WizardLM : Empowering Large Language Models to Follow Complex Instructions
My comment
진화 알고리즘의 핵심은, 지시문을 진화시키는 방법을 여섯 가지 카테고리로 나누었다는 점인 것 같다.
그리고 한 번에 너무 많은 진화를 시도하지 않고, 단계적으로 복잡도를 높이는 것이 순차적 진화의 핵심이라고 생각한다.
LLM에게 한 번에 너무 많은 작업을 시키면, 할루시네이션이나 잘못된 정보를 생성할 가능성이 높다고 본다.
따라서 앞으로의 연구에서는, LLM이 특정 테스크를 가장 효율적으로 수행할 수 있는 적절한 명령 범위를 고민하는 것이 중요하다고 생각한다.
Abstract
지시 데이터를 수작업으로 생성하는 것은 많은 시간적&인적 리소스 발생
인간 대신 LLM을 이용하여 대량의 지시 데이터를 생성
Evol-Insturct : 지시문을 단계적으로 다시 작성(rewrite)하여 복잡한 지시문으로 진화시키는 기법
WizardLM : Evol-Instruct 기법을 통해 생성된 데이터를 LLaMA모델에 파인튜닝한 모델
Alpaca, Vicuna보다 더 뛰어난 성능을 보임
1. Introduction
- LLM 모델의 한계 : 특정 지시나 목표 수행에 취약하며, 실제 환경에서 활용성 및 응용가능성이 제한된다.
- LLM 모델의 훈련은 초기에 NLP 테스크 (closed-domain)을 수행하는데 이는 두 가지 한계를 감
1) 소수의 공통된 지시문을 공유해서 다양성이 제한된다.
2) 대부분의 지시문은 단일 작업 수행만 요구 (인간의 지시는 복합적임)
open-domain instruction data : 특정 domain에 제한되지 않은 일반적이고 다양성 높은 지시문 데이터 다양한 작업 수행을 가능하게 하지만 인적, 시간적 리소스가 많이 요구되고 있음
Evol-Instruct
자동으로 open-domain instructions data 대량 생산하는 새로운 방법
In-depth Evolving
- 제약조건 추가 (Add Constraints)
- 심화 (Deepening)
- 구체화 (Concretizing)
- 추론 단계 증가 (Increase Reasoning Steps)
- 입력 복잡화 (Complicate Input)
In-berath Evolving
- 변이 (mutation) : 주어진 지시문을 기반으로 완전히 새로운 재시문 생성
Instruction Eliminator (지시문 제거기)
- 프롬프트를 통해 LLM이 지시문을 생성 진화가 실패한 지시문 제거
- 학습 결과 비교
-- Alpaca : self-instruct를 통해 데이터 생성
-- Vicuna : 인간이 만든 open-domain instruction 포함 (현실 데이터)
-- WizardLM : 인간 없이 LLM을 이용해 지시문 자체를 점점 복잡하게 진화시켜 만든 모델
결론 (발견사항)
- open-domain instruction을 LLM을 통해 자동 대량 생성함으로써, LLM의 성능을 향상시키는 Evol-Instuct 제안
- WizardLM 모델을 개발하여, 다양한 도메인에서 크게 우수한 성능을 보임
- 지시문의 복잡도가 supervised fine-tuning 성능 향상에 매우 중요함을 확인
2. Related Work
Closed domain instruction tuning
- 초기 언어모델은 작업 간 일반화 능력에 초점을 맞춤
- 다양한 연구들에서는 다양한 NLP 작업 지시문으로 언어모델을 fine-tuning을 하면 새로운 작업에서도 성능이 향상된다는 점을 보임
- But, closed로 훈련된 언어모델은 실제 사용자 시나리오에서는 제대로 동작 못함
Open domain instruction tuning
- 인간 작성 instruction-response 쌍 제작
- LLM의 표면적 응답 텍스트 뿐만 아니라, 복잡한 추론 과정 신호까지 학습
- 기존 연구와의 차이점 : Vicuna와 달리 AI가 생성한 데이터를 이용하여 파인튜닝을 하고, Alpaca의 self-instruct와 달리 생성되는 지시문의 난이도와 복잡도 수준을 정교하게 제어할 수 있다.
