최종 처리 메서드 종류
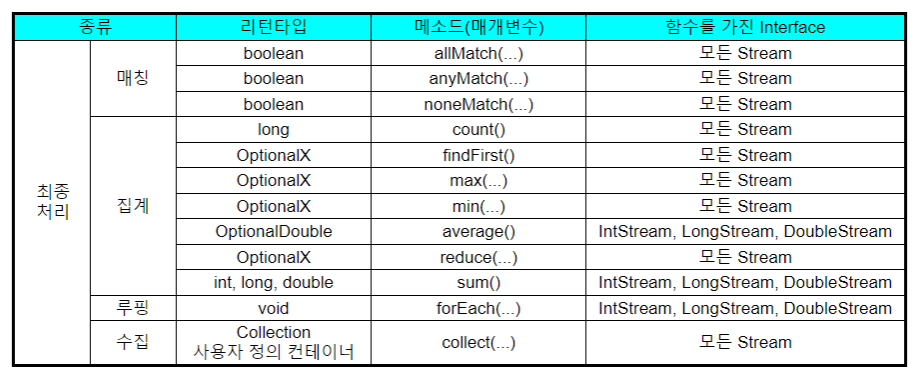
참조 : 이것이 자바다 16강 인강
수집
최종 처리 메서드의 꽃이라고 할 수 있다.
지금까지 Stream으로 처리한 데이터들은 최종 처리 메서드를 통해 결과 출력만 수행하였다.
하지만 현실에서 코드를 사용할 때는 출력문으로 결과를 출력하는 상황보다는 데이터들을 Collection이나 Array에 담아 사용자에게 반환하는 경우가 대부분이다.
따라서 Stream에서도 중간 메서드들을 통해 처리된 데이터들을 Collection이나 배열, 혹은 원하는 Container로 담아주는 메서드가 필요하고 이것이 "수집 최종 처리 메서드"이다.
대표적인 수집 메서드는 "collect()"이며 collect에 전달하는 Parameter를 다르게 하여 어떤 Container에 Stream 데이터를 수집할지 결정할 수 있다.
Collect
기본 Java Collection에 Stream 데이터 수집
Stream 데이터들을 기본 Java Collection인 List, Set, Map에 담는 상황이다.
Stream 데이터들을 Java Collection에 담기 위해서는 주로 "Collectors" 클래스의 정적 메서드를 활용한다.
Collectors.toList()- Stream 데이터를 List에 저장
Collectors.toSet()- Stream 데이터를 Set에 저장
Collectors.toCollection(Supplier<Collection<T>>)- Supplier가 제공한 Collection에 제공
Collectors.toMap(Function<T,K> keyMapper, Function<T,U> valueMapper)- Stream 데이터를 K와 U로 매핑하여 K를 키로, U를 값으로 Map에 저장
Collectors.toCurrentMap(Function<T,K> keyMapper ,Function<T,U> valueMapper)- Stream 데이터를 K와 U로 매핑하여 ConcurrentMap에 저장
메서드만 먼저 정리해 놨지만, 당연히 이렇게만 써 놓으면 어떻게 사용하는지 모호할 것이다.
코드를 통해서 차근차근 알아보자.
Collectors.toList() : Stream → List
List<Member> members = new ArrayList<>();
members.add(new Member(10, "홍길동"));
members.add(new Member(20, "김길동"));
members.add(new Member(30, "박길동"));
members.add(new Member(40, "이길동"));
List<Member> memberList = members.stream().filter(s->s.age>20).collect(Collectors.toList());
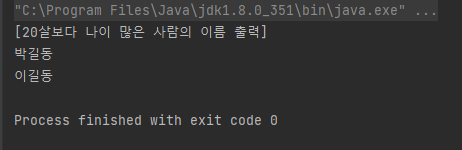
System.out.println("[20살보다 나이 많은 사람의 이름 출력]");
for(Member member:memberList){
System.out.println(member.name);
}
filter(s->s.age>20)를 통해 나이가 20보다 많은 사람만 memberList에 저장시켰다.
