이번 글은 나만의 AI Server를 만드는 것입니다.
ChatGPT를 사용하다보면 정말 만족스러울 정도의 경험을 하기도 하는데요. 그러다보면, 나만의 AI를 가지고 싶어집니다.
저는 AI를 정말 유용하게 쓰고 있는데, 문득 이 서비스가 사라진다면 너무 불편할 것 같아서 나만의 AI서버 만드는 방법이 정말 솔깃하게 다가오더라구요.
이번 글은 How to make my own AI Server 입니다.
0. Setup
윈도우의 WSL(Windows Sub Linux) 기능을 통해 윈도우에서 리눅스를 이용할 것이기 때문에 WSL을 설치해야합니다.
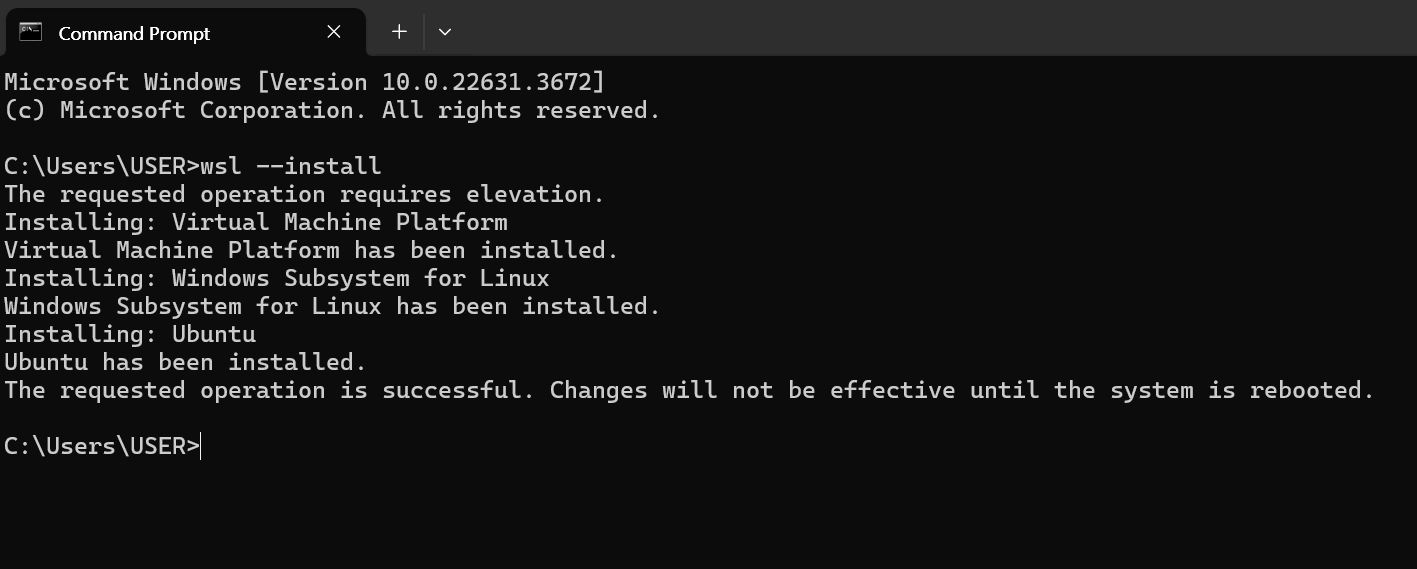
재부팅 후에는 아래와 같이 Linux가 실행됩니다. 동일한 화면이라면 성공적으로 준비완료되었습니다.
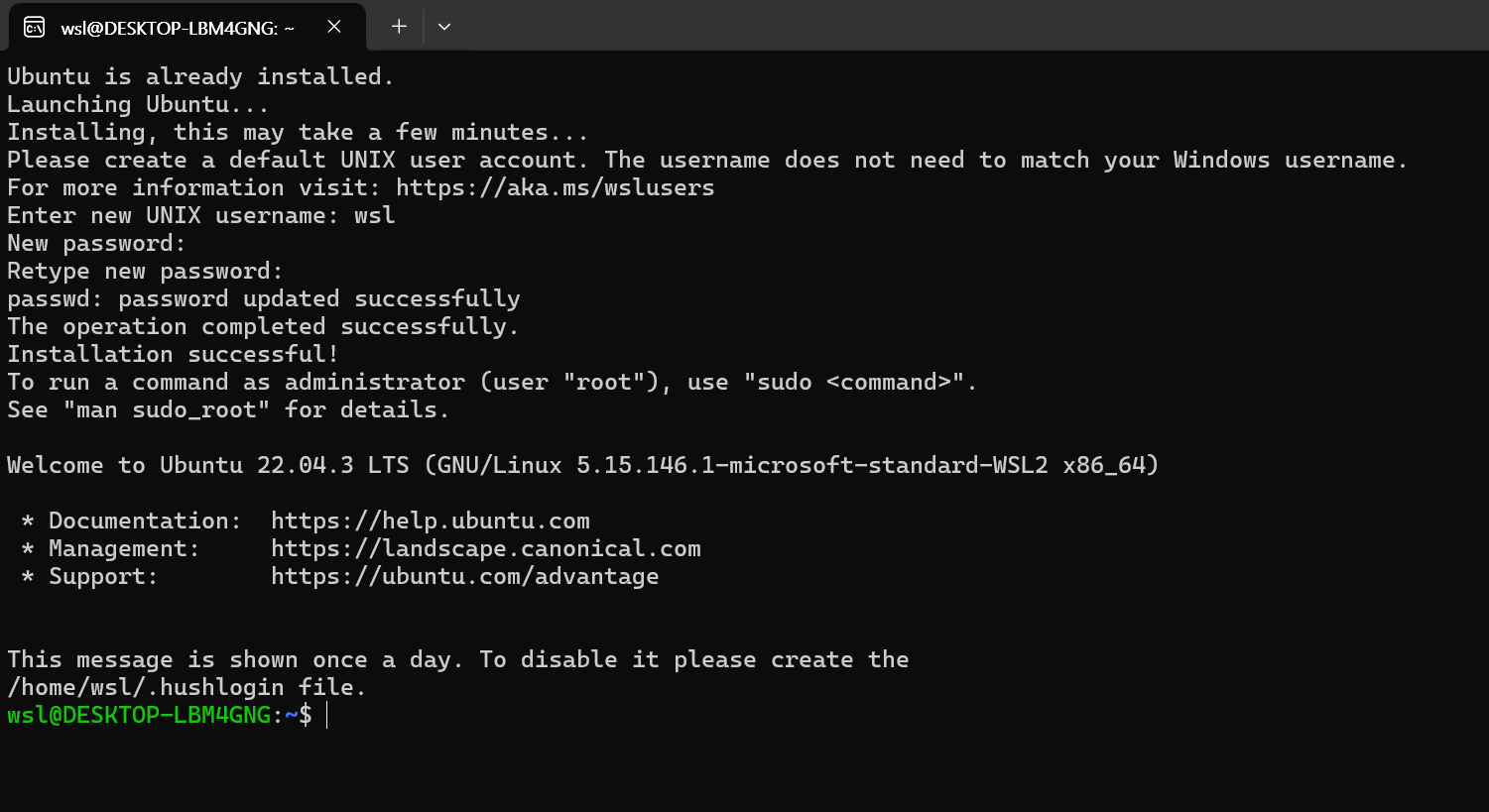
마지막으로 리눅스 패키지들을 업데이트 해줍니다.
sudo apt-get update
sudo apt-get upgrade -y
ㅤ
1. Ollama 설치 및 실행
우선 https://ollama.ai 로 접속합니다.
저는 win11 환경을 사용하고 있습니다. 하지만, 올라마의 경우 윈도우는 preview 버전을 제공하고 있기에 Linux 를 사용할 계획입니다.
위에서 설치한 WSL에서 아래의 command를 입력합니다.
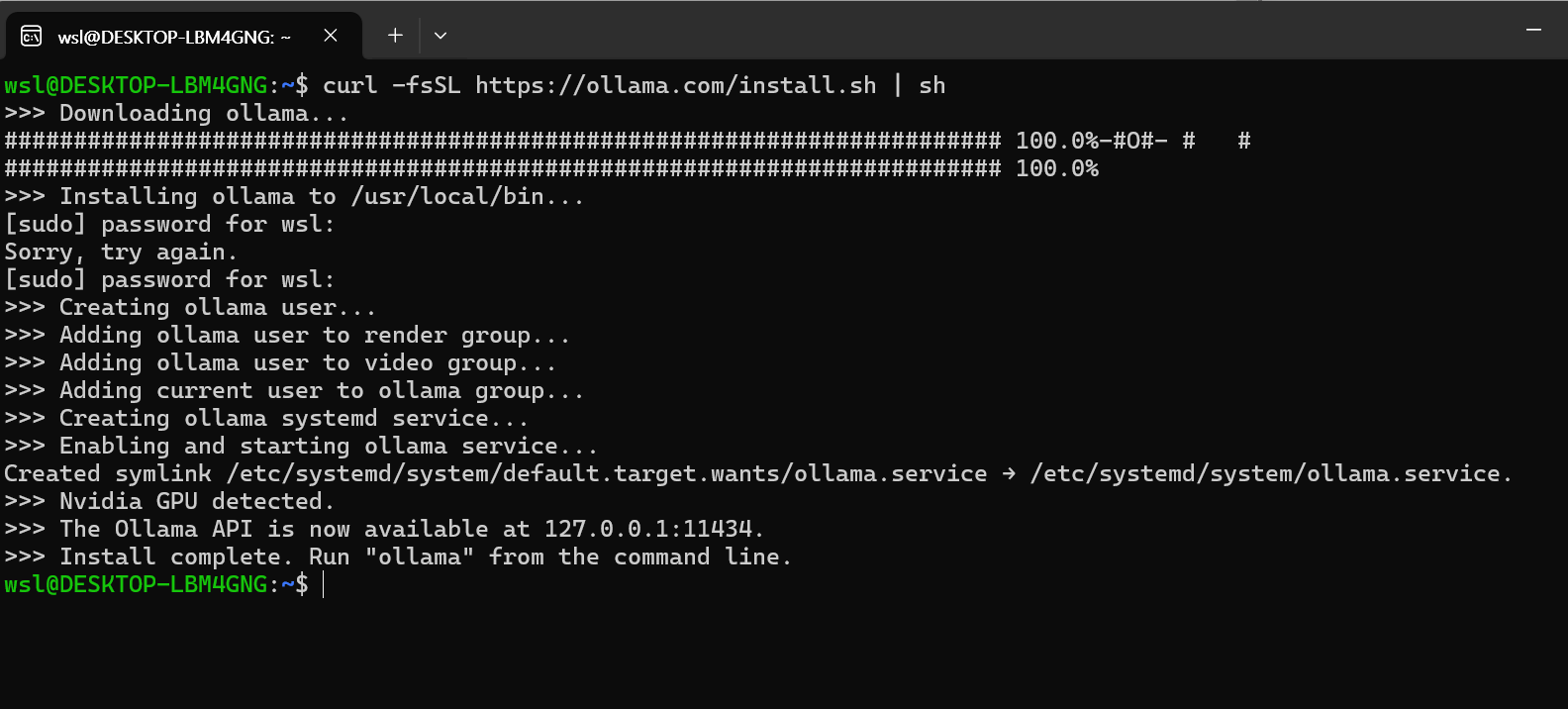
curl -fsSL https://ollama.com/install.sh | sh이미지와 같이 성공을 확인할 수 있는데, Ollama는 GPU를 자동적으로 찾아냅니다 ("Nvidia GPU Detected")
만약 GPU가 있는데 찾아내지 못했다면 관련 드라이버를 설치해주셔야합니다.
이제, 올라마가 정상적으로 동작하는지 확인을 해야합니다.
이미지에서처럼 127.0.0.1:11434 라고 안내되는데 이를 통해 브라우저에서 접근할 수 있습니다.
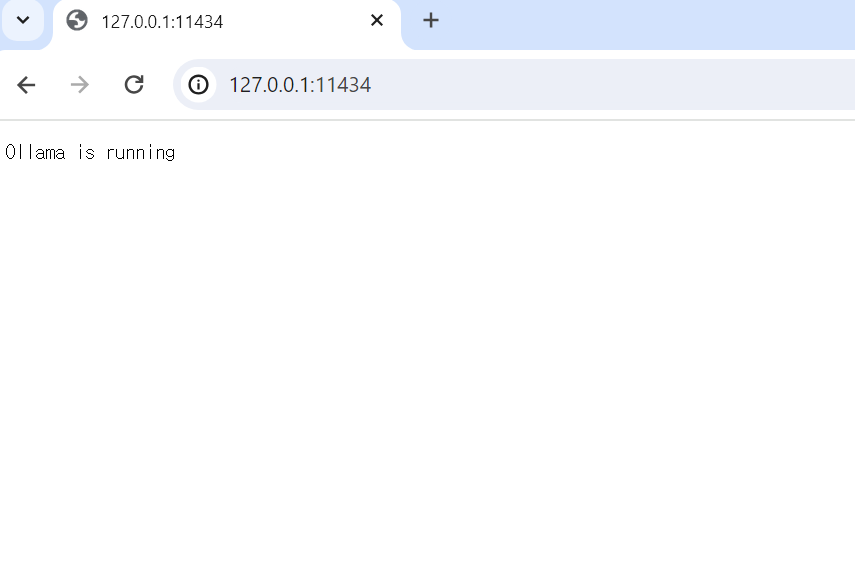
Running이 확인된다면 Ollama API Service가 정상적으로 동작 중이라는 의미입니다.
