[논문리뷰] Sequence to Sequence Learning with Neural Networks
Abstract
- 전통적인 MLP/Conv 등 고정 길이 입력을 주로 다루는 DNN은 시퀀스처럼 가변 길이이고 순서·의존성이 중요한 데이터에 직접 적용하기 어렵다.
- RNN은 재귀적으로 은닉상태를 갱신하며 시퀀스를 처리하지만, 긴 의존성을 다룰 때 기울기 소실/폭주(vanishing/exploding) 문제가 발생한다.
- LSTM은 게이트와 셀 상태(𝑐𝑡) 를 도입해 중요한 정보를 오래 보존하고 불필요한 것은 잊게 하면서 이 문제를 완화한다.
- Seq2Seq(Encoder–Decoder) 는 인코더가 입력 시퀀스를 요약한 뒤(컨텍스트/최종 상태) 디코더가 이를 조건으로 다음 토큰 분포를 순차적으로 생성하는 구조다. 바닐라 RNN 대신 LSTM 셀을 쓰면 장기 의존성에 더 강하다.
- 다층 LSTM을 사용
- 입력 시퀀스를 고정 차원의 벡터로 매핑하고, 이어서 또 다른 다층 LSTM을 사용해 그 벡터로 부터 목표 시퀀스를 디코딩한다.
- 어순을 거꾸로 하면서 입력 문장과 target 문장 사이에 많은 단기 종속성 (short term dependencies)를 도입하도록 함
- 본 논문에서는 인위적으로 만들어낸 다양한 패턴들에 대해서 LSTM을 적용시켜 RTRL, BPTT, Recurrent Cascade-Correlation, Elman nets, Neural Sequence Chnking등과 비교해보았으며, 실험을 통해 LSTM의 우수함을 입증하였다.
Introduction
- 기존 DNN에 관한 내용
- 음성 인식과 객체 탐지와 같이 많은 task에 사용되고 있음
- 병렬 컴퓨팅이 가능하고, 지도 학습의 경우에는 역전파를 이용하여 최적의 파라미터 찾음
- 그러나, input과 target이 고정된 길이의 벡터로 encoding되는 점이 문제점
- 실제로 대부분의 task는 고정된 길이가 아닐 것이기 때문에, 도메인 독립적인 게 필요!
논문은 LSTM을 제시하면서 이 문제를 풀고자 한다. 입력 시퀀스를 한 타임 스템씩 읽어 큰 고정 차원의 벡터 표현을 얻고, 그 다음 또 다른LSTM을 사용해 그 벡터로 부터 출력 시퀀스를 추출하는 것이다.
모델 구조
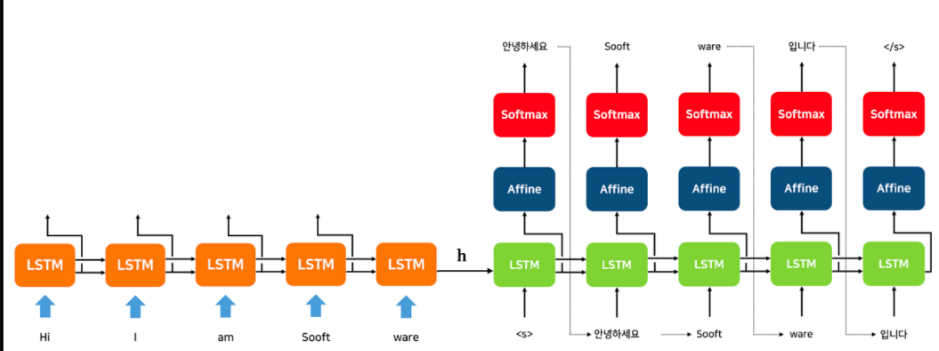
모델을 읽는 법 박스는 RNN cell에서 LSTM으로 대체했다 그리하여 LSTM이반 seq2seq가 된다.
첫번째, 하나의 LSTM을 사용하여 입력 sequence를 읽고나서 고정 차원 벡터로 표현한다.
두번째, 다른 LSTM을 사용하여 해당 벡터에서 출력 sequence를 추출한다.
세번째, LSTM은 입력 sequence에 따라 조건이 지정된다는 점을 제외하면 기본적으로 RNN 언어 모델이다.
