Collection이란?
"자료구조"라는 말을 많이 들어 봤을 것이다.
Wikipedia 기준 자료구조란 아래와 같은 의미를 가진다.
컴퓨터 과학에서 (데이터에) 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장을 의미한다
더 정확히 말해, 자료 구조는 데이터 값의 모임, 또 데이터 간의 관계, 그리고 데이터에 적용할 수 있는 함수나 명령을 의미한다.
이를 해석하면 "자료구조"란 자료 그 자체, 다른 자료와의 관계, 그리고 자료를 처리할 수 있는 명령들을 모두 포함하고 있는 개념인 것이다.
Collection도 자료 구조의 일종인데, "여러 원소들을 담을 수 있는 자료구조"를 의미한다.
더욱 정확히 말하자면 다수의 데이터를 저장 및 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 Framework를 말한다.
아마 다수의 데이터를 저장할 수 있는 자료구조라고 하면 대표적으로 생각나는 것이 배열일 것이다.
그렇다면 배열이 존재함에도 불구하고 왜 Collection Framework라는 새로운 개념을 구현했을까?
배열은 선언 당시 배열이 사용할 메모리 공간을 미리 선언해 둔다.int[] arr = new int[4]
이를 "정적 메모리 할당"이라고 한다.
하지만 현실에서 코드를 활용할 때 필요한 메모리 공간이 미리 정해져 있는 경우는 많이 존재하지 않는다.
따라서 개발자들은 공간이 필요할 때마다 공간을 자유롭게 추가할 수 있는 "동적 메모리 할당"의 자료구조가 필요해졌다.
이 때문에 동적 메모리 할당으로 여러 데이터를 담을 수 있는 Collection Framework가 도입된 것이다.
Collection 사용 이유
공간에 구애받지 않고 데이터 주입이 가능
Collection의 가장 큰 장점은 동적 메모리 할당으로 자료 구조를 사용할 수 있기 때문에 ArrayIndexOutOfBoundsException 발생 걱정 필요 없이 데이터를 주입할 수 있다는 것이다.
빠르고 정확한 자료구조 알고리즘의 사용
Collection Framework는 자료구조를 이미 Java 언어로 구현해놓은 고품질의 Framework이기 때문에 Low-level 알고리즘을 고민하고 구현하는데 필요한 시간을 아낄 수 있다.
이에 대해서는 Stack이나 Queue를 생각하면 바로 이해할 수 있을 것이다.
배열로 Stack이나 Queue를 구현하기 위해서는 가장 나중에 저장된 데이터가 저장된 Index인 top을 지정하고, 이 top을 통해 여러 Case를 고려하여 로직을 짜는 귀찮은 작업이 선행되어야 한다.
아마 배열을 통해 Stack을 직접 구현해 본 경험이 있는 사람이라면 이 과정에서 많은 에러가 발생함을 경험했을 것이다.
그리고 이런 에러는 운영 상 문제를 야기할 수도 있는 중요한 문제이다. 그렇다고 항상 구글에 검색하여 에러가 발생하지 않는 코드를 검색하여 복사 붙여 넣기 하기에는 너무 귀찮은 작업이다.
하지만 Collection Framework에서는 Stack이 이미 구현되어 있으므로 단순히 Stack<Integer> stack = new Stack<>(); 명령을 통해 선언만 하면 Stack의 모든 기능을 손쉽고 정확하게 활용할 수 있다.
데이터 검색 시간의 단축
Collection을 사용할 경우 데이터를 검색하는 시간 또한 단축시킬 수 있다.
이에 대한 예시는 Map일 것이다.
만약 Map을 사용하지 않고 배열을 통해서만 Key-Value 데이터를 저장한다고 가정하자.
이 상황에서 데이터를 뽑고 싶다면 Key값을 저장한 배열을 순회한 뒤 원하는 Key값 Index를 찾으면 Value 값을 저장한 배열에 접근하여 찾은 Index를 활용해 값을 추출해야 한다.
당연히 시간도 오래 걸릴 것이며 Key를 저장하는 배열과 Value를 저장하는 배열이 어떠한 문제로 Index Sync가 안 맞게 될 경우 Key와 매칭되지 않는 엉뚱한 Value를 반환할 위험도 존재한다.
Collection의 Map은 Key-Value Mapping 문제를 B-tree 등의 알고리즘으로 미리 해결해놨기 때문에 안전하게 Value 값을 추출할 수 있고, Key를 통해 바로 데이터를 추출하면 되므로 검색 시간도 단축된다.
※ Collection은 다형성의 장점을 가진다는 글들도 있었으나 사용만 잘한다면 배열 또한 다형성의 장점을 가지기 때문에 이 장점은 따로 기입하지 않겠다.
