DBMS 서버
DBMS 서버란?
DBMS 서버는 Database Management System의 약자로써 직역하자면 "Databse를 관리해 주는 시스템"을 가지고 있는 서버를 말한다.
DBMS를 알기 위해선 데이터베이스(DB) 용어부터 알아야 한다.
데이터 베이스를 한 마디로 정의하면 "데이터의 저장 공간"이라고 할 수 있다.
데이터베이스는 대량의 데이터를 효율적으로 저장하고 접근할 수 있도록 데이터 집단을 체계적으로 구성해 놓았다.
효율적인 데이터 관리를 위해 활용되는 대표적인 것이 Query문(SQL), Index이다.
DB에는 여러 종류의 데이터가 저장되어 있다. 그리고 다양한 데이터가 저장되어 있는 DB에는 여러 명의 사용자와 응용 프로그램이 접근할 수 있어야 한다.
대표적으로 은행 예금을 생각해 보면 된다. 은행 측에서는 사용자마다 얼마를 통장에 저장하고 있는지 알아야 한다. 하지만 동시에 사용자도 통장에 얼마가 저장되어 있는지 알아야지만 자신이 가진 자산을 관리할 수 있을 것이다.
이렇게 다양한 사용자나 응용 프로그램이 DB에 동시 접속하여 데이터를 공유하기 때문에 이를 관리하기 위한 소프트웨어가 필요하며 이것이 DBMS인 것이다.
DBMS 용어
- 스키마(Schema) : DB 구조나 제약 조건 등에 관한 설명
- Meta-Data
- DB Table 같은 구조에 관한 설정이라고 생각하면 됨
- 테이블 : 데이터를 표 방식으로 표현한 것
- 데이터 : 자료
- 레코드 : 테이블의 행
- 필드(컬럼) : 테이블의 열
- Primary Key 필드 : 레코드를 식별하기 위한 필드로 저장된 값이 테이블 컬럼에서 유일해야 하며 Null이 아니여야 함
- Foreign Key 필드 : 다른 테이블의 Primary Key와 대응되는 필드
- 데이터 타입 : 저장할 데이터의 형식
- 정수형, 문자형, Date(날짜형) 등이 존재
- 필드명 : 각 필드의 이름
DBMS 장점
데이터의 독립성 보장
DBMS를 사용할 경우 데이터의 논리적, 물리적 독립성이 보장된다.
데이터의 논리적 독립성이란 응용 프로그램에 영향을 주지 않고 데이터베이스의 논리적 구조를 변경할 수 있는 능력을 의미한다.
데이터의 물리적 독립성이란 응용 프로그램이나 논리적 구조에 영향을 미치지 않고 데이터의 물리적 구조를 변경할 수 있는 능력을 의미한다.
DBMS를 사용할 경우 논리적 독립성을 보장할 수 있어 DB를 확장하거나 축소하며 외부 스키마에 영향을 주지 않으면서도 DB 테이블들을 관리할 수 있게 된다.
또한 물리적 데이터의 독립성도 보장받을 수 있어 데이터를 저장하는 물리적 구조가 변경되더라도 영향 없이 이전과 동일한 서비스를 제공할 수 있게 된다.
데이터 중복 제거
DBMS를 사용할 경우 설정을 통해 중복된 데이터가 저장되는 것을 사전에 막을 수 있다.
예를 들어 주민번호를 DB에 등록할 때 이 컬럼을 Unique Key로 만들 경우 동일한 값이 존재한다면 DB에 데이터가 저장되기 전 유효하지 않음을 판단하고 사전에 중복 데이터 저장을 막을 수 있는 것이다.
데이터의 무결성과 일관성
데이터의 무결성은 "데이터가 얼마나 정확한가"를 의미하며 데이터의 일관성이란 "저장된 데이터 중 논리적으로 맞지 않는 데이터가 존재하는가"를 의미한다.
예를 들어 주민번호를 저장하는데 뒷자리가 2로 시작된다고 가정하자.
그런데 그 사람의 성별이 "남"일 경우 논리적으로 맞지 않으므로 데이터의 일관성이 깨지며 주민번호든 성별이든 문제가 있는 것이므로 무결성도 깨지게 된다.
