데이터 송신
write
connect를 통해 데이터 송/수신을 위한 통로인 커넥션을 만들었으니 데이터를 실제로 송신해 보자.
애플리케이션은 데이터를 송신하기 위해 "write" 메서드를 호출하여 프로토콜 스택에 송신 데이터를 건네준다.
이 동작에는 몇 가지 특징이 존재한다.
먼저 프로토콜 스택은 데이터의 내용에 대해 큰 신경을 쓰지 않는다.
프로토콜 스택에게 있어 전달받은 메시지는 단순히 입력받은 길이만큼 나열된 Binary Data일 뿐이다.
두 번째로 프로토콜 스택은 데이터를 받자마자 송신하는 것이 아닌 송신용 버퍼 메모리 영역에 잠시 저장시킨다는 것이다.
애플리케이션에서 프로토콜 스택에 송신을 의뢰할 때 데이터의 길이는 애플리케이션의 종류나 데이터를 만드는 방법에 따라 결정된다.
한 번에 모든 데이터를 건네줄 수도 있고 1바이트나 1행씩 데이터를 쪼개 송신을 의뢰하는 경우도 있다.
이런 상황에서 패킷을 받자마자 바로 보내는 단순한 방식을 사용하면 작은 패킷을 많이 보내게 되어 효율성이 낮아질 수 있다.
즉, 네트워크의 효율성을 높이기 위하여 어느 정도 데이터를 버퍼 메모리에 저장시킨 뒤 송신 동작을 수행하는 것이다.
버퍼 메모리에 어느 정도까지 데이터를 저장할지 결정하는 요인
버퍼 메모리에 얼마나 데이터를 저장할지 결정하는 요인은 2가지가 존재한다.
먼저 MTU라는 매개변수이다.
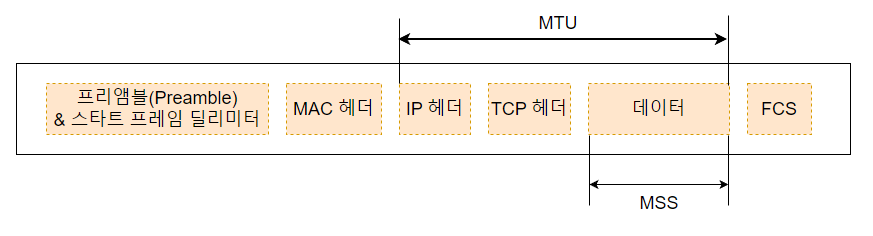
MTU란 패킷 1개가 운반할 수 있는 디지털 데이터의 최대 길이를 의미한다.
MSS란 헤더를 제외하고 1개 패킷으로 운반할 수 있는 TCP 데이터의 최대 길이를 의미한다.
이더넷에서 MTU는 보통 1500 바이트 정도로 설정되어 있는데 여기에는 IP 헤더와 TCP 헤더 같은 제어 정보가 포함되어 있다.(PPPoE를 사용한 서비스에서는 1500 바이트보다 작아진다)
여기에서 제어 정보를 제외한 순수한 데이터 최대 길이를 MSS라고 한다.
MTU는 고정되어 있는 값이지만 IP 헤더와 TCP 헤더의 길이는 고정되어 있지 않으므로 MSS는 고정되지 않은 값이다.
만약 버퍼 메모리에 저장된 데이터가 MSS를 초과하거나 MSS에 가까운 길이만큼 저장되어 있다면 데이터 송신 동작을 수행하는 것이다.
두 번째 판단 요소는 타이밍이다.
애플리케이션이 프로토콜 스택에 의뢰하는 속도가 느려 송신 버퍼 메모리에 데이터가 늦게 쌓인다고 가정하자.
이때 MSS에 가깝게 데이터가 쌓이는 것을 기다릴 경우 그만큼 대기 시간이 발생되기 때문에 전체적인 네트워크 통신 속도가 느려질 것이다.
따라서 프로토콜 스택은 내부 타이머를 활용해 일정 시간 이상이 경과할 경우 메모리에 쌓인 데이터를 패킷으로 만들어 송신한다.
두 가지 판단요소(타이밍, MTU)는 서로 상충되는 면이 존재한다.
타이밍을 중요시하면 송신 지연 시간은 줄어들겠지만 네트워크가 비효율적으로 활용될 것이며 MTU를 중요시하면 네트워크는 효율적으로 활용되겠지만 송신 지연 시간이 증가한다.