배열만의 장점 & 그럼에도 불구하고 Collection 사용을 추천하는 이유
그렇다고 배열만의 장점이 없는 것은 아닌데, 바로 메모리 효율이 높다는 것이다.
ArrayList는 어떻게 무한하게 데이터를 집어넣을 수 있는 걸까?
ArrayList는 먼저 어느 정도의 메모리를 사용해 배열 상태로 개발자에게 자료구조를 제공한다. 만약 User가 ArrayList 측에서 미리 준비한 메모리보다 더 많은 데이터를 집어넣을 경우 ArrayList는 스스로 다른 공간에 기존보다 더 많은 메모리를 사용해 새로운 배열을 만들어내고 여기에 추가 데이터를 주입한다.
자세히 말하자면 더욱 복잡하지만, 간단히만 설명하자면 이와 같다.
이때 일반적으로 기존 메모리의 2배만큼의 공간을 사용해 새로운 배열을 만들어낸다고 알려져 있다.
이 때문에 ArrayList를 사용할 경우 메모리는 차지하지만 사용하지 않는 공간이 많이 나올 수 있다.
예를 들어 데이터가 250 ~ 300개 주입됨이 고정되어 있다고 가정하자.
배열의 경우 int[] arr = new int[300];으로 미리 선언한 뒤 데이터를 주입할 경우 아무리 공간이 낭비되어도 50 밖에 낭비되지 않는다.
하지만 ArrayList의 경우 처음 준비된 공간이 30일 때 30 → 60 → 120 → 240 → 480으로 확장되어 총 480 메모리가 사용될 것이므로 최대 230 공간이 낭비될 수 있는 것이다.
이처럼 배열은 사용하는 메모리 범위가 어느 정도 정해져 있는 상황에서 메모리를 조금 더 효율적으로 사용할 수 있다.
하지만 이전에 말했듯 실생활에서는 사용할 메모리 범위가 미리 정해져 있는 Case가 드물기 때문에 이런 장점을 실제로 활용하기엔 어려운 점이 많고 최근 HW Spec적으로 큰 성장이 이뤄졌기 때문에 이런 메모리 절약의 장점이 편의성을 포기하면서까지 사용할 이유는 되지 않는다.
배열이 Index를 통해 Collection보다 빠른 접근이 가능하다고 주장하는 사람이 있지만 ArrayList라는 Index를 통한 접근이 가능한 Collection이 있기 때문에 이 주장도 살짝 애매한 것 같다.
따라서 메모리 공간 효율성이 극대화되어야 하는 상황이 아니라면 Collection 사용을 추천한다.
Collection Framework 상속 구조
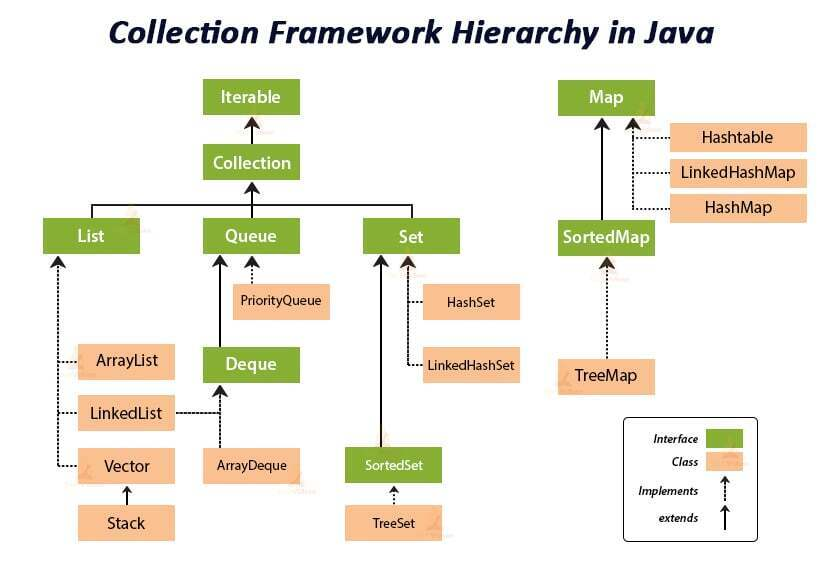
출처 : https://techvidvan.com/tutorials/java-collection-framework/
Collection Interface는 Iterable Interface를 상속하고 있음을 알 수 있다.
Iterable Interface 또한 나중에 자세히 다뤄야겠지만, 여기서 간단히 설명하자면 하위 클래스에서 "iterator()"를 하위 클래스에서 무조건 구현을 하기 위한 껍데기 인터페이스라고 할 수 있겠다.