3. Approach
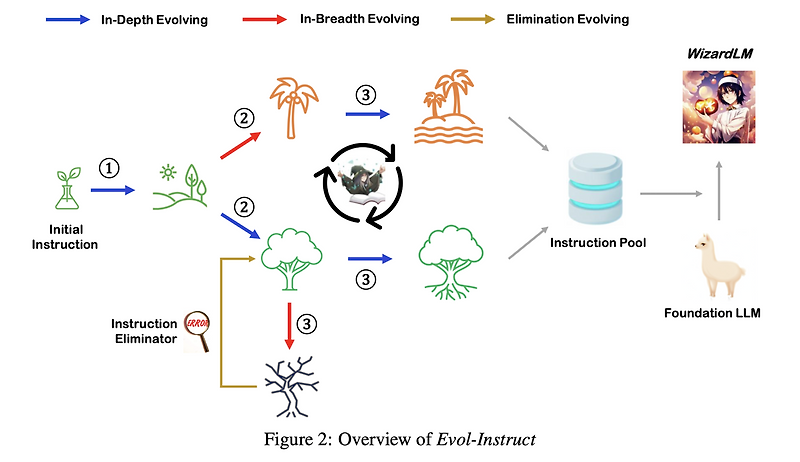
Evol-Instruct의 파이프라이은은 크게 Instruction Evolver(In-Depth Evolving + In-Breathe Evolving)와 Instruction Eliminator로 구성
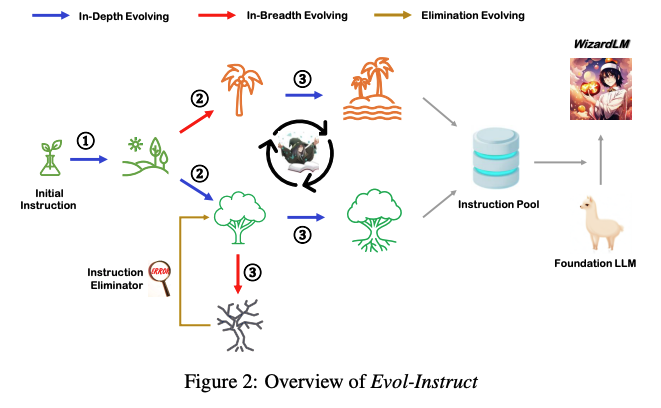
3.1 Definition of Instruction Data Evolution
를 Evol-Instruct 프롬프트를 사용하여 LLM에 입력
새로운 지시문 생성
를 통해 생성
M회 반복
3.2 Automatic Instruction Data Evolution
지시문 생성 3가지 단계
1. instruction evolving
2. response generation
3. elimination evolving
Instruction Evolution
LLM 특징
- LLM은 특정한 프롬프트를 사용하면 instruction을 더 복잡하고 어려운 형태로 변환 가능
- 완전히 새로운 복잡한 instruction도 생성할 수 있음
초기 instruction 데이터셋을 반복적으로 진화시켜, instruction의 difficulty를 높이고, 내용의 풍부함과 다양성을 확장
- instrcution pool에서 이전 instruction을 불러와 진화시키고, instruction eliminator을 통해 진화가 실패했는지 검사
- 성공적으로 진화한 instruction은 pool에 추가하고, 실패한 instruction은 그대로 유지하여 다음 단계에서 다시 시도
Instruction Evolver
In-Depth Evolving
1. 제약조건 추가
2. 심화
3. 구체화
4. 추론 단계 증가
5. 입력 복잡화
프롬프트 내용
"Your objective is to rewrite
a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT
and GPT4 (OpenAI, 2023)) a bit harder to handle. But the rewritten prompt must be reasonable,
understood, and responded to by humans"
korean ver.
"당신의 목표는 주어진 프롬프트를 더 복잡한 버전으로 다시 작성하여,
ChatGPT나 GPT-4 같은 유명한 AI 시스템이 처리하기 조금 더 어렵게 만드는 것이다.
단, 새로 작성된 프롬프트는 인간이 이해하고 응답할 수 있을 정도로 합리적이어야 한다."
- instruction의 난이도를 조금씩 높이도록 유도하고, 추가되는 단어 수를 최대 10~20단어로 제한
- 입력 복잡화를 제외한 네 가지는 예시없이 수행 가능
In-Breadth Evovlving
- 주제 범위, 기술 범위, 전체 데이터셋의 다양성을 확장하기 위한 과정
- 기존 instruction에서 영감을 받아 새로운 instruction을 생성하도록 프롬프트 진행
프롬프트 내용
"I want you act as a Prompt Creator.
Your goal is to draw inspiration from the #Given Prompt# to create a brand new prompt.
This new prompt should belong to the same domain as the #Given Prompt# but be even more rare.
The LENGTH and difficulty level of the #Created Prompt# should be similar to that of the #Given Prompt#."
Response Generation
- 진화된 instruction에 대한 response를 생성
Elimination Evolving
진화 실패로 분류하는 4가지 경우에 따라 해당 instruction을 제거한다.