DBMS를 사용할 경우 설정이나 함수 등을 통해 이런 상황을 미리 방지할 수 있다.
보안 강화 및 백업 기능을 통한 안정성 증가
DBMS를 사용하면 보안을 강화할 수 있다.
또한 DBMS에는 백업 기능이 있어 혹시 어떤 문제로 인해 데이터나 DB가 삭제되었다 하더라도 짧은 시간 내에 발생한 사건이라면 백업이 가능하므로 운영상 안정성이 높아진다.
대량의 데이터 처리
DBMS를 사용할 경우 데이터를 표준화하여 통합 관리할 수가 있게 된다.
또한 DBMS를 통해 데이터의 실시간 처리도 가능해진다.
이런 DBMS의 특징 덕분에 DBMS를 사용할 경우 대량의 데이터를 처리할 수 있게 된다.
DBMS 단점
전산화 비용 증가
DBMS는 결국 DB 관리를 위한 시스템이기 때문에 SW이며, 이 SW가 구동되기 위한 서버를 따로 마련해줘야 한다.
따라서 DBMS 운영 및 관리를 위한 전산화 비용이 증가할 수밖에 없다.
과부하(Overhead) 발생 가능성 증가
모든 데이터는 DBMS를 거쳐 논리적으로 올바른지를 판단받은 뒤 DB에 저장되게 된다.
따라서 만약 DBMS가 처리할 수 있는 능력 이상의 데이터가 DBMS에 접근한다면 과부하(Overhead)가 발생할 수 있고 이 과정에서 속도 저하나 데이터 누락 등의 문제가 발생할 수 있다.
시스템이 복잡함
DBMS는 시스템이 꽤나 복잡하다. 대표적으로 우리는 MySQL이나 Oracle을 사용하기 위해 각 시스템에 맞는 Query문을 알고 있어야 한다.
이 때문에 DBMS 전문가를 찾기가 어렵고, 전문가를 채용하기 위한 비용도 높아지기 마련이다.
DBMS 동작 방식
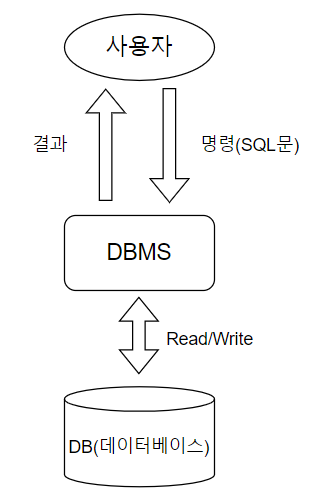
사용자는 DB에서 데이터를 뽑아내기 위한 SQL 구문을 만들어 DBMS 서버에 보낼 것이다.
더 정확히 말하자면 사용자는 WAS에 HTTP Request를 통해 원하는 동작을 보낼 것이고 개발자가 미리 개발해 놓은 로직에 의해 HTTP Request를 충족하기 위한 SQL 구문이 만들어질 것이다.
그리고 이렇게 생성된 SQL 구문이 DBMS 서버에 보내질 것이다.
DBMS 서버는 SQL 구문에 따라 DB에 접근하여 Read/Write 과정을 거쳐 데이터를 DB에 저장하거나 DB에서 데이터를 추출한다.
이후 DBMS는 사용자에게 데이터 처리 상태와 그 결과물을 사용자에게 반환하는 것이다.
DBMS 분류
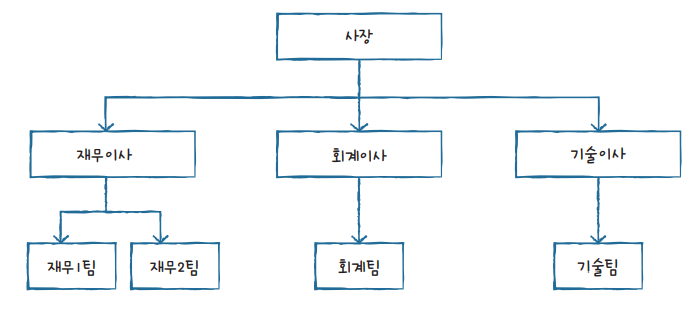
계층형 DBMS
계층형 DBMS(Hierarchical DBMS)는 트리(Tree) 형태를 가지는 DBMS이다.