이 둘의 밸런스에 대한 규정은 없므로 OS 종류나 버전에 따라 다르게 동작한다.
추가로 프로토콜 스택이 아닌 애플리케이션 측에서도 송신 타이밍을 제어할 수 있다.
애플리케이션은 데이터 송신을 진행할 때 옵션을 통해 데이터를 메모리 버퍼에 임시 저장하지 않고 바로 송신하도록 설정할 수 있다.
브라우저와 같은 대화형 애플리케이션의 경우 버퍼에 머무는 시간만큼 응답 시간 또한 지연되므로 이러한 옵션을 활용하는 경우가 많다.
데이터 분할
HTTP 리퀘스트 메시지의 길이가 너무 커 MSS를 넘는 경우 1개 패킷에 전체 데이터를 저장하지 못하는 경우가 발생한다.
이 경우 TCP 담당은 데이터를 맨 앞부터 MSS의 크기에 맞게 분할한 후 조각에 TCP 헤더를 덧붙인다.
이후 IP 담당은 모든 조각에 IP 헤더와 MAC 헤더를 붙임으로써 패킷을 만들어 송신한다.
시퀀스 번호 & ACK 번호
TCP는 안정성을 중요시하는 프로토콜로써 송신한 패킷이 상대에게 올바르게 도착했는지 확인하고 도착하지 않았을 경우 누락된 패킷을 다시 송신한다.
이를 위해 TCP에서는 "시퀀스 번호"를 Request에 담아 보내고 Response에는 "ACK 번호"를 담아 확인하는 과정이 존재한다.
출처 : 성공과 실패를 결정하는 1%의 네트워크 원리 p.125
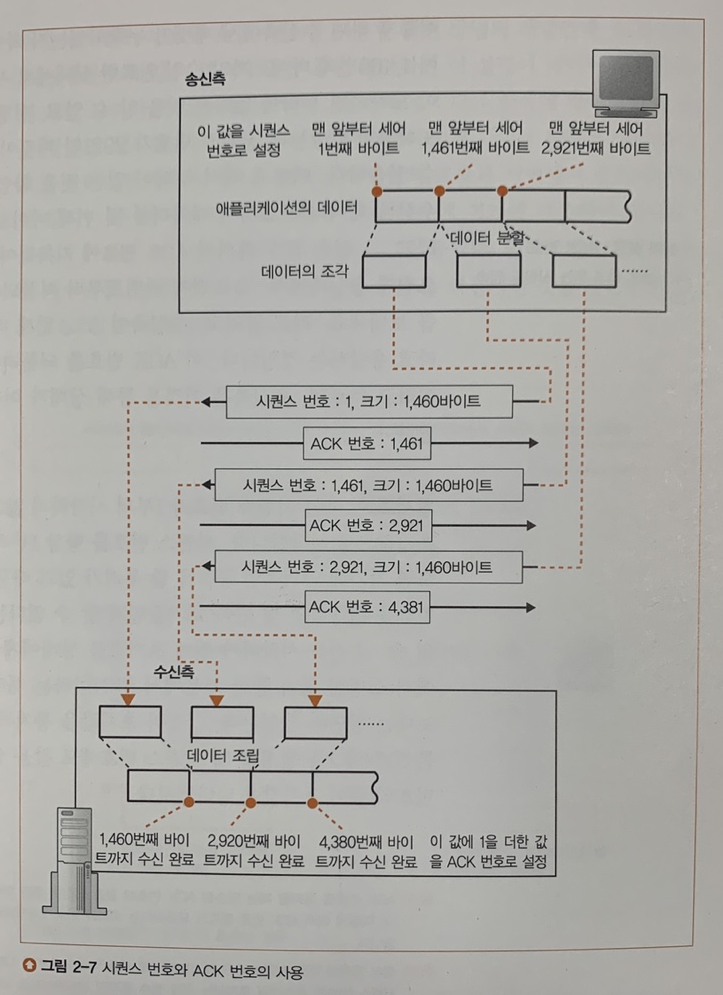
TCP 담당은 데이터를 조각으로 분할할 때 각 조각의 시작 부분이 데이터의 맨 처음부터 몇 번째 바이트인지를 센다.
그리고 이를 "시퀀스 번호"라는 TCP 헤더 항목에 기록해 둔다.
데이터를 수신하는 측에서는 패킷 전체 길이에서 제어 정보로 주어지는 헤더 길이를 뺌으로써 데이터의 크기를 얻을 수 있다.