이후 ".collect(Collectors.toList())" 메서드를 통해 Stream을 List<Member> 형태로 수집하고 반환시켰다.
실제 결과로 30, 40살인 "박길동", "이길동"씨가 출력됨을 볼 수 있다.
Collectors.toSet()
이번 단계를 수행하기 전 Member 클래스에 hashCode() 및 equals() 메서드가 제대로 Override 되어 있어야 한다.
이전에 설명했듯 Java Set은 두 객체가 동일한지를 판단하기 위해선 먼저 두 객체의 hashcode 값을 검사하고 hashcode 값이 동일할 경우 equals() 메서드를 수행시켜 True가 반환될 경우만 같은 객체로 보기 때문이다.
두 개 함수를 Override 한 Member 객체는 아래와 같다.
class Member {
int age;
String name;
public Member(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public int hashCode() {
return Objects.hash(name);
}
@Override
public boolean equals(Object o) {
Member s = (Member) o;
return this.name.equals(s.name) && this.age==s.age;
}
}위 설정까지 마쳤으면 이제 Collectors.toSet()을 사용해 보자.
List<Member> members = new ArrayList<>();
members.add(new Member(10, "홍길동"));
members.add(new Member(20, "김길동"));
members.add(new Member(30, "박길동"));
members.add(new Member(40, "이길동"));
members.add(new Member(40, "이길동"));
members.add(new Member(40, "이길동"));
members.add(new Member(40, "이길동"));
members.add(new Member(40, "이길동"));
members.add(new Member(40, "이길동"));
members.add(new Member(40, "이길동"));
members.add(new Member(40, "이길동"));
members.add(new Member(40, "이길동"));
Set<Member> memberSet = members.stream().filter(s->s.age>20).collect(Collectors.toSet());
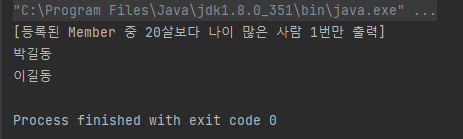
System.out.println("[등록된 Member 중 20살보다 나이 많은 사람 1번만 출력]");
for(Member member:memberSet){
System.out.println(member.name);
}
List에는 동일한 이길동 씨의 데이터가 무려 9개가 존재한다.
만약 이를 List로 처리하면 이길동씨의 나이는 20보다 많으므로 List에는 9개의 이길동 씨의 데이터가 쌓일 것이다.
따라서 Set을 통해 동일한 이길동씨의 데이터는 1개의 데이터로 처리했다.
출력문 사진에서 "이길동"이 1번만 출력됨을 확인할 수 있다.
memberSet.size()를 실행해보면 2가 출력됨을 볼 수 있고, 이를 통해 제대로 Set 처리가 되었음을 확인할 수 있다.
Collectors.toCollection(Supplier<Collection<T>>)
어떤 사람은 Set<Member>가 아닌 HashSet<Member>로 처리하고 싶을 수도 있을 것이다.
하지만 HashSet<Member> 생성 시 Collectors.toSet()으로 처리할 경우 에러가 발생한다.
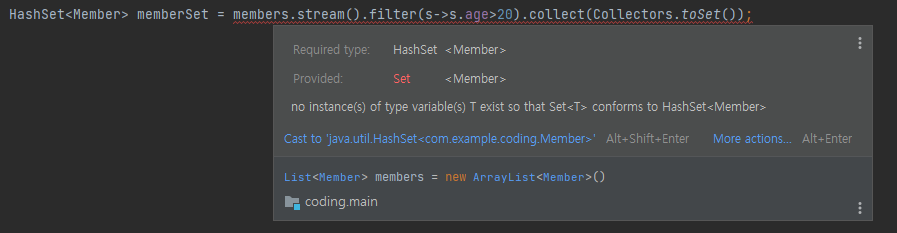
위 문구를 통해 Collectors.toList()는 List<T> 형태로 데이터를 수집하고 Collectors.toSet()은 Set<T> 형태로 데이터를 수집함을 알 수 있다.