계층형 DBMS의 경우 처음 구성을 완료한 후 변경하기가 매우 까다롭다는 단점이 있다.
아래 사진을 예로 들어보면 재무 2팀에서 회계팀으로 연결하기 위해선 재무이사 사장 회계이사 회계팀과 같은 단계를 거쳐야 한다.
이런 단점 때문에 현재는 사용되지 않는 형태이다.
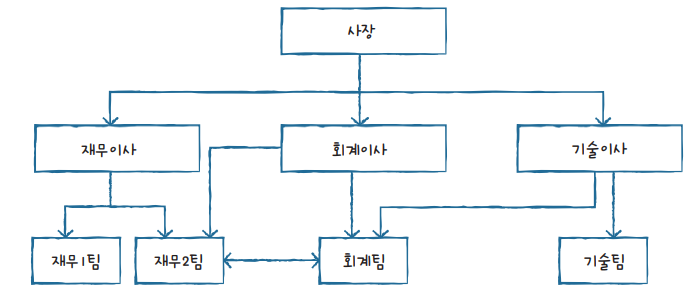
망형 DBMS
계층형 DBMS의 단점을 개선하기 위해 등장한 DBMS이다.
계층형 DBMS와는 다르게 하위에 있는 구성원끼리도 직접 연결되어 있어 굳이 돌아가지 않아도 되는 DBMS 구조를 가진다.
하지만 망형 DBMS를 사용하려면 개발자가 프로젝트 구조를 전부 파악한 뒤 어떤 구성 요소끼리 연결되어 있어야 하는지 미리 파악해 놓아야 한다.
예를 들어 재무 2팀과 회계팀이 직접 연결될 일이 거의 없는데 굳이 연결을 만드는 것은 자원적 낭비이기 때문이다.
이러한 단점 때문에 이 또한 거의 사용되지 않는 형태이다.
RDBMS
RDBMS(Relational Database Management System)은 관계형 DBMS라고도 부른다.
최근 NoSQL이라는 비관계형 DBMS도 나오긴 했지만 요즘 사용되는 대부분의 DBMS는 RDBMS라고 생각하면 된다.
RDBMS는 관계형 데이터베이스를 생성하고 이를 통해 데이터를 갱신/관리하는 시스템을 의미한다.
RDBMS는 Client-Server 구조를 가지는데 클라이언트가 SQL로 요청을 보내면 서버가 이를 받아 SQL 구문의 규칙에 따라 처리해 주는 구조를 의미한다.
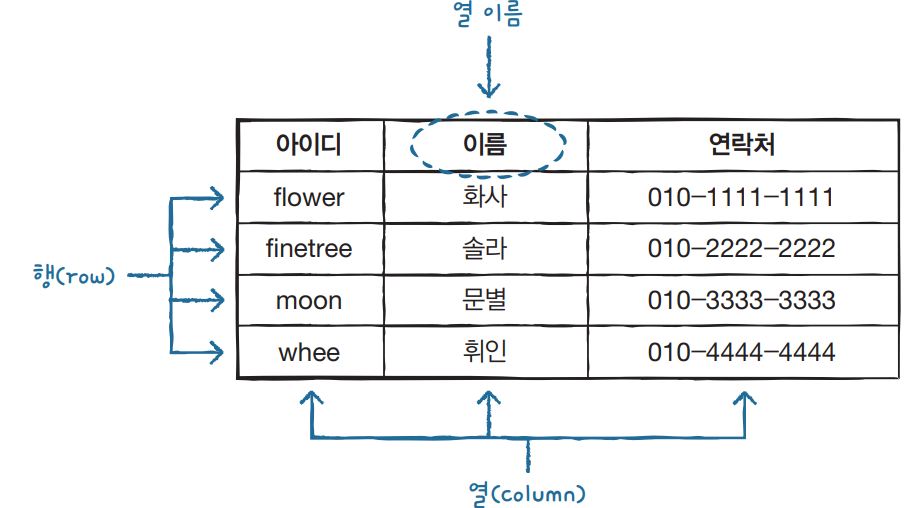
RDBMS의 행에 저장되는 데이터를 "레코드(Record)"라고 하는데 RDBMS는 이 레코드 단위로 데이터를 Read/Write 한다.