2. Add AI Model to Ollama
Ollma에서 추가할 수 있는 AI모델은 아래의 URL에서 확인할 수 있습니다.
https://ollama.com/models
1) llama2 를 추가해줍니다.
ollama pull llama2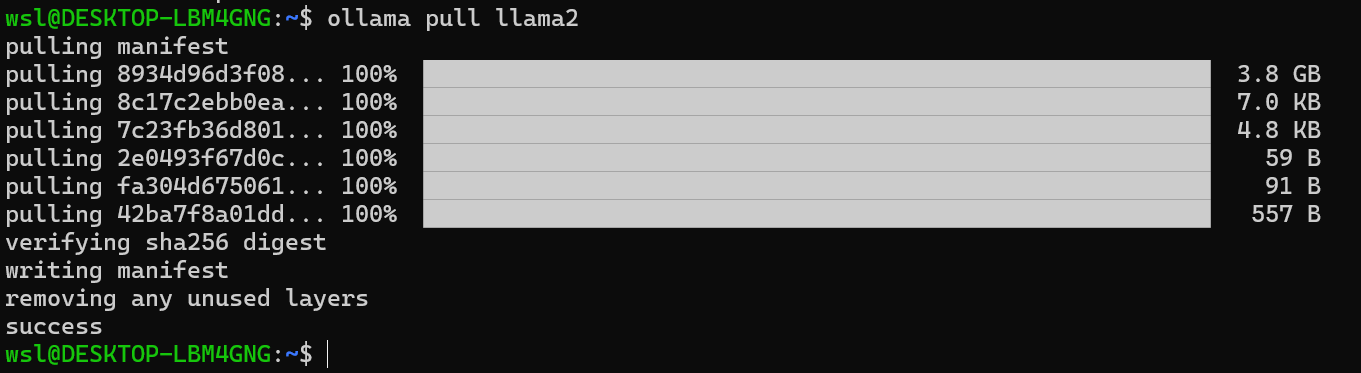
2) llama2 실행
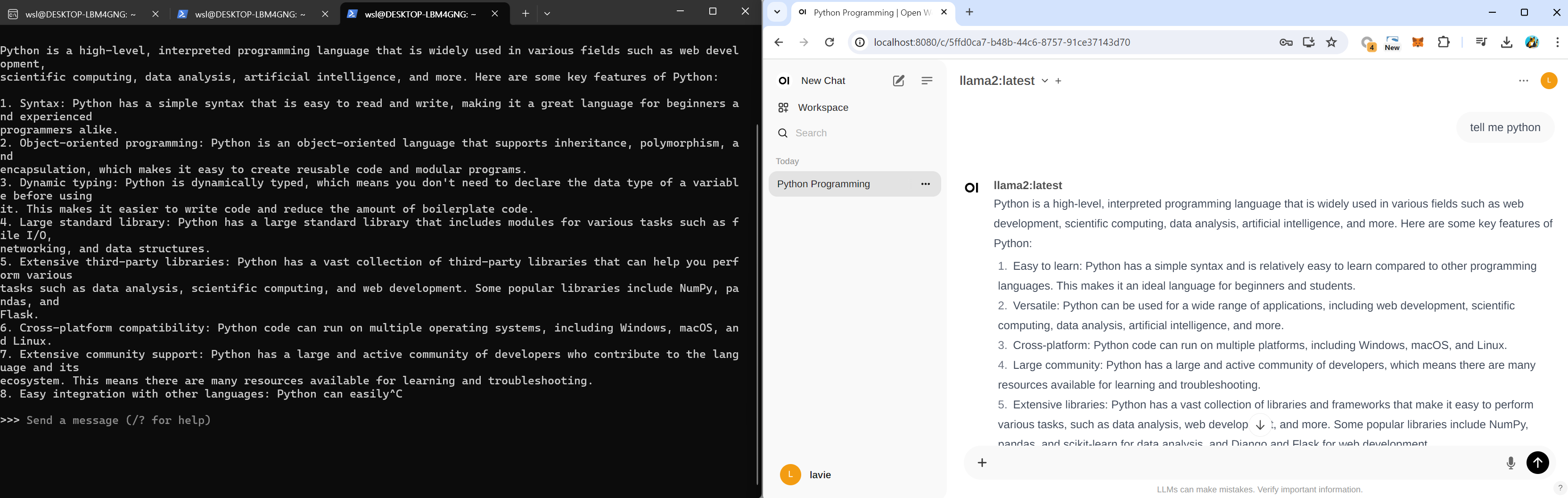
아래의 명령어를 통해서 추가한 AI Model "llama2"를 실행할 수 있습니다. chatGPT와 같이 질문하고 그에 관한 응답을 받을 수 있습니다.
Ctrl+C를 통해 출력을 중간에 멈출 수도 있습니다.
ollama run llama2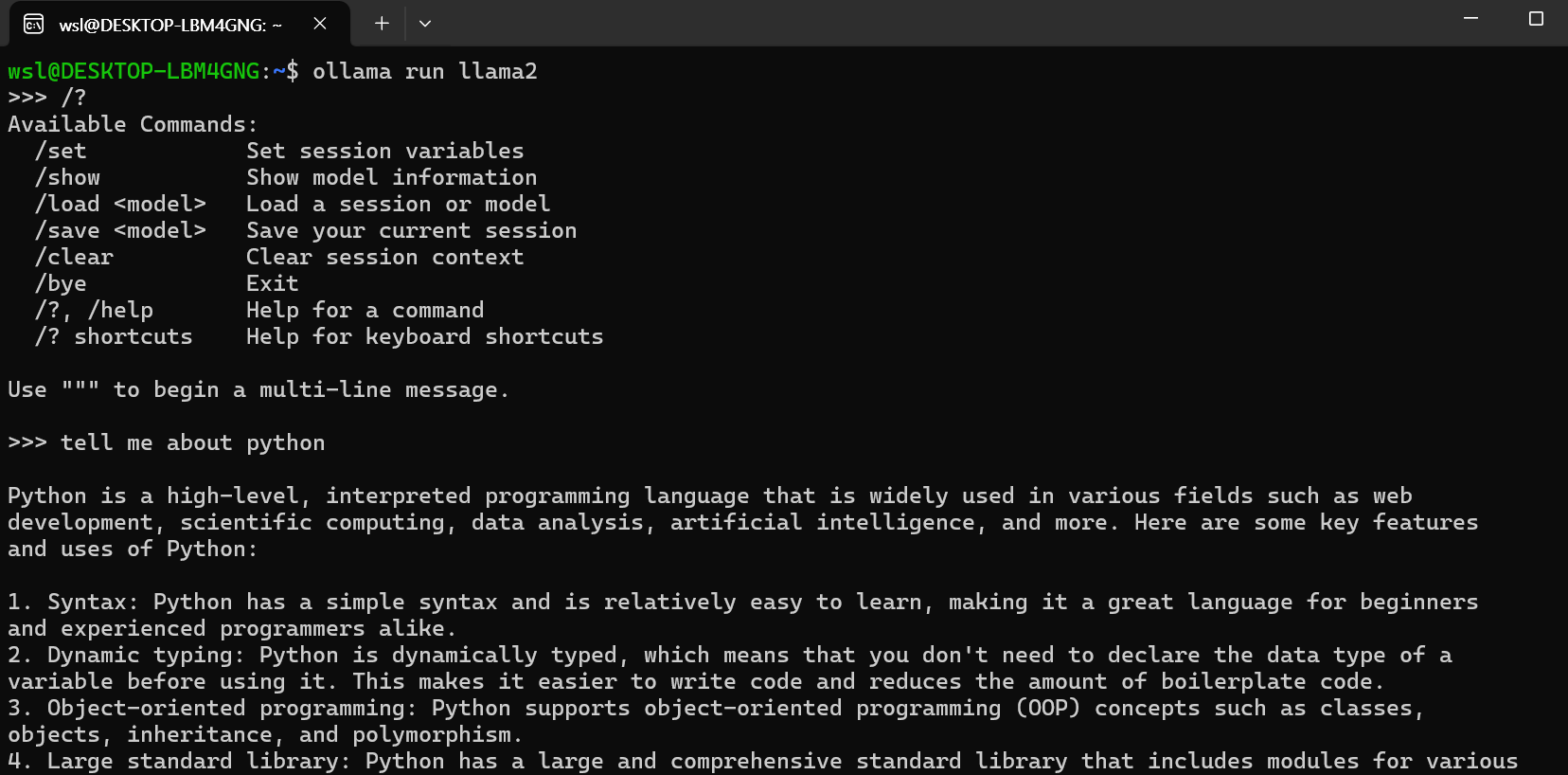
한글로 응답받는 것도 가능합니다. Good😊

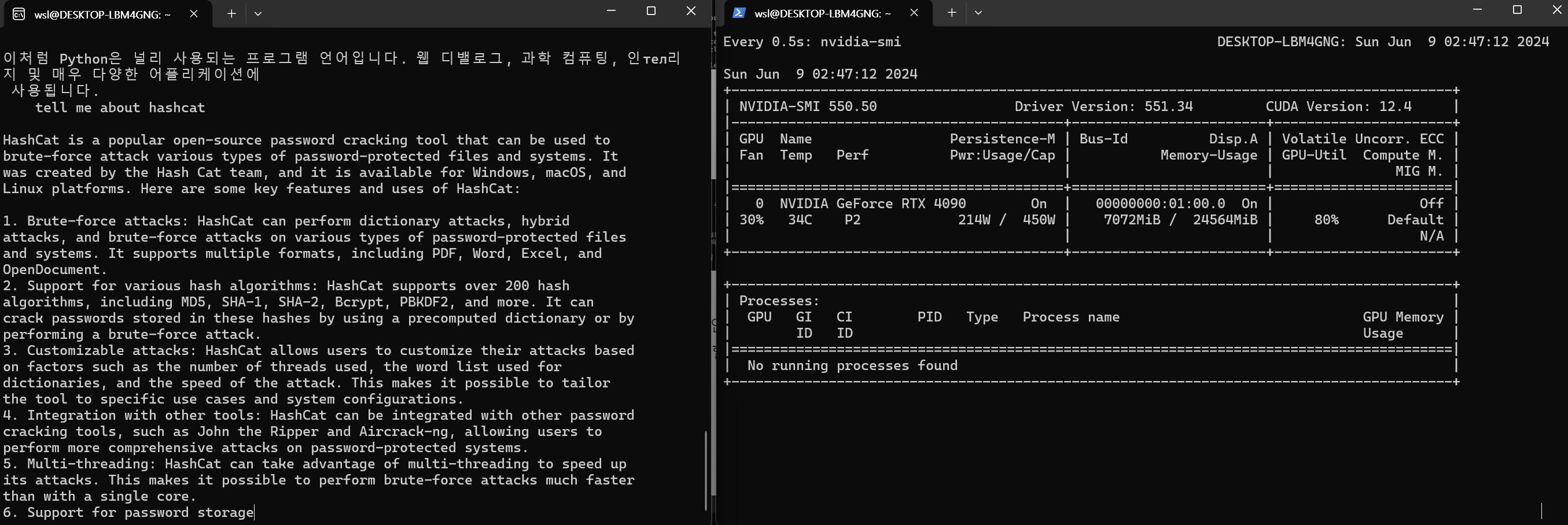
AI서버가 동작하면서 사용되는 GPU의 Performance를 확인하고 싶다면 아래와 같이 다른 터미널에서 명령어를 입력해서 할 수 있습니다.
watch -n 0.5 nvidia-smi
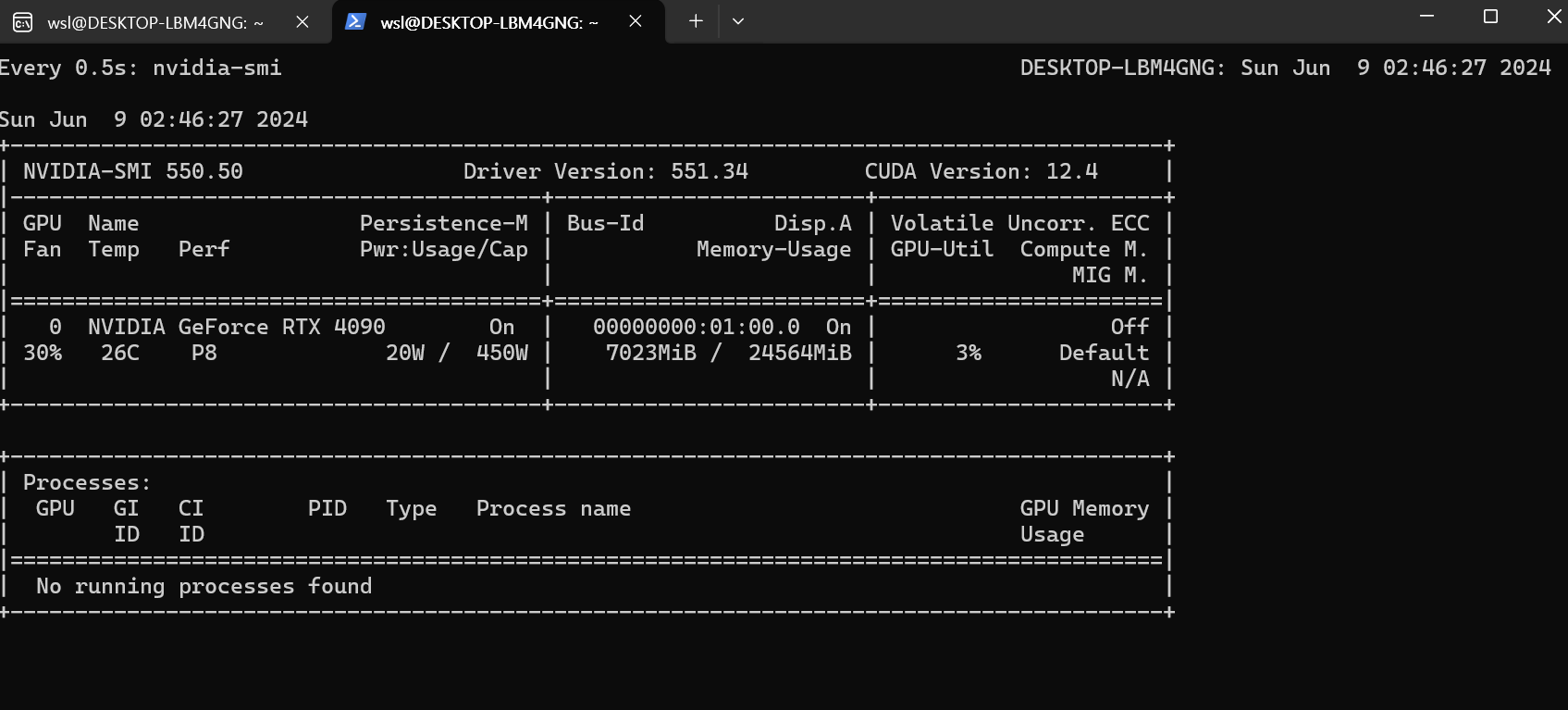
llama2 모델과 상호작용하는 과정에서는 사용량과 전략이 상승하는 것을 실시간으로 관찰할 수 있습니다.
/bye를 통해서 세션을 끝낼 수 있습니다 (도움말 : /?)
/bye3. "Open WebUI" for AI server
Open WebUI는 Docker에서 동작합니다.
1) ubuntu에서 Docker 설치
ubuntu에서 아래의 명령어를 실행합니다.
업데이트하고 도커의 GPG키를 가져옵니다.
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
다음 명령어까지 입력해주면 Docker설치가 완료됩니다.
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
위의 과정에서 오류 발생 시, 아래로 재시도
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
echo \
"deb [arch=$(dpkg --print-architecture)] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin2) open web UI 컨테이터 배포
아래의 명령어를 입력해주세요
sudo docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
이 때에 Ollama base URL (localhost:11434)가 사용된 것을 볼 수 있는데 이것은 host network(--network=host)와 통합하기 위한 것입니다.
open web ui는 포트 8080을 써서 접근합니다.