이렇게 얻은 데이터의 길이와 시퀀스 번호를 통해 패킷에 저장되어 있던 데이터가 전체 데이터(원본 데이터)의 몇 번째 조각 데이터인지를 알 수 있게 된다.
수신 측에서 받은 데이터가 몇 번째 조각 데이터인지 알 수 있다는 것은 패킷 누락 여부도 알 수 있다는 것이다.
만약 패킷이 누락되지 않았음을 확인하면 수신 측은 송신 측에 TCP 헤더의 ACK 번호를 활용하여 정상적으로 패킷이 도착했음을 알린다.
이렇게 ACK 번호를 송신 측에 되돌려 주는 작업을 "수신 확인 동작"이라고 부른다.
ACK 번호는 다음 요청으로 몇 번째 바이트 데이터부터 보내주라는 요청과 동일하다 생각하면 된다.
수신 측에서 지금까지 받은 데이터의 크기(단위 : 바이트)를 계산한 다음 거기에 1을 더한 수를 ACK 번호에 기록한다.
이때 제어 비트의 ACK 비트 또한 1로 설정하여 ACK 번호 필드가 유효하다는 의미를 담는다.
위 사진을 통해 확인해 보자.
1개 데이터 조각은 1460 바이트 크기를 가진다. 그리고 2개 데이터 조각이 도착했다고 가정하자.
이때 수신 측에서 받은 데이터는 (정상적으로 패킷이 도착했다면) 총 2920 바이트일 것이다.
여기에 1을 더한 값이 ACK 번호이므로 ACK 번호로 2921을 세팅한 뒤 송신 측에 응답을 보낼 것이다.
송신 측은 원래 데이터의 2921번째 바이트부터 데이터를 보내야 하므로 ACK 번호 값의 바이트부터 데이터를 보내게 될 것이다.
실제 네트워크 환경에서는 위 사진처럼 시퀀스 번호가 1부터 시작하지 않고 난수값으로 지정된 초기 값으로 시작한다.
만약 시퀀스 번호가 무조건 1부터 시작할 경우 패킷에 대한 예측이 가능하므로 악의적인 공격 가능성이 존재하기 때문이다.
문제는 난수값으로 시퀀스 번호를 지정할 경우 어떤 시퀀스 번호가 초기값인지 알 수 없다는 것이다.
이런 문제를 해결하기 위해 데이터 송/수신을 시작하기 전 먼저 초기 난수값을 통신 상대에게 알리게 되어 있다.
그리고 이 과정은 이전 서버 접속 과정에서 가볍게 다뤘다.
앞에서 설명한 서버 접속 과정에서 SYN이라는 제어 비트를 1로 하여 통신 상대에게 보내는 작업이 존재했다.
바로 이 과정이 통신 상대에게 초기 시퀀스 번호 값을 알려주는 과정이다.
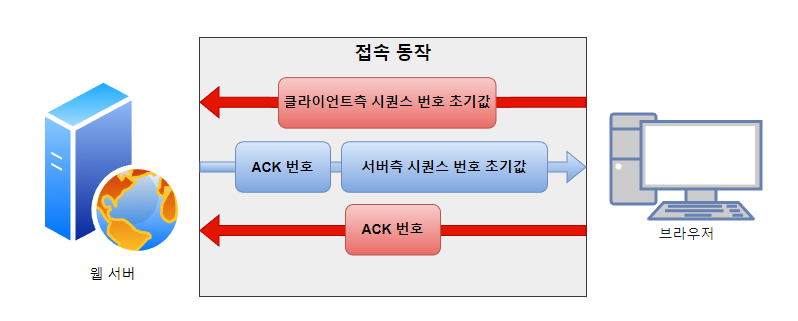
먼저 클라이언트는 SYN 제어 비트를 1로 하는 동시에 시퀀스 번호에 클라이언트 측 시퀀스 번호 초기 값을 저장하여 서버에 보낸다.
서버가 이 제어 정보를 받으면 클라이언트 측 시퀀스 번호의 초기 값을 알게 되고 이를 서버 측 메모리에 저장한다.
이후 서버는 SYN 제어 비트를 1로 만든 뒤 서버 측 시퀀스 번호 초기 값을 저장하여 클라이언트 측에 응답 형식으로 보낸다.
