알고리즘
1-1 선형검색(Linear Search),보초법

선형검색
- 선형으로 나열되어 있는 데이터를 순차적으로 스캔하면서 원하는 값을 찾는다.
- 리스트, 배열 같은 데이터 구조에서 주로 사용된다.
- 리스트의 첫부분 부터 인덱스를 하나씩 확인하면서 원하는 값을 찾을 때까지 탐색한다.
-동작방법-
1. 리스트의 첫 원소부터 반복
2. 현재 찾고자 하는 값 비교
3. 값이 일치하면 반복을 종료하고 해당 값의 인덱스 반환
4. 찾는 값과 일치 하지 않으면 다음 원소(인덱스)로 이동하여 반복실행
5. 일치 하는 값이 아예 없으면 -1과 같은 특정 값 반환
보초법(Sentinel Search)

- 마지막 인덱스에 찾으려는 값을 추가해서 찾는 과정을 간략화한다.
- 선형 알고리즘을 개선하기 위한 방법이다.
- 리스트 원소값 끝에 특정 값을 추가하여 사용한다.
- 보초 값은 리스트의 마지막 원소로 설정되기 때문에, 검색할 때 리스트 끝(마지막 원소)를
체크하지 않고 검색 종료
-동작방법-
1. 리스트 마지막 인덱슬르 보초 값으로 변경
2. 원하는 값을 찾을 때까지 처음부터 반복하여 해당 원소의 인덱스 반환
3. 원하는 값을 찾으면 반복 종료 하고 해당 값 반환
4. 원하는 값이 일치하지 않으면 다음 원소로 이동한다.
-실습-
#선형으로 나열되어 있는 데이터를 순차적으로 스캔하면서 원하는 값을 찾는다.
#선형 검색
datas = [3, 2, 5, 7, 9, 1 ,0, 8, 6, 4]
print(f'datas: {datas}')
print(f'datas length: {len(datas)}')
searchData = int(input('찾으려는 숫자 입력:'))
searchResultIdx= -1
n = 0
while True:
#인덱스 범위 벗어나는 경우
if n == len(datas): #찾을려는 인덱스가 범위를 벗어나는경우 -1
searchResultIdx =-1
break
#원하는 인덱스
elif datas[n] == searchData:
searchResultIdx = n
break
n +=1
print(f'searchResultIdx:{searchResultIdx}')
#리스트에 없는 숫자를 넣으면 범위를 벗어났으므로 -1이 출력된다.
###################################################
#보초법 원하는 값 을 넣어서 인덱스 위치 구해보기
datas = [3, 2, 5, 7, 9, 1, 0, 8, 6, 4]
print(f'datas: {datas}')
print(f'datas length: {len(datas)}')
searchData = int(input('찾으려는 숫자 입력:'))
searchResultIdx = -1
datas.append(searchData)
n = 0
while True:
if datas[n] == searchData:
if n != len(datas) - 1:
#n이 리스트의 마지막 인덱스가 아닌지 확인
#n이 마지막 인덱스가 아니면 searchResultIdx 데이터 할당
searchResultIdx = n
break
n +=1
print(f'datas: {datas}')
print(f'datas length: {len(datas)}')
print(f'searchResultIdx: [{searchResultIdx}]')
#################################################
리스트에서 숫자 7을 모두 검색하고 각각의 위치(인덱스)와 검색 개수를 출력하자
nums = [4, 7, 10, 2, 4, 7, 0, 2, 7, 3, 9]
print(f'nums: {nums}')
print(f'nums length: {len(nums)}')
searchData = int(input('input search number:'))
searchResultIdx = []
nums.append(searchData)
n = 0
while True:
if nums[n] == searchData:
#nums의 리스트 값과 입력 받은 데이터를 비교
if n != len(nums) - 1:
#인덱스 n이 nums리스트의 마지막 인덱스가 아니면
#실행(마지막 값은 보초 값으로 추가한 숫자이며 결과에 포함 x)
searchResultIdx.append(n)
#인덱스를 searchResultIdx에 추가
#7의 경우 3개라서 반복하면서 7과 동일한 인덱스를 더한다.
else: #인덱스가 마지막 인덱스면 while문 빠져나온다.
break
n +=1
print(f'nums: {nums}')
print(f'nums length: {len(nums)}')
print(f'searchResultIdxs: {searchResultIdx}') #7의(3개의) 인덱스 위치 [1,5,8]출력
print(f'searchResultIdxs: {len(searchResultIdx)}')#7 3개
1-2 이진검색
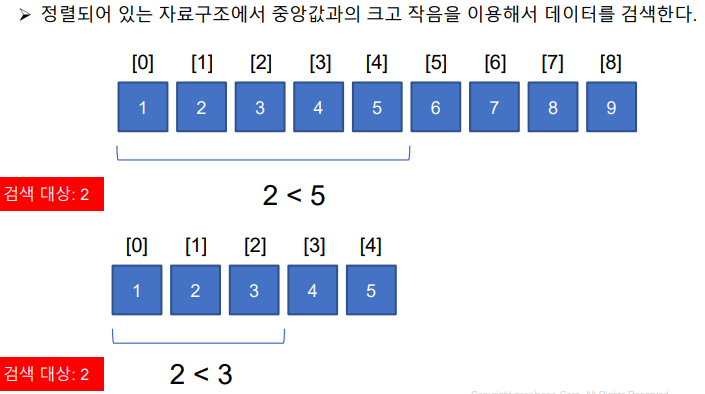
- 정렬되어 있는 자료구조에서 중앙값과의 크고 작음을 이용해서 데이터를 검색한다.
- 탐색 범위를 절반씩 줄여서 원하는 값을 찾는다.
- 리스트를 사용한다.
-사용방법-
- 정렬된 리스트의 중간 원소를 만든다.
- 중간 원소와 찾는 값을 비교한다.
- 찾고자 하는 데이터와 같으면 해당 데이터 인덱스 반환
- 중간 원소보다 찾고자 하는 데이터가 작으면
중간 원소를 기준으로 왼쪽 부분의 서브리스트 반복 - 중간 원소보다 값이 큰경우 오른쪽 부분의 서브리스트
datas = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
print(f'datas: {datas}')
print(f'datas length: {len(datas)}')
searchData = int(input('search data:'))
searchResultIdx = -1 #범위 를 벗어날때 -1출력
staIdx = 0 #0부터 시작하므로 0
endIdx = len(datas) -1 #인덱스의 끝
midIdx = (staIdx + endIdx) // 2 #가운데 인덱스(시작인덱스//끝인덱스)
midVal = datas[midIdx]
print(f'midIdx: {midIdx}')
print(f'midVal: {midVal}')
while searchData <= datas[len(datas) -1] and searchData >= datas[0]:
#searchData(사용자 입력) 변수가 끝 인덱스보다 작거나 같고
#사용자 입력이 datas의인덱스0번 보다 같거나 크면
#아래 부분 실행
#요약: 입력 데이터가 datas의 범위내에 있으면 실행한다는 뜻
#입력 데이터와 끝 인덱스랑 같은 경우
if searchData == datas[len(datas) -1]:
searchResultIdx = len(datas) - 1
break
#입력 데이터가 중간 인덱스보다 큰경우
if searchData > midVal: # 찾으려는 값이 중간 값보다 큰경우
#시작 인덱스와 중간인덱스는 같다.