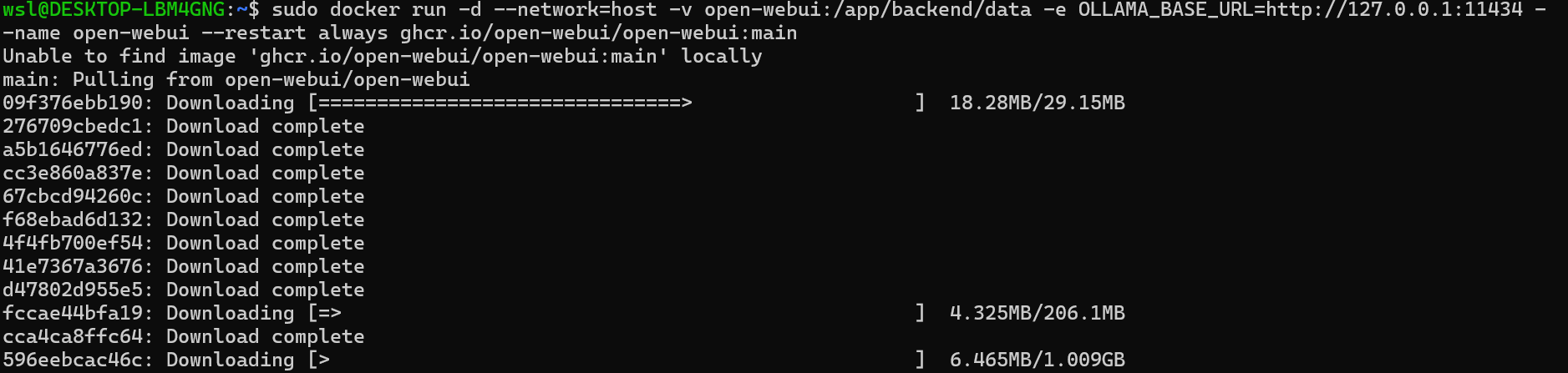
다음 명령어로 동작을 확인합니다.
$sudo docker ps
3) open web UI 접속/로그인
웹 브라우저에서 localhost:8080 으로 접근합니다.
Sign-up을 해줍니다.
이 때 생성되는 계정은 해당 인스턴스에서만 유효합니다.
계정을 생성하면 로그인이 됩니다.
chatGPT와 매우 흡사한 형태의 web UI를 볼 수 있습니다.
알아두어야할 것은 로그인한 첫 계정 혹은 생성된 계정은 자동적으로 admin 계정이 된다는 것입니다.
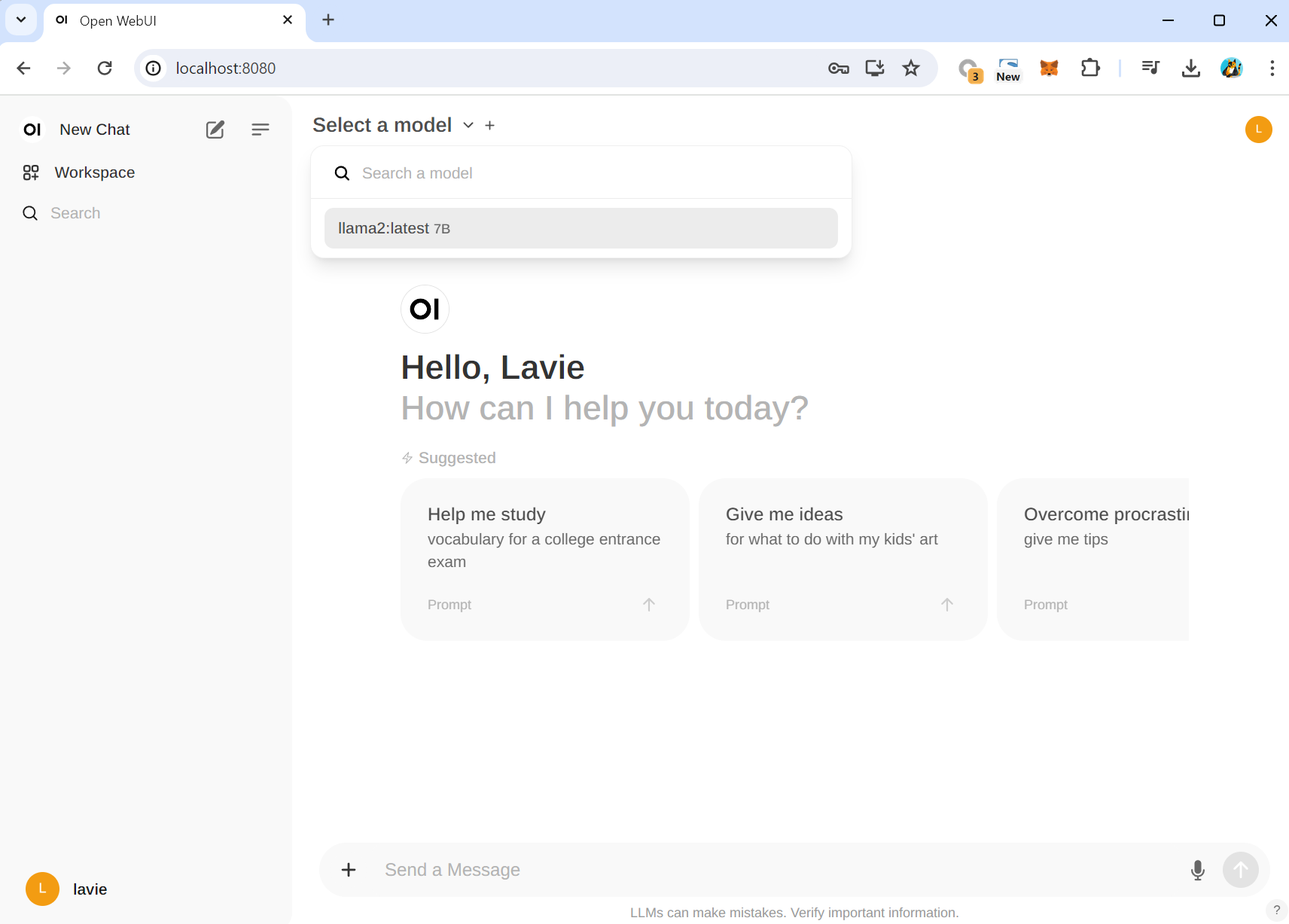
4) oepn web UI 사용
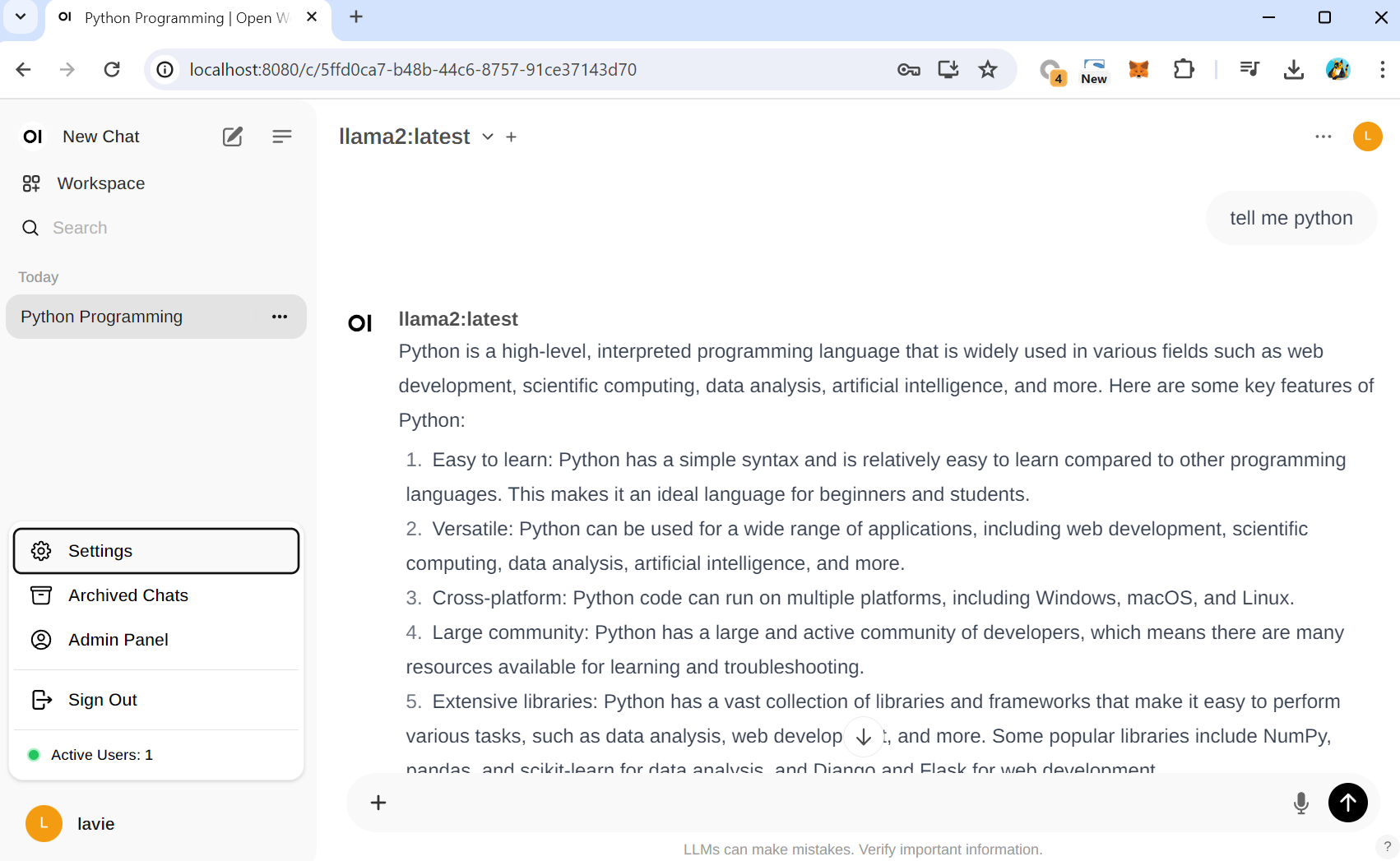
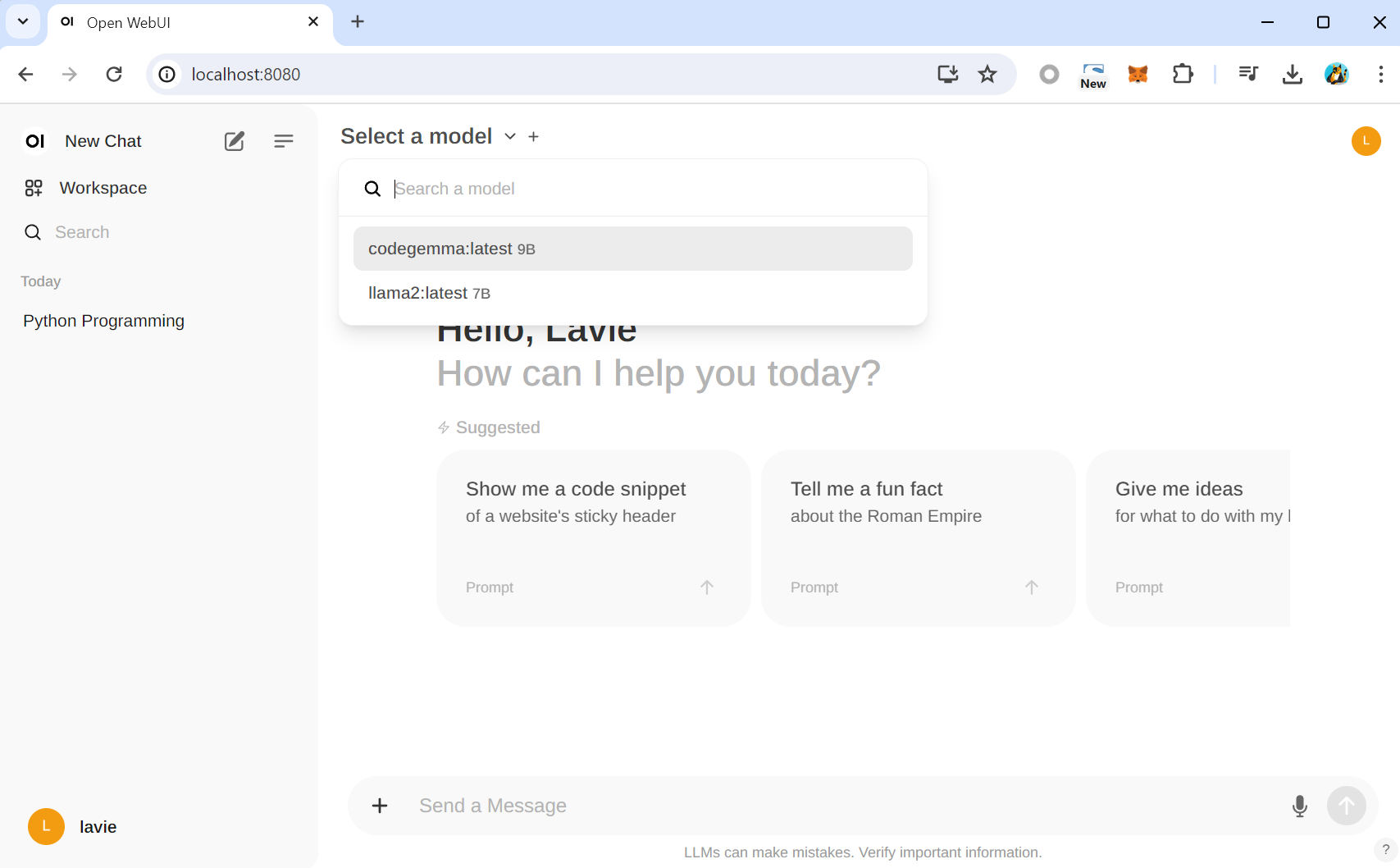
Select a model 에서 llama2를 선택할 수 있습니다.
이 llama2는 앞에서 ollama AI Model 추가를 했었던 그 모델입니다. 즉, open web ui와 ollama는 현재 연동되어있는 상태이며 편리한 화면을 통해서 AI 모델들을 사용하는게 현재 open web UI 환경구성의 목적입니다.
기존의 왼쪽과 같은 CUI 환경에서의 AI모델과 오른쪽의 open web UI (GUI)환경에서의 AI모델은 기능적으로 동일하게 동작합니다.