"RDBMS는 행과 열로 구성된 테이블로 이루어져 있으며, 테이블 행 단위로 데이터를 관리하는 DBMS이다" 정도로만 알고 있어도 RDBMS를 잘 이해했다고 할 수 있을 것이다.
RDBMS의 종류는 아래와 같다.
| DBMS | 제작사 | 특징 |
|---|---|---|
| MySQL | Oracle | 오픈 소스(무료) |
| MariaDB | MariaDB | Oracle이 MySQL을 인수하며 이에 반발한 MySQL 초기 개발자들이 독립해서 만든 DBMS. 오픈 소스(무료) |
| PostgreSQL | PostgreSQL | 오픈 소스(무료). 객체지향 RDBMS |
| Oracle | Oracle | 상용 시장 점유율 1위로 신뢰성과 안정성이 높은 대규모 애플리케이션 |
| SQL Server | Microsoft | MS사에서 개발했으며 주로 중/대형급 시장에서 활용 |
| SQLite | SQLite | DB를 서버가 아닌 파일로 저장하는 DBMS로 가벼운 DB이기 때문에 모바일 환경에서 많이 활용 |
NoSQL
NoSQL을 DBMS 분류 섹션에 넣는 것이 맞나 고민되었으나 최근에 매우 뜨거운 DBMS이기 때문에 추가하였다.
NoSQL은 "Not Only SQL"의 약자로써 SQL만을 사용하지 않는 DBMS를 의미한다.
NoSQL이라고 하니 SQL을 하나도 사용하지 않는다고 생각하는 사람들도 있는데, RDBMS를 사용하지 않는 것이 아닌 여러 유형의 DB를 사용하는 것이 더욱 맞는 개념이다.
사실 NoSQL은 아직까지도 그 개념이 모호하다.
실제로 NoSQL에 내려진 구체적인 정의는 아직도 없으며, 단지 NoSQL이라고 부리는 DB들은 몇 가지 공통적인 성향이 존재한다는 정도이다.
- SQL을 사용하지 않는 Schema-less 데이터베이스
- 21세기 초반 웹 환경의 필요에 기초를 두고 있어 이 시기에 개발된 시스템만을 NoSQL이라고 부름
- 클러스터에서 실행할 목적으로 만들어졌기 때문에 관계형 모델을 사용하지 않음
NoSQL이 등장하게 된 이유는 21세기가 되며 RDBMS의 한계를 느꼈기 때문이다.
RDBMS를 사용하는 가장 큰 이유는 트랜잭션을 통한 안정적인 데이터 관리가 가능하기 때문이다.
문제는 웹 2.0 환경에 도달하고 빅데이터라는 DBMS에서 처리하기 힘든 대용량 데이터가 등장하며 데이터를 처리하는 데 필요한 비용이 증가했다는 한계점이 나타나기 시작했다.
웹 2.0 환경이 되며 사람들은 모바일 환경 등을 통해 더욱 많은 데이터를 웹 환경에 내보내게 되었고, 이 때문에 데이터와 트래픽의 양이 기하급수적으로 증가했다.
결국 기존 하드웨어로는 데이터를 모두 저장할 수 없게 되었고 Scale-up을 통해 장비의 성능을 높여야 했는데 비용이 만만치가 않았다.
NoSQL은 이런 비용적 문제를 해결하기 위해 데이터의 일관성을 약간 포기한 대신 Scale-out으로 데이터를 여러 대의 컴퓨터에 분산하여 저장하는 것을 목표로 등장했다.
NoSQL의 등장으로 작고 값싼 장비 여러 대로 대량의 데이터와 컴퓨팅 부하를 처리할 수 있게 되었다.
NoSQL은 매우 복잡한 개념이기 때문에 자세히 설명하려면 한 섹션을 잡고 설명해야 할 것이다. 따라서 일단 지금은 여기까지만 설명하도록 하겠다.
SQL
SQL이란 RDBMS에 저장된 데이터와 통신하기 위해 사용되는 DB 전용 프로그래밍 언어라고 생각하면 된다.
