중간 처리 메서드 종류
왜인지는 모르겠는데 티스토리에서 표를 작성하면 깨지는 경우가 있어서 Excel로 표를 만들어 스크린샷을 찍었다.
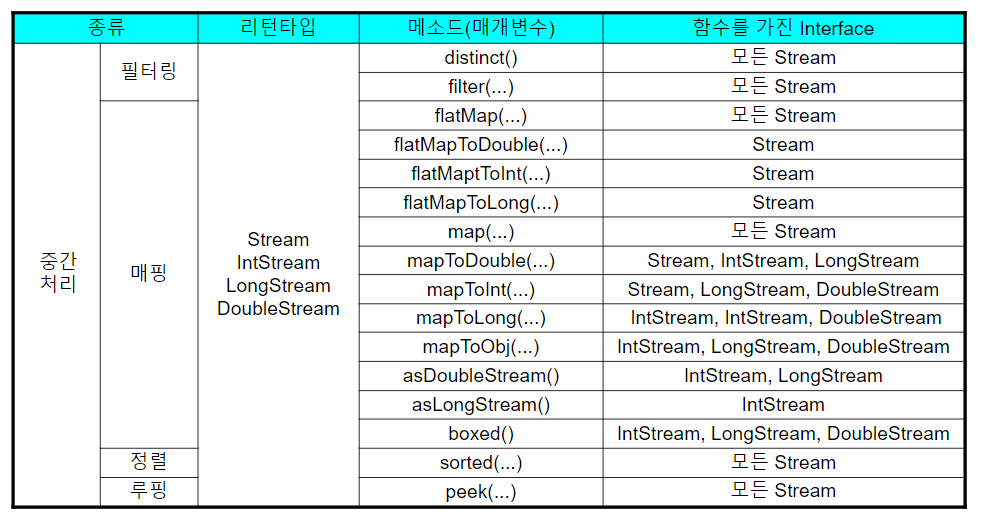
참조 :이것이 자바다 16강 인강
필터링
필터링은 "Filter"라는 말에서 알 수 있듯 Stream에 저장된 수많은 데이터 중 원하는 데이터만 걸러내는 역할을 수행한다.
distinct()
중복을 제거하는 메서드이다.
Stream은 Object.equals(Object B)가 true를 반환할 때 Object와 Object B를 동일한 객체로 판단하는데 Set에서 짧게 설명했듯 자바에서는 equals() 메서드를 수행하기 전 두 Object의 Hashcode 값 일치 여부를 먼저 검사하기 때문에 hashCode() 값 또한 일치해야 한다.
예시 코드는 아래와 같다.
List<Integer> list = new ArrayList<>();
for(int i =0;i<5;i++){
list.add(i);
list.add(i);
}
Stream<Integer> stream = list.stream();
System.out.println("Distinct() 처리 이전 Stream 원소 개수 : "+stream.count());
Stream<Integer> distinctStream = list.stream().distinct();
System.out.println("Distinct() 처리 이후 Stream 원소 개수 : "+distinctStream.count());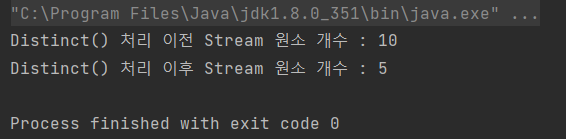
filter()
filter() 메소드는 원하는 기준으로 요소를 걸러내는 역할을 하는 메서드이다.
이때 filter()의 Parameter를 Predicate 형태로 전달해주면 된다.
Predicate는 처음 들어본 개념이니 간단히 정리하자면 Argument를 받아 boolean 값(True, False)을 반환하는 함수형 인터페이스를 말한다.
(함수형 인터페이스라 말하니 어려워 보이지만, 그냥 람다식이나 메서드 레퍼런스를 사용한다고 이해하면 된다)
사용 방법은 아래와 같다.