즉 HashSet<Member>에 데이터를 수집하려 새로운 방법이 필요하다는 것인데, 그 방법이 Collectors.toCollection()이다.
Supplier<K>란 인자를 받지 않고 Type K 객체를 반환하는 함수형 인터페이스를 말한다.
Collectors.toCollection의 Parmeter가 Supplier<Collection<T>>이므로 Collectors.toCollection의 인자로써 원하는 Collection 객체를 반환하는 함수형 인터페이스를 써야 한다.
원하는 Collection 객체를 반환하는 방법은 간단하다.
HashSet 객체를 반환받고 싶으면 new HashSet<>(), ArrayList 객체를 반환받고 싶으면 new ArrayList<>()를 사용해주면 되는 것이다.(Supplier는 인자를 받지 않아야 함을 다시 한번 기억하자)
하지만 new HashSet<>() 형태는 함수형 인터페이스가 아니기 때문에 Collectors.toCollection의 Parmeter로써 주입할 수는 없다.
따라서 람다식(()->new HashSet<>()), 혹은 메서드 레퍼런스(HashSet::new)를 통해 new HashSet<>() 명령을 대체해야 하는 것이다.
// 방법 1 : 람다식을 통한 주입
HashSet<Member> memberSet = members.stream().filter(s->s.age>20)
.collect(Collectors.toCollection(()->new HashSet<>()));
// 방법 2 : 메서드 레퍼런스를 통한 주입. 더 간결하고 명확하므로 이 방법을 추천
ArrayList<Member> memberArrayList = members.stream().filter(s->s.age>20)
.collect(Collectors.toCollection(ArrayList::new));Collectors.toMap(Function<T,K> keyMapper, Function<T,U> valueMapper)
toMap과 toCurrentMap 메서드는 Stream 데이터를 Map에 저장할지 ConcurrentMap에 저장할지의 차이일 뿐이므로 toMap만 설명하겠다.
(참고로 ConcurrentMap이란 Mulit-Thread 환경에서 사용할 수 있도록 나온 Map 형태로써 Hashtable 클래스의 개량 판이라고 보면 된다)
여기서 Function<T,K> keyMapper와 Function<T,U> valueMapper는 Stream 데이터 각각에 적용되는 함수이다.
즉 모든 데이터에 각각 keyMapper와 valueMapper 함수가 적용되어 Stream 데이터 1개가 1개의 Entry 객체를 만든다는 의미이다.(Collection의 Map을 설명할 때 Entry 객체란 Key-Value 데이터 쌍을 묶은 객체임을 배웠다.)
List<Member> members = new ArrayList<>();
members.add(new Member(10, "홍길동"));
members.add(new Member(20, "김길동"));
members.add(new Member(30, "박길동"));
members.add(new Member(40, "이길동"));
Map<Integer, String> itemMap = members.stream().collect(Collectors.toMap(s->s.age, s->s.name));
// 만약 Getter가 함수 내에 존재한다면 아래와 같이 메서드 레퍼런스 방식을 사용해도 된다.
// Map<Integer, String> itemMap2 = members.stream().collect(Collectors.toMap(Member::getAge, Member::getName));
for(Map.Entry<Integer, String> entry : itemMap.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}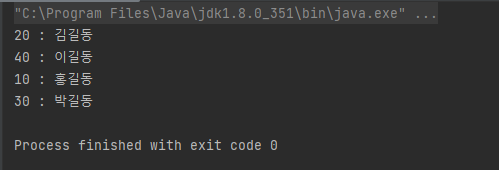
제대로 Map 객체가 추출되었음을 확인할 수 있다.
Collectors.toMap의 문제점
그런데 이 Collectors.toMap에는 생각보다 문제가 많다.
먼저 Value 값에 null이 들어가는 상황에는 NullPointerException이 발생한다는 것이다.
