데이터를 DB에 저장하는 방법
영속성(Persistence)
먼저 Persistence라는 용어의 정의부터 알고 가는 것이 좋다.
영속성이란 "데이터를 생성한 프로그램이 종료되더라도 사라지지 않는 데이터의 특성"을 의미한다.
그리고 영구적으로 저장되는 데이터를 "영구적인 객체(Object Persistence)"라고 한다.
예를 들어 A라는 정보를 프로그램 상 저장해 놓았다고 가정하자. 만약 프로그램이 종료되었을 때 이 A라는 정보는 보존될까? 보존되지 않을 것임을 쉽게 예측 수 있다. 하지만 만약 A라는 데이터를 DB에 저장했으면 어떻게 될까? 프로그램이 종료되더라도 A는 DB에 저장되어 있으므로 사라지지 않을 것이며, 이러한 데이터 특성을 "영속성"이라고 하는 것이다.
프로그램은 CRUD(Create, Read, Update, Delete) 방식으로 Data를 DB에 저장하여 활용한다.
Java 프로그램이 데이터베이스에 데이터를 저장하는 방법은 총 3가지가 존재한다.
JDBC, JdbcTemplate 같은 Spring JDBC, 그리고 Persistence Framewkr가 존재한다.
이번 Section에서는 JDBC와 Spring JDBC에 대해 알아보자
JDBC
JDBC란?
JDBC는 자바 프로그램이 DB와 연결되어 데이터를 주고받을 수 있게 해주는 프로그래밍 인터페이스다.
즉, 자바를 이용하여 DB에 접속하고 SQL 문장을 실행하여 데이터를 처리하기 위한 자바 API를 의미한다.
JDBC를 활용하면 JDBC API 측에서 사용하는 DB에 적절한 JDBC 드라이버를 프로그램과 연결하여 별다른 설정 없이 다양한 DB에 대응하는 프로그램을 만들 수 있게 된다.
JDBC를 활용하지 않은 상황에서 MySQL에서 Oracle로 DB를 바꾼다고 가정하자. DB 제품마다 사용법이 다르기 때문에 각각의 DB 제품에 대한 API도 차이가 존재하게 된다. 즉, 개발자는 프로그램 전체를 대상으로 MySQL과 관련된 코드를 Oracle API 관련 코드로써 수정해줘야 한다. 이런 유지보수가 어렵다는 단점 이외에도 수정을 위해선 MySQL과 Oracle에 관련된 API를 모두 익혀야 한다는 난이도 문제도 존재한다.
이런 문제점을 해결하기 위해 나온 해결법이 JDBC이다. DBMS 회사들은 자신의 제품에 맞는 JDBC Driver를 제공하게 되며 JDBC API 측에서는 활용할 DB와 호환이 되는 JDBC Driver를 선택하면 바로 DB와의 연결이 가능하다
아래 사진은 JDBC의 동작 과정을 그림으로 표현한 것이다
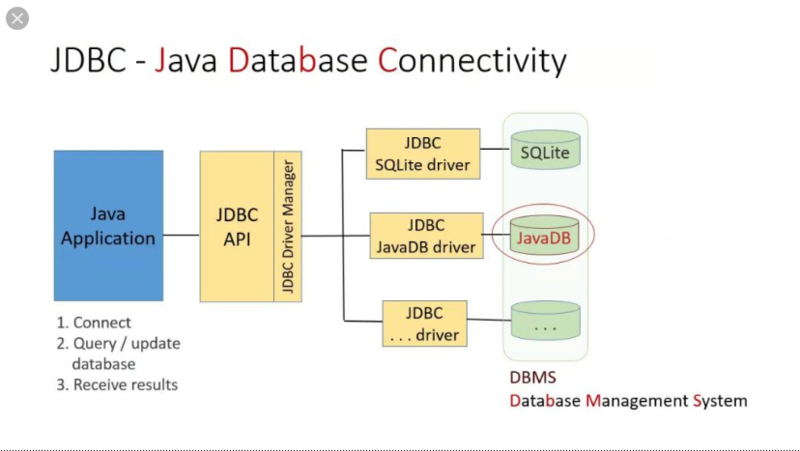
JDBC 애플리케이션이 Query를 JDBC API로 보낸다. 이후 JDBC API 안에 있는 JDBC Driver Manager가 활용할 DB에 맞는 JDBC Driver를 가지고 올 것이다. 이후 JDBC Driver 측에서 애플리케이션 측에서 보낸 Query를 적절히 변형하여 SQL문을 실행하게 될 것이다.