1. 진화된 instruction이 기존 instruction과 비교해 정보 이득(information gain)
이 없는 경우
2. 진화된 instruction에 대해 LLM이 응답을 제대로 생성하지 못하는 경우
3. 생성된 응답이 문장부호나 불용어만 포함하는 경우
4. 진화된 instruction이 프롬프트 내부 단어를 그대로 복사한 경우
3.3 Finetuning the LLM on the Evolved Instructions
- initial instruction dataset과 각 단계의 진화된 instruction dataset을 병합하고, 샘플을 무작위로 섞어 최종 finetune dataset 구성
이렇게 하는 이유: 다양한 난이도의 지시문이 고르게 분포되어 모델의 학습이 안정적으로 진행됨 - Vicuna에서 사용한 동일한 프롬프트 형식을 가지고 파인튜닝 수행
4. Experiment
WizardLM을 automatic evaluation과 human evaluation 수행
4.1 Baselines
- ChatGPT, ALpaca, Vicuna, 그 외 LLaMa-13B 기반 모델들과 비교 수행
4.2 Experiment Detail
- 각 라운드 진화에서 여섯 가지 진화 프롬프트 중 하나를 무작위 선택
parameter
temperature = 1
최대 생성 토큰 수 = 2048
frequency penalty = 0
top-p = 0.9
learning
optimizer = Adam
learning rate = 2 x10^-5
최대 토큰 길이 : 2048
배치 크기 : GPU당 4
4.3 Automatic Evaluation
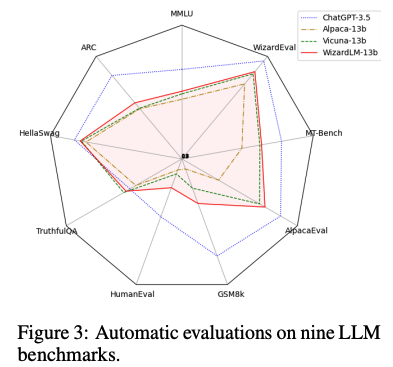
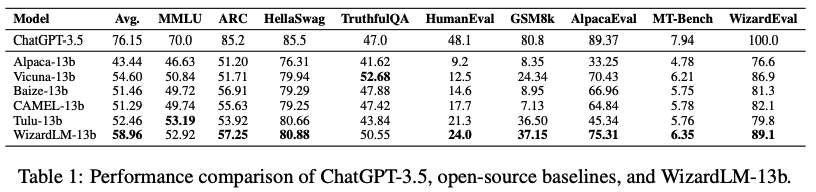
- 벤치마크 테스크 종류 : 다지선다형 학술 문제, 과학 질문, 상식 추론, 모델의 허위 정보 모방하는 정도 측정, 코드 생성, 수학 추론, GPT-4 평가 벤치마크
- 다른 오픈소스 모델들과 비교할 때 WizardLM은 대부분의 벤치마크에서 두드러진 성능 우위를 보임
4.4 Human Evaluation
- 직접 제작한 테스트셋 WizardEval을 통해 평가 수행
- 총 29개의 기술과 도메인 포괄
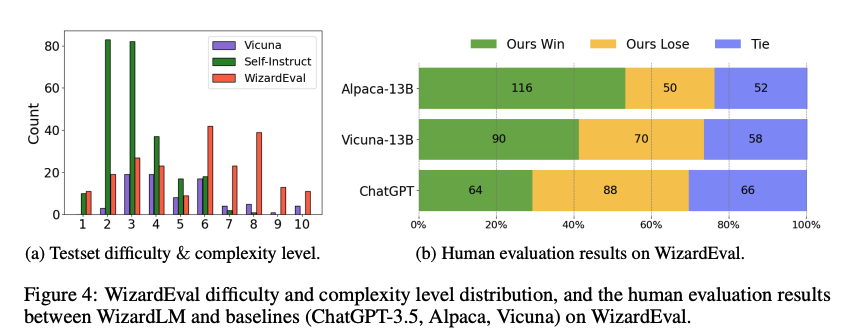
- 직접 생성한 데이터셋은 난이도 분포가 일정
- 인간 평가 결과, Alpaca와 Vicuna와 비교했을 때 더 나은 응답을 나타냄을 알 수 있음
4.5 Ablation Study
(요약)
In-depth Evovling은 instruction의 복잡도와 추론 난이도를 단계적으로 높여서 모델의 사고 능력을 강화
In-breath Evolving은 주제 다양성을 넓혀 모델이 더 다양한 영역을 다룰 수 있도록 함
두 과정이 상호보완적으로 작용하여 WizardLM이 더 넓은 범위의 instruction을 처리하고 더 깊이 있는 추론을 수행
5. Conclusions
본 논문에서는 Evol-Instruct라는 새로운 진화 알고리즘을 제안하였고, 이를 통해 다양한 instruction data를 자동으로 생성하였다.
이를 오픈소스 LLM 모델에 파인튜닝한 WizardLM은 다른 LLM보다 다양한 테스크의 벤치마크에서 우수한 성능을 보였다.
한계점
- automatic evaluation과 human evaluation을 수행했지만, 이러한 평가방식은 확장성과 신뢰성 측면에서 제약 있음
- 본 논문에서 제안한 test set이 모든 시나리오나 도메인을 대표하지는 않음
