airflow
- python 코드를 사용하며 워크플로우를 만들 수 있는 플랫폼입니다.
- 주로 ETL(데이터를 추출, 가공, 다른 DB 저장)할때 사용됩니다.
- 각 작업들은 DAG로 어떤 작업인지 정의하며, 작업마다 실행순서를 설정할 수 있어 유연하면서도 pipeline을 쉽게 만들 수 있습니다.
왜 전략을 설정해야 될까?
처음 만들어본 hello world를 출력하는 파이프라인 입니다.
간단하고 순서가 바뀌어도 상관이 없어도 괜찮습니다.
직접 triger를 실행해봐도 모두 성공 상태로 나오고 있습니다.
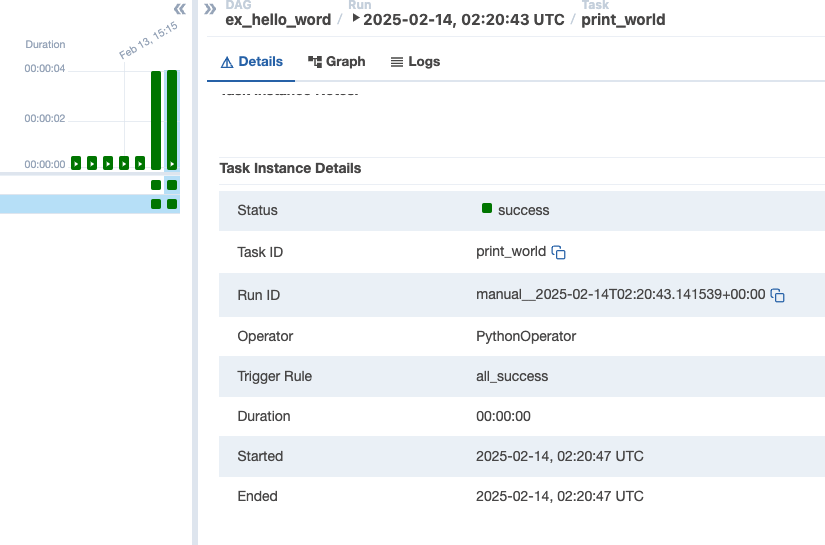
이런 간단한 파이프라인은 전략적으로 고려할 요소가 없어 보입니다.
airflow dag 예제중 하나입니다.
너무나 많은 분기들이 있고 이중 하나라도 실패할 경우에는 어떻게 될까요??
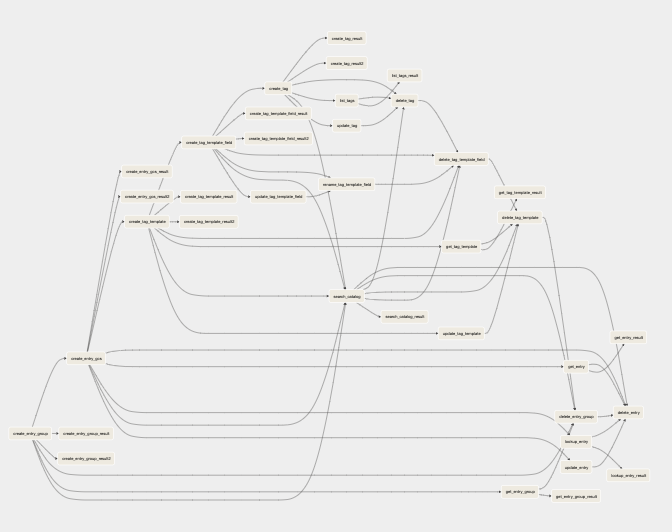
실패된 데이터는 어떻게 되는거지?
pipeline을 통과하지 못한 데이터는 어떻게 되는거지?
➡️ 실패한 task에서 데이터를 어디까지 처리했는지에 따라 달라집니다.
- dw등 다른 데이터베이스에 저장하는 task가 실패하더라도 원본은 남아있습니다.
- 데이터를 이동하는 task가 실패했다면, 일부만 옮겨졌을 가능성이 있습니다.
통과 하지 못한 데이터는 멱등성이 유지되는건가?