List<Integer> list = new ArrayList<>();
for(int i =0;i<10;i++){
list.add(i);
}
// 짝수만 남기기
System.out.println("[Filter 처리 이전 Stream 원소]");
list.stream().forEach(e->System.out.print(e+" "));
System.out.println("\n=============================");
// 짝수만 남기기
System.out.println("[Filter 처리 이후 Stream 원소]");
list.stream().filter(e->e%2==0).forEach(e->System.out.print(e+" "));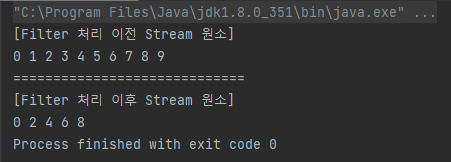
매핑
매핑(Mapping)은 Stream에 저장된 모든 데이터에 원하는 로직을 입혀 다른 데이터로 치환하는 작업을 말한다.
종류는 flatMapX(), mapX(), asDoubleStream(), asLongStream(), boxed()가 존재한다.
flatMapX()와 mapX() 같은 경우 약간 개념이 헷갈릴 수도 있기 때문에 한꺼번에 다루겠다.
map VS flatMap - 개념편
map은 단일 Stream의 원소를 매핑시킨 후 다시 스트림으로 반환하는 중간 연산이다.
이와는 다르게 flatMap은 Array나 Object로 감싸져 있는 모든 원소를 단일 원소 스트림으로 반환한다.
Python에 Numpy라는 모듈에는 "flatten()"이라는 함수가 있다.
이 함수는 N X M 배열(다차원 배열)을 1차원 배열로 평탄화시켜 1 X N*M 배열 형태로 만들어준다.
flatMap도 이런 역할을 한다.
Stream에는 Integer, Long 같은 Wrapper Class 데이터나 int, long 같은 Primitve Class 데이터만 들어가진 않는다.
Array 형태 데이터도 들어갈 수 있을 것이고, 여러 가지 참조 변수를 가지고 있는 Reference Class 데이터도 들어갈 수 있을 것이다.
flatMap은 Reference Class나 Array 형태의 데이터를 일차원 배열에 모두 저장되도록 처리하는 역할을 담당하는 것이다.
map은 이와는 다르게 Stream에 들어있는 Object 객체 그 자체를 처리하는 중간 연산이다.
즉, Array 형태 데이터가 Stream에 저장되어 있을 경우 map Parameter로써 "Array 형태 데이터를 처리할 수 있는 메서드"를 주입해줘야 하는 것이다.
말로만 하면 이해가 되지 않을 수 있으니 예시를 통해 조금 더 확실히 알아보자.
map VS flatMap - 활용 편
List<String> list = Arrays.asList("Hello", "World");
// 1. List를 글자 단위로 쪼개고 출력
list.stream().map(s->s.split("")).forEach(e->System.out.print(e+" "));
System.out.println();
// 2. String[] 배열로 쪼개져 있는 Stream들의 원소를 FlatMap을 통해 하나의 Stream으로 만들고 출력
list.stream().map(s->s.split("")).flatMap(Arrays::stream).forEach(e->System.out.print(e+" "));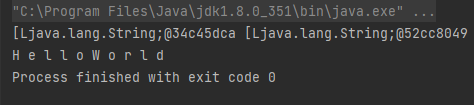
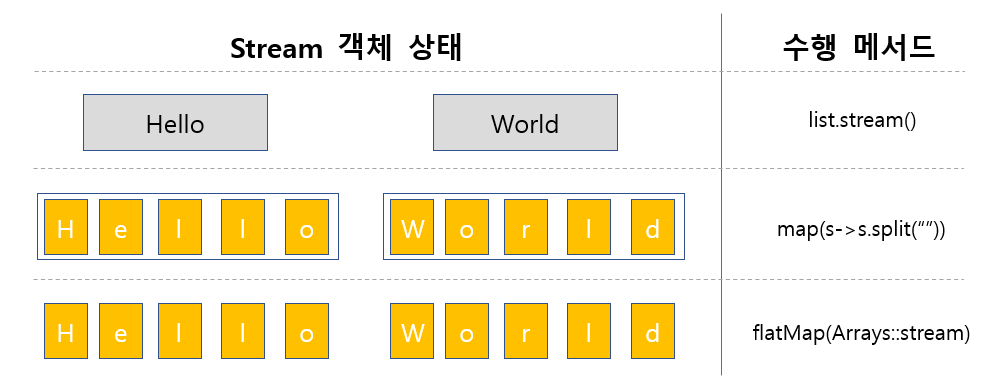
예시 코드에서 일어나는 상황은 위 이미지와 같다.