마지막으로, LSTM은 입력과 해당 출력 사이에 상당한 시간 지연이 있기 때문에 긴 범위의 일시적인 의존성을 학습한다.
Lstm vs Rnn
아래는 편집·복붙 가능한 Markdown + LaTeX 형태로 깔끔히 정리한 내용입니다.
RNN 기본식과 한계
바닐라 RNN의 한 스텝 갱신식은 다음과 같다.
여기서 는 보통 또는 ReLU를 사용한다.
긴 시퀀스에서는 가 반복 곱 형태가 되어, 작은 고유값(또는 큰 고유값)에 의해 기울기 소실(또는 폭주)가 발생하기 쉽다. 그 결과, 멀리 떨어진 정보가 학습 신호로 잘 전달되지 않는 문제가 생긴다.
LSTM 셀 구조와 수식
LSTM은 은닉상태 와 별도로 셀 상태 를 유지한다. 한 스텝의 갱신은 다음과 같다.
흐름도 관점(텍스트 설명)
- 입력: 가 LSTM 셀로 들어간다.
- 수평 내부 전달: (셀 상태의 “고속도로”).
- 수직 출력: 가 FC(+softmax)로 올라가 출력 분포를 만든다.
- 다음 스텝으로 전달: 둘 다 다음 시점으로 전달된다.
중요: “RNN의 확률”과 “LSTM의 확률” 정의는 동일하다. 달라지는 것은 확률을 만들게 되는 표현 의 품질이며, LSTM은 덕분에 장기 정보를 보존해 더 나은 를 제공하는 경향이 있다.
LSTM(Long Short-Term Memory)에 대해 좀 더 자세히 설명하자면
- 장기의존성의 약점을 보완하기 위해 lstm이 탄생했다.
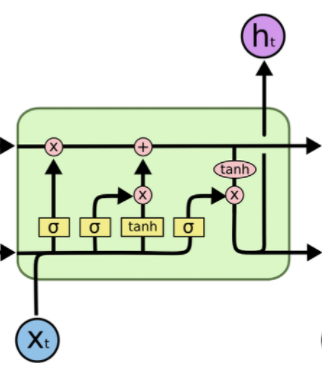
LSTM Cell의 구조는 위와 같다.
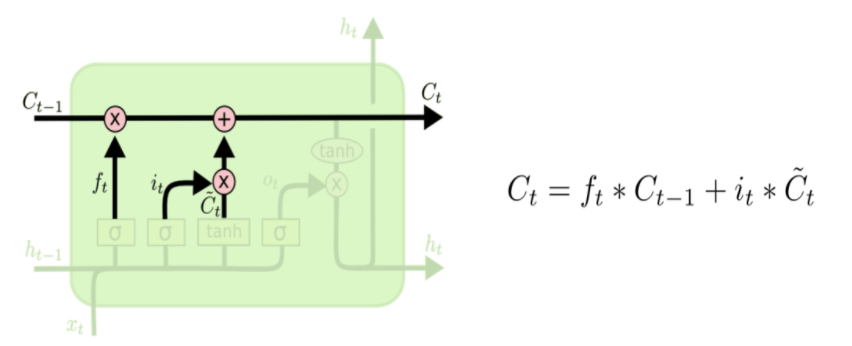
기존 Vanilla RNN이 hidden state만을 사용하던 것과 달리, LSTM에서는 Cell State라는 새로운 Flow를 도입하였다. 이는 마치 컨베이어 벨트처럼 이전에 입력됐던 정보들을 전달해주는 역할을 한다.