➡️ 멱등성이 보장되는 airflow를 만들면 됩니다! 버즈빌 데이터 엔지니터 팀은 delete 로직을 앞에 넣어주어 과거 데이터를 초기화시켜 주는 작업을 하였습니다
그러면 일반 airflow는 멱등성을 유지하지 못한다는건가요???????????
➡️ 파이프 라인 작성시 장애가 발생할때 재실행을 통회 쉽게 복구하도록 하면 됩니다.
데이터는 닥터후 오프닝에 타디스가 회전하면서 떠다니는 것처럼 파이프라인에 둥둥 떠있는건가?
➡️ 일정시간 재시도를 시도 후 실행이 안되면 대기 상태가 됩니다.
그럼 그 다음에 오는 데이터는 어떻게 되는거지? 실패한 데이터를 밀치고오나?
➡️ airflow를 병렬처리 하면 되지 않을까요??
retries 설정
airflow는 default_args에 자동 재시작을 설정할 수 있습니다.
default_args={
"retries": 3, // 재시작 횟수 3번
"retry_delay": duration(seconds=2), //2초후 재시도
"retry_exponential_backoff": True,
"max_retry_delay": duration(hours=2), //최대 2시간동안
},Catch Up 설정
catch up 은 마지막으로 실행된 task부터 실행할 수 있도록 하는 개념입니다. spring batch에서 각 작업별로 batch를 실행하던 중 갑작스럽게 중단될 경우, 마지막으로 실행된 batch에서부터 다시 실행되는 것과 같은 개념인거 같습니다.
default_args={
"retries": 3, // 재시작 횟수 3번
"retry_delay": duration(seconds=2), //2초후 재시도
"retry_exponential_backoff": True,
"max_retry_delay": duration(hours=2), //최대 2시간동안
"catchup"=True,
},airflow를 효과적으로 작성하는 방법들
scheduler는 dag를 어떻게 인식하나
아주 간단한 pipeline을 만들고 나서 scheulder에 dag파일을 인식시키는 작업이 있었습니다.
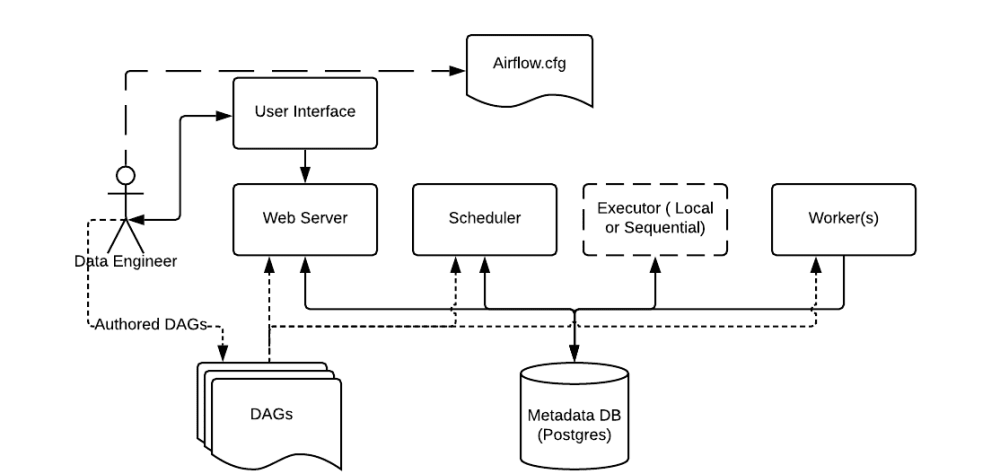
scheduler는 모든 DAG와 Task에 대하여 모니터링 및 관리하고, 실행해야할 Task를 스케줄링을 해주고 있습니다.
DAG파일 파싱 과정

공식문서에 따르면 DAG 파일 처리는 DAG 폴더에 포함된 파이썬 파일을 스케줄링할 작업을 포함하는 DAG 객체로 변환하는 과정을 의미합니다.
Deep into Airflow: DAG Processing WEI HAO님이 Medium에 작성하신 DAG Processing을 읽고 설명이 가능한 수준까지 이해하려 하고 있습니다.
retry와 상관없이 특정 시간 이후 task fail시키기
Airflow DAG 및 작업 다시 실행
멱등성이 보장되는 airflow 로직 만들기 !