DBMS 제품마다 SQL 규칙이 살짝씩 다르지만 표준 SQL이라는 공통적으로 적용할 수 있는 문법이 존재하며 DBMS 별로 다른 문법들은 "방언(Dialect)"라고 부른다.Linux를 설명하며 SQL에 대해 설명하고 싶지는 않았지만 DBMS를 알기 위해선 SQL에 대해서도 어느 정도 파악해야 하므로 간단하게 설명하도록 하겠다.
SQL 명령어 종류
DDL(Data Definition Language)
- 데이터베이스 스키마 처리 명령
- 테이블 생성/변경/삭제 등의 작업을 수행할 때 사용함
DDL 명령문
- CREATE
- ALTER
- DROP
- TRUNCATE
- COMMENT
- RENAME
DML(Data Manipulation Langugae)
- 데이터 검색, 삽입, 변경, 삭제 등을 수행할 때 사용하는 구문
- 테이블에 저장된 데이터를 처리하거나 테이블에 데이터를 저장하기 위한 구문으로 실직적으로 가장 많이 활용되는 SQL 구문
DML 명령문
- SELECT
- INSERT
- UPDATE
- DELETE
- 주로 위 4개를 많이 활용함
- MERGE, CALL, EXPLAIN PLAN, LOCK TABLE
DCL(Data Control Language)
- 데이터에 접근할 수 있는 권한을 관리하기 위한 구문
DCL 명령문
- GRANT
- REVOKE
TCL(Transaction Control Language)
- 트랜잭션을 다루기 위한 구문
TCL 명령문
- COMMIT
- ROLLBACK
- SAVEPOINT
- SET TRANSACTION
SQL 데이터 타입
문자형 데이터 타입(String)
- CHAR(n) : 고정 길이 데이터 타입
- n보다 짧은 데이터가 입력될 시 나머지 공간은 공백으로 채워짐
- VARCHAR(n) : 가변 길이 데이터 타입
- 지정된 길이보다 짧은 문자열 입력 시 나머지 공간을 채우지 않음
- TINYTEXT(n), TEXT(n), MEDIUMTEXT(n), LONGTEXT(n)
- 저장할 수 있는 최대 Byte수가 다를 뿐 모두 문자열 데이터 타입
숫자형 데이터 타입(Numeric)
- TINYINT(n) : 정수형 데이터 타입(1 byte)
- True/False를 저장할 때 자주 활용됨
- INT(n) : 정수형 데이터 타입(4 byte)
- BIGINT(n) : 정수형 데이터 타입(8 byte)
- DOUBLE(n,m) : 부동 소수형 데이터 타입(8 byte)
- 소수점 m자리 숫자까지 표현
- 저장되는 수의 개수는 소수점 아래 수까지 표현하여 총 n개 존재해야 함
- (ex) DOUBLE(2,3)에 2.334를 저장할 경우 2.3이 저장됨(총 2개의 숫자가 존재해야 하므로)
날짜형 데이터 타입(Date/Time)
- DATE : 날짜(연/월/일) 형태로 날짜 저장
- TIME : 시간(시/분/초) 형태로 시간 저장
- DATETIME : 날짜와 시간을 합친 형태로 데이터 저장
- TIMESTAMP : 날짜와 시간 형태의 기간 표현 데이터 타입
- TIMESTAMP는 DATETIME보다 더욱 정밀한 시간을 저장하고 싶을 떄 사용
- 우선순위를 저장하거나 ms(밀리세컨드) 이하까지 표현하기 위해 사용
이진 데이터 타입
- BLOB(n)
- BINARY(n) : CHAR 형태의 이진 데이터 타입
- BYTE(n) : CHAR 형태의 이진 데이터 타입
- VARBINARY(n) : VARCHAR 형태의 이진 데이터 타입
꼭 알아둬야 할 SQL 구문
DDL - Database
SHOW DATABSES: DB 이름 조회USE [DB 이름]: 기록한 이름을 가진 DB의 Table을 사용하기 위해 먼저 입력해야 함CREATE DATABASE [DB 이름]: DB 생성DROP DATABASE [DB 이름]: DB 삭제
DDL - Table
-
SHOW TABLES: 테이블 이름 조회 -
EXPLAIN [Table 이름]: 테이블 구조(형태) 조회 -
CREATE TABLE [테이블 이름](필드명 자료형, [필드명 자료형], ...)- (ex)
CREATE TABLE customer(id CHAR(10), name VARCHAR(10), age INT, ADDRESS VARCHAR(30)); - 소괄호 안에 [필드 이름 + 저장할 데이터 타입] 형태를 이어붙여 저장한다.