여기까지의 단계만으로도 나만의 chatGPT를 얻게 되는 것과 똑같습니다 (my own AI server)
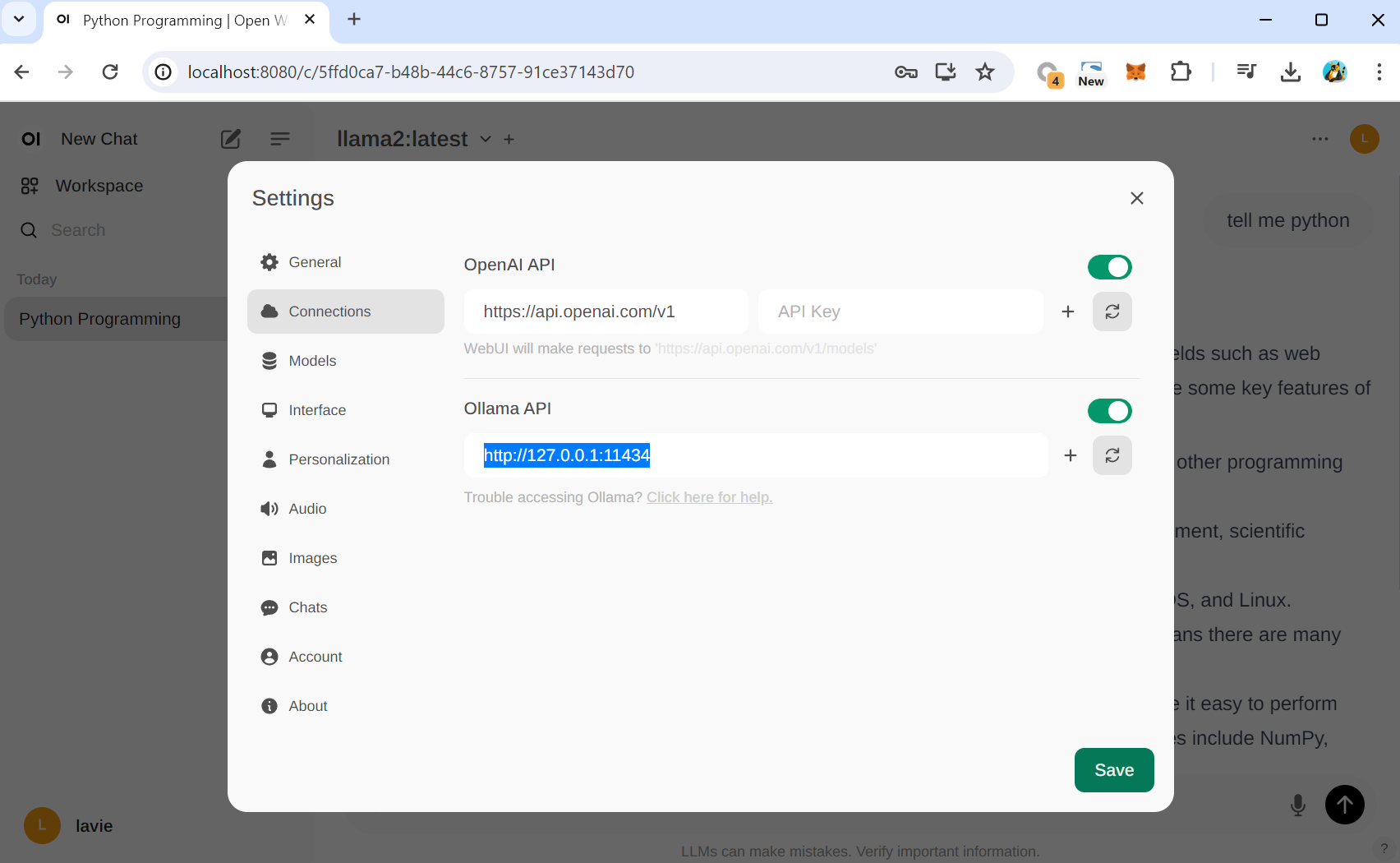
Ollama와의 연동은 Settings - Connections 에서 확인할 수 있습니다.
5) Add AI Model
여러 올라마의 AI모델은 아래의 링크에서 확인할 수 있습니다.
https://ollama.com/library
이번에는 CodeGemma를 추가해보겠습니다.
CodeGemma는 Google DeepMind에서 개발한 AI모델로 코딩 작업을 지원하기 위해 설계된 모델입니다. 이 모델은 코드 완성, 코드 생성, 수학적 추론, 자연어 이해 등의 다양한 작업을 수행할 수 있도록 특화되어 있습니다.
$ ollama pull codegemma
ollama에 AI 모델을 추가 후 open web UI를 통해 간편하게 이용할 수 있습니다.
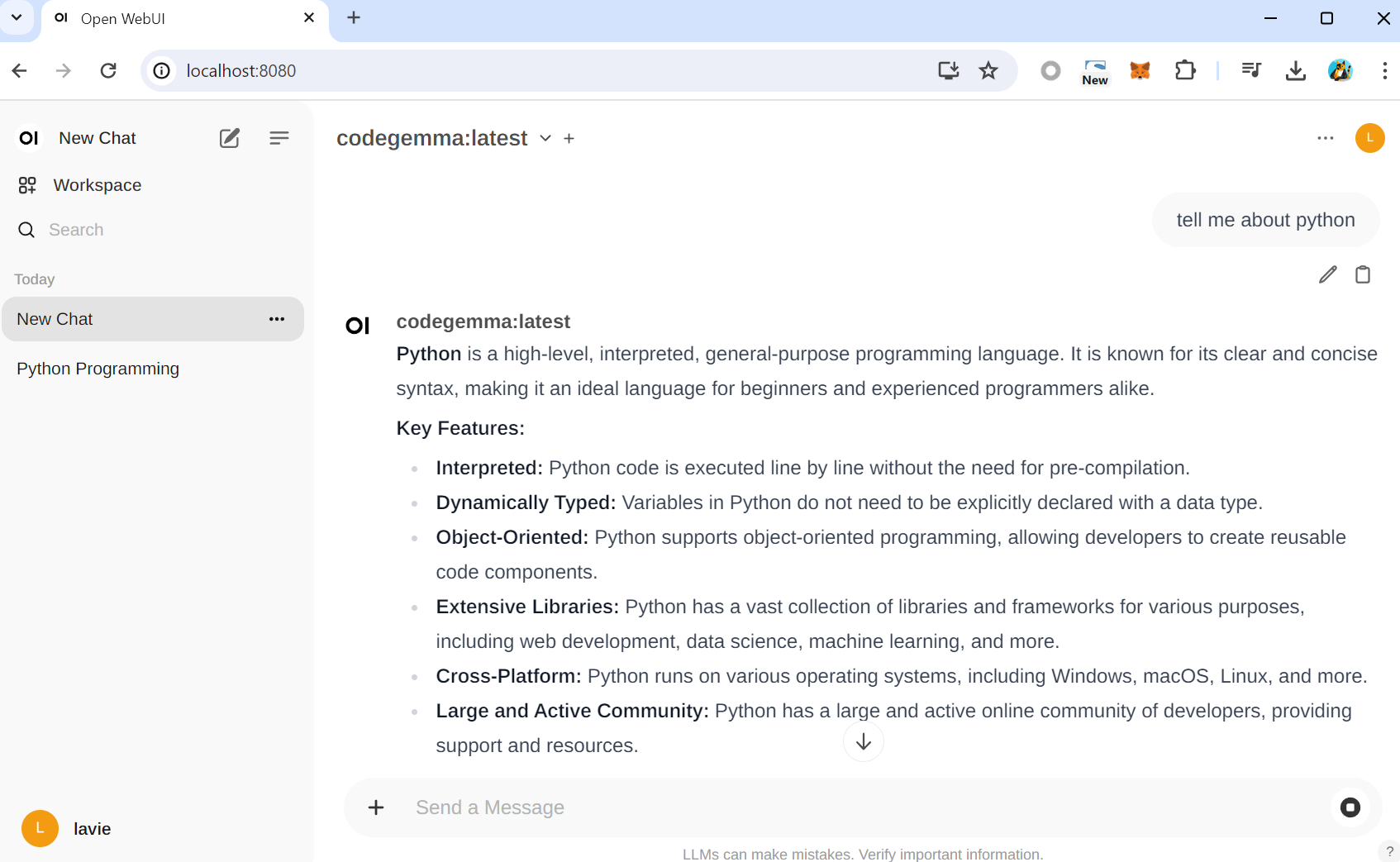
6) AI Model 동시 사용하기
open web UI에서는 AI Model들을 동시에 사용할 수 있습니다.
방법은 간단합니다.
add model을 하고
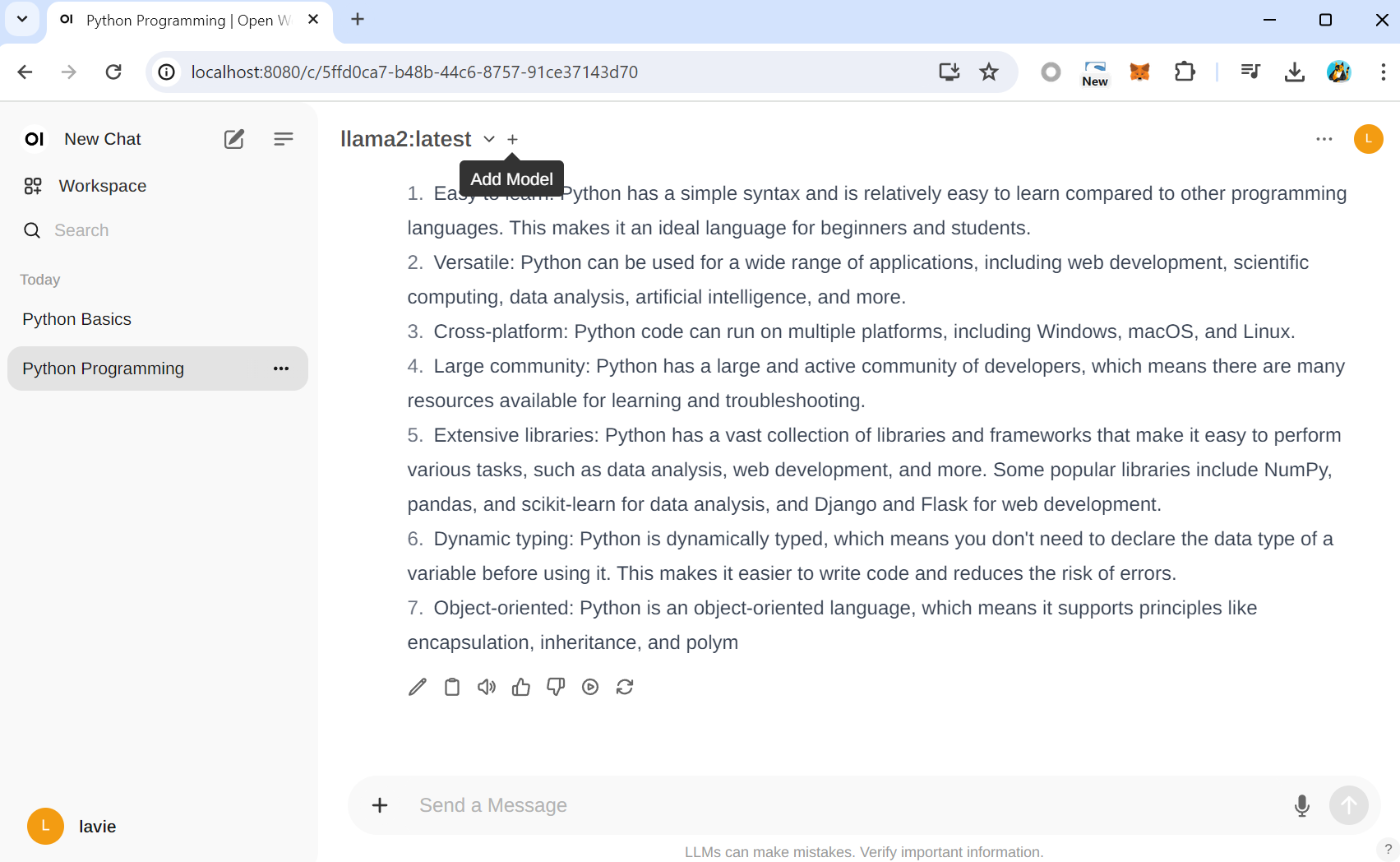
다른 AI 모델을 선택해줍니다.
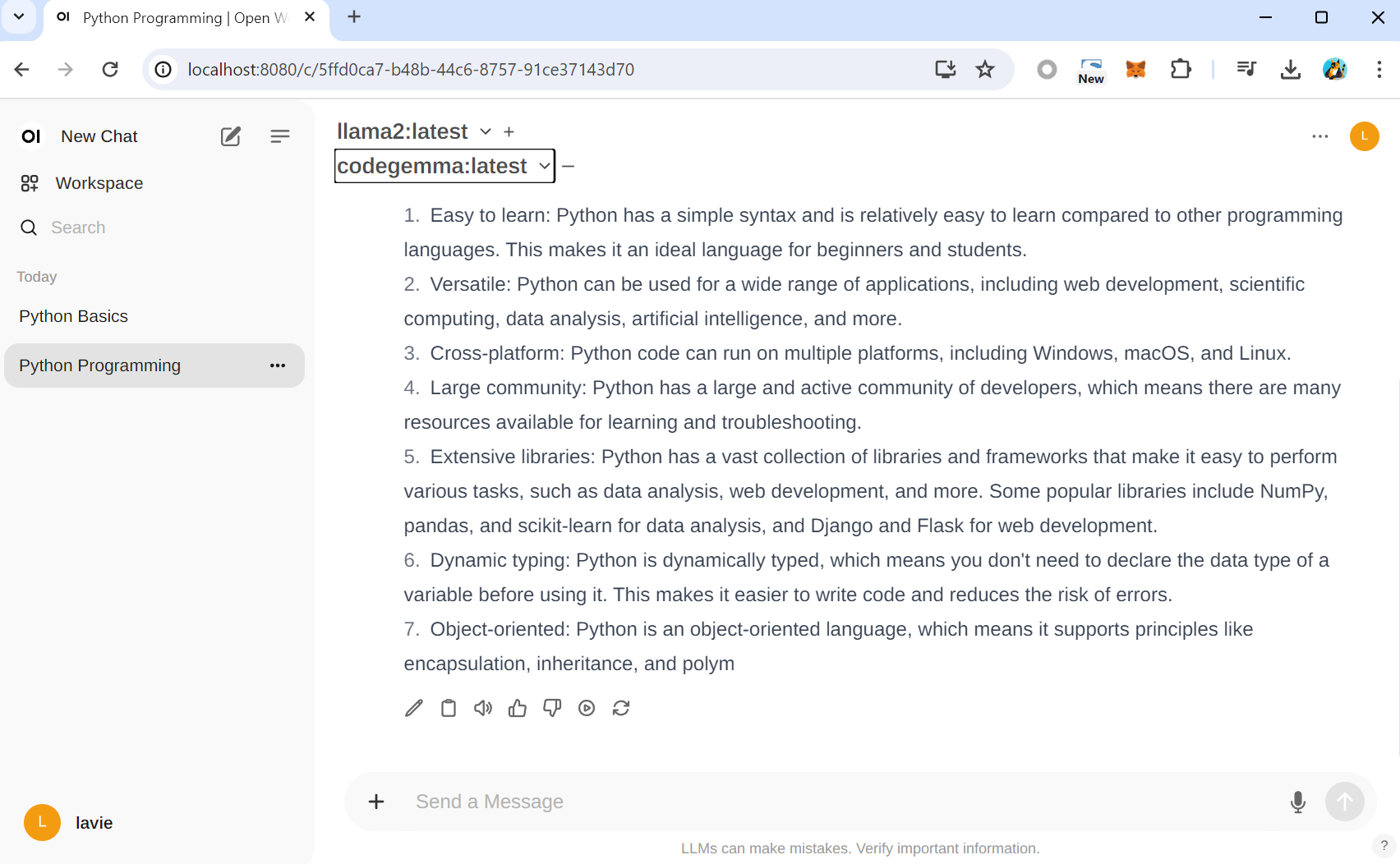
동시에 두 AI모델을 이용해서 응답을 한번에 볼 수 있습니다
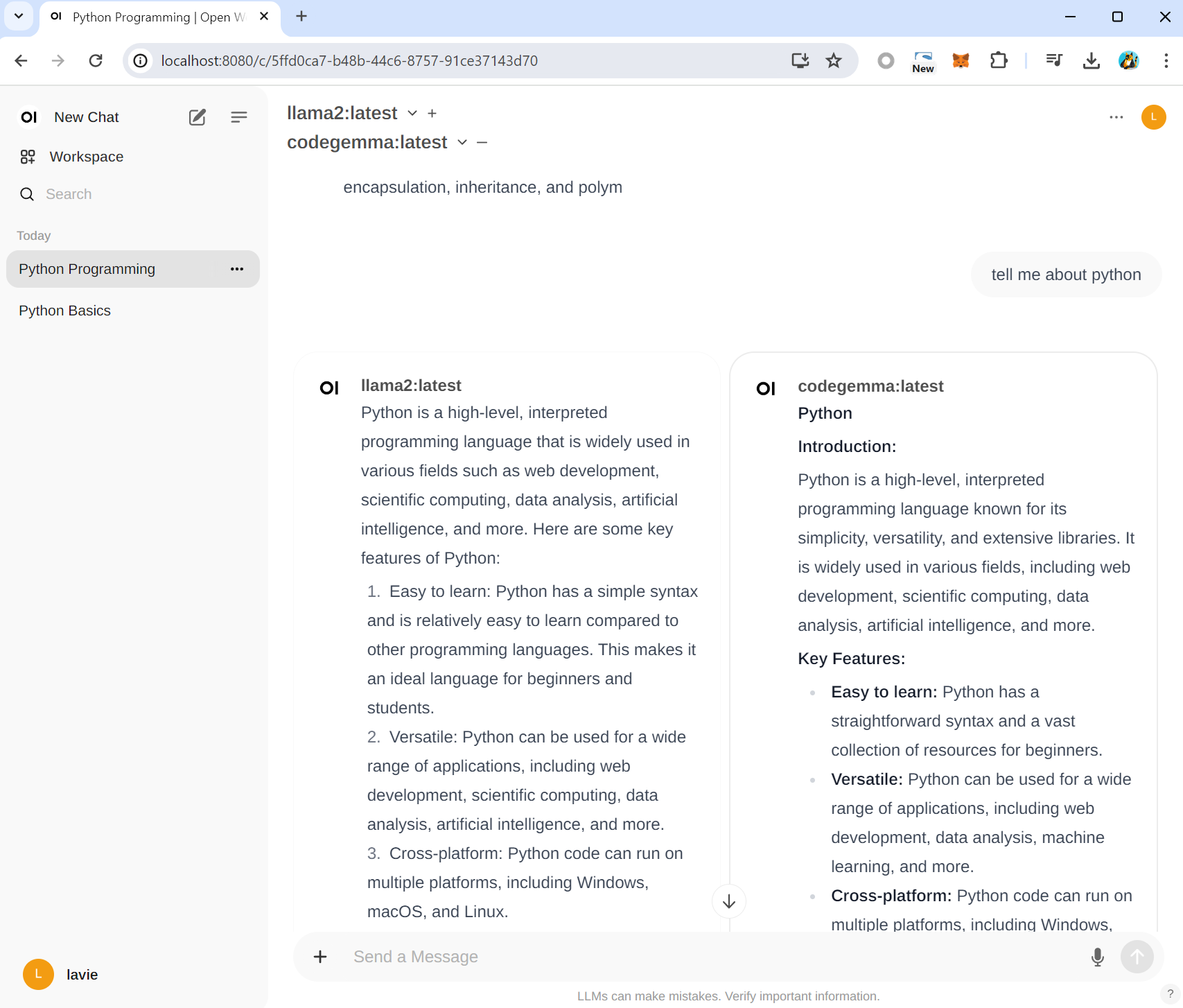
- 사실 AI모델간의 응답이 통합되어 conversion되는 것으로 알고 있었는데.. 각각 응답이 출력되네요. 혹시 그러한 설정정보를 알고 있으시다면 댓글 부탁드립니다.