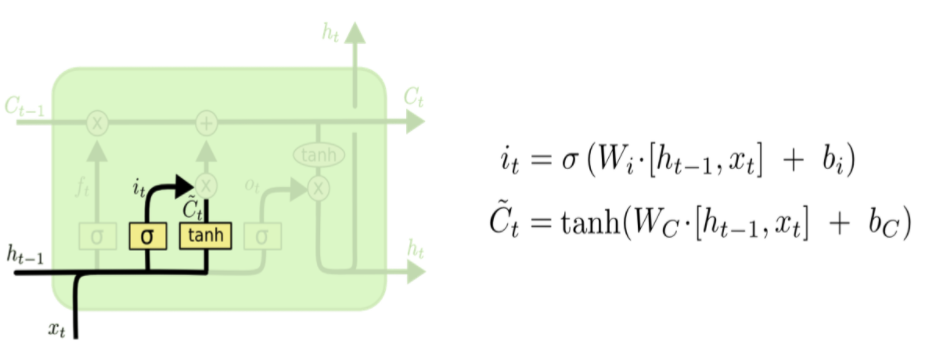
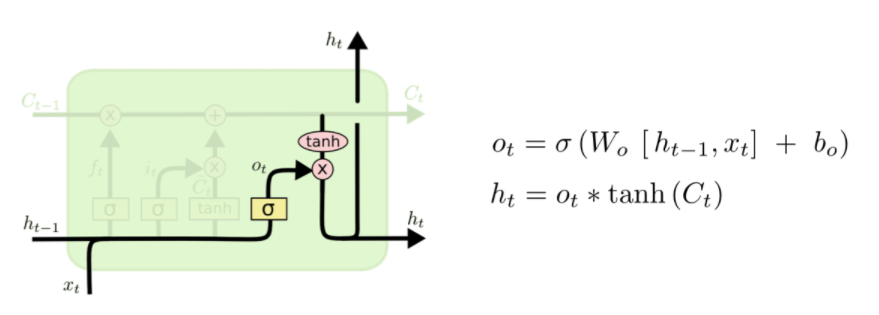
이전 Cell에서 넘어온 hidden state에 대해서 과거의 정보중 어느 것을 Cell State에 반영할 것인지를 정하는 Forget Gate(불필요한 정보를 잊는다는 의미), 현재 입력된 정보를 얼마나 Cell State에 반영할 것인지를 정하는 Input Gate, 다음 Cell에 전달할 hidden state 값에 Cell State를 얼마나 반영할 것인지를 정하는 Output Gate로 구성된다.
Forget gate
모델의 구성
과거에서 넘어온 정보 중, 불필요하다고 여겨지는 데이터들을 삭제해주는 역할을 한다.정확히는 삭제라기보다는, Sigmoid 함수를 통해 얻어진 0~1 사이의 가중치를 곱해줘서 학습을 하면서 상대적으로 중요한 정보에는 높은 가중치를, Gradient 갱신에 별로 좋지 않은 영향을 끼치는 정보에 대해서는 낮은 가중치를 가지게 한다.
즉 Neural Network를 학습하여 얻어진 W_f(Weight of Forget Gate)와 B_f(Bias of Forget Gate)를 바탕으로 0에 가까운 값이 나오면 정보를 버리는 효과, 아예 0이 되면 삭제 반대로 1에 가까울 수록 정보 보존, 1일 경우 데이터 그대로 전달의 역할을 함으로써 Cell을 지나면서도 계속적으로 유의미한 데이터들은 Cell State Flow에 보존되도록 한다.
input gate
현재의 입력값 X_t와 이전 hidden state를 적절히 사용하여 현재 Cell의 Local State를 얻어내고, 이를 Global Cell State에 얼마나 반영할지를 결정하는 게이트이다.마찬가지로 Sigmoid 함수를 사용하므로, 현재 시점에서 얻은 정보가 큰 효용가치가 있을 경우 Cell State에 많이 반영하고, 별로 의미가 없는 데이터일 경우에는 0에 가까운 가중치를 줘서 반영을 최소화한다.
이후, 과거 hidden state에서 적절히 forget이 이루어진 cell state와, 현재 cell에서 얻을 수 있는 새로운 데이터를 반영한 cell state를 더해서 최종적인 global cell state를 update하게 된다.output gate
최종적으로 얻어진 Cell State 값에서 어느정도를 취해서 Hidden State로 전달할 것인지를 정하는 마지막 Gate이다.여기서 최종적으로 얻어진 h_t를 바탕으로 다음 셀에서는 C_t+1을 구하게 된다.