응답을 받은 클라이언트 또한 응답 메시지에 저장된 시퀀스 번호 값을 통해 서버 측 시퀀스 번호 초기 값을 알 수 있으며 이를 클라이언트 측 메모리에 저장함으로써 서버와 클라이언트는 통신 상대의 시퀀스 번호 초기 값을 알게 되는 것이다.
추가로 접속 과정에서 ACK 제어 비트를 1로 설정하여 응답을 보내는 이유도 알아보자.
ACK 제어 비트가 1로 설정되었다는 것은 ACK 번호에 저장된 값이 유효하다는 의미를 가진다.
서버 접속 과정에서 서로 시퀀스 번호 초기값을 주고받을 때도 보낸 패킷이 정상적으로 도착했는지에 대한 응답을 보내줘야 한다. 즉, 응답 헤더에 ACK 번호가 저장되어 있어야 한다는 것이다.
따라서 ACK 번호가 유효한 의미를 가지므로 ACK 제어 비트가 1로 설정되는 것이다.
TCP는 위에서 설명한 방식으로 데이터를 송신하고 정상적으로 도착했는지를 확인한다.
이때 패킷이 정상적으로 도착했다는 응답이 올 때까지 보낸 패킷을 송신용 버퍼 메모리에 저장해 둔다.
만약 패킷이 정상적으로 도착하지 못했다는 응답이 올 경우 저장된 패킷을 다시 보냄으로써 패킷 누락에 대비한다.
이는 매우 안전하고 강력한 구조로써 네트워크 어디에서 오류가 발생했더라도 이를 감지할 수 있고 누락된 패킷을 다시 보냄으로써 회복 처리까지 수행할 수 있다.
TCP 담당이 이런 부분을 강력하게 처리하므로 LAN 어댑터, 버퍼, 라우터 모두 회복 조치를 취하지 않는다.(정확히는 취할 필요가 없다) 이들은 오류가 검출될 경우 패킷을 버리는 역할만 수행한다.
단, 케이블이 분리되어 물리적인 연결이 끊겼거나 서버가 다운되어 메시지를 받을 대상이 존재하지 않을 수 있다.
이 경우 TCP가 패킷이 누락되었다 판단하여 계속해서 패킷을 보내면 자원의 낭비로 이어질 것이다.
따라서 TCP가 패킷을 몇 번 다시 보내도 정상적인 응답이 오지 않으면 회복 가능성이 없는 것으로 간주하여 데이터 송신 동작을 강제 종료하고 애플리케이션 측에 오류를 통지한다.
데이터 수신
◎ read
위 과정을 통해 데이터를 송신했으니 통신 상대에게 데이터가 전달되었을 것이고 통신 상대가 보낸 응답 메시지를 받는 데이터 수신 작업이 수행되어야 한다.
브라우저는 응답 메시지를 받기 위해 Socket 라이브러리의 read 프로그램을 실행시킨다.
애플리케이션에서 read 함수를 실행시키면 프로토콜 스택에게 제어권이 넘어간다.
제어권을 받은 프로토콜 스택은 수신한 데이터를 바로 애플리케이션에 보내는 것이 아닌 수신 버퍼에 잠시 데이터를 저장할 것이다.
이때 Request를 보내자마자 Respose가 오지 않고 응답 메시지가 돌아올 때까지 잠시 시간이 걸리므로 프로토콜 스택은 수신 작업을 보류한다.
서버에서 보낸 응답 메시지의 패킷이 도착하여 수신 버퍼에 저장되었을 때 프로토콜 스택은 수신 작업을 재개한다.
이후 수신 버퍼에서 수신 데이터를 추출하여 애플리케이션에게 건네줄 것이다.
자세한 수신 작업은 데이터 송신 작업에서도 설명한 부분이므로 간단히만 알아보자.
먼저 TCP 헤더를 조사하여 누락된 패킷이 있는지 확인하고 문제가 없으면 ACK 번호를 반송한다.
이후 데이터 조각을 수신 버퍼에 임시보관한 뒤 저장된 데이터 조각들을 연결하여 원래 모습인 Respond Message 형식으로 복원한다.
이렇게 복원한 수신 데이터를 애플리케이션이 지정한 메모리 영역에 저장시킨 뒤 애플리케이션에게 제어를 되돌려주면 애플리케이션은 Respond Message를 인지할 수 있게 된다.
이후 타이밍을 가늠하여 윈도우를 데이터 송신 측에 통지함으로써 데이터 수신 작업이 종료된다.
(윈도우는 나중에 오류 검출 & 회복 Section에서 자세히 알아보자)