7) Open web UI 기능들
응답결과에 대해 Good/Bad Response 등의 피드백을 통해 로컬 AI 서버이더라도 더 나은 성능을 발휘할 수 있도록 학습튜닝할 수 있습니다.
Record Voice 기능을 통해서 STT(Speach To Text)를 할 수도 있습니다. 정말 chatGPT의 거의 모든 요소들을 똑같이 나만의 AI서버로 쓸 수 있는 환경이 주어지는 것이죠. open web UI는 정말 유용합니다. 물론, 다른 여러 UI환경들이 존재하니 선택은 취향입니다.
@ mention 기능을 통해서 호출한 모델로 질문을 전달할 수도 있습니다. 매번 AI모델을 선택하거나 AI마다 세션을 다르게 만들필요가 없습니다.
+버튼을 통해서 upload files도 가능합니다.
llava AI Model을 이용해서 그림을 분석할 수 있습니다.
ollama를 통해 pull하고 open web UI에서 사용합니다.
(llama2의 경우 AI언어 모델이라 그림분석이 어렵습니다)
$ ollama pull llava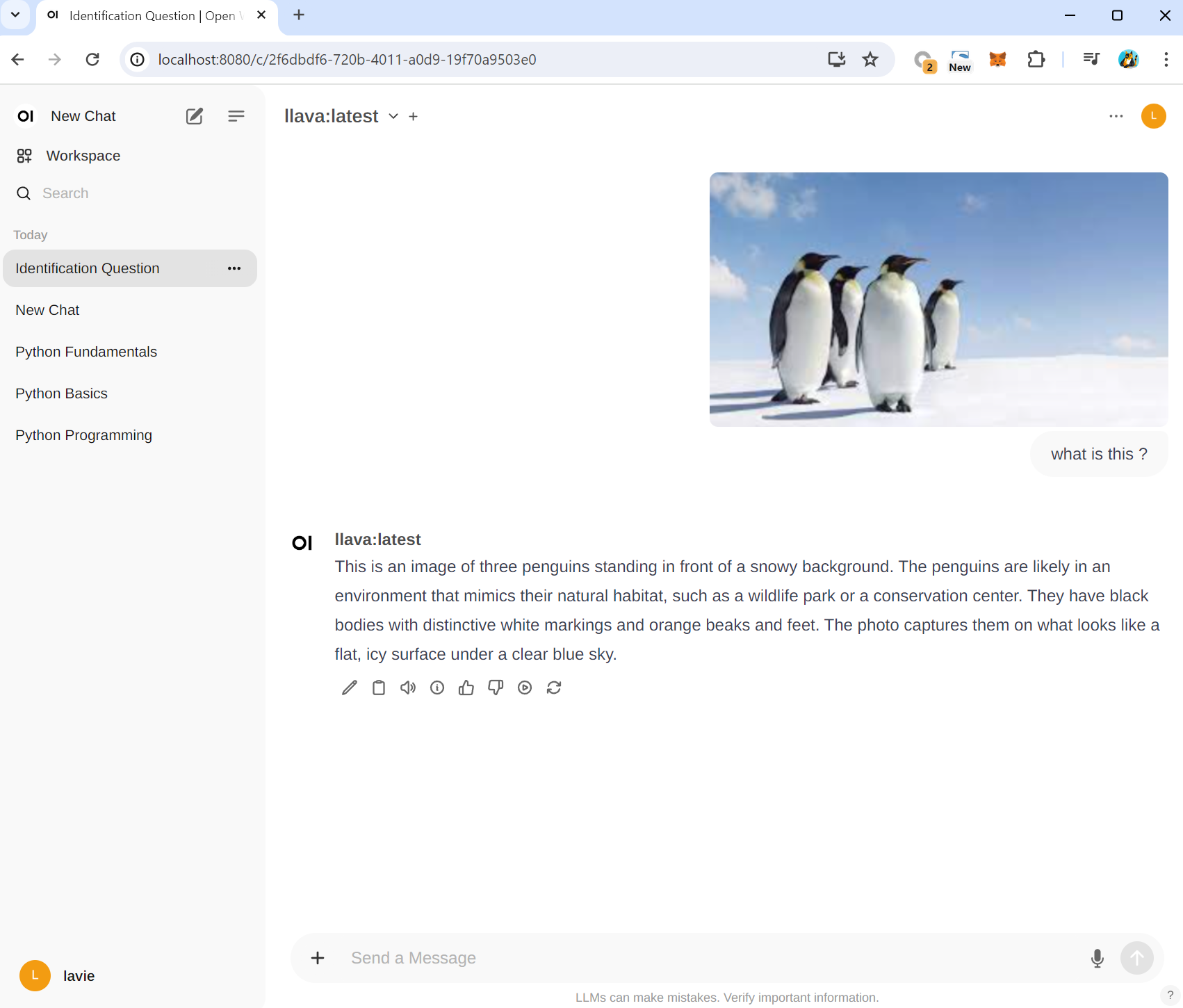
8) Open web UI 사용자 추가 (add new user)
Admin Panel - Admin Settings
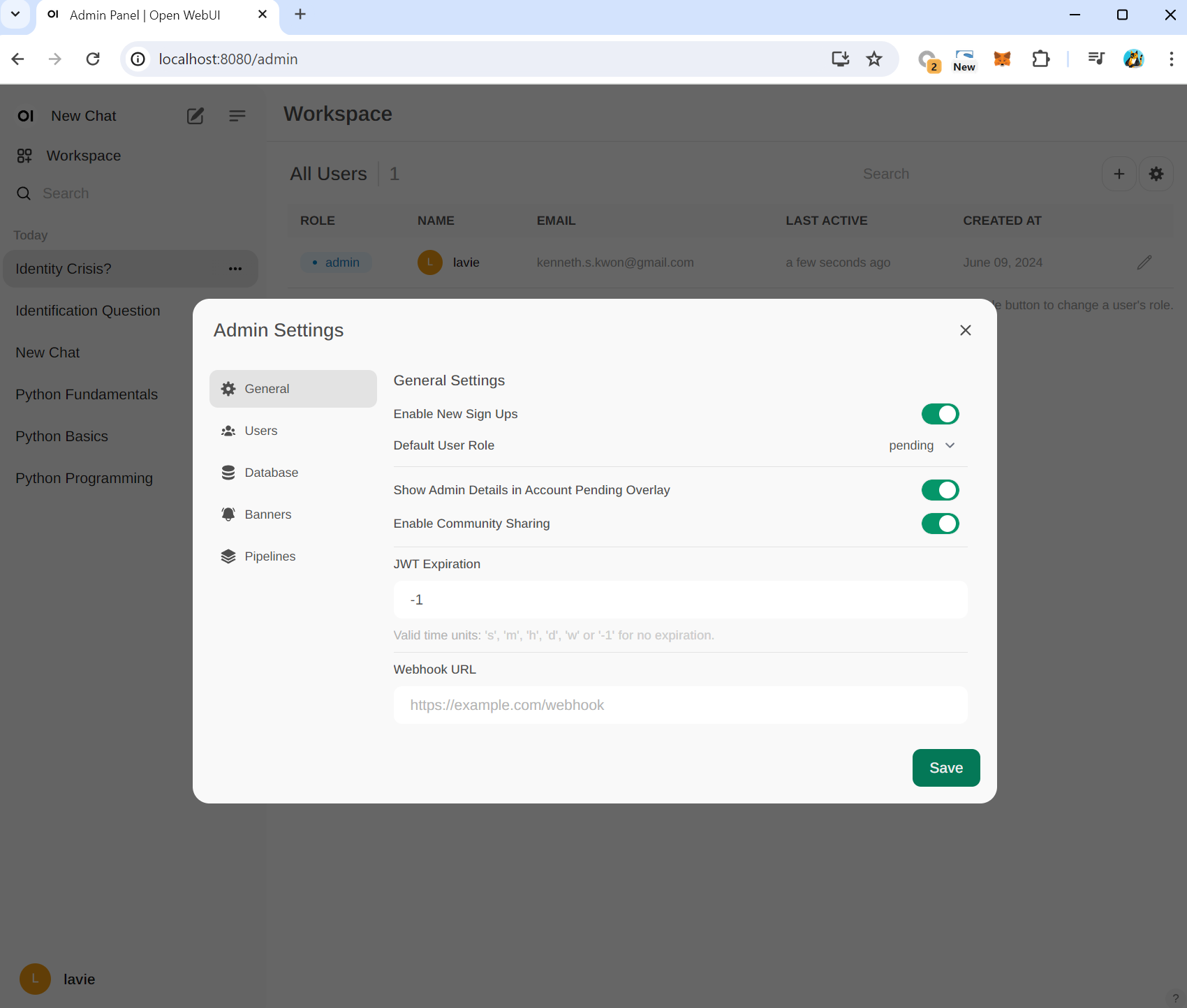
최초설정은 회원가입 허용(enabled), 회원가입 시 대기 (pending) 설정으로 되어있습니다.
새롭게 사용할 사람은 IP주소로 접근 후 회원가입하여 승인을 통해 이용할 수 있습니다.
관리자는 아래와 같은 화면을 통해 가입승인을 할 수 있습니다.
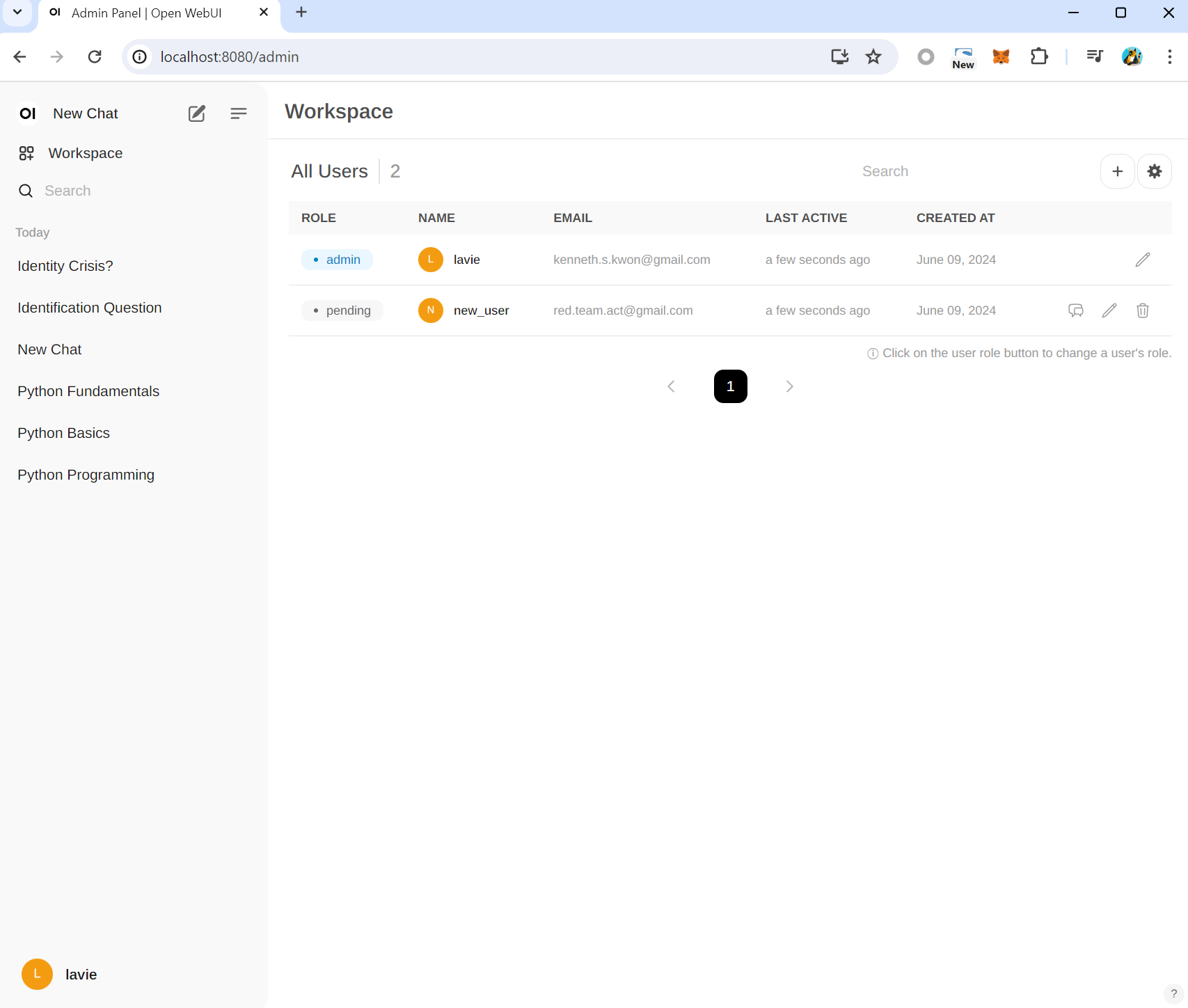
관리자는 특정 사용자에게 whitelist방식으로 AI 모델 허용을 할 수 있으며 같은 관리자 권한을 부여할 수도 있습니다.