staIdx = midIdx #다음과같이 선언해서 예를들면 인덱스10개있으면 중간값 5를 시작으로 한다.
midIdx = (staIdx + endIdx) // 2# 인덱스 찾는 범위를 절반으로 줄인다.
midVal = datas[midIdx]
print(f'midIdx: {midIdx}')
print(f'midVal: {midVal}')
#입력 데이터가 작은경우
elif searchData < midVal: #찾으려는 인덱스 값이 중간 값보다 작은경우
#끝 인덱스와 중간 인덱스는 같다.
endIdx = midIdx#인덱스 범위 절반으로 줄인다.
midIdx = (staIdx + endIdx) // 2 #중간 인덱스
midVal = datas[midIdx]
print(f'midIdx: {midIdx}')
print(f'midVal: {midVal}')
elif searchData == midVal: # 입력 데이터랑 중간 값이 같은 경우
searchResultIdx = midIdx
break
print(f'searchResultIdx: {searchResultIdx}')
##################################
#리스트를 오름차순으로 정렬한 후 7을 검색하고 위치(인덱스)를 출력하자
nums = [4, 10, 22, 5, 0, 17, 7, 11, 9, 61, 88]
nums.sort()
searchData = int(input('찾으려는 숫자 입력: '))
searchResultIdx = -1
staIdx = 0
endIdx = len(nums) - 1
midIdx = (staIdx + endIdx) // 2
midVal = nums[midIdx]
while searchData <= nums[len(nums)-1] and searchData >= nums[0]:
#nums = [4, 10, 22, 5, 0, 17, 7, 11, 9, 61, 88] 범위 내에 있으면 IF문 실행
if searchData == nums[len(nums) - 1]:
#nums에 없는 데이터 출력 하는 경우 -1 출력
searchResultIdx = len(nums) - 1
break
if searchData > midVal:
staIdx = midIdx
midIdx = (staIdx + endIdx)//2
midVal = nums[midIdx]
elif searchData < midVal:
endIdx = midIdx
midIdx = (staIdx + endIdx)//2
midVal = nums[midIdx]
elif searchData == midVal:
searchResultIdx = midIdx
break
print(f'searchResultIdx: {searchResultIdx}')
1-3 순위

- 수의 크고 작음을 이용해서 수의 순서를 정한는 것을 순위라고 한다.
import random
nums = random.sample(range(50, 101), 20)
ranks = [0 for i in range(20)]
# 0으로 초기화된 길이가 20인 리스트 생성
#출력해보면 0,0,0,0,0.... 20개 출력
print(f'nums: {nums}')
print(f'ranks: {ranks}')
for idx, num1 in enumerate(nums):
#idx에는 0,1,2,3,4 인덱스가 들어간다
#num1에는 난수가 들어간다. 75,52,70,94등
#num1에 난수가 한개씩 반복한다.
for num2 in nums:#난수로 뽑아낸 리스트의 요소(난수)를 반복실행
# 리스트의 숫자 크기를 비교하기 위해 또다른 for문 사용
#num1 에는 순서대로 하나씩 값이들어가는 의미
#num2는 리스트의 요소를 반복적으로 들어가는 의미
if num1 < num2:
#nums가 [75,52,70,94]인경우
#75와 75 같음으로 순위 변동 없다.
#75와 52 비교 --> 75가 큼으로rank 1증가
#enumerate의 num1 이 난수 num 보다 작으면
#순위 인덱스 +1
ranks[idx] += 1
print(f'nums: {nums}')
print(f'ranks: {ranks}')
#순위 출력해보기
for idx, num in enumerate(nums):
print(f'num: {num} \t rank: {ranks[idx] + 1}')
1-4 버블정렬
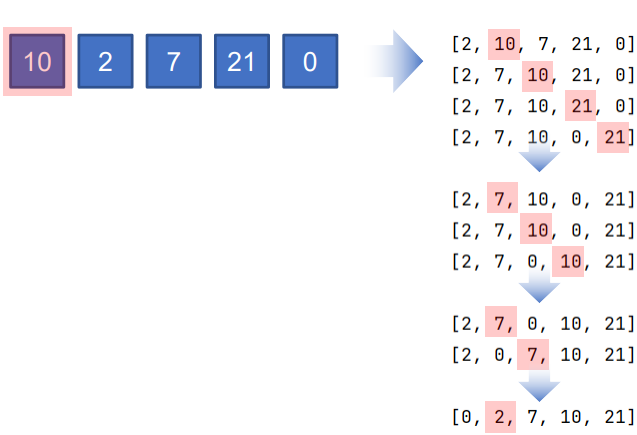
- 버블 정렬이란 처음부터 끝까지 인접하는 인덱스의 값을 순차적으로 비교하면서 큰 숫자를 가장 끝으로 옮기는 알고리즘이다.
-코드 동작-
1. 리스트의 처음 인덱스부터 끝 인덱스 까지 반복하면서 비비교
2. 인접한 두 원소의 크기 비교를 하면서 두 원소를 교환
이때 큰 숫자 원소가 뒤로 간다.
3.끝까지 반복하여 가장 큰 원소는 맨뒤로 가장작은 원소는 맨앞으로 온다.
#처음부터 끝까지 인접하는 인덱스의 값을 순차적으로 비교하면서
#큰 숫자를 가장 끝으로 옮긴느 알고리즘 "버블정렬"
nums = [10, 2, 7, 21, 0]
print(f'not sored nums: {nums}')
length= len(nums) - 1
#인덱스 범위를 벗어나지 않기위해 -1
#버블 알고리즘 수행
#버블 알고리즘은 큰수를 뒤로 빼는 작업이다.
for i in range(length):
#length 길이5만큼 실행(인덱스는 4개)
for j in range(length - i):
#인접 인덱스들을 순차적으로 비교한다.
#이미 정렬된 요소들을 제외하고 나머지 부분들을 비교한다.
#요약: 뒤에있는 0까지 전부 비교해서 정렬하게 된다.
if nums[j] > nums[j + 1]:
#nums[j]앞 인덱스, nums[j+1] 바로 뒤 인덱스
#10과 2를 비교했는데 10이크면 2랑 자리를 바꿔야한다.
#앞 숫자와 뒤숫자를 비교했을때 앞이크면 자리를 바꾸는 기능
#여기서의 코드가 실행된다는건 인덱스가 순서대로 정렬되지 않음을 의미
#인덱스 순서 바꿈(큰숫자랑 작은숫자의 위치 교체)
temp = nums[j]#임시 저장
nums[j] = nums[j +1] #다음숫자nums[j+1]을 저장
nums[j + 1] = temp
#nums[j +1]에 temp를 넣으면 자리를바꾸게 된다.