위와 같은 구조를 활용하면 JDBC Driver가 사용할 DB와의 연결 과정을 자동으로 수행해줄 것이며, 개발자는 "어떻게 DB와의 연결을 구현해야 하는가"에 대한 큰 고민을 하지 않고 그저 JDBC API에 어떤 DB를 활용할지만 알려주면 된다.
즉, DBMS를 수정하더라도 프로그램 내에서 코드를 거의 수정하지 않고 바로 활용할 수 있으므로(사용할 DBMS 이름 및 DBMS URL만 변경해주면 됨) 유지보수가 쉬우며 확장성도 뛰어나게 되는 것이다.
JDBC를 활용한 프로그래밍 방법
먼저 이론적인 순서를 설명하면 아래와 같다
- DriverManager를 통해 Connection Instance를 얻어옴
- Connection을 통해 Statement를 얻어옴
- Statement를 통해 ResultSet을 얻고 데이터 처리를 완료함
여기서 사용할 DBMS의 JDBC Driver를 가지고 오는 것은 DriverManager 객체로써, 해당 객체의 메서드를 통해 적절한 JDBC Driver를 가져올 수 있게 된다.
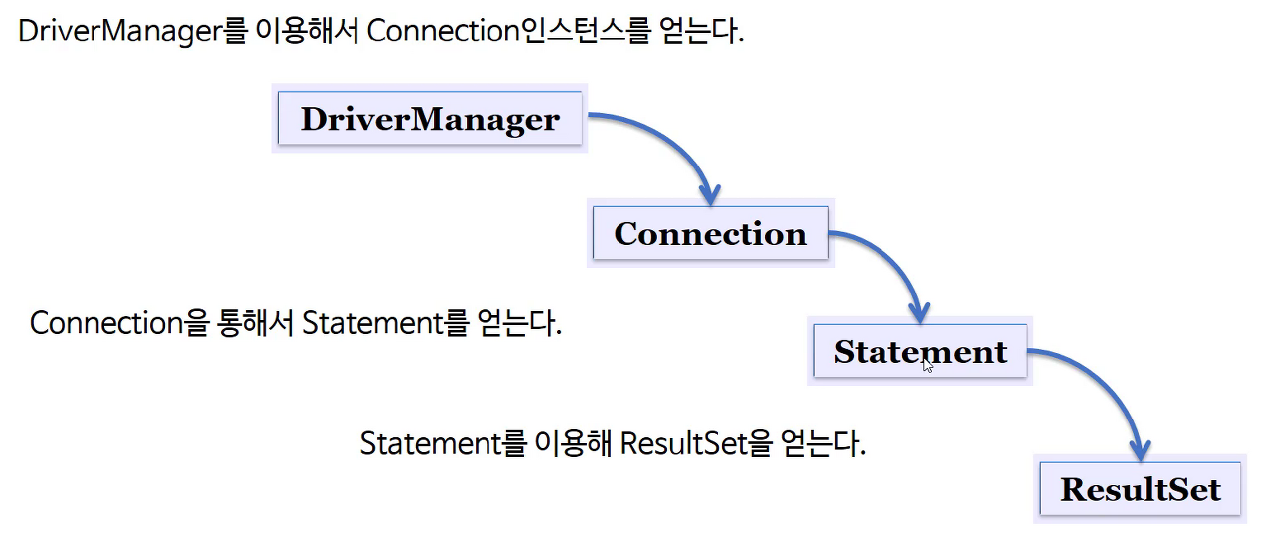
여기서 중요한 점은 JDBC를 활용 때는 생성한 객체를 Close 과정을 통해 연결을 끊어줘야 한다. 이를 "닫는다"라고도 표현한다. 메모리 누수를 위해 꼭 닫는 Close 행위가 이루어져야 하며 순서는 객체 생성과 정확히 반대(즉, ResultSet → Statement → Connection → DriverManger 순서)로 닫아주면 된다.