List<Member> members = new ArrayList<>();
members.add(new Member(10, null));
members.add(new Member(20, "김길동"));
members.add(new Member(30, "박길동"));
members.add(new Member(40, "이길동"));
Map<Integer, String> itemMap = members.stream().collect(Collectors.toMap(s->s.age, s->s.name));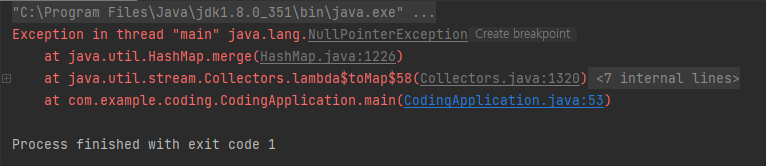
분명 Map의 Key, Value 값으로써 null이 들어갈 수 있다 배웠는데, 잘못 배운 걸까? 한 번 테스트해 보자.
Map<String, String> map = new HashMap<>();
map.put("a", null);
map.put(null, "b");
System.out.println("정상 종료");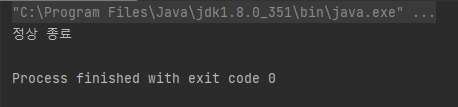
그렇다면 Map의 Key, Value 값으로 Null 데이터가 들어갈 수 있는데 왜 Collectors.toMap은 NullPointerException을 발생시키는 것일까?
NullPoinerException 문제 말고 Collectors.toMap은 다른 문제도 가지고 있는데, 바로 Key가 동일한 값이 2개 있을 경우 에러가 발생한다는 것이다.
List<Member> members = new ArrayList<>();
members.add(new Member(10, "홍길동"));
members.add(new Member(10, "김길동"));
members.add(new Member(30, "박길동"));
members.add(new Member(40, "이길동"));
Map<Integer, String> itemMap = members.stream().collect(Collectors.toMap(s->s.age, s->s.name));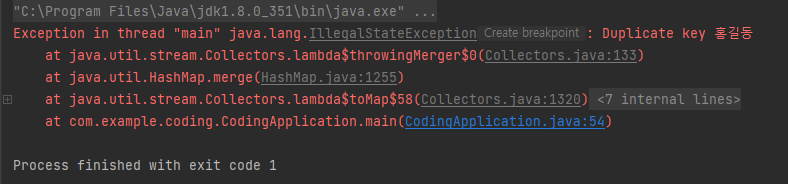
NullPointerException 문제도 이상했지만, 이 문제가 더욱 이상하다.
분명 나는 Key값으로 "나이"를 설정했는데 왜 에러 문구에는 "Duplicate key 홍길동"이라는 문구(즉, 이름값이 중복되었다는 에러 문구)가 발생하며 에러가 발생하는 것일까?
애초에 Map은 Key가 중복될 경우 마지막에 들어온 값으로 Value가 대체되는 것이 아니었나?
이런 문제가 생긴 이유는 Stream 관련 모든 메서드들이 멀티 스레딩(Multi-Threading) 환경에서 병렬 처리가 가능하도록 로직이 짜여 있기 때문이다. 만약 2-Thread 환경에서 4개의 Stream 데이터를 처리할 경우 (A, B)는 첫 번째 CPU에서, (C, D)는 두 번째 CPU에서 처리된다. 이후 첫 번째 CPU와 두 번째 CPU에서 처리된 결과물을 1개로 병합시켜야지만 Stream 데이터 처리 최종 결과물이 도출될 텐데 이 과정 때문에 위와 같은 문제가 발생하는 것이다.
Collectors.toMap()은 Multi-Threading 환경에서 처리된 여러 개의 데이터 병합을 위해 "merge()"라는 메서드를 활용한다.
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
...
// Collector.toMap()을 실행했을 때 실제로 실행되는 메서드
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}toMap 메서드를 확인해보면 아래와 같은 코드가 존재한다.
(map, element) -> map.merge(keyMapper.apply(element), valueMapper.apply(element), mergeFunction);Collectors.toMap에 대해 정확히 알고 싶다면 "map.merge()" 메서드에 대해 파악해볼 필요가 있을 것이다.
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}자 이제 NullPointerException이 발생하는 이유를 찾을 수 있다.
merge() 메서드의 2번째 명령을 보면 "Objects.requireNonNull(value)"가 존재함을 알 수 있다.