즉, Iterable의 역할은 오직 iterator() 함수를 사용하게 하는 것이다.
Iterator Interface는 이를 상속받는 객체에 저장한 여러 요소들을 읽어오는 방법을 표준화한 것이다.
즉, Collection Interface는 Iterable Interface를 상속함으로써 모든 Collection Framework는 동일한 방법으로 저장해 놓았던 데이터들에 접근 및 처리할 수 있게 되는 것이다.
위 사진에서 볼 수 있듯 Collection은 "List, Set, Map, Queue" 총 4가지 종류로 구성되어 있음을 알 수 있다.
각 Collection 유형은 아래와 같이 분류될 수 있다.
- List : 중복을 허용하고 순서를 저장하는 Collection
- Set : 중복을 허용하지 않고 순서를 따지지 않는 Collection
- Map : Key-Value 형태로 값을 저장하는 Collection
- Queue : FIFO 구조를 가지고 있는 Collection
그런데 많은 사이트를 찾아보면 Queue를 Collection에 포함시킨 곳이 있고 포함시키지 않은 곳이 있다.
실제로 면접을 볼 때도 "Collection 3종류를 말씀해 주세요"라고 물어본 경험이 있다.
그리고 정보처리기사 공부 할 때도 Collection 종류에는 List, Set, Map이 존재한다고 말한다.
왜 이런지는 잘 모르겠지만 추측하기로는 Queue를 Queue<Integer> queue = new Queue<>(); 방식으로 사용하는 것보다는 Queue queue = new LinkedList<>(); 방식으로 활용하는 경우가 잦은 것과 연관이 있지 않을까 싶다.
Queue는 new Queue를 통해 객체를 생성할 경우 Anonymous Implement Object(익명 구현 개체)로 인터페이스를 사용해야 한다.
그리고 이런 귀찮은 작업을 피하기 위해 Queue는 주로 구조가 유사한 LinkedList를 사용해 선언하는 경우가 잦다.
이렇다 보니 Queue 또한 결국은 List와 동등한 Collection 종류라기보다는 LinkedList의 하위 분류라고 생각하여 Queue를 Collection으로 간주하지 않은 사람도 있는 것이 아닐까라고 예측했다.
만약 Collection 종류를 물어본다면 "Collection 종류에는 List, Set, Map, Queue 총 4종류가 존재하지만 흔히 Queue를 제외한 List, Set, Map 총 3종류로 구성되어 있다고 알려져 있다"라고 대답하는 것이 가장 정확한 답일 것 같다.
Collection 공통 함수
아래 설명 할 함수들은 "Collection Interface"에 존재하는 함수임을 알린다.
Collection Interface에 존재하는 함수들이니 당연히 이를 상속하는 Collection들 또한 아래 설명할 함수를 공통적으로 가지고 있는 것이다.
반대로 Collection Interface를 상속받지 않지만 Collection으로 간주되는 Map 계열 자료구조에는 사용할 수 없는 함수임을 미리 인지하고 가자.
add(E e)
- Return Type : boolean
Type이 E인 데이터를 Collection에 추가한다
addAll(Collection)
- Return Type : boolean
Parameter Collection의 모든 데이터를 Collection에 추가한다.
당연히 Parameter Collection도 "Collection Interface를 상속한 Collection"을 의미한다.
clear()
- Return Type : void
Collection의 모든 데이터를 지운다.
contains(Object)
- Return Type : boolean
매개 변수인 객체가 Collection에 존재하면 true, 존재하지 않으면 False를 반환한다.
containsAll(Collection)
- Return Type : boolean
Parameter Collection에 있는 모든 데이터가 포함되어 있을 경우 true를 반환한다.
isEmpty()
- Return Type : boolean
Collection에 들어 있는 데이터가 없으면(비어 있으면) true를 반환한다.
remove(Object)
- Return Type : boolean
매개 변수로 들어온 객체와 동일한 객체를 Collection에서 제거한다.
removeAll(Collection)
- Return Type : boolean
매개 변수로 들어온 Collection에 포함된 모든 데이터를 현재 Collection에서 삭제한다.
retainAll(Collection)
- Return Type : boolean
매개 변수로 들어온 Collection에 포함된 데이터만 남기고 다른 데이터들은 현재 Collection에서 삭제한다.
size()
- Return Type : int
Collection에 포함된 데이터 개수를 반환한다.
toArray()
- Return Type : Object[]
Collection에 있는 데이터들을 배열로 복사한다.
toArray(T [])
- Return Type : T[]
Collection에 있는 데이터들을 Type이 T인 데이터 배열로 복사한다.
toArray()와 toArray(T[]) 차이 알아보기
toArray()와 toArray(T[])에는 그렇게 큰 차이가 없어 보인다. 결국 List를 배열로 변환해 반환해 주는 동일한 역할을 하는 것 같은데 왜 따로 구별해 둔 것일까?