그렇다면 코드를 통해 JDBC를 활용해보자
1. Import
import java.sql.*;JDBC 요소들을 저장해 놓은 패키지들을 Import 시킨다. 물론, 처음부터 import 시키지 않고 원래 프로젝트를 진행하는 대로 자동 import를 활용해도 된다
2. JDBC Driver Load
Class.forName("com.mysql.jdbc.Driver");DBMS에 맞는 JDBC Driver를 Load 하는 코드이다.
Class.forName 뒤에 활용하고 싶은 DB에 맞는 JDBC Driver 이름을 입력하면 적절한 Driver가 로드된다.
DBMS별 JDBC Driver는 아래와 같다.
- Oralce : oracle.jdbc.driver.OracleDriver
- MySQL : com.mysql.jdbc.Driver
- MariaDB : org.mariadb.jdbc.Driver
이외에도 Sybase, MS-SQL, DB2, UniSQL, Altibase, hsqldb, cubird에 대한 JDBC Driver도 존재하므로 만약 다른 DBMS를 활용할 경우 찾아보길 추천한다.
3. Connection 얻기
Connection conn = null;
String url = "jdbc:mysql://127.0.0.1/studydb";
String username = "root";
String password = "root";
conn = DriverManager.getConnection(url, username, password);DriverManager 객체를 통해 Connection 객체를 얻어오는 과정이다.
이때 DriverManager는 Username, Password와 JDBC URL을 요구한다. 먼저 JDBC URL이란 DB가 있는 IP 주소를 의미한다. 즉, DB가 존재하는 URL을 의미하게 된다. Username과 password는 내가 생성한 Table의 이름 및 패스워드를 의미한다. 위 예시에서는 "root", "root"로 지정했는데 이는 Table을 만들었을 때 기본 설정이다. 만약 내가 Table을 만들 때 이름과 Password를 "root"가 아닌 다른 값으로 설정했다면 해당 설정값을 Username과 Password 값에 입력해주면 된다
이렇게 Connection 객체를 생성하면 이 객체는 내가 활용할 DB에 접속할 수 있는 창구 역할을 해준다.
DBMS URL은 아래와 같다
- Oracle : jdbc:oracle:thin:@localhost:1521:DBNAME
- MySQL : jdbc:mysql://localhost:3306/DBNAME?useUnicode=true&characterEncoding=euckr&connectTimeout=5000&socketTimeout=5000
- MariaDB : jdbc:mariadb://localhost:3306/DBNAME
4. Statement 생성 및 Query 적용
//Statement 생성
Statement stmt = conn.createStatement();
//질의 수행
int num = 1;
String query = "SELECT name, memo FROM TABLE WHERE name =" + num;
ResultSet rs = stmt.executeQuery(query);
//모든 SQL 구문 실행 가능
stmt.execute("SQL query문 입력");
//SELECT문 실행
stmt.executeQuery("SQL query문 입력");
//Insert,Update,Delete문 실행
stmt.executeUpdate("SQL query문 입력");statement 객체는 Query문을 수행하도록 도와주는 역할을 한다. 즉, "적절한 DBMS"와 연결하는 역할을 JDBC Connection이 수행하고, 이 Connection이 URL을 통해 적절한 JDBC Driver와 연결하게 되는 것이다. 이후 개발자는 statement 객체를 통해 연결된 JDBC Driver를 활용하여 Query를 DB에 적용할 수 있게 되는 것이다
여기에서 PreparedStatemnt라는 개념이 새로 나온다.
