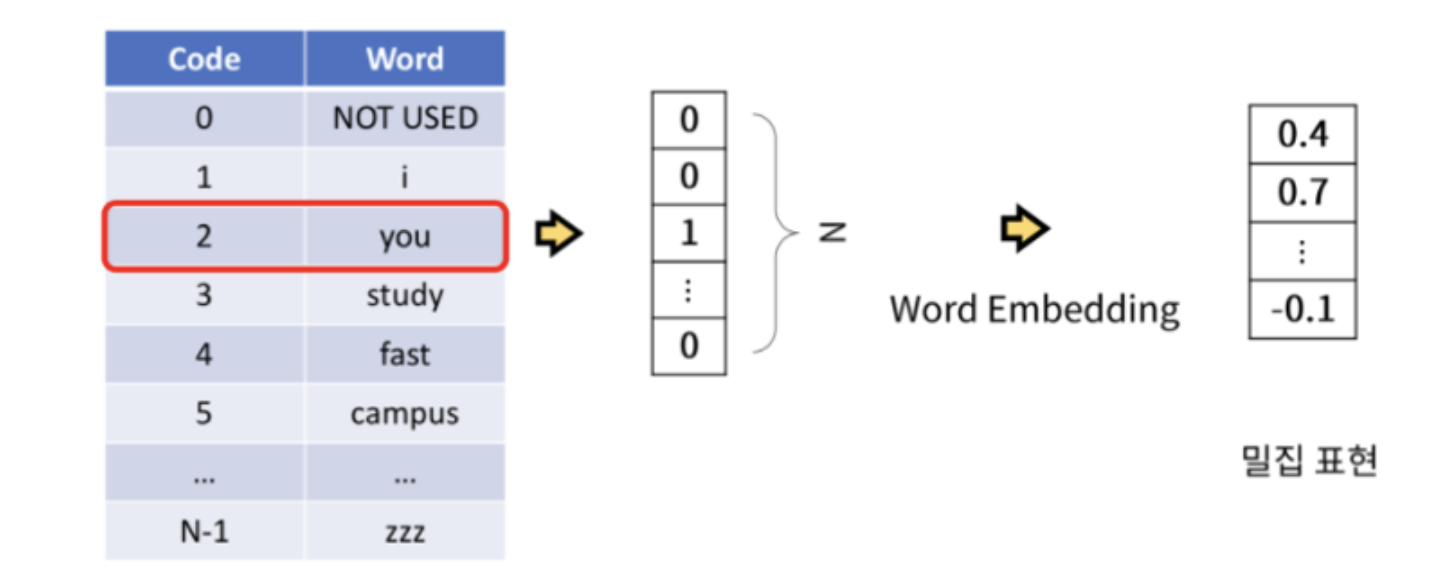
- nn.Embedding
- 기존 범주형변수를 one-hot 인코딩하면 대부분의 값이 0이므로 매우 sparse해짐
- 위의 문제를 해결하기 위하여 임의의 길이의 실수 벡터로 밀집되게 표현하는 일련의 방법을 임베딩(embedding)이라 하고, 각 카테고리가 나타내는 실수 벡터를 임베딩 벡터라 함
- 관련 예시 코드 및 설명
# 임베딩 벡터를 생성한 전체 범주의 개수가 10이고, 임베딩 벡터 차원이 3이므로 10*3 크기의 행렬 생성됨 -> 정규분포를 따르는 랜덤값으로 초기화됨
embedding = nn.Embedding(10, 3)