# nums[j], nums[j+1] = nums[j+1], nums[j]
# #서로의 값을 바꿔서 넣는다.
print(nums)
print()
print(f'sorted nums: {nums}')
#10,2,7,21,0 --> 2,7,10,21,0 으로 바꿔진것을 확인할수있다.
# 10은 21보다 작아서 21뒤로 갈수 없다.
1-5 삽입정렬
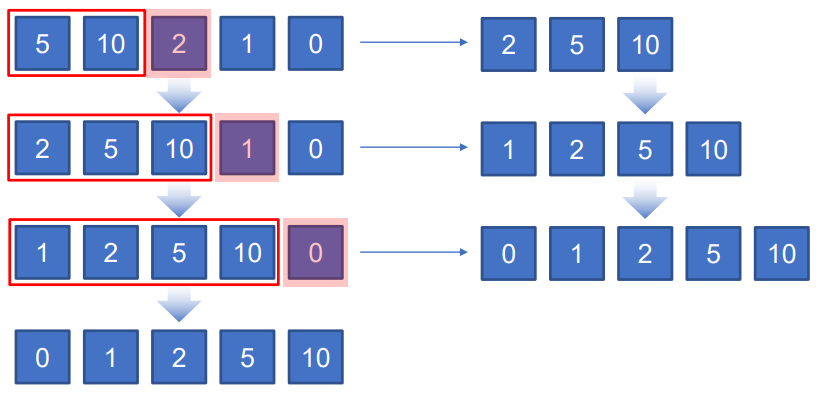
- 처음부터 끝까지 인접하는 인덱스의 값을 순차적으로 비교하면서 큰 숫자를 가장 끝으로 옮기는 알고리즘이다.
-코드동작-
- 정렬되지 않은 첫 번째 원소부터 정렬시작
- 다음 원소를 선택하여 원소가 정렬된 부분에 삽입한다.
- 원소를 삽입 후, 다음 원소를 선택하여 정렬된 부분에 삽입
- 숫자가 제대로 정렬되면 끝
#실행 부분
import random as rd
import sortMod as sm
students = []
for i in range(20):
students.append(rd.randint(170, 185))
print(f'students: {students}')
sortedStudents = sm.bubbleSort(students, deepCopy= False)
#파이썬 sortMod에서 bubbleSort함수 불러온다.
#깊은 복사를 위해 deepCopy= False를 사용한다
#깊은 복사를 안하면 이전 데이터가 계속 출력이된다.
print(f'students: {students}')
print(f'sortedStudents: {sortedStudents}')
# 새 학년이 되어 학급에 20명의 새로운 학생들이 모였다. 학생글을 키 순서로
# 줄 세워 보자. 학생들의 키는 random 모듈을 이용해서 170 ~185사이로 생성한다.
import copy# 깊은 복사를 위한 호출
def bubbleSort(ns, deepCopy = True):
#값을 유지시키는 깊은 복사를 위해 deepCopy =True
if deepCopy :
cns = copy.copy(ns)
#deepCopy 가 True이면 ns 실행
#ns는 난수 값이 들어 있는 students 리스트 데이터이다.
#실행 파일에서의 20개 난수를 받아서 완전히 새로운
#데이터로 새로 출력
else: #얕은 복사 수행
cns = ns
length = len(cns) - 1
#인덱스 범위 벗어나지않기 위해 -1
#버블정렬 구간
for i in range(length):
#리스트 인덱스 범위를 타나내는 i
for j in range(length - i):
#큰값과 작은 값을 교환해주는 j
if cns[j] > cns[j +1]:
#cns =[4,2,7,1] 임의 숫자 일떄
#cns[0] > cns[1] 를 비교하게 된다. 4> 2
# cns=[2,4,7,1]이 된다.
cns[j], cns[j+1] = cns[j+1], cns[j]
#cns[j] = cns[j+1]
# cns[j] 4 = cns[j+1] 2
#cns[j]=2 2를 cns[j] 변수에 할당해서 작은숫자가 앞으로 가게되었다.
return cns
1-6 선택정렬
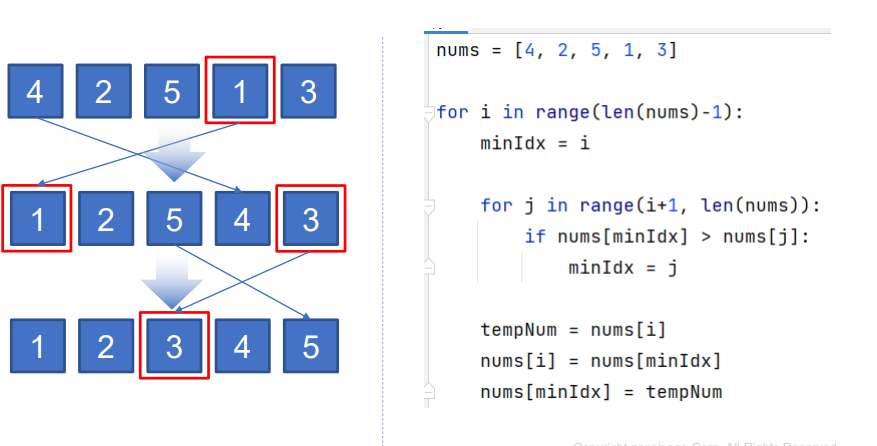
- 주어진 리스트 중에 최소값을 찾아, 그 값을 맨 앞에 위치한 값과 교체하는 방식으로
자료를 정렬하는 알고리즘이다.
nums = [4, 2, 5, 1, 3]
print(f'nums: {nums}')
for i in range(len(nums) -1):
# 인덱스0~3까지 반복
minIdx = i
for j in range(i+1, len(nums)):
#작은 값을 찾아 앞으로 이동시킨다.
# j는 i+1 인덱스1번(2)부터 전체까지 범위를 지정
if nums[minIdx] > nums[j]:
#첫반복에서 nums[minId]=2 > num[j]:1
#즉 4 > 2가 된다.
#즉 2의 인덱스[1]이 minIdx =1 이된다.
minIdx = j
#방법1
tempNum = nums[i]
#tempNum = 4 -> 0의 인덱스 4 가지게 된다. 왜냐하면 nums[i]의 첫 반복이기 떄문
nums[i] = nums[minIdx]
# 4 = 1
#nums[i] = 2 --> 2가된다. minIdx = j --> minIdx=1 (1의 인덱스는 2)
nums[minIdx] = tempNum
#nums[minIdx] 는 최종 4가된다. [4,2,5,1,3] 에서 [2,4,5,1,3]이된다.