- (ex)
-
DROP TABLE [테이블 이름]: 테이블 삭제 -
테이블 수정
ALTER TABLE [테이블 이름] MODIFY 필드명 데이터타입: 테이블의 데이터 타입 변경- (ex)
ALTER TABLE customer MODIFY name CHAR(20);
- (ex)
ALTER TABLE [테이블 이름] CHANGE 기존필드명 변경할필드명 데이터타입: 테이블의 필드명과 데이터 타입 모두 변경- (ex)
ALTER TABLE customer CHANGE name fullname CHAR(10);
- (ex)
ALTER TABLE [테이블 이름] ADD 필드명 데이터타입 AFTER 존재하는필드명: 존재하는 필드명 다음 열에 필드 하나를 추가함- (ex)
ALTER TABLE customer ADD phone VARCHAR(20) AFTER name;
- (ex)
ALTER TABLE [테이블 이름] DROP 필드명: 필드를 삭제함- (ex)
ALTER TABLE customer DROP age;
- (ex)
DML - 레코드 삽입/삭제/수정
-
INSERT INTO [테이블 이름] VALUES('값1', '값2', ...): 레코드 삽입- (ex)
INSERT INTO customer VALUES( ‘hong’ , ‘홍길동’ , 22, ‘경기’); - 이 때 TABLE 데이터의 필드 순서대로 값을 입력해야 하며, 만약 순서를 외우기 힘들다면 [테이블 이름](필드명1, 필드명2, ...)처럼 필드 순서를 지정해줘도 된다.
- (ex)
INSERT INTO customer(성, 이름, 나이, 거주지) VALUES( ‘홍’ , ‘길동’ , 22, ‘경기’);
- (ex)
-
DELETE FROM [테이블 이름] WHERE [삭제할 Record 조건]: 레코드 삭제- (ex)
DELETE FROM customer WHERE id=‘hong’;
- (ex)
-
UPDATE [테이블 이름] [변경할 필드]=[변경할 값] WHERE [변경할 Record 조건]: 레코드 수정- (ex)
UPDATE customer age=25 WHERE id=‘hong’;
- (ex)
DML - 테이블 조회
SELECT [확인할 필드 리스트] FROM [테이블 이름] WHERE [조건]- (ex1)
SELECT * FROM customer;: 테이블의 모든 데이터 확인 - (ex2)
SELECT id, name FROM customer WHERE age > 25;
- (ex1)
Linux에서 MariaDB 설정
이전에 웹 서버 및 WAS를 설치 및 설정하며 MariaDB는 이미 설치했으므로 바로 설정 과정으로 넘어가자.
MariaDB 관련 설정은 Root 계정으로 수행하는 것을 추천한다.
1. MariaDB 최초 설정
mysql_secure_installationroot 계정 비밀번호를 물어볼 텐데 처음에는 초기 비밀번호가 없으므로 그냥 엔터를 입력하면 된다.
이후에 물어볼 것은 질문을 읽어보고 원하는 설정에 따라 Y나 n을 입력하면 된다.
참고로 필자는 "Remove test database and access to it" 질문을 제외하고는 모두 Y를 눌렀다.
질문의 내용과 그 순서는 아래와 같다.
- root 패스워드를 설정할 것인가?
- root 접근을 서버 외부에서 허용시킬 것인가?
- 원격 로그인을 허가할 것인가?
- 데이터베이스에 기본적으로 저장되어 있는 Test DB를 삭제시킬 것인가?
- 설정을 지금 바로 적용시킬 것인가?
2. Chracter Set & collaction 설정
설정 방법에 대해 알기 전 Character Set과 Collaction(정렬)에 대해 먼저 알아보자.
- Character Set
- "utf8" : 글자당 최대 3 Byte 지원
- "utf8mb4" : 글자당 최대 4 Byte 지원
- 이모지(Emoji)가 1 글자당 4Byte이므로 이모지 표현을 위해서는 utf8mb4로 설정해야 한다.
