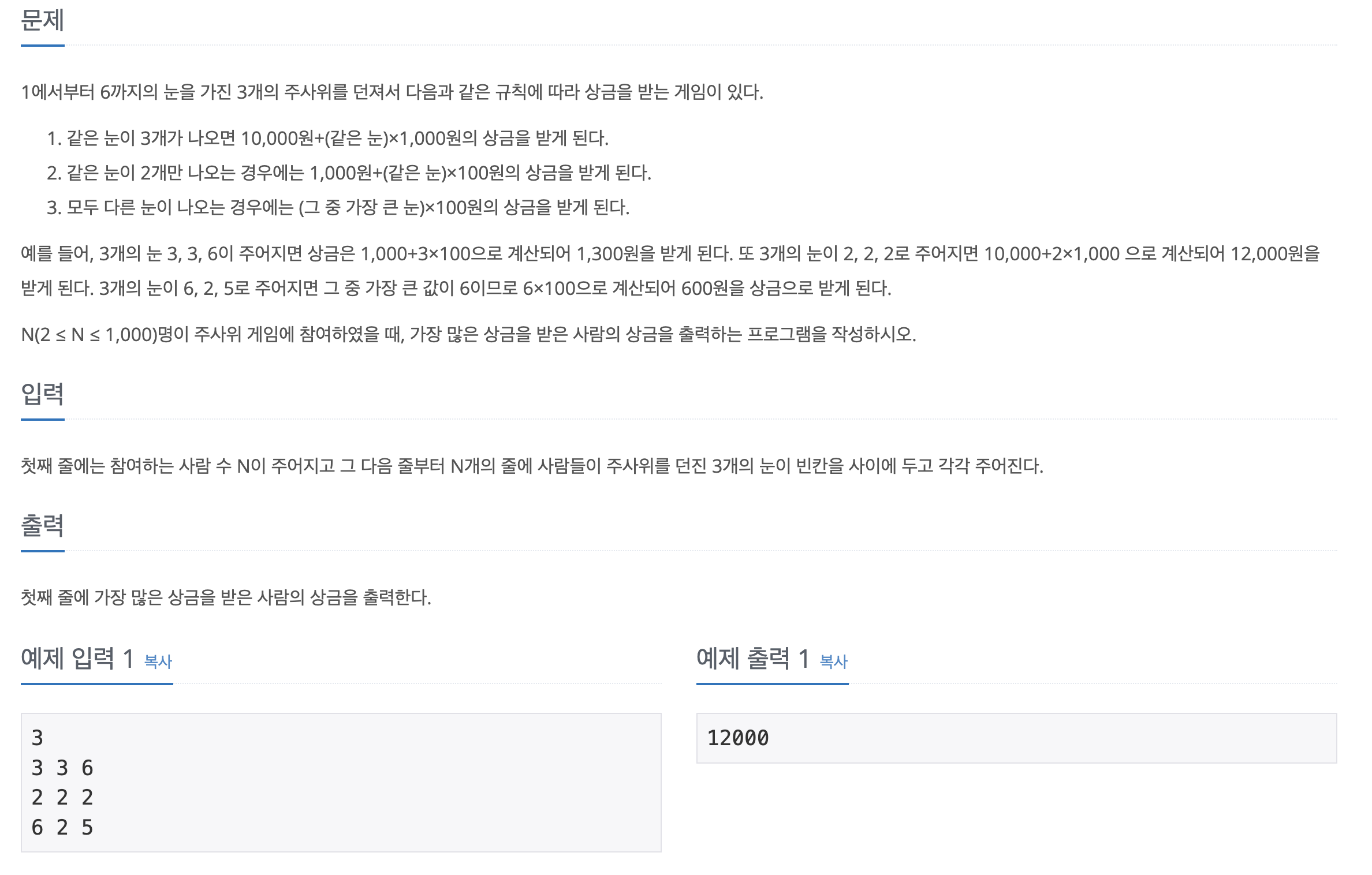
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class B2476 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// 첫 번째 줄에서 입력 개수 n 읽기
int n = Integer.parseInt(br.readLine().trim()); // 첫 줄 읽기 및 공백 제거
//최댓값 설정
int max = 0;
for (int i = 0; i < n; i++) {
int money = 0;
StringTokenizer st = new StringTokenizer(br.readLine());
int A = Integer.parseInt(st.nextToken());
int B = Integer.parseInt(st.nextToken());
int C = Integer.parseInt(st.nextToken());
//나오는 눈에 따른 금액 저장
if(A == B && B == C ) {
money = 10000 + (A * 1000);
}else if(A != B && B != C && A != C) {
money = Math.max(A, Math.max(B, C)) * 100;
}else {
if(A == B || A == C) {
money = 1000 + (A * 100);
}else {
money = 1000 + (B * 100);
}
}
//최대값 저장
if(money > max) {
max = money;
}
}
// 입력값 출력 (최종 결과)
System.out.print(max);
}
}
StringTokenizer
StringTokenizer는 Enumeration<Object>를 주입받는 클래스입니다. 이 클래스에는
nextToken()이라는 구현체가 있습니다.