(in Admin Settings)
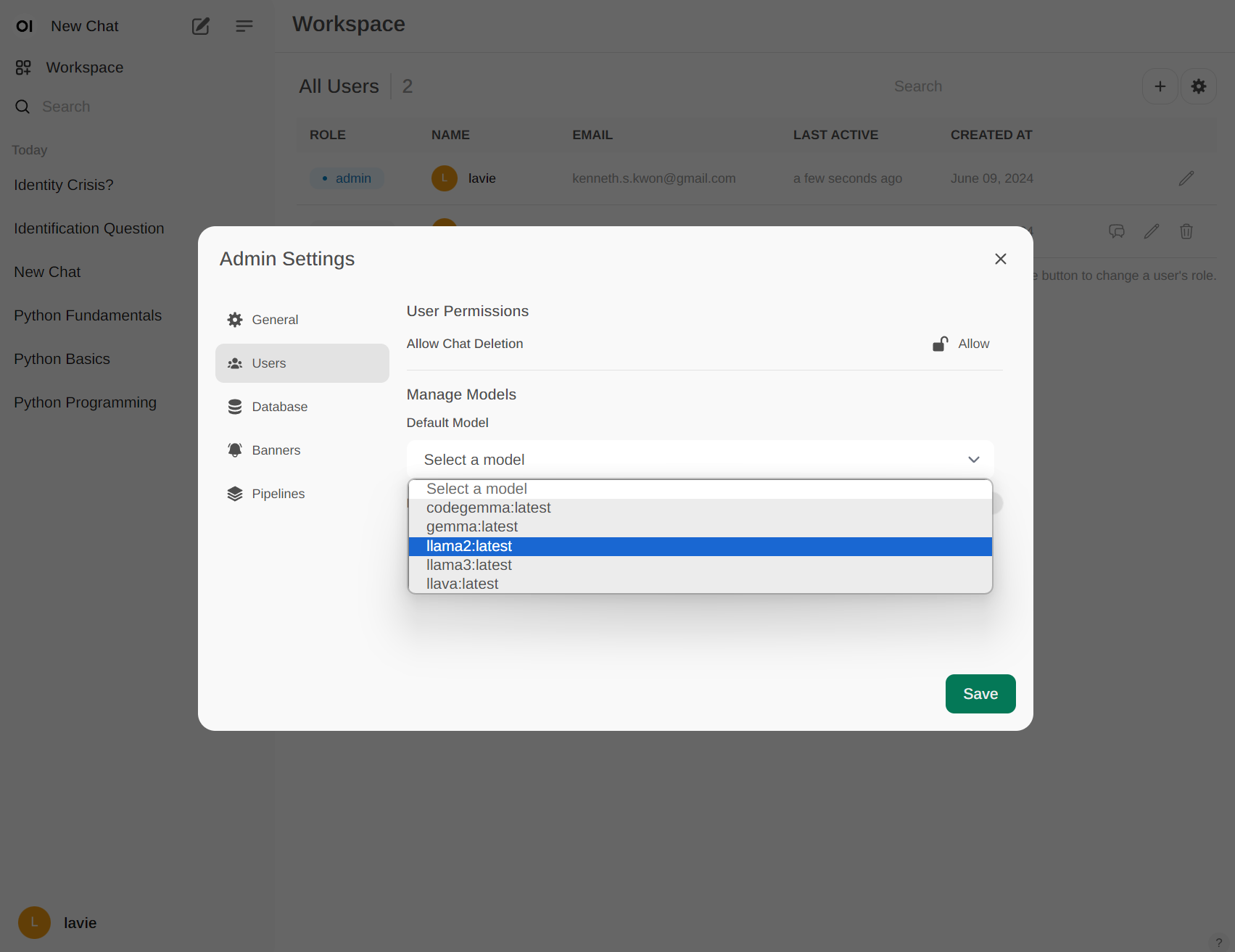
사용자에게 부여해주는 AI모델은 Custom AI 모델을 만들어서 설정하는 것이 가능합니다. 기본 시스템 프롬프트를 작성하여 적용시키거나 사용자에게 사용법을 안내할 수도 있습니다.
(in WorkSpace)
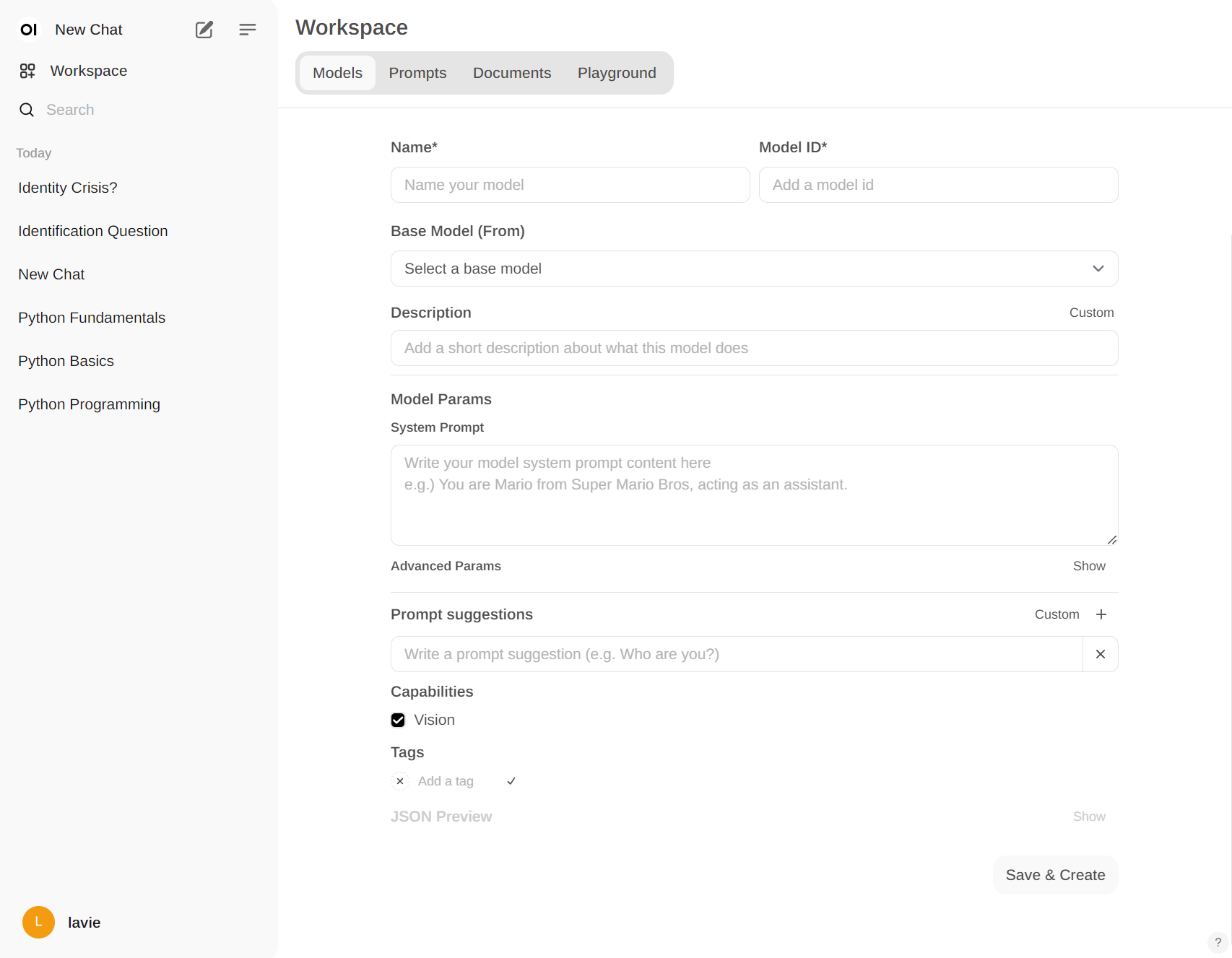
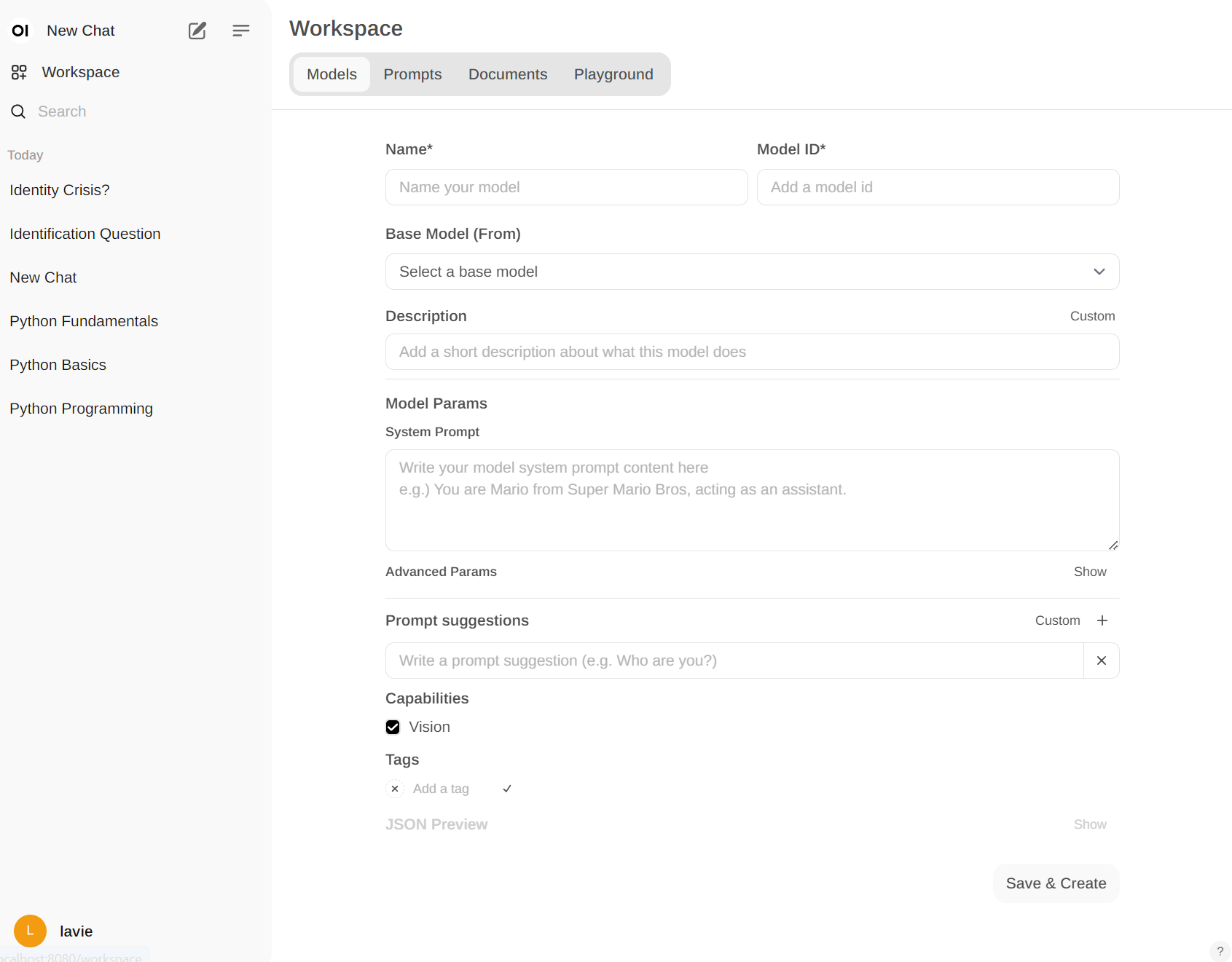
ex. 오직 Guide만 가능하도록 시스템 프롬프트를 적용시켜서 아이에게 학습용으로 제공할 수 있습니다.
4. Stable Diffusion
Stable Diffusion은 텍스트에서 이미지를 생성하는 최첨단 딥러닝 모델입니다. 이 또한 나만의 AI Server 구축이 가능합니다.
사전설치해야할 요소들이 있는데, 아래의 명령어를 이용해서 설치할 수 있습니다.
$ sudo apt install -y make build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev \
libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev python3-openssl git
끝나면 다음 명령어를 통해 설치해줍니다.
$ curl https://pyenv.run | bash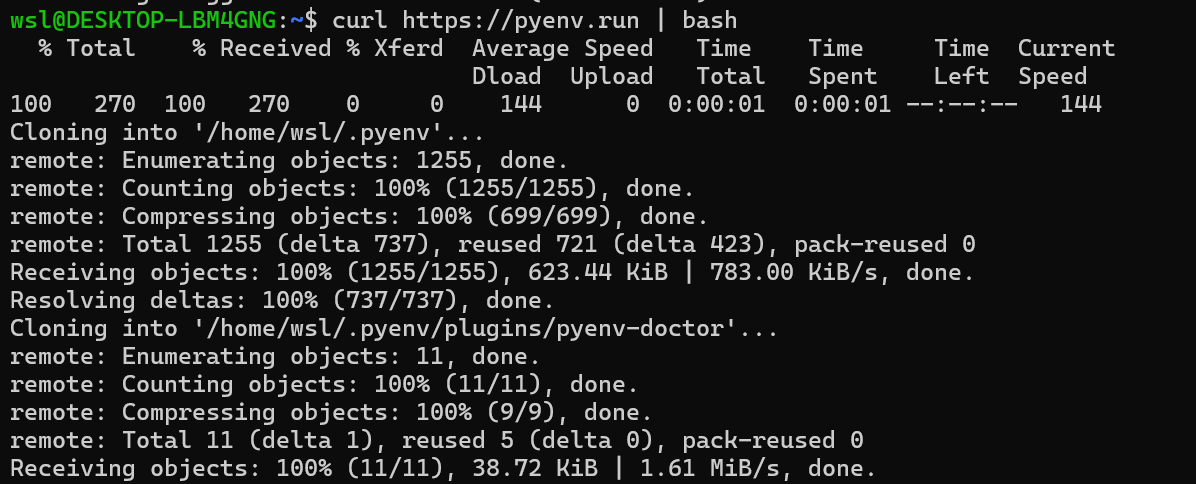
약간의 설정으로 아래 화면에 보이는 부분을 복사하여 적용해주어야합니다.