먼저 PreparedStatemnt의 사용 방법은 아래와 같다
//Statement가 아닌 PreparedStatement 객체를 생성
PreparedStatement stmt = conn.preparedStatement();
// Query문 Template 생성 및 Template에 값 적용
String query = "SELECT name, memo FROM TABLE WHERE num = ?"
stmt.setInt(1, num);
// Query 적용
ResultSet rst = stmt.executeQuery(query);
// 참고로, 이 때도 PreparedStatement처럼 execute(), executeQuery(), executeUpdate() 사용이 가능함여기서 setInt는 아래와 같은 의미를 가진다
setInt("몇 번째 ? 위치에 넣을 값인가", "어떤 값을 넣을 것인가")
// 사용 방법
// 1. ? 위치는 1부터 시작한다.
// 2. setInt 뿐만이 아닌 setString 등 여러 Type의 데이터를 넣을 수 있음
Query문 예시 : INSERT INTO table VALUES(?,?)
// setString(1, name), setInt(2, level)을 통해 Int형 데이터인 level을 2번째 ?에, String형 데이터인
// name을 1번째 ?에 대입하여 VALUES("푸린", 2) 등으로 Query문을 생성할 수 있음그렇다면 PreparedStatement와 Statement의 차이는 무엇일까?
간단히 말하자면 "캐시 사용 여부"이다.
SQL을 실행하는 단계는 "SQL 문장 분석 → 컴파일 → 실행"이다. 그런데 Statement를 활용하면 이 모든 과정이 수행되게 되어 너무나 많은 비용적 손실이 생기는 것이다. 그래서 PreparedStatment는 "공통된 SQL 구문"을 미리 컴파일시켜 캐싱을 수행하는 것이다.
이렇게 할 경우 Compile이 미리 되어있으므로 좋은 성능을 지니며, 특수문장을 자동으로 Parsing 해주므로 SQL Injection 등의 공격에 강해진다.
위 예시를 통해 알아보자.
내가 실행시키고 싶은 Query문은 SELECT name, memo FROM TABLE WHERE {원하는 Number}이다.
statement구문에서는 "SELECT name, memo FROM TABLE WHERE num = "+num으로 처리함을 볼 수 있다.
이 경우 먼저 문자열에 num 매개변수에 저장된 값을 합해 최종적인 문자열을 만들어야 한다. 그리고 이렇게 만들어진 최종적인 문자열을 Compile 하여 프로그램이 알아들을 수 있는 저급 언어로 번역하는 과정이 수행되어야 할 것이다. 그런데 이렇게 하면 몇 가지 문제가 생긴다.
먼저, 변경되는 부분은 별로 없는데 일부분 때문에 문자열 하나를 계속 Compile 하여야 한다는 것이다.
실제로 Query문에서 값이 바뀌는 부분은 num에 저장된 값일 뿐 앞의 Query문은 변하지 않는다. 그런데 뒤의 num이 바뀔 수도 있다는 이유 하나로 전체 문자열을 계속해서 Compile하여 처리해야 한다는 말이다. 시간 낭비가 엄청날 것이다.
두 번째로 그나마 num이 숫자라면 괜찮지만 "문자형" Type이라고 가정하자.
이 경우 num에 "SQL 구문"을 추가할 수도 있게 되는 것이다. 만약 입력 값으로 SQL 구문이 들어온다면 해당 구문까지 합쳐 전체 SQL 구문을 실행시킬 것이고, 보안상 문제가 발생할 수도 있는 것이다.(이런 공격 방법을 SQL Injection이라고 한다). 만약 num에 "1, name = '홍길동'"이라는 값이 들어왔다면 나는 num = 1인 사람만 찾고 싶었는데 SQL의 입력문을 통해 새로운 조건이 추가되어 "num = 1이고 홍길동이 이름인" 사람을 찾게 되는 것이다. 그나마 예시가 보안상 문제를 일으키는 것은 아니었으나, SQL 구문을 통해 보안상 문제를 일으킬만한 구문을 입력해버리면 엄청난 보안 이슈가 발생하는 것이다
PreparedStatement는 이런 문제에서 어느 정도 자유롭다.
PreparedStatment는 "SELECT name, memo FROM TABLE WHERE num = " 자체를 Compile 하여 캐싱한다. 즉, 바뀌지 않는 Query 부분은 컴파일하고, 해당 Query 부분은 더 이상 바뀔 이유가 없으므로 캐싱을 통해 다시 컴파일하는 과정을 없앤 것이다.