즉, Collectors.toMap()을 수행하려면 merge() 메서드를 수행해야 하는데 이 merge() 메서드 로직에서는 (Key, Value) 쌍 데이터에서 Value값을 활용하며, 이 때문에 Value가 Null이 아닌 상황을 요구하는 것이다.
또한 merge() 코드를 통해 중복된 Key값이 존재하는 상황에서 Duplicate Key에러가 발생한 이유도 알 수 있다.
V newValue = (oldValue == null) ? value : remappingFunction.apply(oldValue, value);merge() 코드에는 위와 같은 내용이 존재하는데, 만약 동일한 Key값을 가진 Entry 객체가 있다면 oldValue는 null이 아닐 것이다.
그렇다면 remappingFunction.apply(oldValue, value); 메서드가 수행될 텐데 위의 toMap 메서드를 확인해보면 remappingFunction으로 throwingMerger()라는 함수가 들어가는 것을 확인할 수 있다.
그리고 throwingMerger() 함수는 아래와 같다.
private static <T> BinaryOperator<T> throwingMerger() {
return (u,v) -> { throw new IllegalStateException(String.format("Duplicate key %s", u)); };
}(u, v) = (oldValue, value)이기 때문에 동일한 Key값을 가진 Entry 객체가 존재하는 상황에서 merge() 함수가 실행될 경우 "Duplicate Key oldValue"라는 IllegalStateException이 발생하는 것이다.
이를 통해 나이를 Key값으로 설정했는데 에러 문구에는 Value 값이 출력되었는지도 알 수 있다.
(솔직히 이건 에러 문구를 잘못 만든 것 같다. Duplicate Key 에러를 띄울 거면 Value 값이 아닌 Key값을 띄워야지 왜...)
거기에 사소한 불편한 점이라면 Map <T>로만 변환 가능하고 HashMap, TreeMap으로는 변환 불가하다는 것이다.
그래서 Stream을 Map으로 변환할 때는 filter로 이런 상황을 다 걸러주거나(생각만 해도 너무 귀찮고 Human Error가 많이 나올 것 같은 방법이다) 아래에서 설명할 사용자 정의 Container에 Stream 데이터를 저장하는 방법 사용을 추천한다.
(참고로 merge() 메서드는 Value 값의 null 여부만 체크하기 때문에 Key값은 null이어도 문제가 발생하지 않는다)
사용자 정의 Container에 Stream 데이터 수집
collect(Supplier<R>, BiConsumer<R, ?super T>, BiConsumer<R,R>)위에 기입한 코드가 Collectors의 정적 메서드를 사용하지 않을 경우 직접 주입해줘야 할 Parmeter이다.
위에서 Supplier는 배웠으니 BiConsumer에 대해서 배워봐야 한다.
BiConsumer<R, T>는 컨테이너 객체 R에 데이터 T를 저장할 때 사용하는 함수형 인터페이스를 말한다.
객체 R에 Stream 데이터 1개를 수집할 때마다 BiConsumer<R, ?super T>가 사용될 것이다.
그렇다면 마지막 Parmeter인 BiConsumer<R,R>은 무엇일까?
이는 Stream의 Multi-Threading 작업을 위한 메서드로써 위에서 설명한 merge()처럼 다른 CPU에서 작업한 Stream 작업물들을 병합할 때 사용하는 메서드이다.
CPU에서 작업한 각각의 Stream 작업물들은 Supplier에서 생성한 객체 R 형태로 반환될 것이므로 객체 R을 병합할 수 있는 메서드여야만 한다.
먼저 HashMap이라는 이미 구현되어 있는 기능으로 collect()를 사용해 보자.