#방법2
# nums[i], nums[minIdx] = nums[minIdx], nums[i]
print(f'nums: {nums}')
1-7 최대값

- 자료구조에서 가장 큰 값을 찾는다.
class MaxAlgorithm:
def __init__(self, ns):
self.nums = ns
self.maxNum = 0
def getMaxNum(self):
self.maxNum = self.nums[0]
for n in self.nums:
if self.maxNum < n:
#maxNum이 n보다 작으면 최대값이 아니라서
#maxNum = n 으로 n을 최대값으로 설정한다.
self.maxNum = n
#계속 반복하면서 n을 새로 업데이트한다
#첫반복떄는 최대값이 -2가 되는데
#반복하면서 -4,5,7,등을 반복하게 되어서
#최종 20이 제일 큰 최대값이된다.
return self.maxNum #최대값 리턴
ma = MaxAlgorithm([-2, -4, 5, 7, 10, 0, 8, 20, -11])
#MaxAlgorithm클래스의 ns 매개변수에 값 할당
maxNum = ma.getMaxNum() # 최대값 반환
print(f'maxNum: {maxNum}')
##############################
#가장 큰 문자 찾기
class MaxAlgorithm:
def __init__(self, cs):
self.chars = cs
self.maxChar = 0
def getMaxChar(self):
#가장큰 문자를 찾는 함수
self.maxChar = self.chars[0]
#가장 큰 문자를 저장하는 변수
for c in self.chars:
#문자열 리스트 를 c에 반복실행
if ord(self.maxChar) < ord(c):
#가장 큰 문자와 탐색중인 문자(c) 와 비교해서
# 더큰 값 c를 maxChar로 변수 할당
self.maxChar = c
return self.maxChar
chars = ['c', 'x','Q', 'A', 'e', 'P', 'p']
mc = MaxAlgorithm(chars)
#매개변수 cs로 할당
maxChar = mc.getMaxChar()
print(f'maxChar: {maxChar}')
1-7 최소값

- 자료 구조에서 가장 작은 값을 찾는다.
class MinAlgorithm:
def __init__(self, ns):
self.nums = ns
self.minNum = 0
def getMinNum(self):
self.minNum = self.nums[0]
#nums = [-2, -4, 5, 7, 10, 0, 8, 20, -11]
#인덱스0번으로 최소값 변수 할당
#-2를 기준으로 최소값을 찾는다.
#가장 작은 범위에서 제일 작은 값을 찾기위함
for n in self.nums:
# nums = [-2, -4, 5, 7, 10, 0, 8, 20, -11]
#nums의 인덱스들을 n에 할당해서 반복한다.
if self.minNum > n:
#인덱스가 담긴 데이터 n을 최소값변수보다 작으면
# minNum 최소값 변수에 n을 할당한다.
self.minNum = n
return self.minNum
nums = [-2, -4, 5, 7, 10, 0, 8, 20, -11,-12]
ma = MinAlgorithm(nums)
minNum = ma.getMinNum() ## --> 리턴된 minNum을 할당한다.
print(f'minNum: {minNum}') # --> 최소값 -11 출력
###############가장 작은 문자 찾기
class MinAlgorith:
def __init__(self, cs):
self.chars = cs
# ma = MinAlgorith(['c', 'x', 'Q', 'A', 'e', 'P', 'p', ])
#chars에 다음과 같은 문자들이 들어온다.
self.minChar = '0'
#큰 의미는 없지만 최소값을 0으로 선언
# 1을 넣어도 되고 'A'문자를 넣어도 된다.
def getMinChar(self):
self.minChar = self.chars[0]
#인덱스 0번 'c'를 의미한다.
for c in self.chars:
if ord(self.minChar) > ord(c):
#ord 아스키코드 변환 함수
#c보다 작은 인덱스를
#minChar = c 로 선언한다.
self. minChar = c
return self.minChar
ma = MinAlgorith(['c','x','Q','A','e','P','p',])
minChar = ma.getMinChar()
print(f'minChar: {minChar}')
1-8 최빈값
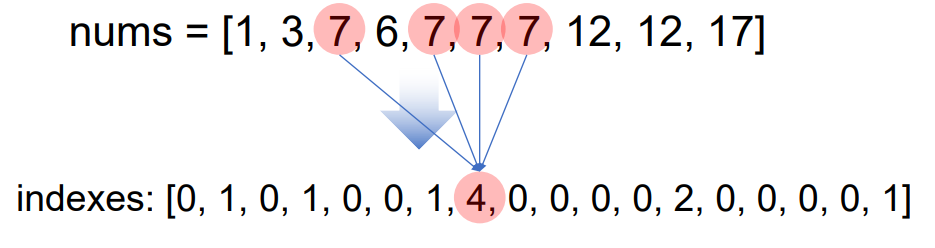
- 데이터에서 빈도수가 가장 많은 데이터를 최빈값이라고 한다.
class MaxAlgorithm:
def __init__(self, ns):
self.nums = ns
self.maxNum = 0
self.maxNumIdx = 0
#가장 큰 숫자의 idx와 Num 을 구하는 함수
def setMaxIdxAndNum(self):
self.maxNum = self.nums[0]
for i, n in enumerate(self.nums):
if self.maxNum < n:
self.maxNum = n #가장 큰데이터 선언
self.maxNumIdx = i#가장 큰 인덱스 선언
#
def getMaxNum(self):
return self.maxNum
def getMaxNumIdx(self):
return self.maxNumIdx
nums = [1, 3, 7, 6, 7, 7, 7, 12, 12, 17,6]
maxAlo = MaxAlgorithm(nums) #인스턴스 생성 (매개변수 ns에 값을 주기 위함)
maxAlo.setMaxIdxAndNum()#최대값과 최대인덱스값이 설정된다.
maxNum = maxAlo.getMaxNum() #최대값 17이 들어온다.
#0~17인 아이템이 0으로 설정되어있는 새로운 배열 만든다.
print(f'maxNum:{maxNum}')
#인덱스가 18개인 배열 만들기 (최대값이 17임으로 인덱스0~17(총 18개))
indexes = [0 for i in range(maxNum + 1)]# +1을 해야 18개가 됨으로
#출력 해보면 0이 총 18개가 출력된다. 0,0,0,0,0....
print(f'indexes: {indexes}')
print(f'indexes length: {len(indexes)}')
#중복 되거나 한번이라도 등장 한 숫자의 인덱스를 +1 해준다.
for n in nums:
indexes[n] = indexes[n] + 1
print(f'indexes: {indexes}')
#좀더 보기 쉽게 출력해보자
maxAlo = MaxAlgorithm(indexes)
maxAlo.setMaxIdxAndNum()
maxNum = maxAlo.getMaxNum()
maxNumIdx = maxAlo.getMaxNumIdx()
print(f'maxNum : {maxNum}')
print(f'maxNumIdx: {maxNumIdx}')
print(f'{maxNumIdx}의 빈도수가 {maxNum}로 가장 높다.')