또한 PreparedStatement는 입력값에 대한 검증을 해주므로, 만약 입력값이 SQL Injection을 일으킬 수 있는 보안상 문제가 발생할 수 있는 입력값일 경우 자동으로 코드 수행을 막는다.
그래서 특히 "사용자 입력값으로 Query문을 실행하는 Case", "Query를 반복해서 수행해야 하는 Case"에서는 PreparedStatement를 사용하는 것이 DB에 훨씬 적은 부하를 주고 좋은 성능을 내며 보안적으로도 안전해진다.
execute(), executeQuery(), executeUpdate()
execute() 메서드를 활용하면 INSERT, UPDATE, SELECT 등 모든 SQL 구문을 실행시킬 수 있다. 그렇다면 왜 굳이 Case를 나눠 놓은 것일까?
바로 각각의 메서드마다 "반환시키는 값"이 차이가 있기 때문이다.
먼저 execute()는 Query를 "실행"만 시킨다. 즉 결괏값을 반환하지 않으며, Query가 제대로 적용되었는지 혹은 Query의 결괏값이 무엇인지 확인할 방법이 없다. 따라서 거의 활용하지 않는 메서드이다
executeUpdate()는 테이블에 영향을 준 행 개수를 반환한다.
아까 executeUpdate()는 "INSERT, UPDATE, DELETE문"을 실행시킨다고 말하였다. 즉, DB Table에 영향을 끼치는 Query문을 실행시키는 명령인 것이다. 이에 따라 executeUpdate()를 통해 기존 Table에서 변경된 부분이 있을 것이며 이렇게 변경된 행 개수를 반환하게 되는 것이다
executeQuery()는 "ResultSet"을 반환한다.
ResultSet이란 DB에 존재하는 데이터를 Java에서 처리할 수 있도록 변환하여 가지고 온 형태이다. executeQuery()는 위에서 말했듯 "SEARCH" Query문에 주로 활용되는 메서드이다. 즉, executeQuery()는 "Search 명령을 통해 DB에서 찾은 결과물"들을 활용하기 위해 많이 활용되며, 이를 위해 ResultSet을 반환하게 된다.
5. ResultSet으로 결과받기(executeQuery 메서드를 사용하는 Case에만 해당)
ResultSet rs = stmt.executeQuery("select no from user");
while(rs.next())
System.out.println(rs.getInt("no"));
Query를 통해 데이터에 대한 결과를 얻어왔을 때 이 결과는 DB 쪽에 존재한다. DB쪽에 존재하는 데이터를 ResultSet 형태로 DB에서 받아와 프로그램에서 처리할 수 있게 되는 것이다.주의할 점은 ResultSet을 확인하기 위해선 꼭 "rs.netxt()" 명령이 한 번 수행되어야 하며, "rs.next()" 명령을 수행하면 "현재 확인했던 결과의 다음 결과"를 확인할 수 있게 되는 것이다.
말이 좀 어려우니 예시를 들어보자.우리가 DB Query를 통해 "1", "2", "3"이라는 값을 얻어왔고, 이를 ResultSet에 저장했다고 가정하자. 이 "1", "2", "3"이라는 값을 사용하기 위해선 어떻게 해야 할까?현재 ResultSet을 가리키는 포인터는 "1" 이전의 장소, 즉 빈 공간을 가리키고 있다. 아직 ResultSet을 활용하기 전이라는 것을 알리는 것이다."rs.next()"를 수행하면 포인터는 그제야 ResultSet에 저장된 첫 번째 값인 1을 가리키게 된다. 여기서 중요한 점은 "rs.next()"를 통해 어디까지나 "포인터가 첫번째 값을 가리킨다"이지 첫 번째 값을 반환하지는 않는다. 따라서 rs.getInt나 rs.getString 등으로 포인터가 가리키는 값을 반환하는 메서드까지 추가해야 할 필요가 이다.이후 "rs.next()" 명령을 수행하면 "1" 다음에 있는 "2"를, 한 번 더 수행하면 "2" 다음의 "3"을 가리키게 될 것이다.마지막으로 "3"을 가리킬 때 "rs.next()" 명령이 수행되면 다음 결괏값이 존재하지 않으므로 포인터가 가리킬 값이 없게 된다. 이 경우 rs.next() 메서드는 False 값을 반환하게 된다.