먼저 ArrayList에는 "Hello"라는 단어와 "World"라는 단어가 순차적으로 저장되어 있다.
이를 list.stream() 메서드를 통해 Stream 형태로 만들어지면 위 이미지와 같이 Stream<String> 형태가 될 것이다.
문제는 2번째 수행 메서드인 map(s->s.split(""))가 실행된 이후이다.
s.split("")라는 명령은 String 데이터인 s를 글자 단위로 쪼개는 명령이다. String 데이터를 split을 통해 나누면 String[] 데이터 타입이 반환되는 것은 알고 있을 것이다.
즉, "Hello"라는 단어는 "H, e, l, l, o" 데이터를 담은 String 배열 1개로 변환될 것이고 "World"라는 단어는 "W, o, r, l, d" 데이터를 담은 String 배열 1개로 변환될 것이다.
이런 상황이 되다 보니 map() 메서드를 수행할 경우 Stream<String[]> 형태로 결과물이 반환되는 것이다.
실제로 map 함수만 실행시킨 결과물을 보면 "[Ljava.lang.String~ [Ljava.lang.String" 형태로 출력됨으로써 String 배열꼴 2개가 출력되었음을 볼 수 있다.
그렇다면 아래 명령어를 통해 실제로 Hello와 World가 String 배열 데이터로 처리되었는지 확인해 보자.
list.stream().map(s->s.split("")).forEach(e->System.out.print(e[0]+" "+e[1]+" "+e[2]+" "+e[3]+" "+e[4]+" "));
배열 원소로 간주하고 접근하였을 때 정상적으로 원소값이 출력됨을 볼 수 있다.
하지만 이렇게 배열 Index를 통해 Stream 값을 조회한다면 Stream을 사용할 이유가 없을 것이다.
따라서 이 Stream<String[]>을 Stream<String>으로 평탄화시켜 바로 "H e l l o W o r l d" 결과값을 보기 위해 "flatMap"을 활용하게 되는 것이다.
예시코드처럼 flatMap(Arrays::stream)을 사용한다면 Stream 내부에 있는 배열에 저장된 데이터를 모두 뽑아 1개의 Stream에 담아주는 역할을 한다.
위 이미지를 보면 "H, e, l, l, o"를 담은 배열 틀과 "W, o, r, l, d"를 담은 배열 틀이 없어져 "H, e, l, l, o, W, o, r, l, d"가 1개의 공통된 공간에 존재함을 볼 수 있다.
어디까지나 flatMap은 배열이나 Reference Class의 틀을 없애주는 역할만 하기 때문에 "Arrays::stream" 형태의 메서드 레퍼런스나 람다식을 사용해 틀을 없앤 데이터들을 "어떤 형식으로 묶을 것인지" 명시해줘야 한다.
결국, 위 예시에서는 flatMap()이 모든 글자를 같은 공간에 보내고 Arrays::stream을 통해 같은 공간에 존재하는 글자 데이터들을 Stream 형태로 묶어주기 때문에 Stream<String> 데이터가 만들어지는 것이다.
마지막으로 만들어진 Stream<String> 데이터를 출력하면 결과물 출력 사진 중 2번째 상황처럼 "H e l l o W o r l d"가 출력됨을 알 수 있다.
asDoubleStream(), asLongStream(), boxed()
asDoubleStream()은 Stream이나 IntStream, LongStream의 요소들의 Type을 double로 변환한 후 DoubleStream을 반환하는 메서드이며 asLongStream()은 Stream, IntStream, DoubleStream의 요소들의 Type을 long으로 변환한 후 LongStream을 반환하는 메서드이다.
boxed()는 LongStream이나 DoubleStream, IntStream의 자료형을 Wrapper Class로 Boxing 하여 Stream 형태로 반환해주는 역할을 수행한다.
