Java 8에 추가된 내용 & Java Stream이 강조되는 이유
Java LTS 버전 중 하나인 Java8에 추가된 대표적인 내용은 아래와 같다.
- Lambda(람다) : 마치 함수처럼 코드를 작성하는 함수형 프로그래밍 언어에서 사용되는 개념으로 메서드에 이름이 없어 익명 함수라고도 부름
- Optional : Null이 될 수 있는 객체를 담는 클래스
- 메소드 레퍼런스 : Lambda의 축약 표현. 아래와 같이 사용 가능
- 클래스 이름::메소드 이름
- (예시) list.forEach(System.out::println)
- 생성자::new
- (예시) list.stream().map(Integer::new)
- 클래스 이름::메소드 이름
- Stream : Collection이나 배열에 저장된 요소를 람다식(Lambda Expression)이나 메소드 레퍼런스를 통해 처리할 수 있게 해주는 반복자
위에서 볼 수 있듯 Java Stream은 Java 8부터 추가된 기능이다.
Stream 설명 중 "반복자"라는 단어가 생소할 수도 있지만 개념은 매우 간단하다.
반복자는 Container 내의 원소를 순회하기 위해 사용하는 도구들을 의미한다.
Collection이나 배열에서 데이터를 조회하기 위해 활용한 for each문이나 for(int i =0;i<s.size();i++), Iterator 또한 Container 내 원소를 순회하기 위해 사용한 도구이므로 반복자의 일종이다.
위 설명에서 볼 수 있듯 Java Stream을 통해 Java 8에서 추가된 대표적 기능인 Lambda와 메소드 레퍼런스를 활용할 수 있다.
이런 면에서 생각해볼 때 사실상 Java 8 Update의 핵심은 Java Stream이라 해도 과언이 아니다.
그렇다면 Java Stream 개념에 대해 자세히 알아본 뒤 사용법을 알아보자.
Java Stream 개념
Stream의 사전적 의미는 "흐르다"이다.
Java Stream 또한 이런 의미를 담고 있는데 "데이터의 흐름"이라는 의미를 가지고 있다.
아마 무슨 의미인지 와닿지 않을 테니 이미지 및 간단한 설명을 통해 알아보자.
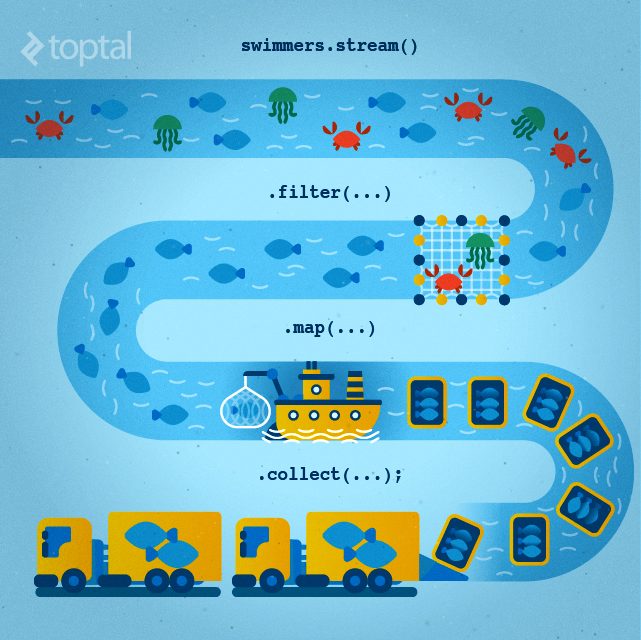
위 사진처럼 swimmers라는 객체가 존재한다고 생각하자. swimmers 객체에는 수많은 데이터(위 사진에서는 물고기, 해파리, 게)가 저장되어 있을 것이다.
swimmers 객체에 저장된 수많은 데이터들은 stream()을 통해 "흐르게" 할 수 있다.
왜 데이터를 흐르게 할까? 바로 데이터를 흐르게 하여 "filter"에 도착할 수 있도록 하기 위해서이다.
filter는 단어에서 직관적으로 알 수 있듯 "데이터를 거르는" 역할을 수행한다.
swimmers라는 객체에는 수많은 데이터가 존재하고 있는데 stream()을 통해 이 데이터들을 Filter로 흐르게 하여 Filter에서 "내가 원하는 데이터"(위 사진에서는 물고기)를 걸러내는 것이다. 이 연산자를 중간 연산자라고 한다.
이렇게 필터로 걸러진 데이터(물고기)들을 개발자에게 반환하기 위하여(소비자에게 팔기 위하여) map 과정을 거쳐야 한다.
map 과정은 걸러진 데이터를 원하는 자료형(규격)으로 변환하는 과정으로써 잡은 물고기를 소비자에게 팔기 위한 규격에 맞춰 상자에 담는 과정과 동일하다.
