Work stealing Algorithm
병렬 처리를 위해 작업을 잘게 나누어 각각을 처리하는 별개 쓰레드를 만든다면? 쓰레드를 만들고 제거하는 작업 자체가 큰 오버헤드여서 시간이 더 걸릴 수 있다.
그렇다면 일정 개수의 쓰레드와 병렬 처리를 위해 전체 작업 목록을 관리하는 작업큐를 사용한다면? 이 작업큐에서 task를 꺼내 병렬로 처리한다고 한다면, 작업큐에 접근하는 것 자체가 경쟁이므로 성능저하가 생길수 있다.
따라서 일정한 개수의 쓰레드를 유지하고, 쓰레드마다 독립적인 작업큐를 관리하여, 하나의 쓰레드 큐가 비게 되면 다른 쓰레드에서 task를 훔쳐올수 있게 한다면 효율적으로 동작할 수 있다.
void TaskProcessorThread(Scheduler scheduler) = {
List<TaskQueue> globalQueues = scheduler.taskQueues;
TaskQueue localQueue = globalQueues[ThreadID];
while (true) {
Task task = localQueue.popFront();
while (task != null) {
task.run();
task = localQueue.popFront();
}
while (task == null) {
YieldThread();
task = globalQueues[random].popBack();
}
}
}Fork-Join 프레임워크
Work stealing 알고리즘을 구현한 자바 7부터 추가된 기능
작업을 잘게 나눌 수 있을 때까지 split 하고 작업 큐에 있는 tail task를 다른 쓰레드가 나누어 병렬처리한 후, join하여 합산하는 방식이다.
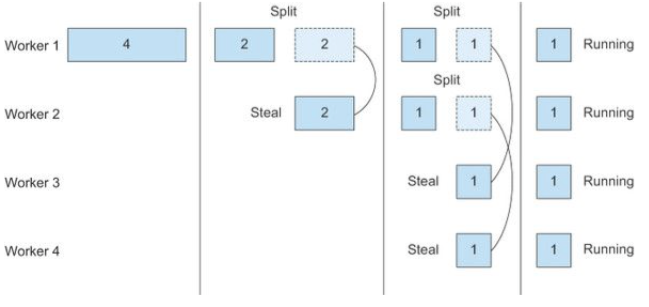
ForkJoinPool
fork-join task를 실행하는 thread pool
public T compute() {
if (더이상 분할 필요 없음) {
} else {
ForkJoinTask leftTask = new ForkJoinTask(절반);
// Thread pool에 추가하여 실행 요청
// 실제 실행될 때 다시 compute 호출됨, 그때 필요하면 다시 분할 됨
leftTask.fork();
ForkJoinTask rightTask = new ForkJoinTask(나머지 절반);
T rightResult = rightrightTask.compute();
T leftResult = leftTask.join();
return mergeResult(leftResult, rightResult);
}
}참고
Java8 in action Chap7. 병렬 데이터 처리와 성능
Java8 Stream의 parallel 처리

김카레