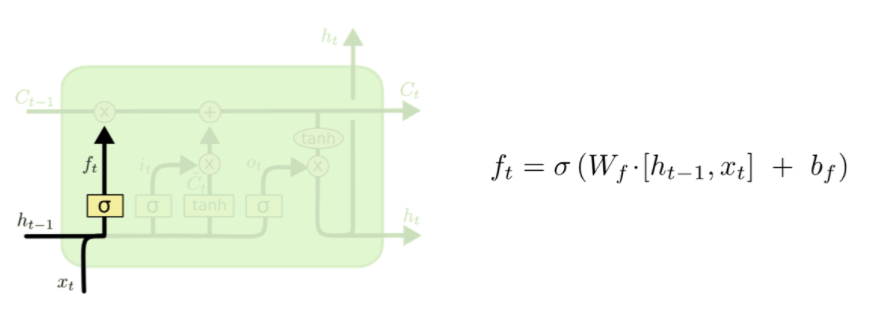
논문 과제
WMT’14 영어→프랑스어 번역 과제
5개의 deep LSTMs(with 384M parameters and 8,000 dimensional state each)를 앙상블
simple left-to-right beam-search decoder 사용
적은 수(80K)의 단어로 학습한 결과, BLEU score가 34.81임
결론
LSTM이 생각보다 긴 문장에 취약하지 않다고 함
어순 배열 바꾸기 trick으로 optimize를 되게 simple하게 해줌
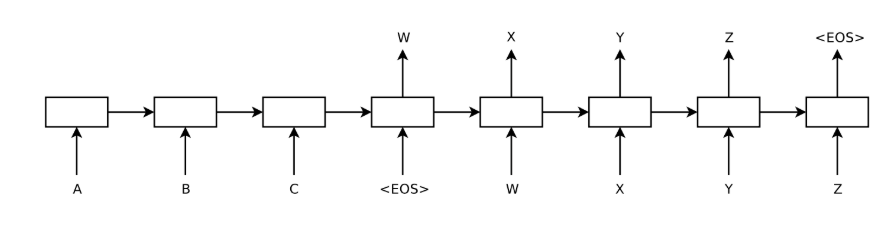
경로 길이 ≈ t + (n - t) = n (거의 항상 n)
뒤집기 후엔 대응 소스 위치가 s' = n - t + 1이 돼.
경로 길이 ≈ t + (n - s') = t + (t - 1) = 2t - 1
LSTM의 경우에는 가변 길이의 문장을 고정된 길이로 바꿔주는 것을 학습함
SOTA 보다는 약간 낮은 BLEU Score이기는 하지만, Sequence한 task를 다뤘다는 점에서 의의
Model
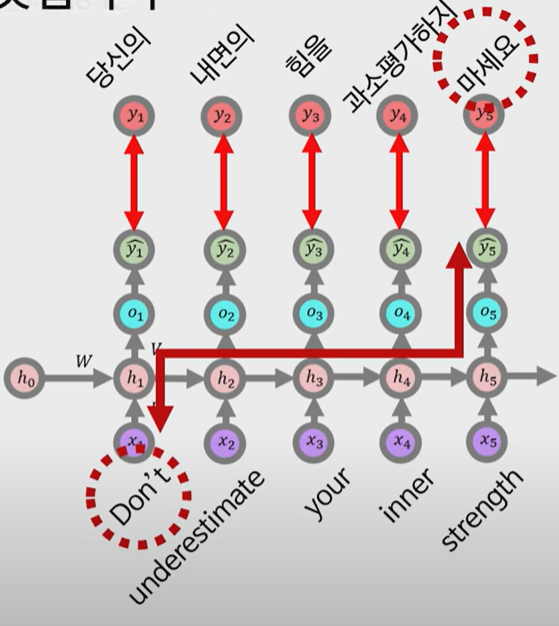
- Rnn은 다음의 방정식을 반복하여 출력 y를 수행한다.