- Collaction : DB에서 문자열의 정렬 기준
- "utf8mb4_general_ci" : 기본값. 정렬 속도는 빠르지만 비라틴계 언어의 정렬에서는 어색함이 존재함
- "utf8mb4_unicode_ci" : 비라틴계 언어의 정렬에서도 어색함이 존재하지 않으므로 특히 한국어를 저장할 DB의 경우 utf8mb4_unicode_ci를 사용하는 것이 좋다.
- general_ci와 unicode_ci는 대소문자를 구분하지 않으므로 "A"와 "a"를 동일한 값으로 취급한다. 이런 점 때문에 Duplicate Primary Key 에러가 발생하는 것을 주의하자.
이제는 MariaDB 설정을 변경하여 Table 및 필드를 생성할 때 Default characte set을 "utf8"로, collaction을 "utf8_unicode_ci"로 설정해 보자.
일단 mariadb를 콘솔 창에 입력한 뒤 show variables like 'c%';를 입력하면 아래와 같이 설정되었음을 확인할 수 있다.
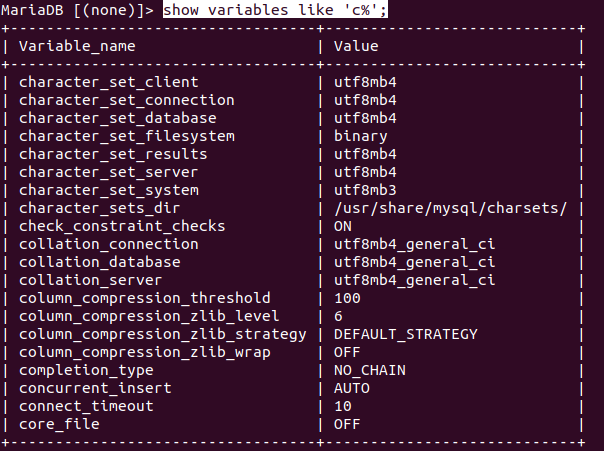
여기에서 "utf8mb4"를 "utf8"로, "utf8mb4_general_ci"를 "utf8_unicode_ci"로 바꿀 것이다.
# MariaDB 설정 파일이 저장된 디렉터리로 이동
cd /etc/mysql/mariadb.conf.d
# MariaDB 설정 파일 수정
vi 50-server.cnf90, 91번째 줄에 기입되어 있는 "character-set-server"와 "collaction-server"를 아래와 같이 변경시키자.
90 character-set-server = utf8
91 collation-server = utf8_unicode_ci
이후 service mariadb restart로 MySQL을 재시작한 뒤 다시 show variables like 'c%';로 설정을 확인해보면 성공적으로 Collaction 및 Character Set이 변경되었음을 확인할 수 있다.
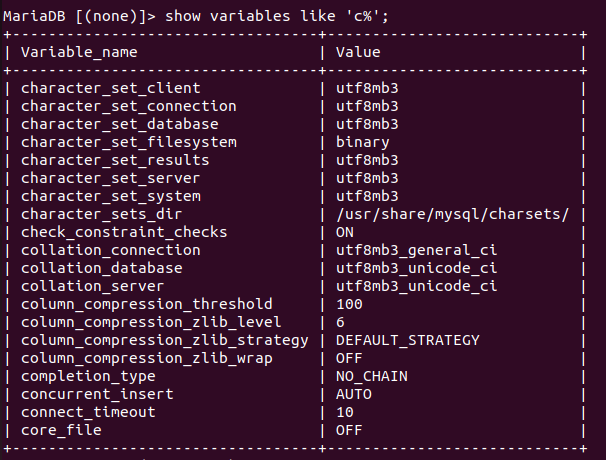
utf8는 3 Byte를 사용하는 UTF8이라는 의미로 utf8mb3라는 별칭을 가진다. 즉, 정상적으로 설정이 변경되었음을 확인할 수 있다.
추가로 50-server.cnf를 통해 아래와 같은 설정을 수행할 수 있다.
- auto commit
- 기본 : on(True)
- INSERT, UPDATE, DELETE 구문을 COMMIT 없이 바로 적용
- 50-server.cnf에 아래 내용을 추가하여 설정할 수 있다.