위 내용을 간단히 정리하면 아래와 같다.
- rs.next()ResultSet은 Search문 등을 통해 DB에서 여러 줄의 결괏값을 얻어오게 되며, 이를 Java에서 활용할 수 있도록 변환한 객체이다.rs.next() 메서드를 통해 ResultSet에서 "이전에 확인했던 Row의 다음 Row"를 가리키게 된다.그리고 해당 Row에 데이터가 존재한다면(이전에 확인했던 Row의 다음 Row에 데이터가 존재한다면) True를, 아닐 경우 False를 반환하게 된다.
- rs.getInt()먼저 rs.getInt(), rs.getString()을 통해 데이터 형식에 맞는 데이터를 뽑아올 수 있다.DB는 여러 가지 Column을 가지고 있으며 이 중에서 "데이터 형식과 일치하는 Column 값"을 반환하게 되는 것이다이때 rs.getInt(Column열 숫자)로 입력할 수도 있으며 rs.getInt("Column 이름")로도 입력할 수 있다.
예를 들어 rs.getInt(1)을 입력하면 "첫 번째 Column에 저장된 값"을 반환하는 명령이 되며, rs.getInt("Name")을 입력하면 "Column명이 Name인 Column에 저장된 값"을 반환하는 명령이 되는 것이다
개인적으로는 Column 숫자를 입력해버리면 DB 구조를 계속 외워놓고 있으면서 코딩을 해야 하기 때문에 귀찮고 실수가 발생할 확률도 커진다고 생각한다. 따라서, 정말 큰 이유가 없다면 "Column 이름"을 활용하는 것을 추천한다
6. Close
rs.close();
stmt.close();
con.close();열어 준 모든 객체를 반드시 "거꾸로" 닫아준다. 생성 순서는 "Connection → Statement → ResultSet" 객체 순서이다. 닫는 행위는 반대이기 때문에 위 코드처럼 "ResultSet → Statement → Connection" 순서로 닫아줘야 한다.
Close를 거치지 않으면 발생하는 문제
불필요한 자원(네트워크 및 메모리) 낭비
Connection Pool의 Connection 부족 문제 발생
DB를 활용할 때마다 연결 과정을 수행하면 너무나 많은 시간이 소요되므로 "DB Pool"이라는 것을 활용한다.
DB Pool이란 큰 메모리 공간(Pool)에 이미 선언되어 있는 여러 Connection 객체를 저장하고 있는 상황에서 DB Connection Pool은 DBMS에 요청이 올 경우 Pool에 존재하는 Connection 객체 중 한 개를 Client에게 주는 흐름으로 Connection을 관리하는 방법을 말한다. 그리고 이 과정은 JDBC API 측에서 Connection 객체를 생성할 때 발생한다.
문제는 Close를 수행하지 않으면 Client는 Pool에서 받은 Connection 객체를 다시 Pool에 반환하지 않으며, Connection Pool에서 보유한 Connection 객체가 점차 줄어들어 다른 유저가 DB를 활용할 수 없을 수도 있다.
DB 활용 불가
Statement를 너무 많이 만들어 놓으면 애플리케이션 측에서 Statement를 더 이상 생성하지 못하는 상황이 발생하기 때문에 어느 순간부터 DB를 활용할 수 없을 수도 있다.
이 Close 과정은 이와 같은 이유로 꼭 수행되어야 하는데, 이때 "에러의 발생 유무는 관계없이" 발생되어야 한다.