이 map 연산자 또한 중간 연산자라고 한다.
이렇게 Filter과정과 Map 과정을 통해 내가 원하는 자료형으로 데이터들을 처리했다면 마지막으로 이 데이터들을 개발자에게 반환해야 할 것이다.
이때 처리된 데이터들을 Collection에 저장하여 처리할 수도 있을 것이고 배열에 저장하여 처리할 수도 있을 것이다.
위 사진 예시로 말해보자면 상자에 담긴 물고기들을 냉동차에 쌓아 보낼 수도 있고 냉장차에 쌓아 보낼 수도 있을 것이며 물에다가 생선을 풀어 보낼 수도 있을 것이다.
즉, "어떤 형태로 데이터들을 개발자에게 보내줄 것인가"를 정하는 것이 stream의 마지막 과정인 collect() 과정이며 최종 연산자라고 한다.
Java Stream 특징
Lambda & 메소드 레퍼런스를 통해 요소를 처리
Java Stream이 제공하는 요소 처리 메소드는 함수적 인터페이스 타입이다.
함수적 인터페이스(functional interface)란 추상메서드가 1개만 정의된 인터페이스를 의미하는데, 정의도 중요하지만 Lambda 식을 함수적 인터페이스에 사용할 수 있다는 특징이 더욱 중요하다.
람다식을 실행하면 인터페이스를 구현한 객체가 하나 생성된다. 이때 람다식이 생성한 객체는 이름이 따로 지정되지 않기 때문에 익명 구현체로 생성된다.
이런 특징이 함수적 인터페이스와 결합되면 매우 큰 편의성을 가지고 온다.
람다식을 실행할 경우 생성되는 것은 익명 구현체이므로 만약 추상 메서드가 여러 개인 인터페이스에서 람다식을 활용한다면 익명 구현체가 인터페이스의 여러 메서드 중 어떤 메서드의 구현체로 동작해야 하는지 컴파일러가 알 수 없을 것이다.
하지만 함수적 인터페이스는 추상 메서드가 오직 하나이므로 익명 구현체는 유일하게 존재하는 추상 메서드의 구현체로 사용될 것이다.
즉, 람다식을 실행하면 익명 구현 객체가 생성되고, 함수적 인터페이스에 람다식을 사용할 경우 람다식이 생성한 익명 구현체가 함수적 인터페이스의 추상 메서드 로직을 자동으로 짜주는 것이다.
이렇게 Java Stream을 통해 람다식 및 람다식을 축약해주는 메소드 레퍼런스를 활용할 경우 코드가 매우 간결해지며 복잡한 코드의 가독성을 올려준다는 장점을 가지고 온다.
내부 반복자의 사용
반복자에 대해선 위에서 설명했다. 그렇다면 "내부 반복자"는 무엇일까?
외부 반복자부터 알아보자면 개발자가 코드를 통해 직접 컬렉션 요소에 접근하는 패턴을 의미한다.
우리가 이전까지 요소에 접근하기 위해 활용했던 for문이나 for each문, Iterator 등은 모두 개발자가 함수를 통해 "어떤 데이터에 접근하는지"를 명시해 줬다.
이와는 다르게 내부 반복자는 개발자가 Collection에 요소 처리 코드만 전달할 뿐 Collection 내부에서 모든 데이터를 처리하는 반복자를 의미한다.
말로만 들으면 조금 어려울 수도 있으니 아래 사진을 통해 확실히 이해하자.
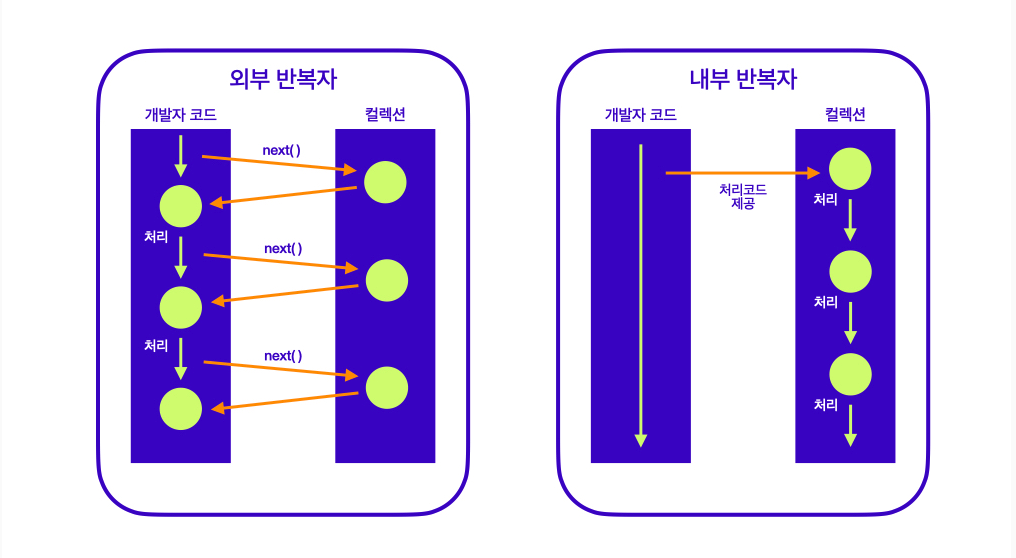
출처 : https://velog.io/@gwichanlee/%EC%8A%A4%ED%8A%B8%EB%A6%BCStream-kb2zjwfq
왼쪽 외부 반복자는 Iterator를 활용한 예시이다.