# 이미 만들어진 embedding에서 2개의 샘플을 복사해서 가져오는 Lookup 작업을 함.
# 이때 1번째 샘플은 embedding 행렬의 1,2,4,5 행의 임베딩 벡터를 가져오고,
# 2번째 샘플은 4,3,2,9 행의 임베딩 벡터를 가져옴
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
embedding(input)
# 결과값
>> tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])- nn.init
- 가중치 초기화 관련 기본 개념 정리
(1) Xavier 초기화
import torch
# 빈 텐서 생성
tensor_uniform = torch.empty(3, 5)
tensor_normal = torch.empty(3, 5)
# 균등 분포로 초기화
torch.nn.init.xavier_uniform_(tensor_uniform, gain=1.0, generator=None)
print(f'균등 분포 ', tensor_uniform )
# 정규 분포로 초기화
torch.nn.init.xavier_normal_(tensor_normal, gain=1.0)
print(f'정규 분포',tensor_normal)
------------------------------------------------------
균등 분포 tensor([[-0.5576, -0.7264, 0.2654, -0.7511, -0.3088],
[ 0.7059, 0.6009, -0.6884, -0.0664, 0.7435],
[ 0.5134, 0.6118, 0.2403, 0.0801, 0.7607]])
정규 분포 tensor([[ 0.9741, 0.1742, -1.0699, -0.1486, 0.2731],
[-0.2109, -0.2306, 0.7515, -0.9540, 1.0228],
[-0.4853, 0.2636, 0.6432, -0.1358, -0.4924]])
출처: https://resultofeffort.tistory.com/114 [resultofeffort:티스토리]파라미터 설명
- tensor_uniform : 가중치 초기화할 타겟 행렬
- gain(float, optional) : 기본값 1.0으로, 초기화 값의 크기를 조절하는 배율
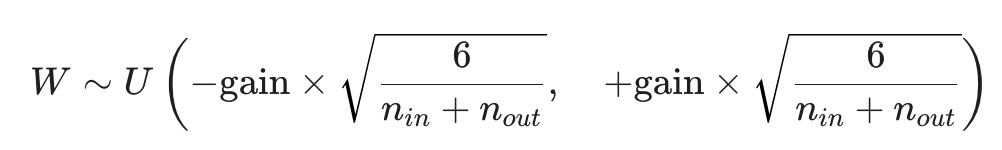
- generator(optional) : 기본값 None으로, 난수 생성할 때 사용하는 시드 생성기, 해당 generator를 넣으면 항상 똑같은 랜덤값을 나오게 고정할 수 있음(재현성 보장)
(2) He 초기화
import torch
tensor_uniform = torch.empty(3, 5)
torch.nn.init.kaiming_uniform_(tensor_uniform, mode='fan_in', nonlinearity='relu', generator=None)
print(f'균등 분포 ', tensor_uniform )
tensor_normal = torch.empty(3, 5)
torch.nn.init.kaiming_normal_(tensor_normal, mode='fan_in', nonlinearity='relu', generator=None)
print(f'정규 분포',tensor_normal)
출처: https://resultofeffort.tistory.com/114 [resultofeffort:티스토리]파라미터 설명
- tensor_uniform : 가중치 초기화할 타겟 행렬
- mode : 기본값 fan_in, He 초기화 공식에서 분모에 넣을 값 정함
- fan_in : 들어오는 노드 수를 기준으로 분산 맞춤
- fan_out : 나가는 노드 수를 기준으로 분산 맞춤
- nonlinearity : 기본값 relu, 어떤 활성화 함수를 사용할지 적으면 적절한 gain 값을 계산해서 적용
- generator(optional) : 기본값 None으로, 난수 생성할 때 사용하는 시드 생성기, 해당 generator를 넣으면 항상 똑같은 랜덤값을 나오게 고정할 수 있음(재현성 보장)
- torch.cat
- Concatenate의 약자로, 주어진 차원(dim)을 기준으로 텐서들을 이어 붙임
- 연결하려는 차원을 제외한 나머지 차원의 크기가 반드시 같아야 함
import torch
t1 = torch.tensor([[1, 2], [3, 4]]) # (2, 2)
t2 = torch.tensor([[5, 6], [7, 8]]) # (2, 2)
# dim=0 (행 기준, 세로로 붙이기)
cat_0 = torch.cat([t1, t2], dim=0)
# dim=1 (열 기준, 가로로 붙이기)
cat_1 = torch.cat([t1, t2], dim=1)
print("dim=0:", cat_0)
print("dim=1:", cat_1)
# 결과값
>> dim=0: tensor([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
>> dim=1: tensor([[1, 2, 5, 6],
[3, 4, 7, 8]])- torch.stack
- 새로운 차원을 생성하며 텐서들을 결합함
- cat은 기존 차원을 늘리는 것이고, stack은 새로운 차원을 하나 더 만드는 것이 차이점
- 모든 입력 텐서의 크기(shape)가 정확히 같아야 함
import torch
t1 = torch.tensor([1, 2])
t2 = torch.tensor([3, 4])
# dim=0에 쌓기 (새로운 차원 추가)
# t1, t2는 (2,) 크기 -> stack 후 (2, 2) 크기가 됨
stacked = torch.stack([t1, t2], dim=0)