정렬
sorted()
말 그대로 Stream 데이터를 정렬해주는 메서드이다.
Collections.sort나 Arrays.sort를 사용하기 위해선 객체가 Comparable Interface를 상속하여 compareTo 메서드가 오버라이드 되어 있거나 Comparator 익명 구현체를 Parmaeter로써 추가해줘야 한다.
원래 Comparator 객체를 추가하기 위해서는 아래와 같은 과정을 거쳐야 한다.
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return 0;
}
});그런데 이 Comparator는 재밌는 특성을 가지는데, 바로 "함수형 인터페이스"라는 것이다.

@FunctionalInterface = 이 객체가 함수형 인터페이스
이제는 모두 알겠지만 람다식을 통해 익명 구현체를 생성할 수 있으며 익명 구현체는 함수형 인터페이스에 사용할 경우 자동으로 1개의 추상 메서드 구현체로 들어간다.
따라서 Comparator 대신 람다식을 활용할 수 있고, Stream에서는 sorted()와 람다식을 활용해 손쉽게 정렬을 수행할 수 있다.
예시 코드를 통해 알아보자.
// Member Class 정의
class Member {
int age;
String name;
public Member(int age, String name) {
this.age = age;
this.name = name;
}
}List<Member> members = new ArrayList<>();
members.add(new Member(10, "D"));
members.add(new Member(20, "B"));
members.add(new Member(30, "C"));
members.add(new Member(10, "A"));
System.out.println("[정렬하지 않은 상황에서 Stream 데이터 출력]");
members.stream().forEach(m -> System.out.println(m.age+" "+m.name));
System.out.println("[나이 기준으로만 정렬한 상황에서 Stream 데이터 출력]");
members.stream().sorted((m1,m2)->m1.age - m2.age).forEach(m -> System.out.println(m.age+" "+m.name));
System.out.println("[나이가 같을 경우 이름으로 정렬한 상황에서 Stream 데이터 출력]");
members.stream().sorted((m1, m2) -> {
if (m1.age == m2.age) {
return m1.name.compareTo(m2.name);
} else {
return m1.age - m2.age;
}
}).forEach(m -> System.out.println(m.age + " " + m.name));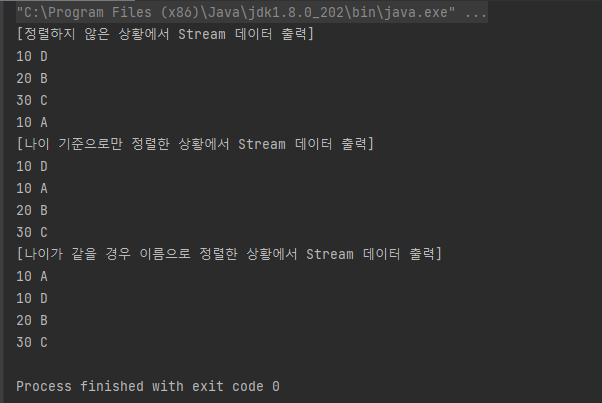
먼저 정렬하지 않은 상황에서의 Stream 데이터 출력 구문을 보자.
보다시피 D → B → C → A 순, 즉 List에 데이터를 넣은 순으로 객체를 반환함을 알 수 있다.
두 번째로 나이 기준으로 정렬한 상황에서 Stream 데이터를 출력한 상황을 보자.
D → A → B → C 순, 즉 나이 순으로 오름차순 정렬이 수행되었고 만약 나이가 같을 경우 List에 데이터가 들어온 순서대로 객체가 반환되었다.
마지막으로 나이가 같을 경우 이름으로 정렬한 상황에서 Stream 데이터를 출력하면 우리가 원하는 대로 A → D → B → C순으로 출력됨을 알 수 있다.