... [mysqld] autocommit=0 ... - Transaction isolation
- READ-UNCOMMITED : 다른 트랜잭션에서 commit하지 않은 데이터까지 보임
- READ-COMMITED : 다른 트랜잭션에서 commit한 데이터만 보임
- REPEATABLE-READ : 다른 트랜잭션의 commit 여부와 관계 없이 트랜잭션이 접속한 시점의 데이터만 보임
- SERIALIZBLE : 현재 트랜잭션에서 작업중인 모든 데이터에 LOCK 발생
- 50-server.cnf에 아래 내용을 추가하여 설정할 수 있다.
- 참고로 50-server.cnf의 9번째 줄에 [mysqld] 영역이 존재한다.
... [mysqld] transaction-isolation=READ-COMMITTED ...
3. 방화벽 열어주기
# 모든 사용자에게 mysql에 대한 방화벽을 열어줌
firewall-cmd --permanent --add-service=mysql
# 방화벽 설정 적용
firewall-cmd --reload4. 접근 권한 부여
DB는 데이터를 저장하는 만큼 민감 데이터 또한 저장하고 있다.
이런 상황에서 모든 사용자에게 (물론 Username과 패스워드를 알아야겠지만) DB에 접근하도록 허용하는 것은 매우 위험한 일이다.
따라서 DB는 2가지 설정을 더 해야지만 원격에서 DBMS에 접근할 수 있게 된다.
4-1. bind-address 값 변경
/etc/mysql/mariadb.conf.d/50-server.cnf 파일에 27번째 줄을 보면 bind-address = 127.0.0.1로 설정되어 있을 것이다.
이 127.0.0.1을 0.0.0.0으로 변경하여 리눅스 서버 외부에서도 DBMS에 접근할 수 있도록 설정을 바꿔줘야 한다.
27 bind-address = 0.0.0.0 4-2. MariaDB 자체에서 접근 가능하도록 설정
DBMS 설정으로 외부에서 접근 가능하도록 했지만 아직도 MariaDB 보안상 IP 허용이 되지는 않은 상태이다.
따라서 mariadb로 들어가 SQL 콘솔 창으로 들어간 뒤 아래 명령어를 통해 특정 IP에 접근 권한을 부여해 줘야 한다.
GRANT ALL PRIVILEGES ON *.* TO 'root'@'[IP 주소]' IDENTIFIED BY '[Password]';이는 특정 IP 주소에 Username : root, Password : [Password]를 입력하면 접근 가능하도록 권한을 부여해 주는 Query문이다.
이렇게 MariaDB 측에서도 IP 주소에 대한 접근 권한을 부여해 줘야지만 외부에서 DBMS에 접근이 가능해진다.
참고로 %를 IP 주소 부분에 입력함으로써 IP 대역대나(ex. 1.2.3.%) 모든 IP 주소(%)에 접속을 허용할 수도 있다.
4. DB 접속
여기까지 설정했다면 Windows에서는 "Datagrip"이나 "HeidiSQL" 같은 SQL 접속 툴을 활용하여 생성한 DB에 접근할 수 있다.
Hostname은 리눅스 서버의 IP 주소, Username과 암호는 root 계정 및 설정한 패스워드로 입력한 뒤 접근해 보자.
(따로 설정하지 않았다면 기본 DB 포트인 3306으로 접근하면 된다)
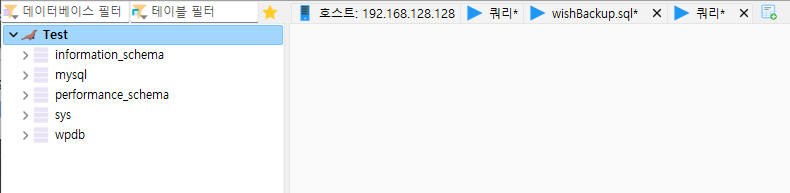
정상적으로 접근했음을 알 수 있다.
IP Address도 리눅스 서버의 IP 주소이고 이전 웹 서버 설정 시 만들었던 "wpdb" 데이터베이스도 존재하는 걸로 리눅스 서버에 설치된 DBMS임을 확인할 수 있다.