복사하여 붙여넣고, source .bashrc를 통해 현재 터미널을 리프레시해줍니다.
export PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"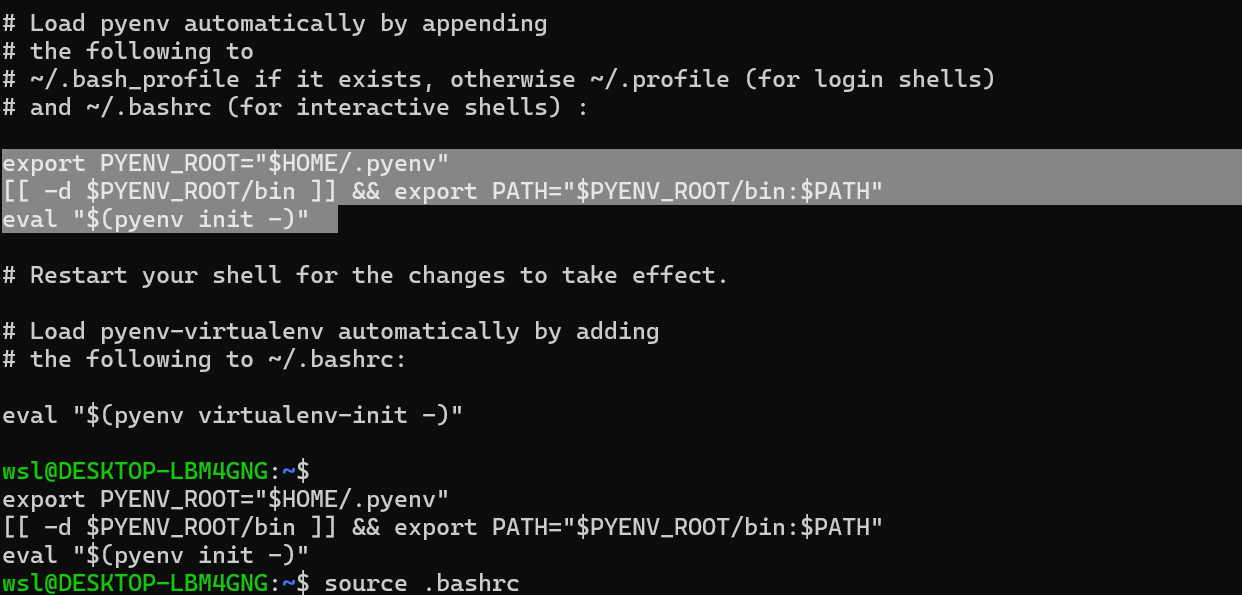
이제 pyenv 사용이 가능합니다 (pyenv -h로 테스트)
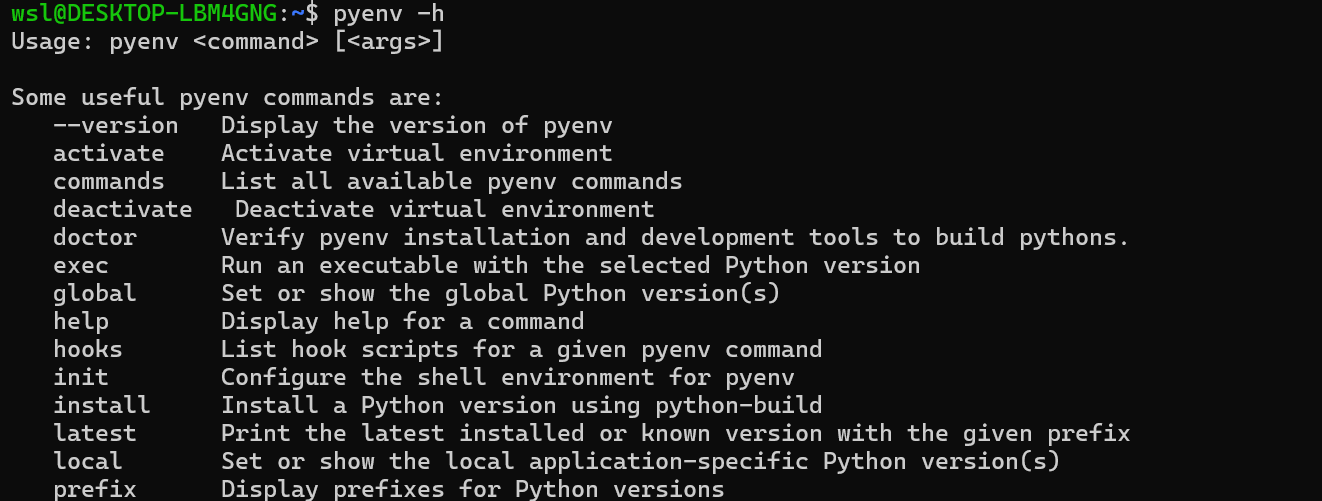
pyenv에 python 3.10 버전을 설치해주고 global 설정해줍니다.
pyenv는 여러 버전의 Python을 쉽게 설치하고 관리할 수 있게 도와주는 도구입니다.
$ pyenv install 3.10
$ pyenv global 3.10
다음은 stable diffusion을 위한 실제과정입니다.
아래의 명령어들을 실행합니다 (시간이 꽤 걸립니다)
mkdir stablediff
cd stablediff
cd stablediff/
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
chmod +x webui.sh
./webui.sh
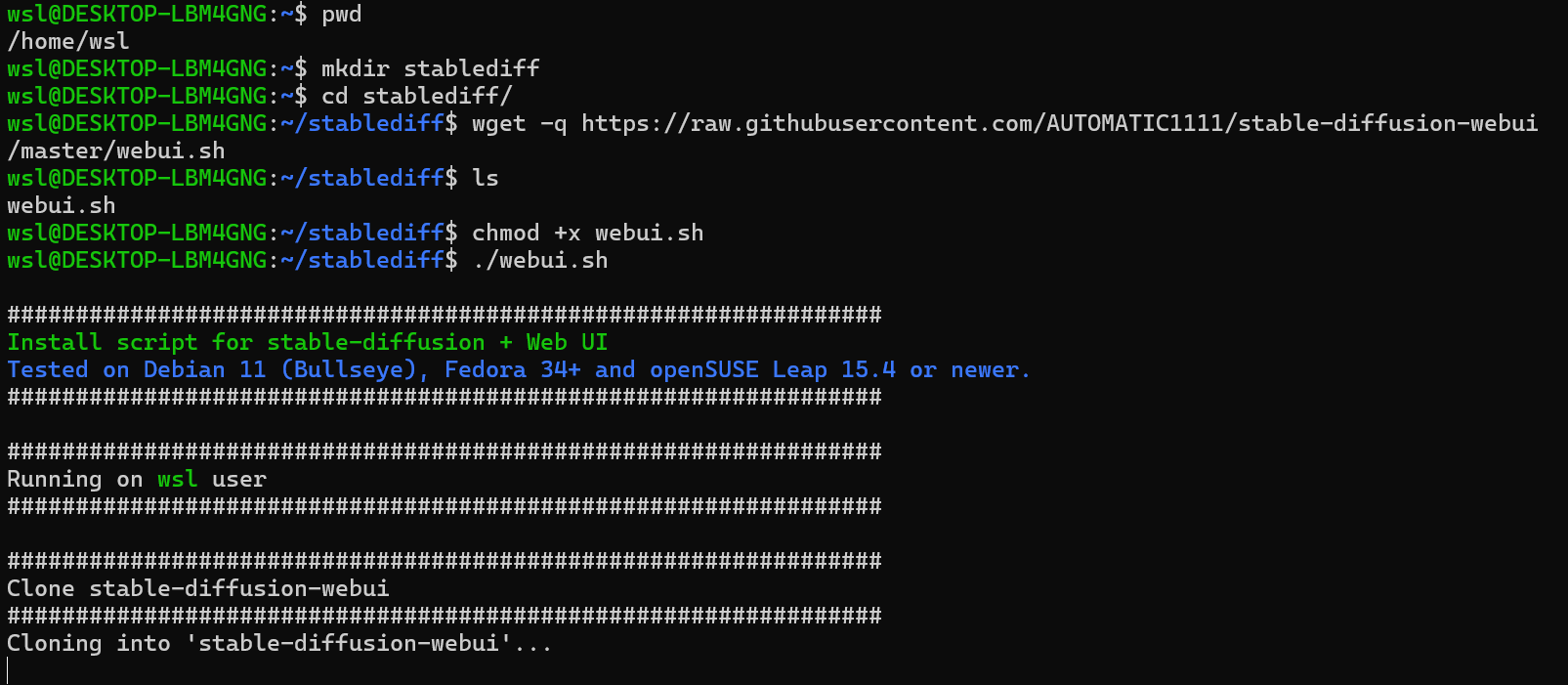
아래와 같은 상태로 완료됩니다.
멈춘 것 같지만 아직 Running 중인 것입니다.
화면출력 중 URL을 확인할 수 있습니다.
http://localhost:7860/
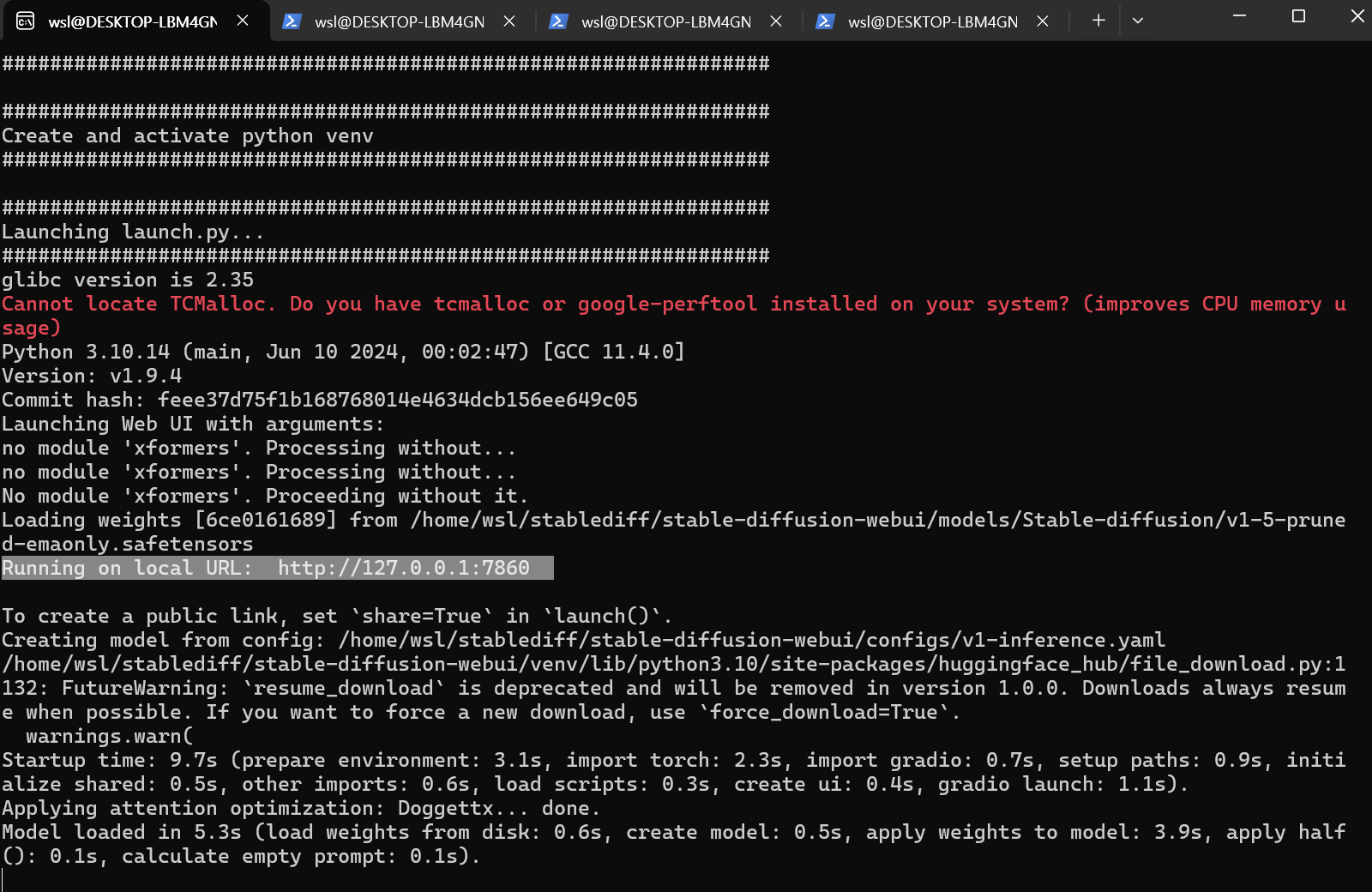
URL로 접근 시, Stable Diffusion을 사용할 수 있습니다.
prompt 입력 - Generate
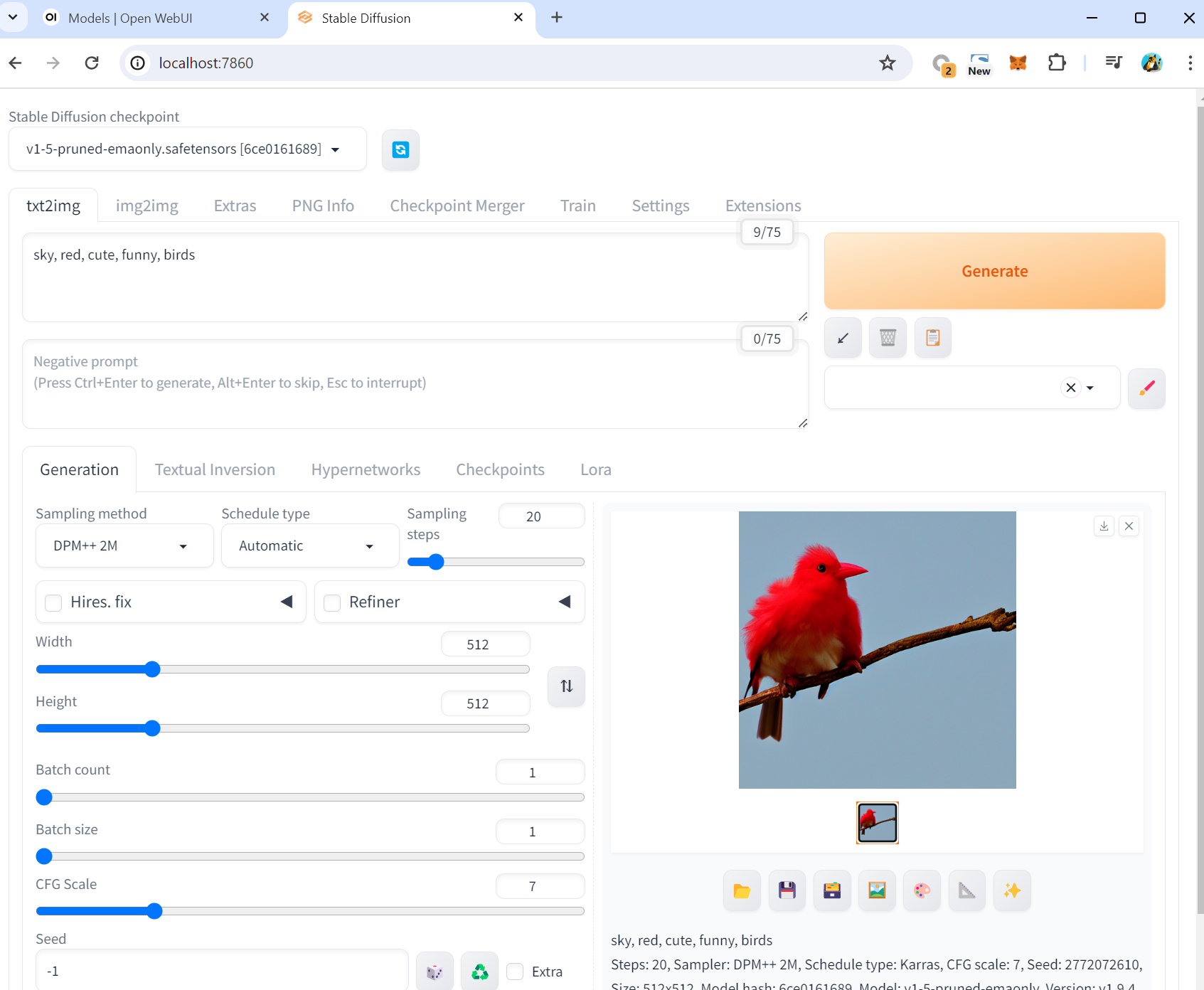
버튼 하나로 쉽게 upscaling해서 개선된 결과로 재생성도 가능합니다.