같이 있는 설명에 따르면
Returns the next token from this string tokenizer.
Returns:the next token from this string tokenizer.
Throws: NoSuchElementException – if there are no more tokens in this tokenizer's string.
해당 tokenizer의 다음 token을 반환합니다. throw: NoSuchElementException -해당 tokenizer에 토큰이 없을경우
라고 적혀져 있습니다.
public String nextToken() {
/*
* If next position already computed in hasMoreElements() and
* delimiters have changed between the computation and this invocation,
* then use the computed value.
*/
currentPosition = (newPosition >= 0 && !delimsChanged) ?
newPosition : skipDelimiters(currentPosition);
/* Reset these anyway */
delimsChanged = false;
newPosition = -1;
if (currentPosition >= maxPosition)
throw new NoSuchElementException();
int start = currentPosition;
currentPosition = scanToken(currentPosition);
return str.substring(start, currentPosition);
}코드를 보아도 이해가 잘 안되어서 다른 분이 작성한 글을 읽고 이해가 되었습니다.
그러면 반복문은 어떻게 동작하는거지?
라는 의문이 들었습니다.
다음은 클래스 상단에 작성되어 있는 설명입니다.
The string tokenizer class allows an application to break a string into tokens. The tokenization method is much simpler than the one used by the StreamTokenizer class. The StringTokenizer methods do not distinguish among identifiers, numbers, and quoted strings, nor do they recognize and skip comments.
The set of delimiters (the characters that separate tokens) may be specified either at creation time or on a per-token basis.
An instance of StringTokenizer behaves in one of two ways, depending on whether it was created with the returnDelims flag having the value true or false:
If the flag is false, delimiter characters serve to separate tokens. A token is a maximal sequence of consecutive characters that are not delimiters.
If the flag is true, delimiter characters are themselves considered to be tokens. A token is thus either one delimiter character, or a maximal sequence of consecutive characters that are not delimiters.
A StringTokenizer object internally maintains a current position within the string to be tokenized. Some operations advance this current position past the characters processed.
A token is returned by taking a substring of the string that was used to create the StringTokenizer object.
The following is one example of the use of the tokenizer. The code:StringTokenizer st = new StringTokenizer("this is a test"); while (st. hasMoreTokens()) { System. out. println(st. nextToken()); }prints the following output:
this is a test
음 뭔가 공백을 중심으로 token을 생성하는것 같습니다.
다른 구현체를 살펴보던중
public StringTokenizer(String str, String delim) {
this(str, delim, false);
}
/**
* Constructs a string tokenizer for the specified string. The
* tokenizer uses the default delimiter set, which is
* "\t\n\r\f": the space character,
* the tab character, the newline character, the carriage-return character,
* and the form-feed character. Delimiter characters themselves will
* not be treated as tokens.
*
* @param str a string to be parsed.
* @throws NullPointerException if str is {@code null}
*/
public StringTokenizer(String str) {
this(str, " \t\n\r\f", false);
}를 찾았습니다.
해석해 보니
지정된 문자열에 대한 문자열 토크나이저를 구성합니다. 토크나이저는 기본 구분 기호 집합인 " \t\n\r\f"를 사용합니다. 즉, 공백 문자, 탭 문자, 줄 바꿈 문자, 캐리지 리턴 문자, 폼 피드 문자입니다. 구분 기호 문자 자체는 토큰으로 처리되지 않습니다.
매개변수:
str – 구문 분석할 문자열.
throws:
NullPointerException – str이 null인 경우
라는 말이였습니다.
상단 코드에서 tokenizer를
public StringTokenizer(String str) {
this(str, " \t\n\r\f", false);
}로 사용하고 \n형태로 입력했기 때문에 반복문이 정상적으로 동작하였습니다.
