
PK(Primary key)는 DB 테이블을 구성할떄 거의 필수적으로 지정된다. 하지만 문득 필수로 있어야 하는가?에 대한 의문을 품었다. 우선 PK가 무슨역할을 하는지 알아보자.
테이블에서 PK의 역할
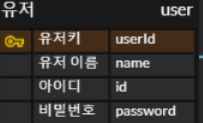 위 테이블 처럼 PK는 각각의 유저 레코드 끼리 구분짓기 위해 사용된다.
위 테이블 처럼 PK는 각각의 유저 레코드 끼리 구분짓기 위해 사용된다.
또한 테이블 끼리 관계를 맺을경우 보통 PK를 이용하여 관계를 맺기에 관계성이 중요한 RDB에선 PK는 거의 필수이다.
그럼 PK와 마찬가지로 고유성을 중요시하는 Unique key는 언제 사용하는 걸까?
Unique key의 역할?
-
PK는 NULL값을 넣지 못하므로 중복값도 허용하지 않으므로 모든 레코드를 구분할 수 있지만,UK는 NULL값을 허용하여 모든상황에서 레코드를 구분하진 못함.
-
PK는 테이블내에 하나만 설정 가능하지만 UK는 여러개를 지정할 수 있다.
-> PK는 테이블 관점에서 각 레코드를 구분시켜주기 위해 존재하고, UK는 레코드별 같은 컬럼끼리의 중복을 방지하는 역할일뿐 레코드를 구분시켜주기엔 적합하지 않음.
PK 설정시 이점
PK를 지정하면 다양한 이점이 있다.
인덱싱
검색 및 조인 연산의 속도를 향상시키기 위해 PK는 자동적으로 인덱싱으로 설정한다.
기본적으로 검색을 할때 FULL TABLE SCAN을 통해 하나씩 찾는다. 하지만 인덱싱을 사용하면 B+트리 같이 검색에 최적화 되게 저장을 하여 검색 성능이 증가한다.
외래 키(Foreign Key) 지정
RDB는 보통 PK를 이용하여 FK로 지정한다. 무조건 PK를 이용할 필요는 없지만 한테이블과 여러 테이블이 관계를 맺을때 서로 다른 컬럼을 FK로 하면 데이터 일관성에 문제가 생긴다.
다중컬럼을 PK로 둘수도 있다
PK는 무조건 하나의 컬럼으로 이루어질 필요는 없다.

다음과 같이 다대다 관계를 위해 만든 테이블은 두개의 FK 조합이 NULL값이 될 수 없고 고유성도 보장하기에 임의로 컬럼을 생성하여 PK로 지정하지 않아도 된다.
다중컬럼을 PK로 지정할땐 DDL에서 먼저 선언한 컬럼을 우선으로 인덱싱한다.
PK는 다른 테이블의 FK로 쓰이는 경우가 많고 인덱싱으로 지정되어 있어 삽입시에 오래 걸려 주로 잘 변경되지 않는 컬럼으로 지정한다. 이런 관점에서 다중컬럼을 PK로 지정하는것은 안좋을 수 있다.
PK는 필수인가요?
PK를 두면 여러 이점이 있는것을 알았다.
결론적으론 레코드를 각각 식별할 필요없는 데이터(ex.분석을 위해 수집한 수많은 데이터..) 는 굳이 PK를 둘 필요가 없다.
하지만 PK를 설정하지 않으면 RDB의 이점을 제대로 사용하지 못한다고 할 수 있다.