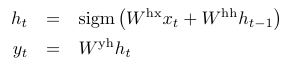
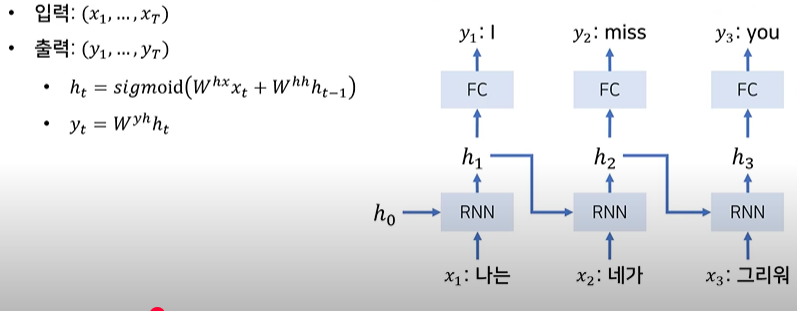
이런식으로 입출력의 갯수가 같다고 진행함
영어는 목적어가 주어와 조금 떨어진 즉 어순이 다르다. 우리는 그리워라는 단어를 확인 했을 때 비로소 miss라는 동사를 가진다고 알 수 있는 것이다. 이것은 정확한 유추가 힘들어 지는 원인이 되며
본 논문은 context 벡터를 뽑은 후에 디코딩이 도리 수 있도록 만드는 것이다.

즉 lstm 및 rnn은 밑과 같은 조건부 확률로 계산된다.
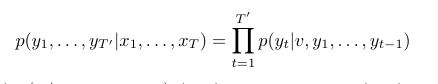
그리하여 본 논문은 위 설명과 세가지 중요한 점에서 다름을 보여준다.
첫째, 입력 시퀀스용 LSTM과 출력 시퀀스용 LSTM 두 개를 사용했는데, 이는 계산 비용 증가가 미미한 수준에서 모델 파라미터 수를 늘려 주며 여러 언어쌍을 동시에 학습시키기에 자연스럽기 때문이다
둘째, 깊은 LSTM이 얕은 LSTM보다 훨씬 더 우수하다는 것을 발견했기 때문에 4개 층을 가진 LSTM을 선택했다.
셋째, 입력 문장의 단어 순서를 역순으로 바꾸는 것이 매우 유용하다는 것을 발견했다.(그림으로 설명하겠음)
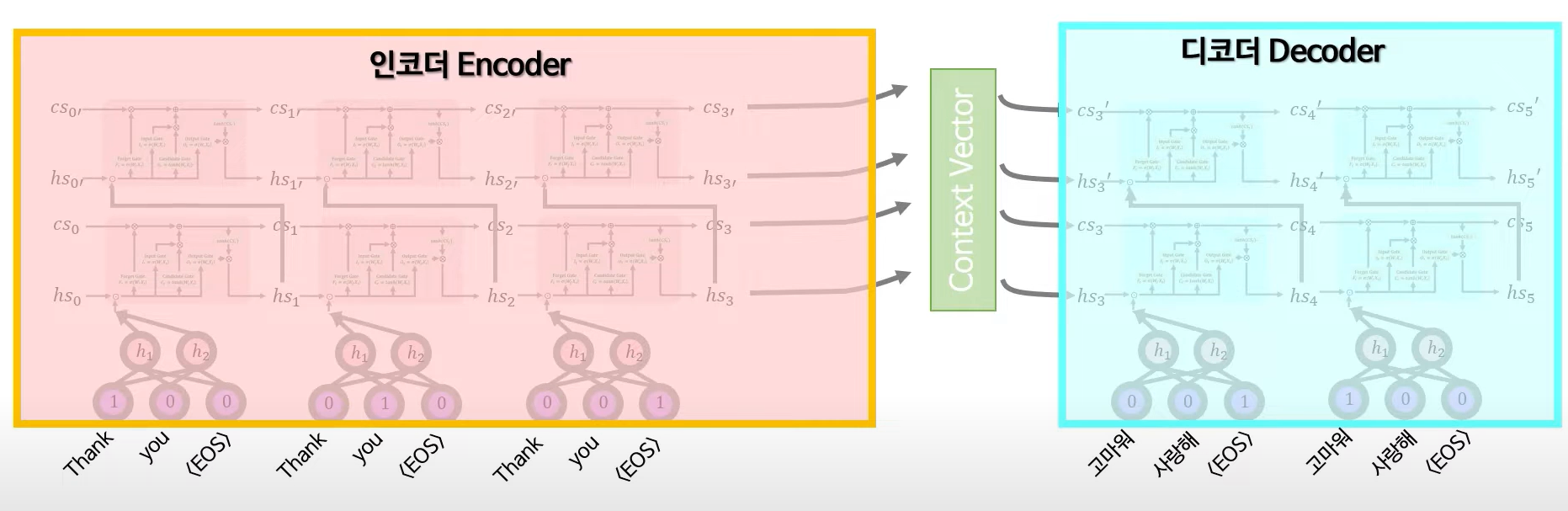
Decoding and Rescoing
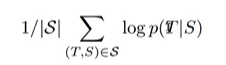
여기서 사용하는 방법은 일반적인 방법으로 특별한 것은 없다. S: 소스고 T: 타겟이다. 즉 소스 센텐스에 대한 타겟이 나올 수 있도록 학습을 진행하였고 로그를 넣음으로 써 확률값이 놓아지는 방향으로 하였다.
