도 일치합니다.)
정규화
데이터베이스의 정규화는 1,2,3차 정규화로 구분됩니다.
- 1 정규화 : 하나의 필드에는 하나의 값만이 존재하도록 변경합니다.
- 2 정규화 : 개념이 비슷한 항목들을 모아 별도의 테이블로 분리합니다.
- 3 정규화 : 2 정규화로 분리된 테이블에서 종속성이 있는 테이블을 분리합니다.
정규화의 목적
정규화의 목적은 데이터의 중복을 최대한 막으면서 데이터의 무결성을 지키기 위함입니다.
데이터의 중복을 최소화 할 수 있기에 저장공간을 효율적으로 사용이 가능합니다.
데이터의 무결성이 유지됩니다.
테이블에는 지정된 데이터만 입력,수정,삭제가 가능합니다. 따라서 데이터의 구조가 안정적입니다. (NoSQL이라고 불안정한것은 아닙니다.)
무결성
저장된 데이터의 값이 정확한 상태를 유지하는 것을 의미합니다. 제약조건을 통해 보장하며 여러 무결성 조건으로 상태를 유지합니다.
무결성 조건
- 엔티티 무결성 : 행으로 데이터를 구분합니다. PK를 이용하여 데이터가 중복되더라도 바로 수정할 수 있습니다.
- 도메인 무결성 : 열을 이용해 적용됩니다. 열의 값을 입력받아 데이터 형식이나 유형을 확인합니다.
- 참조 무결성 : A테이블이 B테이블을 참조 하는 제약입니다. 이때 A테이블에서는 B테이블에 없는 값을 참조하면 오류가 납니다.
- 사용자 정의 무결성: 사용자가 특수한 방식으로 데이터 무결성을 유지하기 위해 생성하는 제약입니다.
돌아와서 예제는 이정도로 분리하면 좋을 것 같습니다.

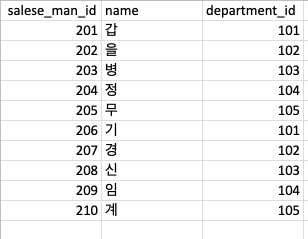
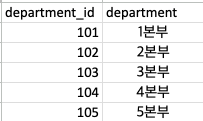
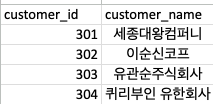
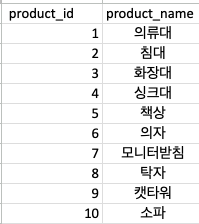

상위 5개의 데이터를 차원분리후 다시 만들어 보면

이런식으로 다른 테이블을 참조하면서 보기가 깔끔해졌습니다.
이런 테이블을 fact table이라 합니다.
팩트 테이블을 중심에 놓고 참조되는 테이블을 펼칠 수 있습니다.
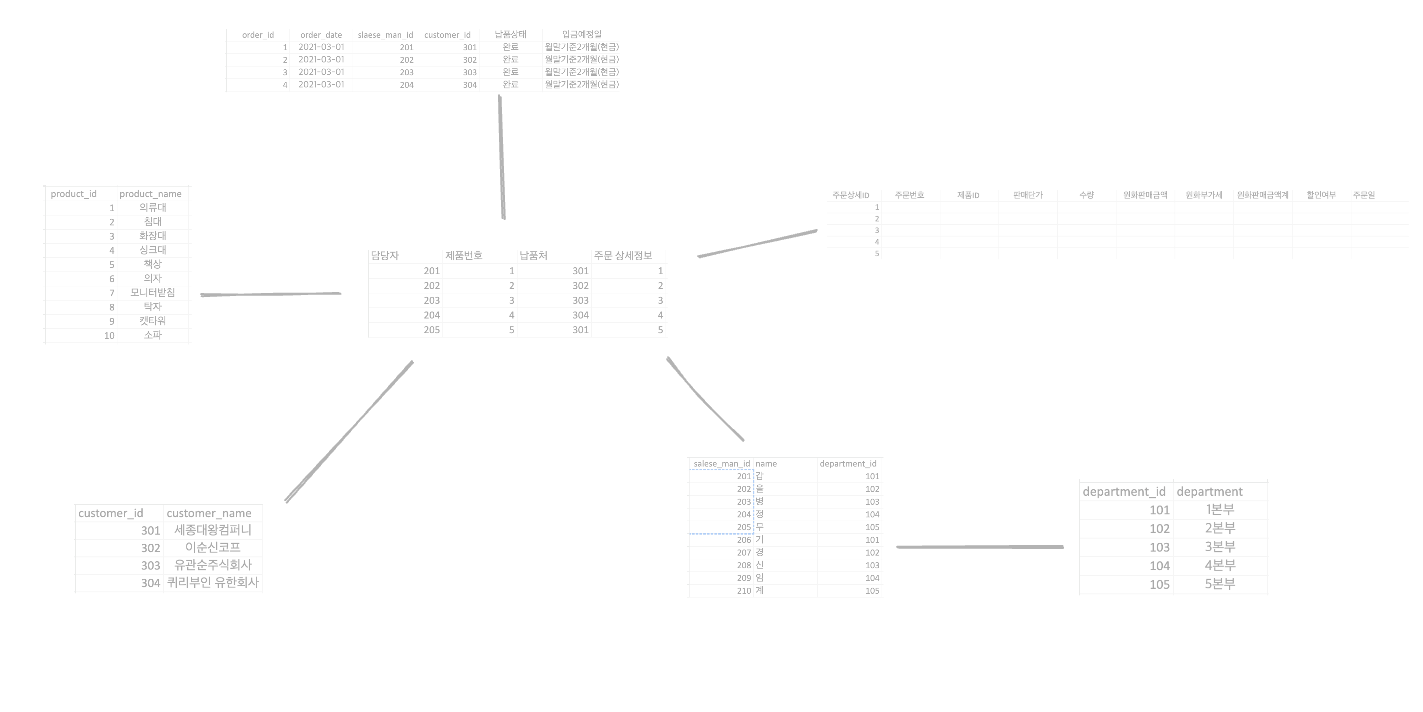
본부에 해당하는 테이블이 없다면 완벽한 star schema 형태라고 하겠지만, 제가 생각하기에는 showflake schema로 생각됩니다.
왜 star 혹은 snowflake일까?
사실 이리저리 배치해보면서 다른 모양이 나오는지 알고싶었습니다. 그럴경우 스키마가 한눈에 들어오지 않았습니다...
SQL 쿼리 작성
간단하게 부서 아이디가 101인 담당자를 찾는 query문을 이용하여 만들었습니다.

오늘은 엑셀을 이용하여 데이터를 분석하는 방법을 살펴보았습니다.
하지만 엑셀이 익숙하지 않으실 경우 시각화툴을 이용하여 쉽게 만드실수 있습니다.
데이터 출처 : [직장인을 위한 실전엑셀 - 61] 엑셀 피벗테이블(Pivot) 사용법 (1) 피벗테이블 설명
The beginner's guide to OLAP modeling and modeling concepts
What is STAR schema | Star vs Snowflake Schema | Fact vs Dimension Table
SQL강좌:6-1. 데이터 무결성 - 데이터 무결성 이해