List<Member> members = new ArrayList<>();
members.add(new Member(10, "홍길동"));
members.add(new Member(20, "김길동"));
members.add(new Member(30, "박길동"));
members.add(new Member(40, "이길동"));
HashMap<Integer, String> hashMap = members.stream()
.collect(HashMap::new, (m, s) -> m.put(s.age, s.name), HashMap::putAll);
for(Map.Entry<Integer, String> entry : hashMap.entrySet()){
System.out.println(entry.getKey() + " : " + entry.getValue());
}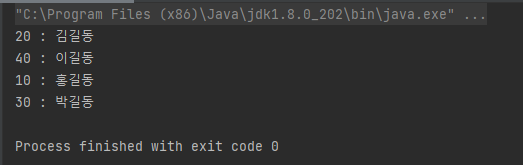
먼저 Supplier로 HashMap::new를 통해 HashMap에 데이터를 저장할 것이라고 전달했다.
BiConsumer<R,T>라는 형태를 생각했을 때 Lambda 식의 첫 번째 Parmeter는 R로 지정한 HashMap, 두 번째 Parameter인 T는 Stream에 저장된 Member 객체임을 유추할 수 있다.
따라서 (m, s) -> m.put(s.age, s.name)으로 Map에 Member Data를 추가한 것이다.
마지막으로 HashMap 2개를 병합시킬 때는 "putAll" 메서드를 사용하면 되므로 HashMap::putAll을 전달했다.
HashMap의 put 메서드 및 putAll 메서드는 merge()와 다르게 Value가 null이어도 괜찮고 key값이 중복되어도 자체적으로 처리하기 때문에 아무런 문제 없이 HashMap을 만들 수 있다.
그렇다면 한 번 직접 Container를 만들어 collect()로 모아보자.
class Students{
List<Student> list;
public Students() {
this.list = new ArrayList<>();
}
public void add(Student student){
list.add(student);
}
public void addAll(Students students){
this.list.addAll(students.list);
}
}
class Student{
String name;
int age;
public Student(String name, int age){
this.name = name;
this.age = age;
}
}List<Student> list = new ArrayList<>();
Random random = new Random();
for(int i =0;i<10;i++){
list.add(new Student("Person"+i, random.nextInt(30)+5));
}
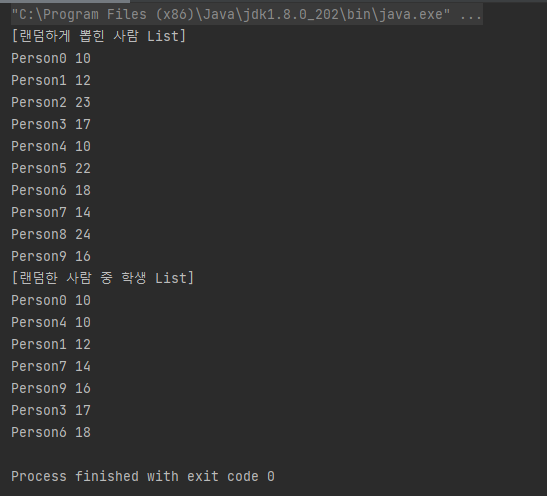
Students students = list.stream().filter(student -> student.age>=7 && student.age<=19)
.sorted((s1,s2) -> s1.age - s2.age)
.collect(Students::new, (sList, s) -> sList.add(s), (sL1, sL2) -> sL1.addAll(sL2));
System.out.println("[랜덤하게 뽑힌 사람 List]");
for(Student student : list){
System.out.println(student.name + " " + student.age);
}
System.out.println("[랜덤한 사람 중 학생 List를 나이 순으로 정렬]");
for(Student student : students.list){
System.out.println(student.name + " " + student.age);
}
toArray
collect()는 Java Collection이나 사용자 생성 Container에 데이터를 수집했다.
그렇다면 Stream 데이터를 Array(배열)에 저장시키고 싶을 때는 어떻게 할까?
이 경우 "toArray" 메서드를 활용한다. collect() 와는 다르게 특별한 Parameter 없이 toArray만 기입하면 되므로 코드만 기입해 놓겠다.
(단, int[]의 경우 mapToInt, long[]의 경우 mapToLong, double[]의 경우 mapToDouble 중간 처리 메서드로 변환 뒤 사용하도록 하자)
List<Integer> list = new ArrayList<>();
for(int i =0;i<10;i++) list.add(i);
long[] arr = list.stream().mapToLong(Integer::longValue).toArray();