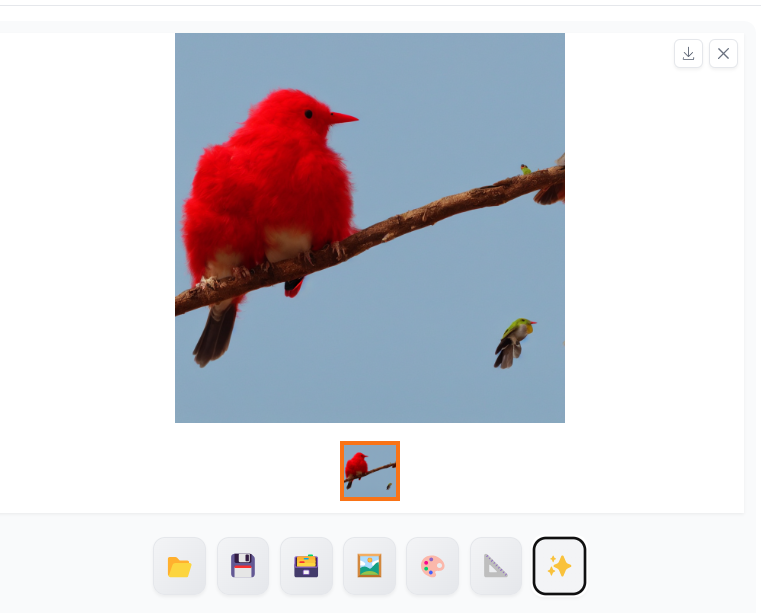
Sampleing Steps를 높이면 실시간으로 생성되는 것을 설핏 살펴볼 수도 있습니다.
5. open web UI에 Stables Diffusion을 통합
Automatin1111 을 통한 통합을 하기전에 사전단계가 있습니다.
기존 StableDiffusion 실행을 멈추고, 새롭게 실행합니다.
./webui.sh --listen --api그러면 아래의 이미지와 같이 Local URL이 변경됩니다 (0.0.0.0:7860)
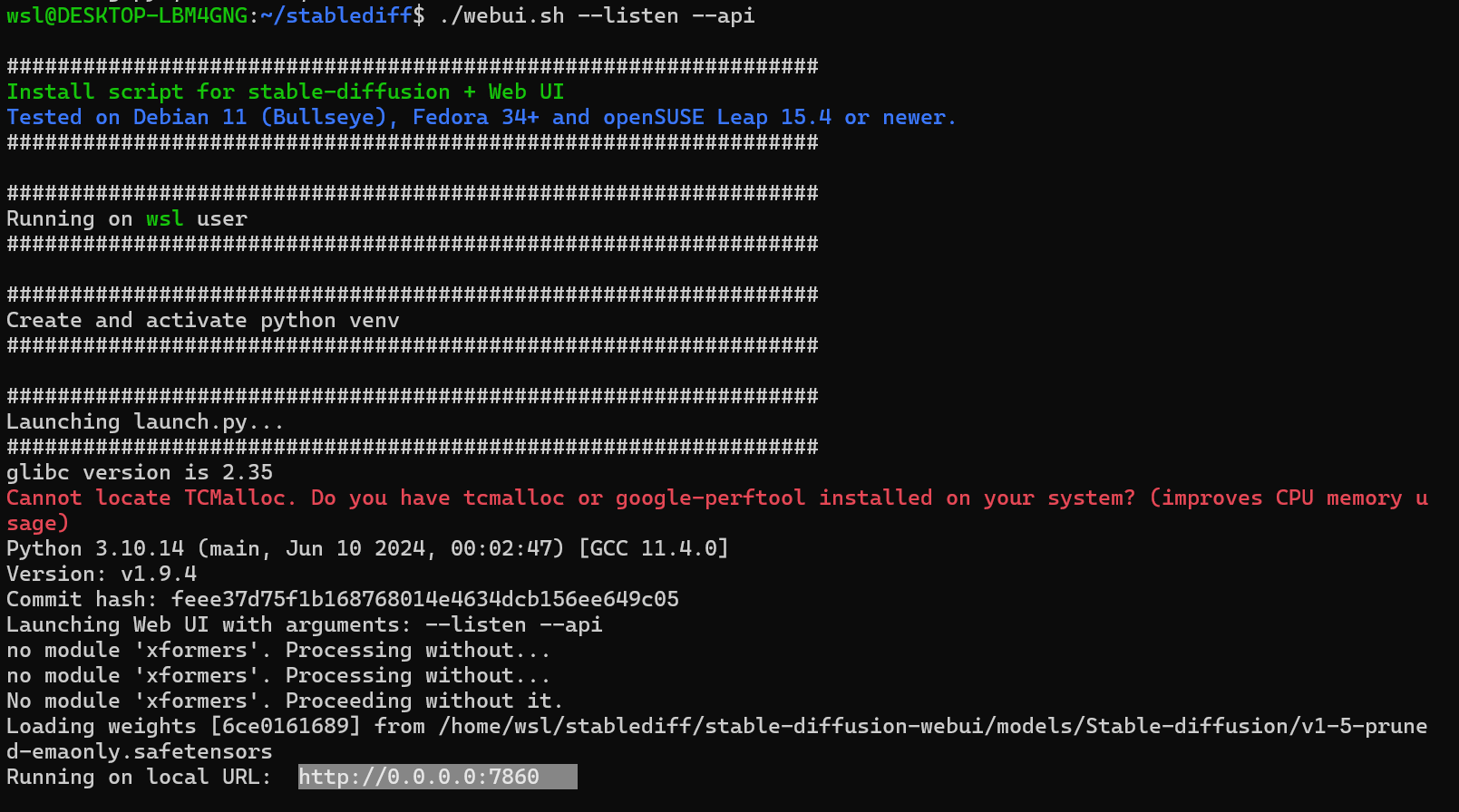
open web UI - settings - Images
AUTOMATIC1111 Base URL 주소로 Stable Diffusion을 연결해줍니다.
Server connection verifed 팝업 나타나면 성공입니다.
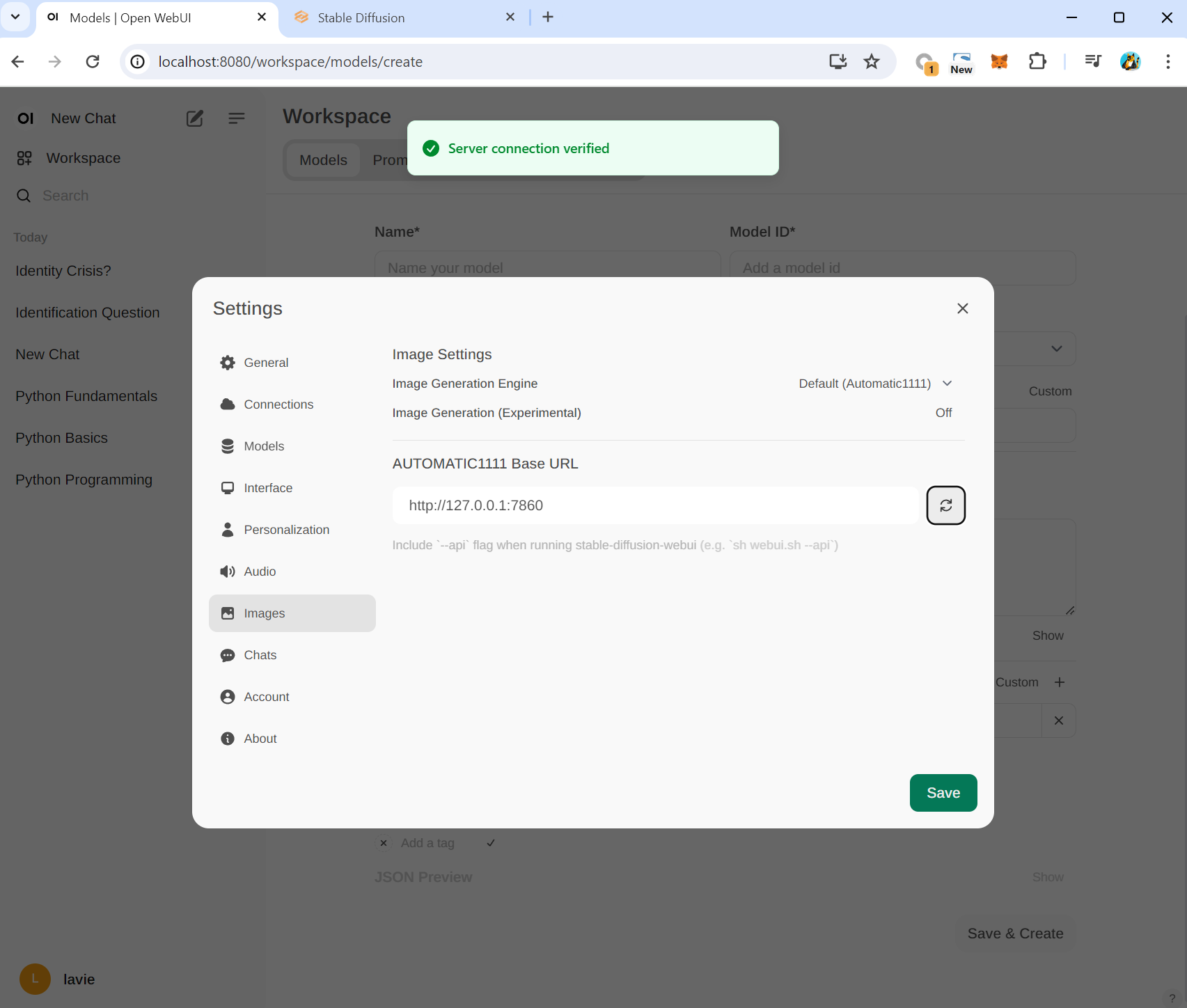
Net chat - Select Model: llama2
"Draw a man wearing party suite. This is for stable diffusion."
그림을 그려달라는 요청에 아래와 같이 이모티콘을 응답하거나 이미지 생성은 할 수 없음을 응답합니다.
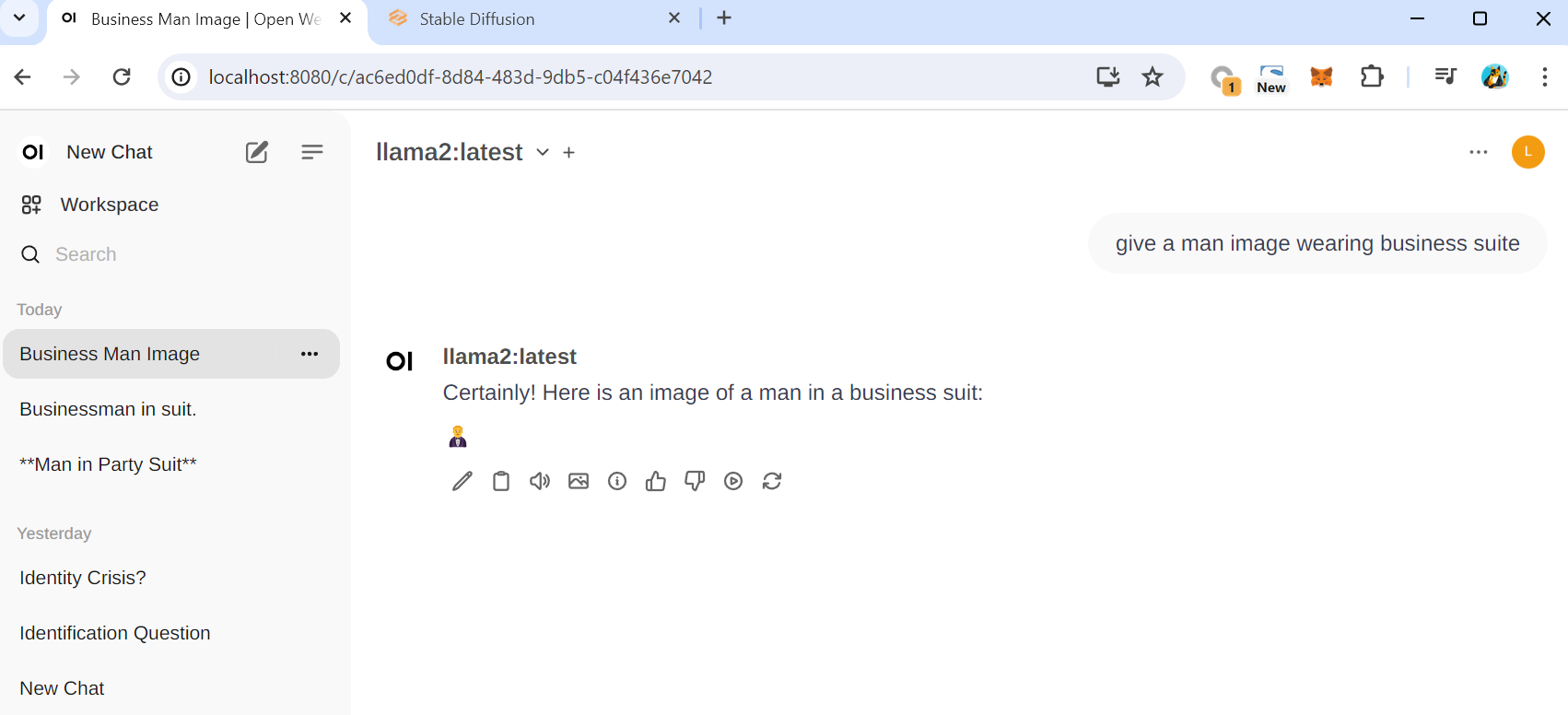
하지만 새로 생겨난 "Generate Image" 버튼을 통해 그림을 그릴 수 있습니다. 이 이미지는 Stable Diffusion을 통해 만들어졌습니다.
=== REFERENCE
https://www.youtube.com/watch?v=Wjrdr0NU4Sk&t=345s