1-9 근삿값
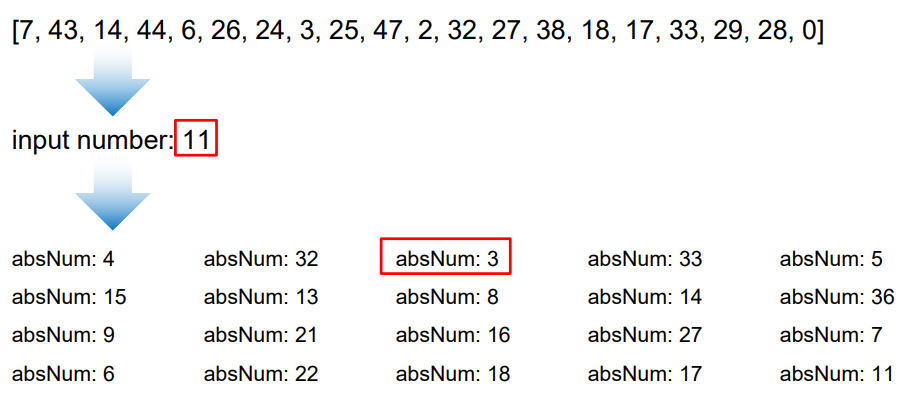
- 특정 값(참값)에 가장 가까운 값을 근삿값이라고 한다.
import random
nums = random.sample(range(0, 50), 20)
print(f'nums{nums}')
inputNum = int(input('input number: '))
print(f'inputNum: {inputNum}')
nearNum = 0 #인접값 변수
minNum = 50 #난수 최대치를 50으로 설정했음으로 50
for n in nums:
absNum = abs(n - inputNum)
# #난수 - 사용자입력값 출력하기 (이때 마이너스가 나오면 안되서 절대값 함수 abs 사용)
# print(f'absNum: {absNum}')
#11 입력하면 absNum12 --> 23과 12차이가 발생 한다는뜻
if absNum < minNum: #최대치 50범위 안에서 답을 구해야 함으로
#absNum < minNum 선언
minNum = absNum #절대값이 최소값보다 작으면 절대값은 최소값 minNum으로 할당
nearNum = n #사용자가 입력한 숫자와 가장 가깝다.(절대값이 최소값 보다 작은경우 실행)
print(f'가장 가까운수 :{nearNum}') # 난수에 없는 숫자를 넣어서 편하게 확인하자!
1-10 평균
- 여러 수나 양의 중간값을 갖는 수를 평균이라고 한다.
# 정수들의 평균
nums = [4, 5.12, 0, 5, 7.34, 9.1, 9, 3, 3.159, 1, 11, 12.789]
