정렬(sorting)
👉우리가 정렬을 하는 이유
- 각종 데이터 목록을 정리해야 할 때.
- 분포도의 '중위값'을 알아내고 싶을때.
- 데이터에서, '중복값'을 알아내고 싶을때.
- '이진 탐색'을 해야할 때!
👉우리가 정렬 알고리즘을 배워야 하는 이유
: 사실 거의 모든 프로그래밍 언어에는 자체적인 정렬메소드가 존재하지만,
모든 정렬을 하는 이유에 부합하는, 가장 효율적인 퍼포먼스를 보장하지 않기 때문에,
우리는 효율적인 정렬 알고리즘을 이용하여 상황에 맞게 사용할 수 있어야 한다.
👉대표적인 정렬 알고리즘 몇 가지
- Bubble sorting(버블정렬)
: 데이터를 앞에서부터 2개씩 묶어서 비교한 후, 더 크기가 큰 쪽이, 오른쪽으로 가도록
자리를 바꿔가며, 크기가 더 큰 데이터를 오른쪽으로 미는 원리이다. => 1회차 종료
=> 이런 식으로, n번째 데이터를 한 회차가 끝날 때까지, 비교하면서 오른쪽 자리로 민다.
모든 데이터의 회차가 끝나면 정렬은 종료된다.
⏳시간 복잡도⏳
- O(n^2) : 정렬이 하나도 안되어 있을 때. > 모든 데이터를 순서대로 하나씩 비교해야 하기 때문.
- O(n) : 정렬이 모두 되어있을 때.
- insertion sorting(삽입정렬)
: 왼쪽에서 오른쪽으로 가면서, 각 요소들을 왼쪽 요소와 비교한다.
처음앤, 항상 앞에서 두번째 요소(인덱스가 1인 요소)를, 그 전 요소와 비교하면서 시작한다.
ex)
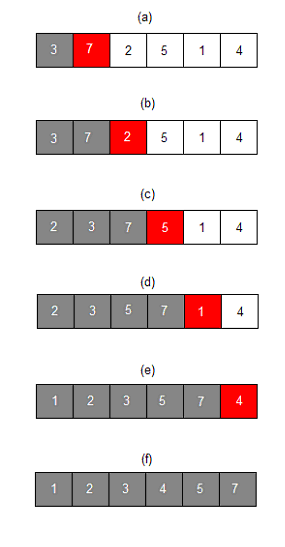
그림 01) 삽입 정렬 예시
↓ 위의 예시를 회차별로 설명해보았다.
.
.
.
즉, 삽입 정렬은 target의 왼쪽 비교대상 데이터들이 정렬되어 있다는 가정하에 진행된다.
⏳시간 복잡도⏳
- O(n^2) : 정렬이 하나도 안되어 있을 때. > 모든 데이터를 순서대로 하나씩 비교해야 하기 때문.
- O(n) : 정렬이 모두 되어있을 때.
=> 버블정렬과 똑같은 시간 복잡도를 가진다. 버블정렬 === 삽입정렬
선택정렬은... 다음시간에 계속..!
인용 출처

예비개발자