print(stacked)
# 결과값
>> tensor([[1, 2],
[3, 4]])- torch.matmul
- 두 텐서의 행렬 곱(Matrix Multiplication)을 수행
- 더 자세한 설명 : https://velog.io/@passiona2z/%EC%9E%91%EC%84%B1%EC%A4%91-PyTorch-%ED%85%90%EC%84%9C%EA%B0%84%EC%9D%98-%EA%B3%B1%EC%85%88
import torch
mat1 = torch.tensor([[1, 2], [3, 4]]) # (2, 2)
mat2 = torch.tensor([[1, 0], [0, 1]]) # (2, 2) 단위 행렬
# 행렬 곱
result = torch.matmul(mat1, mat2)
print(result)
# 결과값
>> tensor([[1, 2],
[3, 4]])- torch.sparse.mm
- 희소 행렬(Sparse Matrix)과 밀집 행렬(Dense Matrix)의 곱셈을 수행
- 추천 시스템이나 GNN에서 인접 행렬(Adjacency Matrix)은 대부분 0인 희소 행렬이므로, 메모리 효율을 위해 일반 matmul 대신 사용함
- mat1은 희소 텐서(Sparse Tensor), mat2는 밀집 텐서(Dense Tensor)여야 함
import torch
# 1. 희소 텐서 생성 (Indices와 Values로 정의)
# (0, 1) 위치에 3, (1, 2) 위치에 4가 있는 2x3 행렬
i = torch.LongTensor([[0, 1], [1, 2]])
v = torch.FloatTensor([3, 4])
sparse_mat = torch.sparse_coo_tensor(i, v, (2, 3))
# 2. 밀집 텐서 생성 (3x2 행렬)
dense_mat = torch.tensor([[1, 0], [0, 1], [1, 0]], dtype=torch.float32)
# 3. 행렬 곱 (2x3) @ (3x2) -> (2x2)
res = torch.sparse.mm(sparse_mat, dense_mat)
print(res)
# 결과값
# [0행] (0,1)값 3 * [1행] (0,1) -> 3*0 + 3*1 = 3
>> tensor([[0., 3.],
[4., 0.]])- torch.mul
- 두 텐서의 원소별 곱셈(Element-wise multiplication) 을 수행
- 행렬 곱(matmul)이 아님. 같은 위치에 있는 원소끼리 곱함
import torch
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[2, 2], [2, 2]])
# 원소별 곱셈 (1*2, 2*2, 3*2, 4*2)
result = torch.mul(a, b)
print(result)
# 결과값
>> tensor([[2, 4],
[6, 8]])- torch.split
- 텐서를 특정 크기(size) 혹은 섹션 개수로 나눔
- torch.cat의 반대 연산
import torch
t = torch.tensor([1, 2, 3, 4, 5, 6])
# 2개씩 자르기
split_t = torch.split(t, 2)
print(split_t)
# 리스트 형태로 각 텐서 반환
# 결과값
>> (tensor([1, 2]), tensor([3, 4]), tensor([5, 6]))- torch.rand_like
- 입력 텐서와 동일한 크기(Shape) 와 데이터 타입(dtype) 을 가지는 텐서를 생성하되, 값은 0~1 사이의 랜덤 값으로 채움
- torch.rand(input.size(), dtype=input.dtype, ...)와 동일함
import torch
input_tensor = torch.empty(2, 3) # (2, 3) 크기
random_tensor = torch.rand_like(input_tensor)
print(random_tensor)
# 결과값 (랜덤)
>> tensor([[0.8231, 0.4123, 0.1982],
[0.2141, 0.6521, 0.9812]])- torch.sign
- 입력 텐서 각 요소의 부호(Sign) 를 반환함
- 양수면 1, 음수면 -1, 0이면 0을 반환
import torch
t = torch.tensor([10, -5, 0, 3.5, -0.1])
result = torch.sign(t)
print(result)
# 결과값
>> tensor([ 1., -1., 0., 1., -1.])- nn.Sequential
- 여러 nn.Module들을 순차적으로 포장하는 컨테이너
- 내부에 정의된 순서대로 데이터가 통과하며, forward() 메서드를 직접 정의할 필요 없이 자동으로 순전파가 실행됨
- 가독성이 좋고 코드가 간결해지지만, 분기(Branching)나 반복문 등 복잡한 제어 흐름을 구현하기에는 제한적임
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 10)
)
print(model)- nn.ModuleList
- nn.Module들을 파이썬 리스트(List)처럼 인덱싱으로 관리하는 컨테이너
- nn.Sequential과 달리 자동으로 연결되지 않음. 따라서 forward() 메서드에서 반복문이나 인덱싱을 통해 직접 실행 순서를 정의해야 함
- 파이썬의 기본 list 대신 사용하는 이유는, nn.ModuleList에 넣어야만 PyTorch가 해당 모듈들의 파라미터(가중치)를 모델의 학습 대상으로 인식하기 때문임
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.layers = nn.ModuleList([
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 10)