원래라면 "@Override" 구문과 "public int compare(String o1, String o2)" 구문 때문에 코드가 복잡해져야 하지만 람다식을 통해 이런 구문을 기입하지 않아도 되므로 코드가 더욱 깔끔해져 가독성이 증가하고 직관적인 코드가 되었다.
루핑
peek() VS forEach()
"루프"의 사전적 의미는 반복의 의미로 활용된다.
루핑이란 "Loop + ing"로 Java에서 반복하는 과정을 말하며 흔히 사용하는 for문이나 while문, forEach문 또한 루핑 도구이다.
Stream에서는 데이터를 순회하기 위한 반복 작업을 peek()이나 forEach()를 통해 처리한다.
peek()과 forEach()는 같은 역할을 하지만 사용 방법은 완전히 다르다.
사용 방법이 다른 이유는 forEach는 "최종 처리 메서드"이고 peek은 "중간 처리 메서드"이기 때문이다.
forEach()는 Return 값이 void인 최종 처리 메서드로써 그 자체만으로도 사용 가능하다.
하지만 peek()은 IntStream을 Return 한다.
즉 peek() 과정으로 루핑을 시도한 이후 Stream 처리를 종료해버리면 Stream 처리 Output을 IntStream으로 다시 받게 되는 것이다.
말로는 잘 이해가 안 될 수도 있으니 코드를 통해 알아보자.
int[] intArr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
System.out.println("[peek()를 마지막에 호출한 경우]");
Arrays.stream(intArr)
.filter(a -> a%2 == 0)
.peek(System.out::println);
// 최종처리 메소드(Terminal) sum()이 존재하므로 정상 작동한다.
System.out.println("[peek() 결과물을 IntStream으로 받은 뒤 처리]");
IntStream stream = Arrays.stream(intArr)
.filter(a -> a%2 == 0)
.peek(System.out::println);
System.out.println("Stream 개수 : "+stream.count());
System.out.println("[forEach()로 루핑 처리]");
Arrays.stream(intArr)
.filter(a -> a%2 == 0)
.forEach(System.out::println);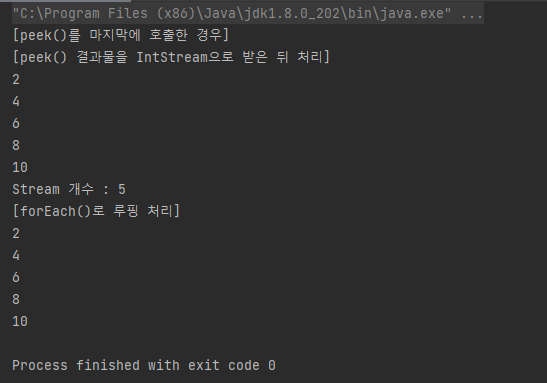
먼저 peek()을 마지막에 호출한 경우를 확인해 보자.
아무것도 출력되지 않았다. 분명 코드에서는 peek()에서 루핑을 통해 요소를 출력하라는 명령을 했는데 말이다.
그렇다면 peek() 결과를 IntStream으로 받아 처리하면 어떻게 될까? 2번째 상황을 보자.
2번째 상황에서 IntStream으로 peek() 처리 결과를 받아 최종 처리 명령 중 하나인 .count()를 통해 처리했다.
그 결과 "2, 4, 6, 8, 10"과 "Stream 개수 : 5"가 출력되었다.
즉, peek()을 통해 처리한 루핑 결과가 출력된 이후 최종 처리 명령이 수행되었음을 확인할 수 있다.
여기에서 중요한 게 "2, 4, 6, 8, 10"만 출력되고 바로 Stream 개수가 출력되었다는 점이다. 이는 처음 실행했던 "peek()을 마지막에 호출한 경우"의 Stream이 증발했다는 것을 의미한다.
3번째 상황에서는 peek() 대신 forEach문을 사용했는데 따로 IntStream으로 받아 처리하지 않아도 바로 "2, 4, 6, 8, 10"이 출력되었음을 알 수 있다.