이미 알고 있듯이 Iterator는 "iterator.next()" 메서드를 통해 현재 Search 한 데이터 다음에 저장된 데이터에 접근할 수 있다.
즉, 개발자는 Collection에서 데이터를 가지고 오고, next() 메서드를 통해 다음 데이터를 가지고 오는 방식으로 계속해서 Collection과 상호작용을 일으키며 데이터를 순회하는 것이다.
하지만 오른쪽 내부 반복자에서는 개발자가 Collection에 처리 코드를 1번 전달 한 이후로 컬렉션과의 어떤 상호작용도 일어나지 않는다.
개발자가 처리 코드를 Collection 측에 전달만 하면 Collection에서 처리 코드를 받아 이를 저장한 모든 요소에 알아서 적용하는 것이다.
내부 컬렉션의 경우 어떻게 전체 데이터를 순회할지에 대한 방법을 신경 쓸 필요가 없으므로 개발자는 Collection에 전달할 요소 처리 코드에만 집중할 수 있다.
또한 내부 반복자는 Collection 내부 요소들의 반복 순서 변경 같은 방법으로 멀티코어 CPU를 최대한 활용해 병렬 작업이 효율적으로 일어날 수 있도록 도와준다. 이를 통해 내부 반복자는 외부 반복자보다 간단하게 병렬처리(multi-threading)가 가능해져 더욱 많은 요소들을 빠르게 처리할 수 있게 된다.
그렇다고 무조건 외부 반복자가 아닌 내부 반복자만 사용해야 한다는 것은 아니다.
외부 반복자는 개발자가 현재 Collection의 어떤 데이터에 접근하고 있는지를 코드 상에서 알 수 있다. 하지만 내부 반복자는 Collection 내부에서 모든 데이터가 처리되기 때문에 현재 어떤 Collection의 데이터가 처리되고 있는지 개발자가 알 수 있는 방법이 없다.
따라서 데이터마다 다른 처리 과정이 필요할 때는 외부 반복자를, 저장되어 있는 모든 데이터에 일괄적인 처리 과정을 적용할 때는 내부 반복자를 사용하는 것이 좋을 것이다.
중간 처리 및 최종 처리가 존재
위에서 설명했듯 Stream에는 중간 연산자와 최종 연산자가 존재한다.
Stream에서는 중간 연산자를 통해 Mapping, Filtering, 정렬 등을 수행할 수 있다.
또한 최종 연산자를 통해 반복, 카운팅, 평균, 총합 등의 집계처리를 수행할 수도 있고 처리된 데이터를 Collection이나 배열형태로 반환받을 수도 있다.
일회용 객체
상당히 중요한 부분이다.
Java Stream 객체는 한 번 사용할 경우 닫히기 때문에 재사용이 불가능하다.
이 때 사용이란 의미는 Stream 객체에 어떤 메서드나 람다식을 적용한다는 의미로써, Stream 객체를 선언하고 선언한 Stream 객체를 아래에 기입만 했다면 무조건 사용이 불가해진다.
따라서 Stream 처리를 수행한 결과물에 한 번 더 Stream 처리를 해주기 위해선 첫 번째 Stream 처리를 한 데이터들을 Collection에 담고 다시 Collection을 stream 객체로 변환하여 Stream 처리를 수행해줘야 하는 것이다.
예시 코드를 통해 알아보자.
List<Integer> list = new ArrayList<>();
for(int i =0;i<10;i++) list.add(i);
Stream<Integer> stream = list.stream();
System.out.println(stream.count());
System.out.println(stream.count());
실제로 첫 번째 stream.count() 명령은 정상적으로 원소 개수인 10을 반환했지만, 두 번째 stream.count()는 "stream has already been operated upon or closed"라는 Stream이 이미 닫혔다는 에러를 발생시키는 것을 볼 수 있다.