print(f'{nums}')
targetNums = []
total = 0
for n in nums:
if n - int(n) ==0:
# 정수 확인 여부 하는 코드이다.
# ex) 4- 4 ==0 이면 True
#반복하면서 나온 정수들을 더해서 total 변수에 넣는다.
total += n
#반복문 n 의데이터 4 +5.12 +0+5....12.789까지 계산
targetNums.append(n)
average = total / len(targetNums)
print(f'targetNums: {targetNums}')
print(f'average: {round(average, 2)}')
1-11 재귀 알고리즘

- 나 자신을 다시 호출하는 것을 재귀라고 한다.
#재귀 함수 사용
def recusion(num):
#양수인 경우 동작
if num > 0:
print('*' * num)
return recusion(num - 1)#함수 호출 재귀 부분
#num이 0이하이면 재귀 호출 종료하고 1반환
else:
return 1
#num이 0이하인 경우 함수가 더 이상 재귀 호출하지 않도록 하고
#호출을 종료하며 반환 값을 1로 지정
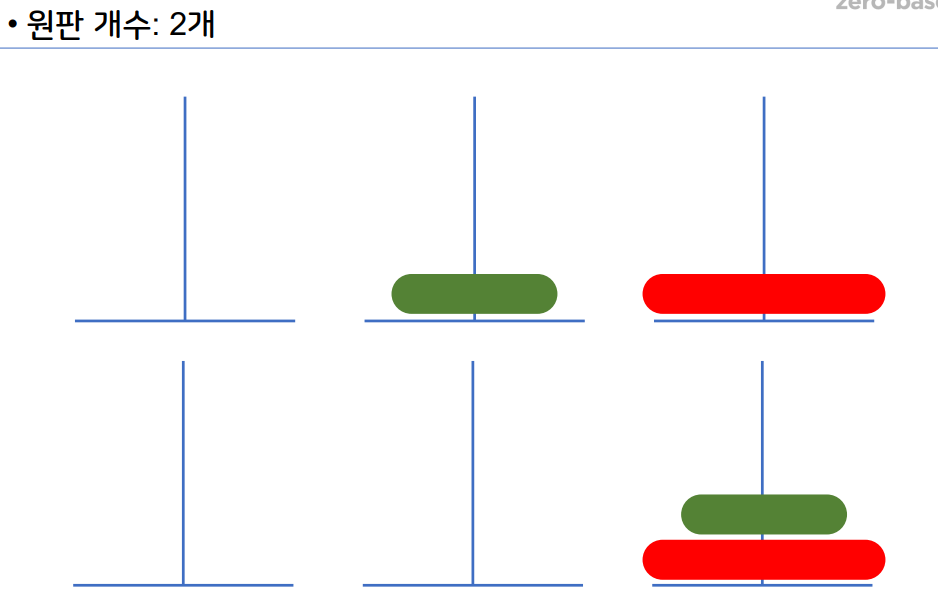
1-12 하노이 탑
원판 2개
원판 3개
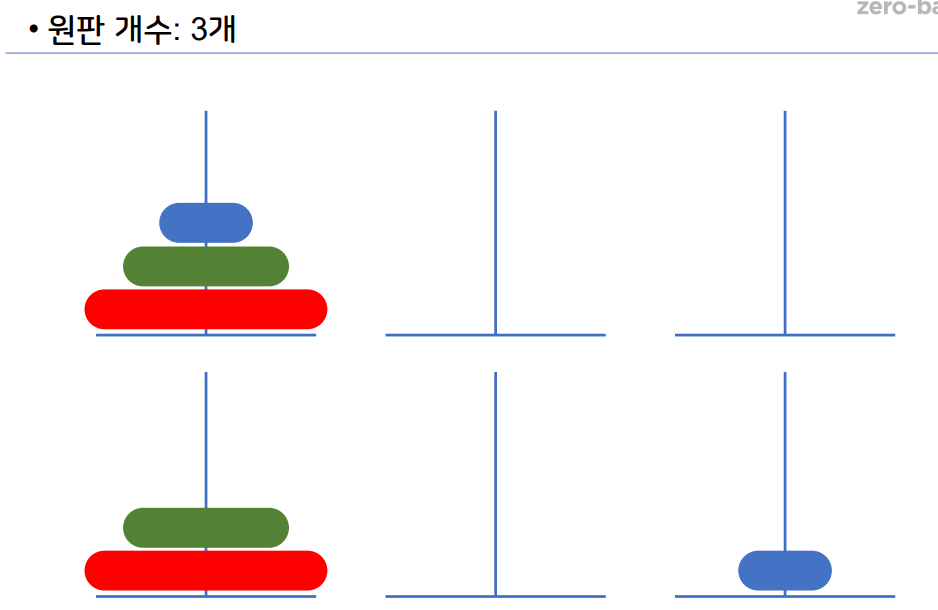
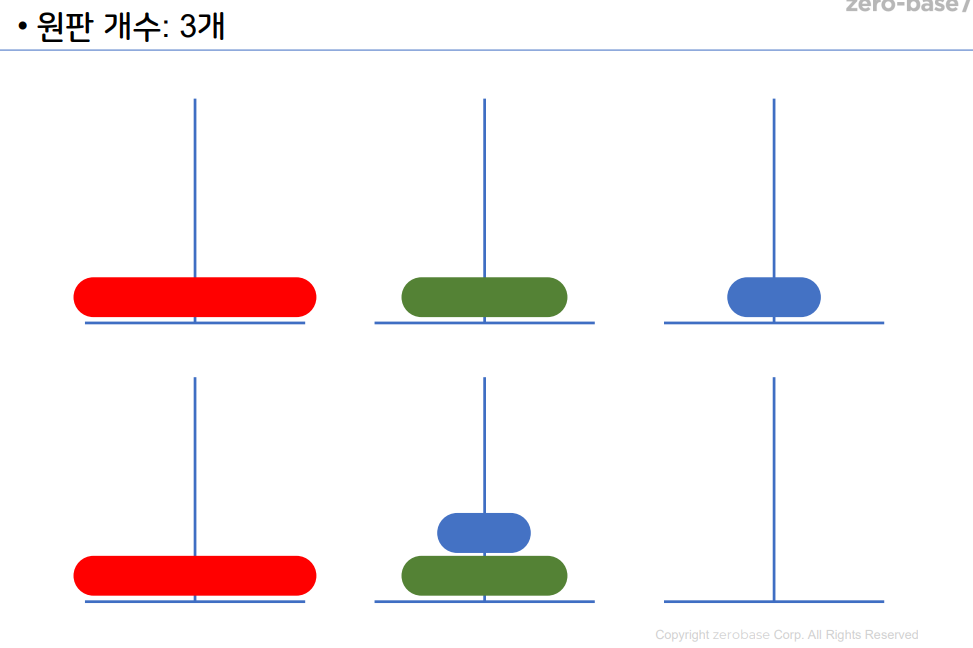
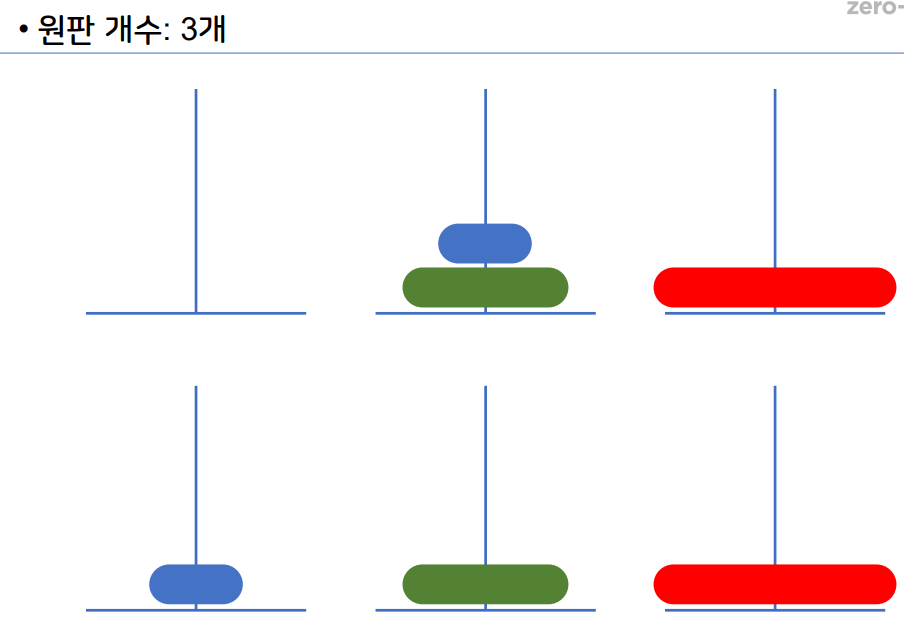
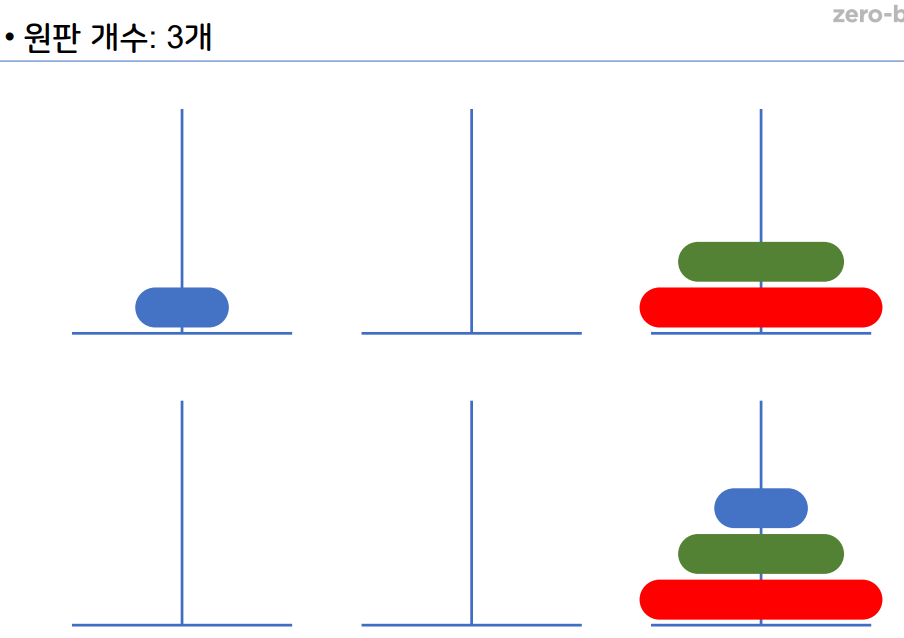