이를 정리해보자면 peek()을 사용할 경우 결과물이 IntStream으로 반환되고, 반환된 IntStream에 최종 처리 결과문을 붙여줘야 peek()으로 처리한 로직이 처리됨을 알 수 있다.
만약 최종 처리 결과문을 붙이지 않을 경우 peek()으로 처리된 Stream은 증발되는 것을 알 수 있다.
peek()을 사용하는 이유
그렇다면 forEach()라는 편리한 루핑 도구이자 최종 처리 메서드가 있는데 왜 peek()가 존재할까?
함수형 프로그래밍의 까다로운 점 중 하나는 "디버깅"이 안된다는 것이다.
만약 배열에 존재하는 데이터 값에 1을 더한 뒤 2를 곱하는 로직을 수행한다고 가정하자.
이때 for문을 사용하여 외부 반복자를 사용할 경우 1을 더한 뒤의 중간 결과를 System.out.print 같은 문구로 출력할 수 있다.
하지만 함수형 프로그래밍(람다식)은 일괄적으로 데이터를 처리해버리기 때문에 중간 결과물을 확인하기가 까다롭다.
이 때 Stream에서 사용하는 것이 peek()다.
중간 처리 메서드 뒤에 peek() 문을 추가하여 이전까지의 중간 처리 메서드를 통해 처리된 중간 결과물을 확인할 수 있는 것이다.
코드를 통해 확인해 보자.
System.out.println("[2와 3의 공배수를 찾아보자]");
IntStream.range(1,13).filter(i ->i %2==0).filter(i ->i %3==0).forEach(i -> System.out.println(i+" "));
System.out.println("[2와 3의 공배수를 찾을 때 중간 처리 과정을 확인해보자]");
IntStream.range(1, 13).peek(i-> System.out.println("확인할 수 : "+i))
.filter(i -> i % 2 == 0).peek(i-> System.out.println("2의 배수 : "+i))
.filter(i -> i % 3 == 0).peek(i-> System.out.println("2와 3의 공배수 : "+i))
.count();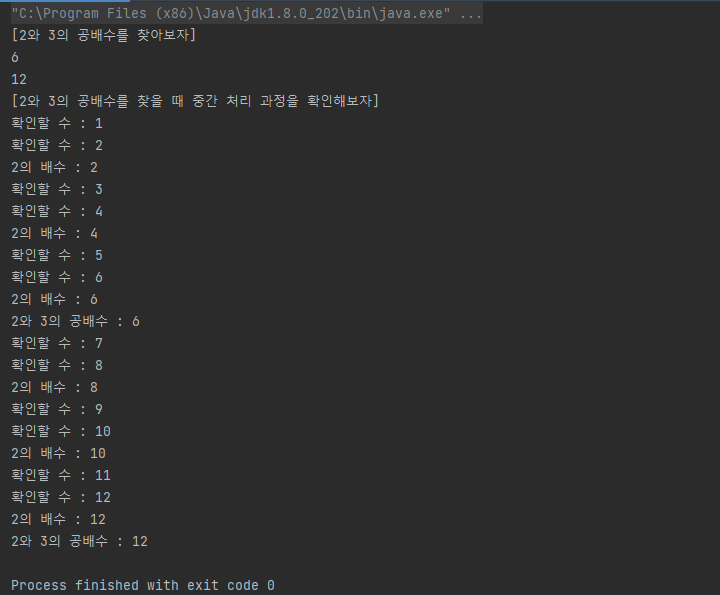
첫 번째 상황에 forEach문을 활용했을 때는 단순히 2와 3의 공배수인 6, 12만 출력됨을 알 수 있다.
두 번째 상황처럼 peek을 사용하면 2와 3의 공배수를 찾는 중간 과정을 확인할 수 있다.
위 예시에서 볼 수 있듯 peek() 메서드는 이전까지 수행된 filter나 중간 메서드가 True를 반환하거나 조건에 맞는 경우에만 실행되는 것을 볼 수 있다.
추가로 위 예시를 통해 Stream은 원소 1개를 모든 중간 연산자에 통과시킨 뒤 다음 원소를 처리하는 것 또한 알 수 있다.