따라서, try ~ finally 구문을 많이 활용하게 되며 예외처리를 통해 Close 과정을 거치는데, 코드는 아래와 같다
Connection conn = null;
try{
// JDBC API를 활용한 핵심 로직
} finally {
if(rs != null) try { rs.close();} catch(SQLException ex) {}
if(stmt != null) try { stmt.close();} catch(SQLException ex) {}
if(conn != null) try { conn.close();} catch(SQLException ex) {}
}ResultSet, Statement, Connection의 에러 여부도 다른 객체를 닫는 상황에 영향을 미치면 안 되므로 3개 모두 따로 if문을 통해 Close 과정을 수행하는 것이다
JDBC 특징
1. JDBC는 관계형 데이터베이스 전용
JDBC는 RDBMS 전용이기 때문에 요즘 유명한 NoSQL 데이터베이스와의 연결 방법으로는 활용하지 못한다.
2. JDBC 연결 Cost가 비쌈
Java에서 JDBC를 사용할 경우 DB와의 상호작용 때마다 DB 연결 과정을 수행하도록(DB Connection 객체를 생성하도록) 지시할 것이다. 그런데 DBMS와 연결하는 과정은 매우 비싼 비용이 든다. 따라서 JDBC Pool을 통해 이런 Cost 문제를 해결한다.
3. JDBC는 변하지 않았다
JDBC도 버전이 높아지면서 새로운 기능이 추가된다. 하지만 전체적인 측면으로 봤을 때 JDBC API는 첫 번째 Java 출시 이후 거의 변화되지 않았다.
Java 언어 개발자들이 역호환성을 우선시하는 것과 마찬가지로 JDBC도 역호환성을 매우 중요시 생각하는 것이다.
4. JDBC는 Java Database Connectivity를 나타내지 않는다.
Java Database Connectivity의 약자를 JDBC라고 생각하는 사람도 많다. 물론 JDBC가 하는 일을 봤을 때 이런 의미로 유추하는 것이 충분히 가능하다고 생각한다. 하지만 JDBC는 Sun Microsystems 회사에서 용어를 만들었을 때부터 Java Database Connectivity라는 단어를 명시하지 않았다.
즉, 엄밀히 말하자면 JDBC는 "자바와 다양한 DBMS를 연결해주는 API 그 자체"라고 말하는 것이 더욱 적절한 것이고, 이를 포괄적인 말로 담기 위해 Java Database Connectivity라는 용어라고 간주된 것이다
5. JDBC와 ODBC의 연결
JDBC는 "Java"에 특화된 API라면 ODBC는 프로그래밍 언어 관계없이 모든 응용 프로그램에서 모든 DBMS와 통신할 수 있게 해주는 개방형 Interface이다. 범용성 면에서는 ODBC가 좋겠지만, 자바를 활용한다면 자바를 대상으로 전문적으로 개발된 JDBC가 더 좋은 성능을 가질 것이다.
하지만 JDBC-ODBC 드라이버를 활용한다면 Java 프로그램을 ODBC로도 DBMS에 연결할 수 있게 되는 것이다
Spring JDBC
SpringJDBC는 JDBC를 조금 더 발전시킨 개량형 JDBC라고 생각하면 된다.
JDBC가 수행했던 반복적인 저수준 처리 과정(Connection 연결 객체 생성/종료, Statement 준비/실행 및 종료, ResultSet 처리 및 종료, 예외 처리, 트랜잭션 등)을 개발자가 직접 코딩하지 않고 Spring Framework에서 수행하도록 위임함으로써 개발자는 DB Query 및 로직에 대해 더 집중할 수 있게 되는 것이다
Spring JDBC는 JDBC Template 등의 객체를 활용하여 세부적인 작업을 수행한다. 또한 JDBC에는 에러를 모두 Runtime Exception으로 처리하는데 Spring JDBC는 이를 내부적으로 커스텀한 일반 예외(Expection)로 변환해준다
Spring JDBC를 활용하는 것보다는 ORM 활용이 편하며 원리를 알고 싶다면 JDBC 자체를 활용하는 것이 더 좋기 때문에 모호한 기술이라고 생각된다(중간 기술들이 대부분 그렇지만..). 그래서 따로 활용 방법을 기술하지는 않고 넘어가겠다
(물론, 최근에는 JDBC API도 거의 활용하지 않는다)