원판 4개
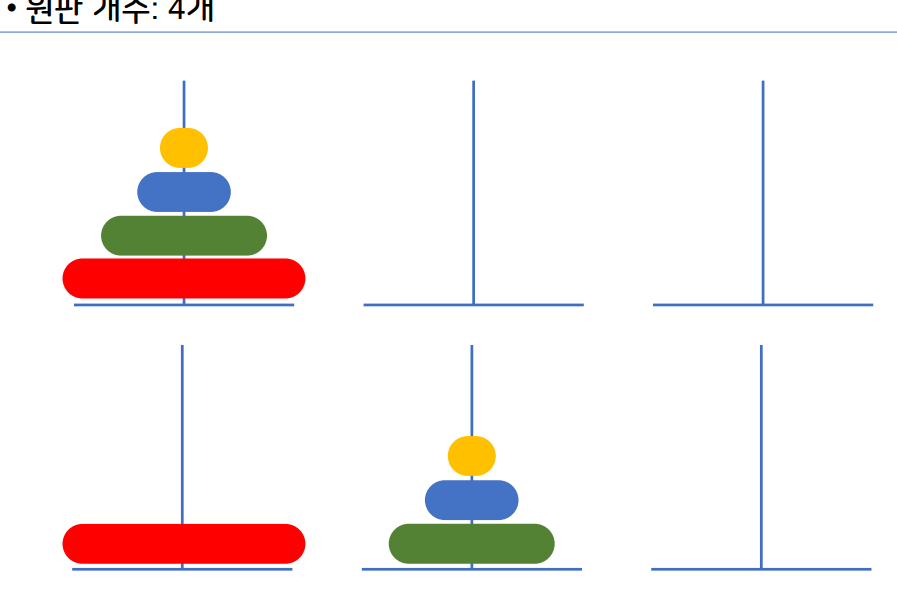
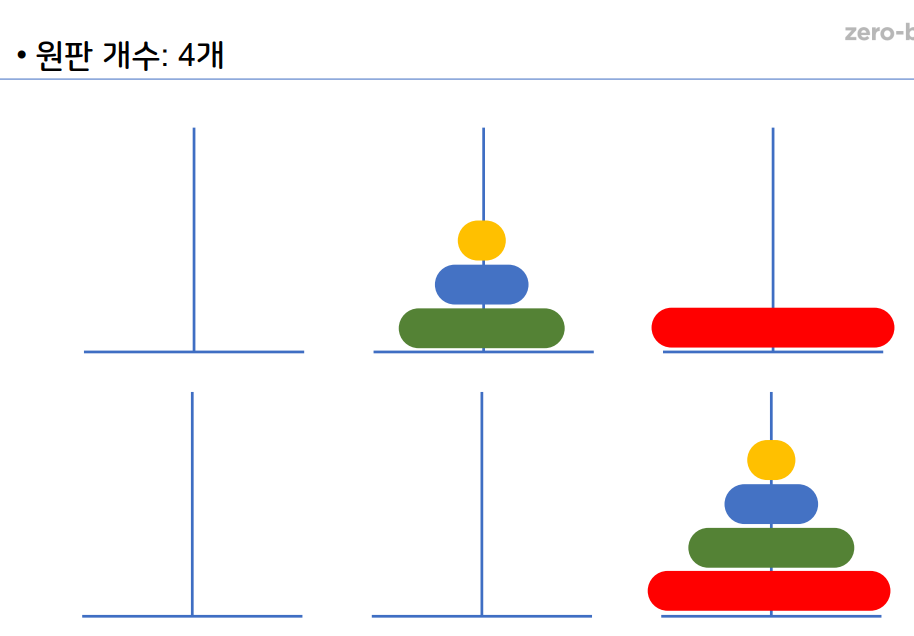
- 재귀 알고리즘 중 하나이다.
- 하노이 탑 이란 세 개의 기둥을 이용해서 원판을 다른
기둥으로 옮기면 된다. - 이때 조건은 원판을 한개씩만 사용해서 옮길 수 있다.
- 큰 원판이 작은 원판 위에 있으면 안된다.
#원판 개수, 출발 기둥, 도착 기둥, 경유 기둥
def moveDisc(discCnt, fromBar, toBar, viaBar):
if discCnt == 1:
print(f'{discCnt}번 원판을 {fromBar}번 기둥에서 {toBar}번 기둥으로 이동!')
else:
# (discCnt - 1)개의 원판들을 경유 기둥으로 이동
moveDisc(discCnt - 1, fromBar, viaBar, toBar)
# discCnt번 원판을 목적 기둥으로 이동
print(f'{discCnt}번 원판을 {fromBar}번 기둥에서 {toBar}번 기둥으로 이동!')
# (discCnt - 1)개의 원판들을 도착 기둥으로 이동
moveDisc(discCnt - 1, viaBar, toBar, fromBar)
moveDisc(3, 1, 3, 2)
1-13 병합 정렬
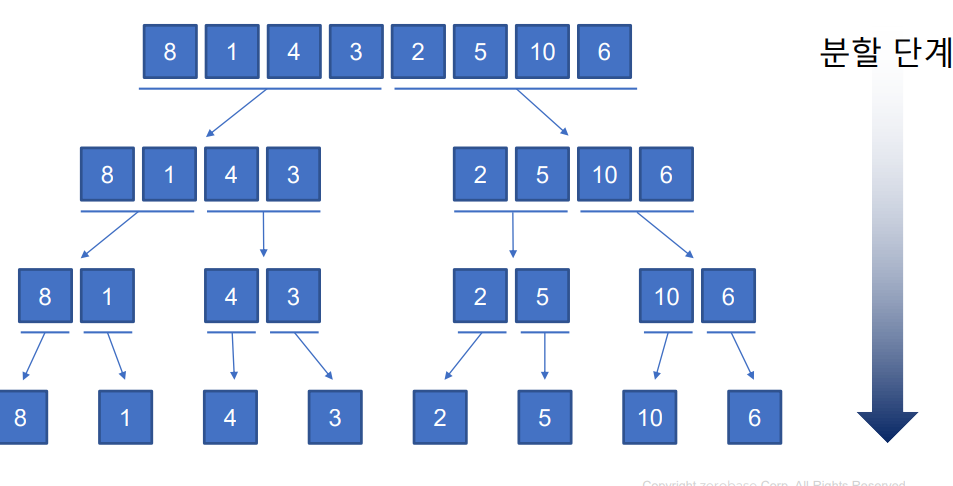
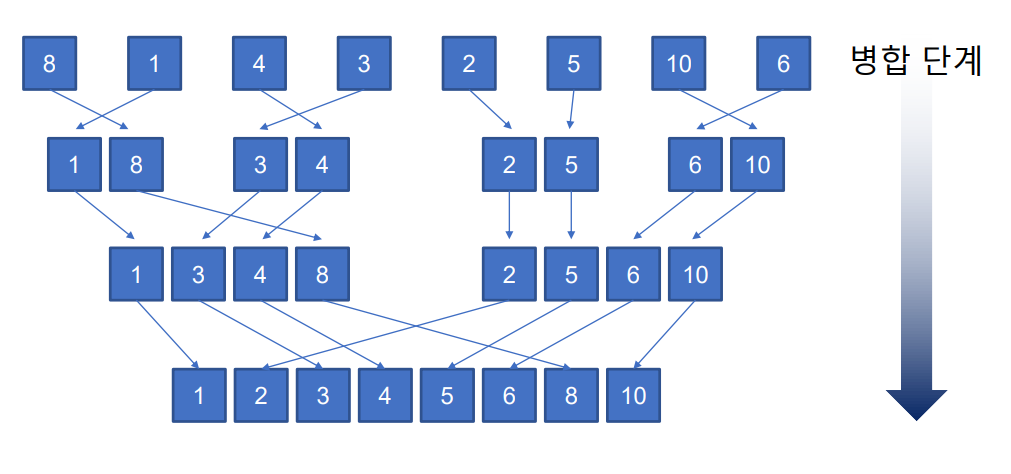
- 자료 구조를 분할하고 각각의 분할된 자료구조를 정렬한 후 다시 병합하여 정렬한다.