])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
model = MyModel()
print(model)- nn.ModuleDict
- nn.Module들을 파이썬 딕셔너리(Dictionary)처럼 키(Key)와 값(Value)으로 관리하는 컨테이너
- 데이터의 타입이나 조건에 따라 서로 다른 레이어를 선택적으로 실행해야 할 때 유용함
- nn.ModuleList와 마찬가지로 forward()에서 실행 로직을 직접 구현해야 함
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.layers = nn.ModuleDict({
'fc1': nn.Linear(10, 20),
'relu': nn.ReLU(),
'fc2': nn.Linear(20, 10)
})
def forward(self, x):
x = self.layers['fc1'](x)
x = self.layers['relu'](x)
x = self.layers['fc2'](x)
return x
model = MyModel()
print(model)- nn.Parameter
- Tensor의 하위 클래스로, nn.Module 안에서 속성으로 할당될 때 자동 학습 대상 리스트인 parameter에 등록되는 변수
- 일반 Tensor 대신 nn.Parameter를 사용해야 단순 데이터가 아닌 학습시켜야할 가중치인 것을 인식함
- forward 함수에서 수식을 작성하면 pytorch에서 자동으로 역전파 시 가중치 업데이트 함
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super().__init__()
# Case 1: 일반 Tensor로 선언
# 모델은 이것을 그냥 '고정된 숫자 데이터'로 취급함 (학습 X, 상수로 변하지 않음)
self.my_tensor = torch.randn(1)
# Case 2: nn.Parameter로 감싸서 선언
# 모델은 이것을 '학습해야 할 가중치'로 등록함 (학습 O)
self.my_param = nn.Parameter(torch.randn(1))
def forward(self, x):
# 우리는 그저 수식만 적으면 됨 (어떻게 학습할지는 PyTorch가 알아서 함)
# y = x * W + b 형태
return x * self.my_param + self.my_tensor
model = MyModel()
# 모델이 인식한 '학습 대상' 목록 확인
print(f"학습 대상 파라미터: {list(model.parameters())}")
# 결과값
# my_tensor는 무시되고, my_param만 리스트에 존재함!
# >> 학습 대상 파라미터: [Parameter containing: tensor([-0.5421], requires_grad=True)]- nn.ParameterDict
- nn.Parameter을 key와 value 형태의 딕셔너리로 관리하는 컨테이너
- 노드 타입이나 엣지 타입별로 서로 다른 가중치를 이름으로 구분하여 관리할 때 사용
import torch
import torch.nn as nn
class GNNLayer(nn.Module):
def __init__(self):
super().__init__()
# 타입별로 다른 가중치를 딕셔너리로 관리
self.weights = nn.ParameterDict({
'user': nn.Parameter(torch.randn(5, 5)),
'item': nn.Parameter(torch.randn(5, 5))
})
def forward(self, x, node_type):
# 입력된 node_type('user' or 'item')에 맞는 파라미터를 꺼내서 연산
# 마찬가지로 수식만 적으면 해당 파라미터만 자동으로 학습됨
w = self.weights[node_type]
return torch.matmul(x, w)
model = GNNLayer()
# 'user' 타입 가중치 확인
print(f"User Weights Size: {model.weights['user'].size()}")
# 결과값
# >> User Weights Size: torch.Size([5, 5])- 그 외 궁금점
(1) nn.Parameter를 안쓰면 가중치(w)와 편향(b)은 어디서 정해지고 학습되는지?
- 보통 nn.Linear에서 내부적으로 알아서 nn.Parameter를 생성해줌. 만약 nn.Linear를 사용하지 않으면 nn.Parameter로 정해줘야 함.
(2) (x×W+b)/d 와 같은 커스텀 수식 코드
- d도 학습시켜서 최적의 값을 찾아야 할 때
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.W = nn.Parameter(torch.randn(1)) # 가중치 (학습 O)
self.b = nn.Parameter(torch.randn(1)) # 편향 (학습 O)
self.d = nn.Parameter(torch.randn(1)) # 나누는 값 (학습 O)
def forward(self, x):
# 수식 그대로 작성
return (x * self.W + self.b) / self.d- d는 상수로 학습을 안시켜도 될 때
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.W = nn.Parameter(torch.randn(1))
self.b = nn.Parameter(torch.randn(1))
# d는 학습 안 함 (상수)
self.d = 2.0
def forward(self, x):
return (x * self.W + self.b) / self.d*참고

하루살이