:???? 왜 로그를 붙였다고 확률이 높아지는가?--> 그래프를 그려서 생각해라
학습이
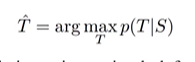
매번 센텐스가 주어질 때마다 가장 높은 확률을 타겟을 return하도록 한다. 또한 beam search기법을 활용하여 eos가 나올 떄까지의 가장 높은 확률을 고르며 토큰을 이어 붙인다. 통계적 접근 중 rescoring에서 저 기법을 사용한다.
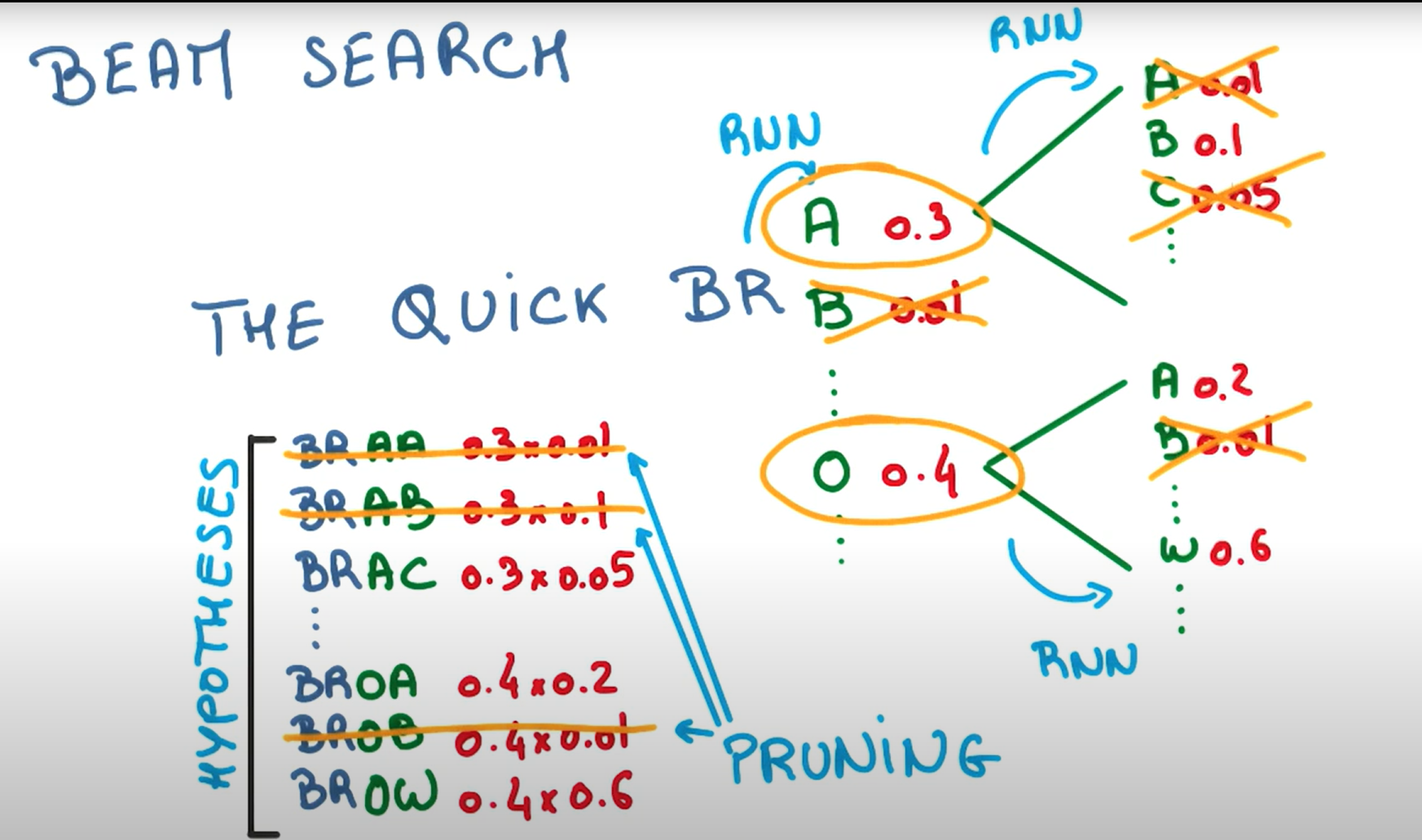
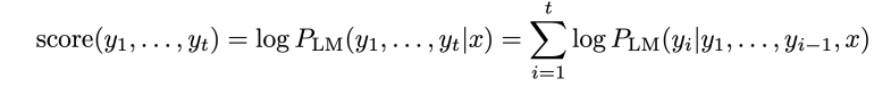
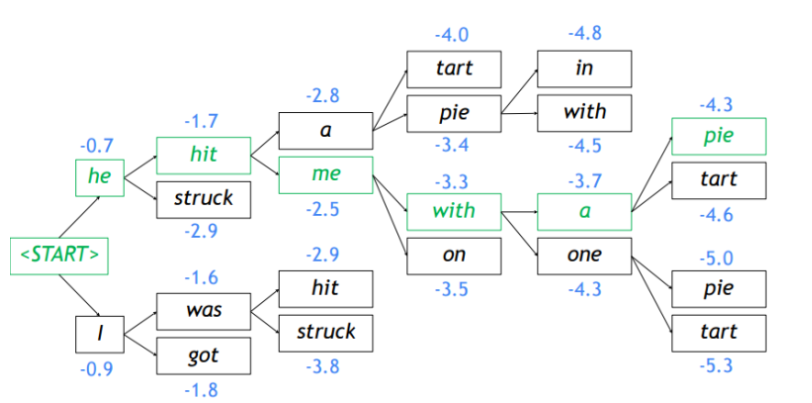