-코드 동작-
1. 먼저 정렬할 리스트를 분할하여 두 개의 리스트로 나눈다.
2. 분할은 리스트 길이가 1까지 한다.
3. 두 개로 나뉜 리스트들을 재귀 정렬한다.
4. 정렬된 부분 리스트들을 하나의 정렬 리스트로 병합한다.
5. 리스트의 원소를 크기 비교를 하여 순서대로 합친다.
def mSort(ns):
if len(ns) < 2:
#nums = [8, 1, 4, 3, 2, 5, 10, 6]
#인덱스가 0~1개 일때 재귀를 멈추고 해당 리스트 인덱스를 반환하도록 설정
#2
return ns
#분할단계 값을 쪼갠다.
midIdx = len(ns) //2
#매개변수 ns를 (mSort(nums))의 리스트를 반으로 나눈다.
#그 이유는 왼쪽(leftNums)와 오른쪽(rightNums)로 나누기 위함이다.
leftNums = mSort(ns[0:midIdx])
#리스트를 분할한다. 첫번째 인덱스 부터 midIdx-1까지 분할하여 정렬
#0부터 분할된 부분까지 임으로 왼쪽 부분에 해당한다.
rightNums = mSort(ns[midIdx: len(ns)])
#분할 부분부터 시작하여 끝까지 정렬한다. (오른쪽에 해당)
mergeNums = []
leftIdx = 0
rightIdx = 0
while leftIdx < len(leftNums) and rightIdx < len(rightNums):
#leftIdx,rightIdx 가 왼쪽,오른쪽 길이보다 작으면 실행 반복
# 리스트 범위내에서 반복 한다는뜻
#병합단계
#왼쪽 부분 정렬 단계
if leftNums[leftIdx] < rightNums[rightIdx]:
#leftIdx가 rightIdx 보다 작으면
#mergeNums 리스트에 값 추가한다.
#그리고 leftIdx 값을 +1
mergeNums.append(leftNums[leftIdx])
leftIdx +=1
#오른쪽 부분 정렬 단계
else:#rightIdx가 큰경우 rightIdx +1
mergeNums.append(rightNums[rightIdx])
rightIdx +=1
mergeNums = mergeNums + leftNums[leftIdx: ]
#leftIdx 왼쪽부터 끝까지부분 인덱스를 mergeNums 변수에 추가한다.
mergeNums = mergeNums + rightNums[rightIdx:]
#rightIdx 위치부터 끝부분 인덱스 까지 추가한다.
return mergeNums
nums = [8, 1, 4, 3, 2, 5, 10, 6]
print(f'mSort(nums): {mSort(nums)}')
1-14 퀵 정렬
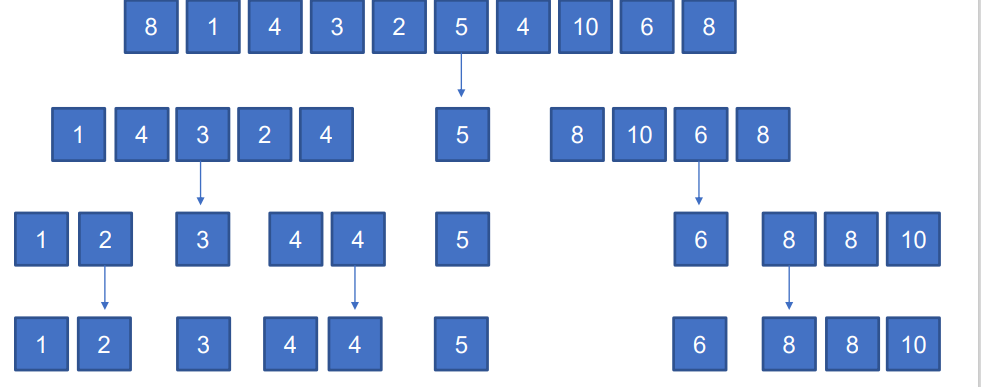
- 기준 값보다 작은 값과 큰 값으로 분리한 후 다시 합친다.
-코드동작-
(기준점 선택)
1. 하나의 요소를 기준점으로 선택한다.
위 이미지 에선 처음에 5 를 기준으로 기준점을 선택했고
분리를 하면서 3 ,5 ,6 기준점으로 정렬 선택
또 분리 후 2, 4, 5, 6, 8을 기준으로 정렬
(분할)
2. 기준점을 기준으로 작은 요소는 왼쪽, 큰 요소는 오른쪽으로 분할한다.
3. 기준점을 기준으로 정렬되지 않은 두 개의 부분 리스트로 분할
(정복)
4. 분할된 두 개의 부분 리스트에 대해 퀵 정렬 수행한다.
(병합)
5. 정렬 된 리스트들을 하나로 합친다.
#기준 값보다 작은 값과 큰 값으로 분리한 후 다시 합친다.
def qSort(ns):
if len(ns) < 2:
return ns
midIdx = len(ns) // 2
midVal = ns[midIdx]
smallNums = [] # 값이 작은 경우 (왼쪽)
sameNums = [] # 값이 같은 경우
bignums = [] # 값이 큰 경우 (오른쪽)
for n in ns:
if n < midVal: # 기준값보다 작은 경우
smallNums.append(n)
elif n == midVal: # 기준값과 같은 경우
sameNums.append(n)
else: # 기준값보다 큰 경우
bignums.append(n)
return qSort(smallNums) + sameNums + qSort(bignums)
nums = [8, 1, 4, 3, 2, 5, 4, 10, 6, 8]
print(f'qSort(nums): {qSort(nums)}')
후기
어느덧 제로베이스 입과후 4주차가 지났다.
이번주는 팀원들과 첫 영상 미팅을 가지게 되었다.
첫 미팅 주제는 3주차 스터디 과제에 대해서 이야기를 나누었다.
4주차에 알고리즘을 배우게 되었다. 생소하고 주석 처리를 하면서 코드를 작성했지만
쉽지 않았다. 이론은 이해했으나 코드해석은 절반도 이해하지 못한 거 같다.
자주 벨로그를 확인해서 코드를 이해해보아야 겠다.
이래가지고 DA가 될수있을까... 공부 시간을 더 늘려야 겠다.
