1. Tensor(텐서)
- 배열(array)이나 행렬(matrix)과 매우 유사한 특수한 자료구조
- GPU 연산이 가능, 자동 미분(Autograd) 지원
1-1. 함수
- torch.zeros(): 0으로 채워진 텐서
- torch.ones(): 1로 채워진 텐서
- torch.randn(): 정규분포를 따르는 랜덤 텐서
- torch.tensor(): 리스트나 배열을 텐서로 변환
- tensor.shape : 텐서 모양
- tensor.dtype : 텐서 자료형
- tensor.device : 텐저 장치
** 실제로 코드를 작성할 때 차원이 맞지 않아서 생기는 오류가 많으므로 텐서의 shape과 dtype을 항상 확인!
1-2. 텐서 연산
tensor = torch.ones(4, 4)
print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:,1] = 0
print(tensor)
출력값
First row: tensor([1., 1., 1., 1.])
First column: tensor([1., 1., 1., 1.])
Last column: tensor([1., 1., 1., 1.])
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])2. Autograd(자동 미분)
- 역전파 알고리즘을 수행하기 위해 손실함수의 그레디언트(기울기)를 구해야함
- Autograd를 활용하여 그레디언트(손실함수의 변화도)를 구함
2-1. 예시
- 단층 퍼셉트론 코드 및 그래프
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)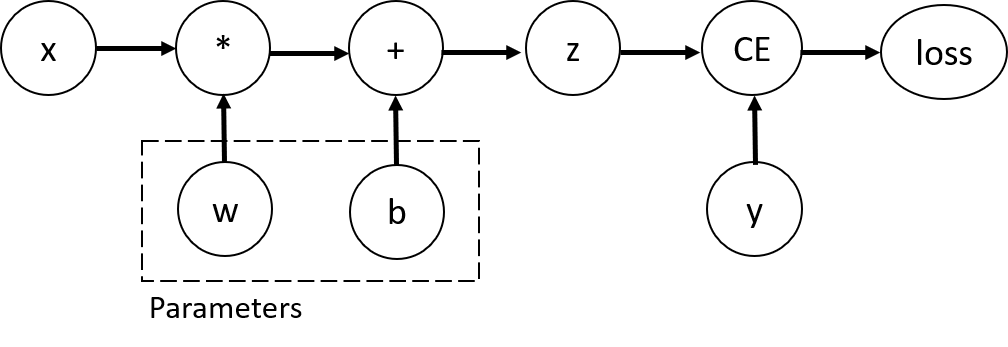
- 코드 설명
1. 입력 데이터
x = torch.ones(5)
- x = [1, 1, 1, 1, 1]
2. 정답 데이터
y = torch.zeros(3)
- y = [0, 0, 0]
3. 학습을 통해 맞춰나가야할 가중치(weight)
w = torch.randn(5, 3, requires_grad=True)
- 5행 3열 행렬 (입력 5개일 때 출력 3개로)
- randn:평균이 0이고 표준편차가 1인 정규분포에서 랜덤한 숫자 뽑음
- requires_grad=True : Autograd(자동미분) 실행, 나중에 역전파로 w 학습을 하기 위해 미분(기울기)값 기록함
4. 학습을 통해 맞춰나가야할 편향(bias)
b = torch.randn(3, requires_grad=True)
- 1행 3열 행렬
- randn:평균이 0이고 표준편차가 1인 정규분포에서 랜덤한 숫자 뽑음
- requires_grad=True : Autograd(자동미분) 실행, 나중에 역전파로 b 학습을 하기 위해 미분(기울기)값 기록함
5. 곱하기 더하기 연산
z = torch.matmul(x, w)+b
- 입력(x)에 가중치 w를 곱하고 편향 b를 더함(z = wx + b)
6. 오차 계산
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
- 예측값 z와 정답 y가 얼마나 차이나는지 계산
- CE는 Cross Entropy를 말함, 다른 오차 함수로는 MSE가 있음
즉, requires_grad=True 이 설정으로 Autograd 적용함
3. Dataset과 DataLoader
- 데이터 샘플을 처리하는 코드는 지저분(messy)하고 유지보수가 어려울 수 있음
- 데이터셋 코드를 모델 학습 코드로부터 분리하는 것이 이상적
3-1. Dataset
- torch.utils.data.Dataset
- 샘플과 정답(label) 지정
- 미리 준비해둔(pre-loaded) 데이터셋이 존재함
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)- 사용자가 준비한(사용자 정의) 데이터셋 사용 가능
- 사용자 정의 Dataset 클래스는 반드시 3개 함수를 구현해야 함
__init__, __len__, __getitem__
- 사용자 정의 Dataset 클래스는 반드시 3개 함수를 구현해야 함
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file, names=['file_name', 'label'])
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label3-2. DataLoader
- torch.utils.data.DataLoader
- Dataset 을 샘플에 쉽게 접근할 수 있도록 순회 가능한 객체(iterable)로 감쌈
- 미니배치(minibatch)로 전달하고, 매 에폭(epoch)마다 데이터를 다시 섞어서 과적합(overfit)을 막고, Python의 multiprocessing 을 사용하여 데이터 검색 속도를 높임
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)*. 관련 개념
- 선형 변환(Linear Transformation)
- 데이터를 이동시키고 늘리는 가장 기초적인 작업
- 수식: y = wx + b (항상 수식이 동일함)
- 의미: 입력 데이터(x)에 가중치(w)를 곱하고 편향(b)을 더함
- 특징:그래프로 그리면 무조건 '직선'이나 '평면' 형태가 나옴
- 비선형 변환(Non-linear Transformation)
- 직선(선형변환 결과)을 구부려서 복잡한 문제를 풀게 함
- 활성화 함수가 이 역할을 함
- 종류: Sigmoid, ReLU, Tanh 등
- 의미: 선형 변환된 결과값을 구부러지거나 꺾인 형태로 바꿈
- 특징:
- 직선을 곡선으로 만들어 줌
- 이 과정이 있어야 신경망이 복잡한 데이터(사람 얼굴, 자연어 등)의 경계선을 그려낼 수 있음
참고

하루살이