로그확률 합은 길어질수록(곱이 많아질수록) 더 작아지기 쉬워서, 빔서치가 짧은 문장을 과도하게 선호하는 편향이 있지 않을까? 하는 생각 같이 생각나누기!!
Model Analysis
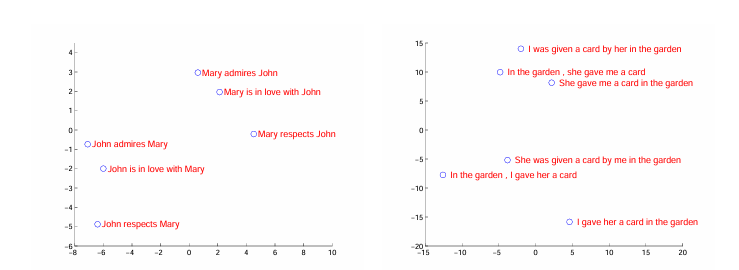
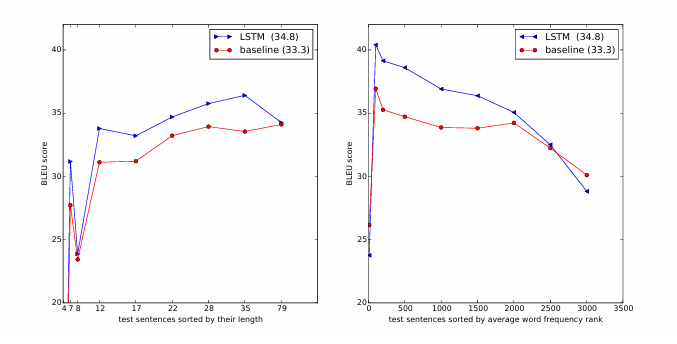
Conclusion
- LSTm을 깊게 쌓아서 기존의 통계적 선택 기법에 비해 성능이 좋았다는 것을 보여줌
- 입력 단어 순서를 바꾸는 것이 기존 그대로 이용하는 것보다 좋은 성능을 보일 수 있다.
- LSTM기반의 디코더를 거쳐 번역을 만들어 성능을 높인다.