이것은 Object 배열을 T[] 형식의 배열로 바로 변환시킬 수 없기 때문이다. 예를 들어보자.
Object[] objects = new Object[4];
for (int i = 0; i < 4; i++) {
objects[i] = i;
}
Integer[] intObjects = (Integer[]) objects;일반적으로 Object 객체는 Integer s = (Integer) 3;처럼 변환할 수 있다. 그렇다면 Object[] 또한 (Integer[])로 변환할 수 있지 않을까 생각했다.
위 예시에서 objects는 Object 배열이고, Object에는 Integer Data가 들어갔음이 명확하므로 Integer 배열로 변환 가능하지 않을까 생각했지만 결과는 Object 배열은 Integer 배열로 Cast 할 수 없다는 에러 문구였다.

결국 Object 배열을 Integer 배열로 바꾸기 위해선 for문을 활용하여 Object 배열 원소 각각에 (Integer)을 통해 형 변환을 수행해준 뒤 Integer 배열에 넣어줘야 하는 것이다.
처음부터 Integer 배열을 선언하여 데이터를 넣어주면 되겠지만 toArray()는 Object 배열을 반환해주므로 여기엔 제한 사항이 존재한다.
따라서 toArray()를 통해 Object 배열을 반환받고 for문을 통해 데이터에 접근하여 형 변환을 통해 T[] 형식으로 만들어줘야 한다는 것인데 이는 시간도 많이 들고 비효율적인 작업이다.(심지어 코드도 더러워진다)
이런 비효율적인 코드를 막기 위해 생긴 것이 toArray(T[])이다.
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < 4; i++) {
list.add(i);
}
Long[] obj2 = list.toArray(new Long[0]);성공함을 볼 수 있다.
심지어 위 예시에서 볼 수 있듯 Integer ArrayList였는데 Long 배열로 형 변환까지 자동으로 수행해줌을 알 수 있었다.
(물론 Long ArrayList를 Integer 배열로 반환할 경우 에러가 발생한다. 어디까지나 (T) 예약어를 통해 자동 형변환이 가능한 Data Type 사이에서만 가능한 방법이다)
그런데 신기한 점이 있다. 바로 List의 Size는 4일 텐데 선언한 배열은 new Long[0], 즉 Length가 1밖에 되지 않는다는 것이다.
그렇다면 List 값에 누락이 발생한 걸까? 한 번 obj2 값을 확인해 보자.
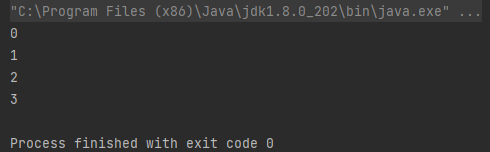
값 누락이 없음을 확인할 수 있다.
이렇게 Length를 1로 설정했지만 값이 그대로 유지되는 이유는 toArray의 동작 방식 때문이다.
- List를 toArray 메서드에 넣으면 배열 객체의 Size만큼 배열로 전환된다.
- List size가 원래 선언된 배열 Size보다 클 때 List의 Size로 배열이 새로 만들어져 새로 만들어진 배열에 값이 저장된다
- List size보다 원래 선언된 배열 Size가 클 경우 원래 선언된 배열 Index 0부터 값이 채워지고 사용하는 공간, 즉 배열의 Length는 유지된다.
그렇다면 만약 toArray(new Integer[10])로 설정하면 길이가 10으로 바뀔까? 한 번 확인해 보자.

실제로 10이 출력됨을 알 수 있다.
굳이 원래 List보다 길이를 길게 하여 Array를 형성할 필요는 없으므로 toArray의 자동 길이 맞춤 능력을 믿고 new T[0]을 사용하도록 하자.
추가로 아래 3개는 개인적으로 그렇게 중요하지 않다고 생각되므로 이런 게 있다 정도로만 알고 넘어가자.
iterator()
- Return Type : Iterator
Collection 데이터를 하나씩 처리하기 위한 Iterator 객체를 반환한다.
위 사진에서 봤듯 Collection은 Iterable 객체를 상속하므로 무조건 가지고 있어야 하는 객체이다.
equals(Object)
- Return Type : boolean
매개 변수인 객체와 Collection이 동일할 경우 true를 반환한다.
hashCode()
- Return Type : boolean
매개 변수인 객체와 Collection이 동일할 경우 true를 반환한다.
다음 Section에는 List, Set, Map에 각각에 대해 자세히 알아보도록 하자.
